
CLI - интерфейс уровня вызовов








• Большим достижением явилось появление (1994 г.) в стандарте SQL интерфейса уровня вызова - CLI (CallLevelInterface), в котором стандартизован общий набор рабочих процедур, обеспечивающий совместимость со всеми основными серверами баз данных. Ключевой элемент CLI - специальная библиотека для компьютера-клиента, в которой хранятся вызовы процедур и большинство часто используемых сетевых компонентов для организации связи с сервером. Это ПО поставляется разработчиком средств SQL, не является универсальным и поддерживает разнообразные транспортные протоколы.
• Использование программных вызовов позволяет свести к минимуму операции на компьютере-клиенте. В общем случае клиент формирует оператор языка SQL в виде строки и пересылает ее на сервер посредством процедуры исполнения (execute). Когда же сервер в качестве ответа возвращает несколько строк данных, клиент считывает результат с помощью серии вызовов процедуры выборки данных. Далее информация из столбцов полученной таблицы может быть связана с соответствующими переменными приложения. Вызов специальной процедуры позволяет клиенту определить считанное число строк, столбцов и типы данных в каждом столбце.
• Интерфейс CLI построен таким образом, что перед передачей запроса серверу клиент не должен заботиться о типе оператора SQL, будь то выборка, обновление, удаление или вставка.
45.Вопросы практического программирования. ODBCи JDBC -интерфейсы доступа к базам данных. Их особенности.
ODBC - открытый интерфейс к базам данных на платформе MS W indows
• Очень важный шаг к созданию переносимых приложений обработки данных сделала фирма Microsoft, опубликовавшая в 1992 году спецификацию ODBC (OpenDatabaseConnetcivity - открытого интерфейса к базам данных), предназначенную для унификации доступа к данным с персональных компьютеров работающих под управлением операционной системы Windows. (Заметим, что ODBC опирается на спецификации CLI).
• Структурная схема доступа к данным с использованием ODBC:
• 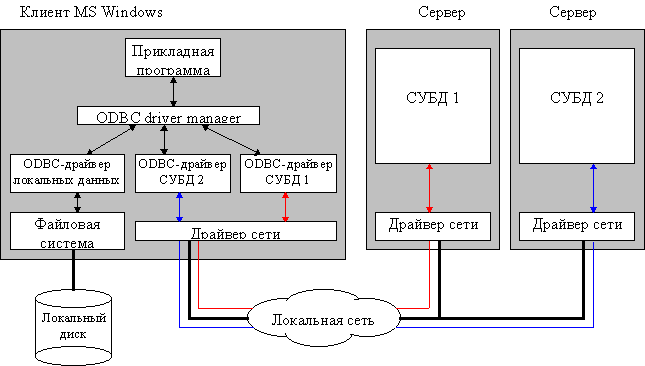 ODBC представляет собой программный слой, унифицирующий интерфейс приложений с базами данных. За реализацию особенностей доступа к каждой отдельной СУБД отвечает специальный ODBC-драйвер. Пользовательское приложение этих особенностей не видит, т.к. взаимодействует с универсальным программным слоем более высокого уровня. Таким образом, приложение становится в значительной степени независимым от СУБД. Однако, этот способ также не лишен недостатков:
ODBC представляет собой программный слой, унифицирующий интерфейс приложений с базами данных. За реализацию особенностей доступа к каждой отдельной СУБД отвечает специальный ODBC-драйвер. Пользовательское приложение этих особенностей не видит, т.к. взаимодействует с универсальным программным слоем более высокого уровня. Таким образом, приложение становится в значительной степени независимым от СУБД. Однако, этот способ также не лишен недостатков:
- приложения становятся привязанными к платформе MS Windows;
- увеличивается время обработки запросов (как следствие введения дополнительного программного слоя);
- необходимо предварительная инсталляция ODBC-драйвера и настройка ODBC (указание драйвера, сетевого пути к серверу, базы данных и т.д.) на каждом рабочем месте. Параметры этой настройки являются статическими, т.е. приложение их самостоятельно изменить не может.
JDBC - мобильный интерфейс к базам данных на платформе Java.
• JDBC (JavaDataBaseConnectivity) - это интерфейс прикладного программирования (API) для выполнения SQL-запросов к базам данных из программ, написанных на языке Java. Напомним, что язык Java, созданный компанией Sun, является платформо - независимым и позволяет создавать как собственно приложения (standaloneapplication), так и программы (апплеты), встраиваемые в web-страницы.
