
3. Физическое проектирование.








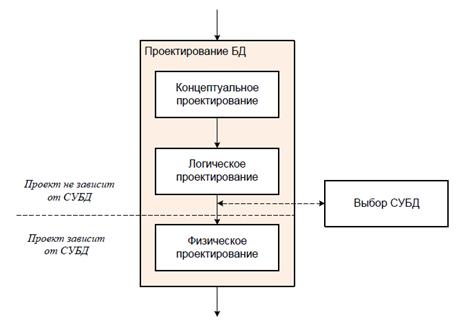
• Концептуальное проектирование
• Во время концептуального проектирования окончательно формируется замысел будущей базы данных, но без учета любых физических аспектов ее реализации.
• Пока его основной интерес направлен на создание общей модели, отражающей представления будущих пользователей БД об автоматизируемом участке компании (складе, бухгалтерии, отделе кадров, производственных цехах и т. п.). Все необходимая для этого информация уже должна быть собрана на предыдущем этапе жизненного цикла БД.
• Логическое проектирование
• Фаза логического проектирования предназначена для преобразования обобщенной концептуальной модели в завершенную логическую.
• Разработчик уточняет все требования, выявленные на концептуальной стадии проектирования, и стремится несколько упростить решение (не снижая его функциональные возможности). Для этого ER-модель проверяют с помощью правил нормализации. В результате мы получаем неизбыточные реляционные таблицы, свободные от присущих ненормализованным данным аномалиям вставки, редактирования и удаления.
• Помимо нормализации, на логическом этапе осуществляют следующие действия:
- уточняют ограничения на данные;
- определяют домены данных;
- вводят бизнес-правила и корпоративные ограничения целостности.
• Физическое проектирование
• К следующей (физической) фазе проектирования БД переходят после выбора целевой СУБД, именно она определяет особенности будущего программного продукта. С этого момента все остальные фазы проектирования и этапы жизненного цикла БД приобретают зависимость от СУБД.
• Физическое проектирование — это уточнение решения с учетом имеющихся в наличии разработчика технологий, возможности реализации и требуемой производительности. Только на заключительной фазе проектирования БД на смену так нелюбимой программистами бумажной деятельности приходит реальная работа на компьютере. Во время физического проектирования задачей проектировщика становится перенос логической модели на платформу целевой СУБД.
• С этой целью разработчик делает следующее:
- создает таблицы и связи между ними;
- назначает вторичные индексы таблиц;
- реализует бизнес-логику БД (в первую очередь, с помощью триггеров и хранимых процедур);
- определяет функциональные характеристики транзакций;
- разрабатывает представления;
- внедряет механизмы защиты (как минимум предусматривает авторизацию пользователей и назначает правила доступа к данным).
• Полученная БД тщательным образом документируется. Особенно важно определить пользовательские типы данных, описать таблицы и связи между ними, задать порядок поддержки бизнес-логики, установить назначение порядок вызова хранимых процедур и триггеров.
40.Инструментальные средства проектирования информационных систем. CASE-технология. Этапы процесса разработки. Методология функционального моделирования.
• Во многих случаях эффективную информационную систему не удается построить вручную. Это объясняется следующими причинами:
- не обеспечивается достаточно глубокий анализ требований к данным;
- большая длительность процесса структурирования;
- трудность учета и согласования изменений, сделанных в системе несколькими разработчиками;
- ограничения сроков на разработку системы;
- и т.д.
• Для преодоления сложностей начальных этапов разработки предназначен структурный анализ - метод исследования, которое начинается с общего обзора системы и затем детализуется, приобретая иерархическую структуру со все большим числом уровней. На каждом уровне рассматривается ограниченное число элементов (обычно от 3 до 6-8), каждый из которых в свою очередь может быть декомпозирован на составляющие детали на следующем уровне. При этом соблюдаются строгие формальные правила записи информации (обычно используются диаграммы различных типов).
• Такая технология получила название CASE (ComputerAidedSoftwareEngeneering - создание программного обеспечения с помощью компьютера).