• Структурная схема доступа к данным с использованием JDBC:
• 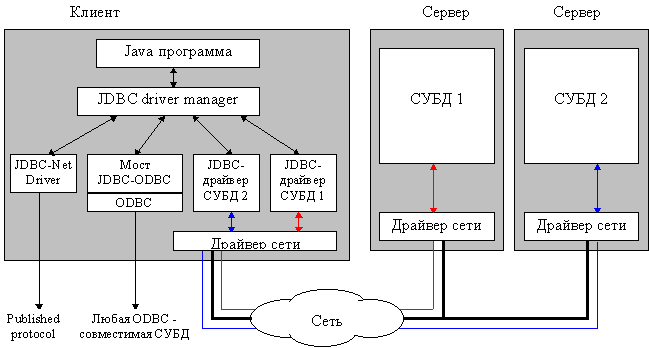 JDBC во многом подобен ODBC (см. рисунок), также построен на основе спецификации CLI, однако имеет ряд замечательных отличий. Во-первых, приложение загружает JDBC-драйвер динамически, следовательно администрирование клиентов упрощается, более того, появляется возможность переключаться на работу с другой СУБД без перенастройки клиентского рабочего места. Во-вторых, JDBC, как и Java в целом, не привязан к конкретной аппаратной платформе, следовательно проблемы с переносимостью приложений практически снимаются. В-третьих, использование Java-приложений и связанной с ними идеологии "тонких клиентов" обещает снизить требования к оборудованию клиентских рабочих мест.
JDBC во многом подобен ODBC (см. рисунок), также построен на основе спецификации CLI, однако имеет ряд замечательных отличий. Во-первых, приложение загружает JDBC-драйвер динамически, следовательно администрирование клиентов упрощается, более того, появляется возможность переключаться на работу с другой СУБД без перенастройки клиентского рабочего места. Во-вторых, JDBC, как и Java в целом, не привязан к конкретной аппаратной платформе, следовательно проблемы с переносимостью приложений практически снимаются. В-третьих, использование Java-приложений и связанной с ними идеологии "тонких клиентов" обещает снизить требования к оборудованию клиентских рабочих мест.
46.Архитектура "клиент-сервер". Структура сервера базы данных.
• Основные понятия.
• Как правило, компьютеры и программы, входящие в состав информационной системы, не являются равноправными. Некоторые из них владеют ресурсами (файловая система, процессор, принтер, база данных и т.д.), другие имеют возможность обращаться к этим ресурсам. Компьютер (или программу), управляющий ресурсом, называют сервером этого ресурса (файл-сервер, сервер базы данных, вычислительный сервер...). Клиент и сервер какого-либо ресурса могут находится как в рамках одной вычислительной системы, так и на различных компьютерах, связанных сетью.
• Основной принцип технологии "клиент-сервер" заключается в разделении функций приложения на три группы:
- ввод и отображение данных (взаимодействие с пользователем);
- прикладные функции, характерные для данной предметной области;
- функции управления ресурсами (файловой системой, базой данных и т.д.).
• Поэтому, в любом приложении выделяются следующие компоненты:
- компонент представления данных;
- прикладной компонент;
- компонент управления ресурсом.
• Связь между компонентами осуществляется по определенным правилам, которые называют "протокол взаимодействия".
• Модели взаимодействия клиент-сервер.
• 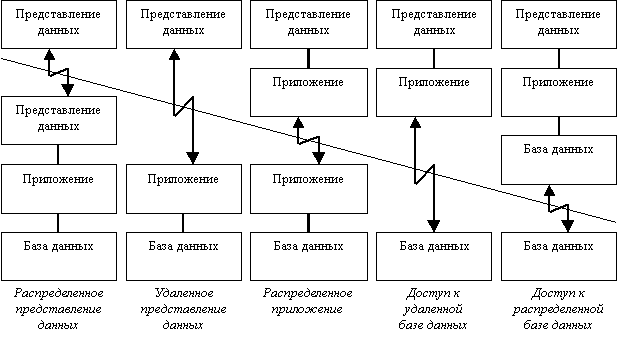 Исторически первой появилась модель распределенного представления данных, которая реализовывалась на универсальной ЭВМ с подключенными к ней неинтеллектуальными терминалами. Управление данными и взаимодействие с пользователем при этом объединялись в одной программе, на терминал передавалась только "картинка", сформированная на центральном компьютере.
Исторически первой появилась модель распределенного представления данных, которая реализовывалась на универсальной ЭВМ с подключенными к ней неинтеллектуальными терминалами. Управление данными и взаимодействие с пользователем при этом объединялись в одной программе, на терминал передавалась только "картинка", сформированная на центральном компьютере.
• Затем, с появлением персональных компьютеров (ПК) и локальных сетей, были реализованы модели доступа к удаленной базе данных. Некоторое время базовой для сетей ПК была архитектура файлового сервера. При этом один из компьютеров является файловым сервером, на клиентах выполняются приложения, в которых совмещены компонент представления и прикладной компонент (СУБД и прикладная программа). Протокол обмена при этом представляет набор низкоуровневых вызовов операций файловой системы. Такая архитектура, реализуемая, как правило, с помощью персональных СУБД, имеет очевидные недостатки - высокий сетевой трафик и отсутствие унифицированного
доступа к ресурсам.
• С появлением первых специализированных серверов баз данных появилась возможность другой реализации модели доступа к удаленной базе данных. В этом случае ядро СУБД функционирует на сервере, протокол обмена обеспечивается с помощью языка SQL. Такой подход по сравнению с файловым сервером ведет к уменьшению загрузки сети и унификации интерфейса "клиент-сервер". Однако, сетевой трафик остается достаточно высоким, кроме того, по прежнему невозможно удовлетворительное администрирование приложений, поскольку в одной программе совмещаются различные функции.
• Позже была разработана концепция активного сервера, который использовал механизм хранимых процедур. Это позволило часть прикладного компонента перенести на сервер (модель распределенного приложения). Процедуры хранятся в словаре базы данных, разделяются между несколькими клиентами и выполняются на том же компьютере, что и SQL-сервер.
• Преимущества такого подхода: возможно централизованное администрирование прикладных функций, значительно снижается сетевой трафик (т.к. передаются не SQL-запросы, а вызовы хранимых процедур). Недостаток - ограниченность средств разработки хранимых процедур по сравнению с языками общего назначения (C и Pascal).
• На практике сейчас обычно используются смешанный подход:
- простейшие прикладные функции выполняются хранимыми процедурами на сервере;
- более сложные реализуются на клиенте непосредственно в прикладной программе.
• В заключение рассмотрим физическую организацию сервера базы данных. Как правило, он включает следующие компоненты:
- подсистема взаимодействия с клиентским приложением Данный модуль отвечает за поддержание связи с клиентом. Как правило, механизм его работы выглядит следующим образом. Подсистема взаимодействия "прослушивает" сеть в ожидании клиентских запросов на установление соединения. Когда такой запрос обнаруживается, порождается новый процесс, который будет обеспечивать связь с данным клиентом. Клиенту сообщается идентификатор данного процесса, в дальнейшем клиент передает свои запросы и получает данные взаимодействуя с этим интерфейсным процессом. После того, как клиент закрывает соединение, обслуживавший его процесс прекращается. Характеристики интерфейсных процессов зависят от операционной системы, под которой исполняется сервер базы данных.
- подсистема синтаксического разбора запросов
Данный модуль отвечает за компиляцию поступающих от клиентов через интерфейсные процессы запросов во внутренний код, который будет исполняться сервером. При ошибках компиляции соответствующие сообщения передаются клиенту. Наиболее современные СУБД позволяют сохранять откомпилированный код запросов некоторое время. Это позволяет избежать стадии компиляции при повторном обращении клиента к запросу.
- подсистема планирования выполнения запросов
Данный модуль должен составить такой план выполнения запроса, чтобы он был обработан наиболее быстро. Для этого анализируются условия выборок и соединений, устанавливается порядок их выполнения. Пусть, например, надо извлечь одного сотрудника из списка работников, в качестве критерия поиска задаются его имя и фамилия. Возможны два плана выполнения запроса: (1) вначале делается выборка всех сотрудников с данным именем, из нее извлекаются записи, содержащие данную фамилию; (2) - наоборот, вначале делается выборка по фамилии, затем по имени. Поскольку множество имен, как правило, меньше множества фамилий, во втором случае запрос будет обработан быстрее, т.к. на втором этапе здесь мы получим меньшую выборку. Планировщики запросов ведущих СУБД отслеживают информацию о распределении значений в таблицах. План выполнения запроса включается в его откомпилированный код.
- подсистема выполнения транзакций
Здесь выполняется оптимизированный код запроса, обновляются индексы, выполняются в случае необходимости триггеры и хранимые процедуры. Как правило, несколько запросов могут исполняться параллельно, при этом обеспечивается необходимый уровень их изоляции. Также ведется журнал транзакций, обеспечивается их завершение и корректный откат.
- подсистема управления памятью
Этот компонент отвечает за считывание данных с диска в оперативную память, синхронизацию обновлений с данными на диске и т.д. Он может использовать файловые функции операционной системы, но часто СУБД имеет свои собственные низкоуровневые средства доступа к дискам.