• Основные черты CASE - технологии:
- использование методологии структурного проектирования "сверху-вниз“;
- разработка прикладной системы представляется в виде последовательных четко определенных этапов:
- поддержка всех этапов жизненного цикла информационной системы, начиная с самых общих описаний предметной области до получения и сопровождения готового программного продукта;
- поддержка репозитария, хранящего спецификации проекта информационной системы на всех этапах ее разработки;
- возможность одновременной работы с репозитарием многих разработчиков;
- автоматизация различных стандартных действий по проектированию и реализации приложения.
• Как правило, CASE-системы поддерживают следующие этапы процесса разработки:
- Моделирование и анализ деятельности пользователей в рамках предметной области (Методология функционального моделирования). Здесь осуществляется функциональная декомпозиция, определение иерархий (вложенности) функций, построение диаграмм потоков данных. Перечень информационных объектов, которыми манипулируют функции, передается на следующий этап проектирования.
- Концептуальное моделирование - создание модели "сущность-связь" на основе перечня объектов, полученного на предыдущем этапе. Здесь уточняются характеристики каждого объекта (атрибуты), устанавливаются связи между объектами.
- Реляционное моделирование - преобразование модели "сущность-связь" в соответствии с требованиями реляционной модели (реляционная модель допускает только бинарные связи, не разрешает существование атрибутов у связей, не поддерживает связи типа n : m).
- Генерация схемы базы данных. Результатом выполнения данного этапа является набор SQL-операторов, описывающих создание схемы базы данных (CREATE TABLE, CREATE INDEX,...), с учетом особенностей целевой СУБД.
• - Генерация прототипов программных модулей по иерархии функций и потокам данных. Для каждого модуля автоматически подготавливается описание используемых им фрагментов данных (таблицы, атрибуты, индексы), а также создаются заготовки экранных форм или отчетов.
• CASE-системы поддерживают следующие этапы процесса разработки:
- Функциональное моделирование;
- Концептуальное моделирование;
- Реляционное моделирование;
- Генерация схемы базы данных;
- Генерация прототипов программных модулей по иерархии функций и потокам данных.
· Методологии функционального моделирования
• Существуют различные методологии функционального моделирования, например:
- Диаграммы потоков данных (DFD - DataFlowDiagramm);
- Методология SADT (Structured Analisys and Design Technique);
- другие методологии.
• Методология функционального моделирования, позволяют выделить первичные информационные объекты, из которых затем строятся концептуальная и реляционная модели данных.
• Рассмотрение этих методов выходит за рамки данного курса.
• Приведем пример DFD-диаграммы для предприятия, строящего свою деятельность по принципу "изготовление на заказ".
DFD-диаграмма 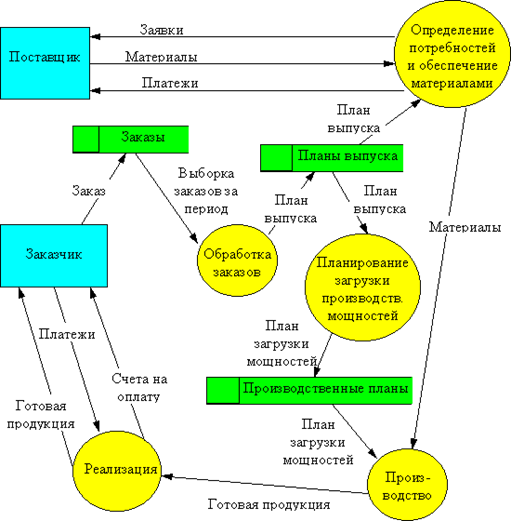
• IDEF0-модель (Методология SADT )
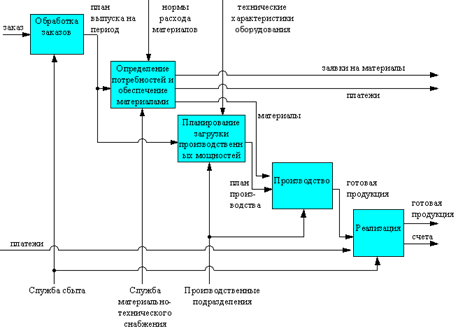
41.Концептуальное моделирование. Пример построения модели «сущность-связь».
• Методология функционального моделирования, позволяют выделить первичные информационные объекты, из которых затем строятся концептуальная и реляционная модели данных. Однако, в случае достаточно простой предметной области выделение информационных объектов можно произвести и без функционального анализа.
• Один из способов такого проектирования структуры реляционной базы данных описан в этом разделе. Далее будет рассмотрен другой способ проектирования реляционной структуры, основанный на декомпозиции универсального отношения.
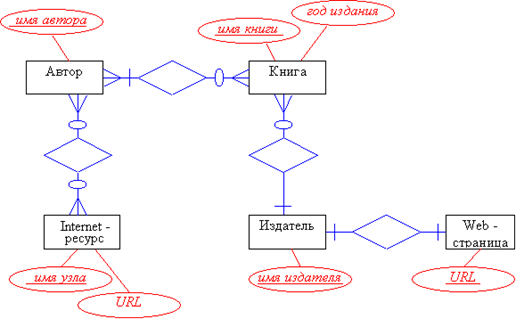
Пример построения модели "сущность-связь"
• Здесь мы рассмотрим пример, связанный с проектированием базы данных publucations, которая использовалась для практических занятий при изучении языка SQL.
• БД publications должна хранить сведения о печатных изданиях, а также ссылки на интересные ресурсы в Internet. И те и другие источники информации будут касаться одной темы, а именно "баз данных". Попробуем выделить интересующие нас сущности и определить связи между ними.
• Прежде всего займемся понятием "печатное издание". Что это такое? Мы знаем, что объект "печатное издание" воплощается в виде книги, которую можно полностью описать с помощью следующих характеристик: название, автор, год издания и издатель (издательство). Можно ли на основании этого ввести сущность "книга", а названные характеристики определить в качестве ее атрибутов?
• Прежде чем сделать это рассмотрим более внимательно отношения между книгой и ее характеристиками:
- Один автор может написать несколько книг, и, в то же время, одна книга может быть написана несколькими авторами. Следовательно, "книга" и "автор" в данном случае выступают как различные сущности, объединяемые связью N : M. Для того, чтобы определить класс принадлежности сущностей в связи, отметим, что книг без авторов не бывает, как и авторов без книг. Значит, каждая сущность должна иметь обязательный класс принадлежности (кардинальность связи(1,N) : (1,N)).
- Точно так же один издатель может издавать сразу несколько книг, но каждая конкретная книга издается только в одном месте. Следовательно, мы должны ввести сущность "издатель", ассоциируемую с "книгой" связью типа 1 : N. Т.к. каждая книга кем-то издана, класс принадлежности сущности "издатель" в данной связи будет (1,1), но в то же время мы допускаем хранение сведений об издательствах, чьих книг в нашей базе данных пока нет. Соответственно, класс принадлежности сущности "книга" в этой связи (0,N).
- По поводу характеристики книги "название" можно сказать следующее: как правило авторы, пишущие на одну тему, стараются придумывать для своих произведений оригинальные названия. Поэтому, можно уверенно предположить, что каждое название обязательно связано только с одной книгой (и каждая книга имеет только одно название). Следовательно, "название" нужно оставить в списке атрибутов "книги".
- Те же рассуждения можно повторить и для характеристики "год издания". Ее мы тоже оставим в списке атрибутов "книги".
• Таким образом, мы определили, что у сущности "книга" имеется два атрибута "название" и "год издания". Как уже говорилось, название, скорее всего, будет однозначно определять данную книгу, чего не скажешь о годе издания. Поэтому объявим ключом сущности атрибут "название" (или "имя_книги").
• Что касается всех возможных авторов, то нас интересует только одна их характеристика - имя. Поэтому, сущность "автор" имеет только один атрибут "имя_автора", который и является ключом.
• С сущностью "издатель" дел обстоит несколько сложнее. Практически все крупные издательства имеют сейчас собственные web-страницы, которые могут содержать информацию полезную для пользователей проектируемой базы данных. Поэтому, нужно рассмотреть две характеристики этого объекта: "имя_издателя" и "URL" (uniformresourcelocator - универсальный указатель ресурсов, с помощью которого в Internet определяется путь к web - странице). Ясно, что каждый издатель имеет уникальное имя и уникальный url, но прежде чем внести их в список атрибутов, вспомним, что наша база данных должна также содержать ссылки и на другие Internet-ресурсы. Возможно, при дальнейшем анализе возникнет необходимость во введении отдельной сущности "URL". Поэтому "имя_издателя" внесем в список атрибутов сущности "издатель", а "URL" будем считать атрибутом отдельной сущности "web - страница", ассоциируемой с "издателем" связью (1,1):(1,1).
• Теперь настала пора заняться объектом "ресурс Internet". Его мы можем описать с помощью понятий "имя ресурса", "url", "автор". Внимательно рассмотрев связи этих понятий с описываемым объектом, можно прийти к заключению, что "имя_ресурса" и "url" однозначно с ним связаны, т.е. являются атрибутами. В то же время, "автор" является отдельной сущностью (один ресурс может иметь много авторов, и один автор может быть создателем многих web - страниц). Т.к. мы уже ранее ввели сущность "автор" просто определим характеристики ее связи с сущностью "Internet-ресурс". Из сказанного выше следует, что эти сущности объединяются связью n : m, в то же время, автор какой-либо книги может не иметь собственной web - страницы, а авторы некоторых Internet ресурсов не указывают своих имен (т.е. можно формально сказать, что эти ресурсы не имеют авторов). Следовательно, класс принадлежности обеих сущностей будет необязательным.
• Прежде чем объявить нашу модель готовой, проверим еще раз определение каждой сущности. Внимательный анализ покажет, что построенная модель имеет несколько ошибок:
• - Сущность "автор" имеет обязательный класс принадлежности в связи с сущностью "книга". Это означает, что мы не сможем добавить в базу данных сведения о человеке, который создал собственный web - сайт, но не написал ни одной книги. Для того, что бы устранить это ограничение изменим класс принадлежности сущности "книга" в рассматриваемой связи "автор" - "книга" на необязательный.
• - При анализе объекта "издатель" мы предположили, что сущность "web-страница" может быть объединена с сущностью "Internet-ресурс". Однако, мы видим, что эти сущности имеют разный набор атрибутов, следовательно выполнить такое объединение нельзя. Вспомним, что в противном случае, предполагалось единственный атрибут сущности "web - страница" присоединить к атрибутам сущности "издатель". Тем не менее, не будем этого делать, в следующем разделе мы увидим, что с помощью правил порождения реляционных отношений из модели "сущность-связь" в том и в другом случае мы получим одинаковый результат.
• Готовая модель "сущность-связь" (концептуальная модель) представлена на следующем рисунке:
42.Правила порождения реляционных отношений из модели «сущность-связь». Пример применения правил. Логическая модель данных. Физическая модель данных.
• Для перехода от концептуальной модели к логической необходимо определить правила порождения реляционных отношений. Эти правила определяются для разных типов связи.
• Бинарные связи
| Тип связи | Пример связи | Правило построения отношений | Отношения |
| (1,1):(1,1) | 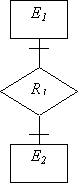
| Требуется только одно отношение. Первичным ключом данного отношения может быть ключ любой из сущностей. | 
|
• Бинарные связи
| (1,1):(0,1) (1,1):(0,n) | 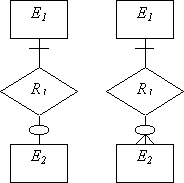
| Для каждой сущности создается свое отношение, при этом ключи сущностей служат ключами соответствующих отношений. Кроме того, ключ сущности с обязательным классом принадлежности добавляется в качестве внешнего ключа в отношение, созданное для сущности с необязательным классом принадлежности. | 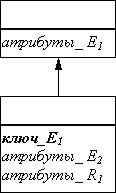
|
| (0,1):(0,1) | 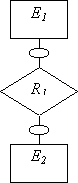
| Необходимо использовать три отношения: по одному для каждой сущности (ключи сущностей служат первичными ключами отношений) и одно отношение для связи. Отношение, выделенное для связи, имеет два атрибута - внешних ключа - по одному от каждой сущности. | 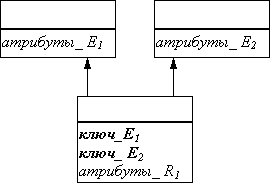
|
| (0,1):(0,n) (0,1):(1,n) | 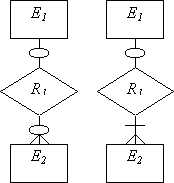
| Формируются три отношения: по одному для каждой сущности, причем ключ каждой сущности служит первичным ключом соответствующего отношения, и одно отношение для связи. Отношение, выделенное для связи, имеет два атрибута - внешних ключа - по одному от каждой сущности. |
|
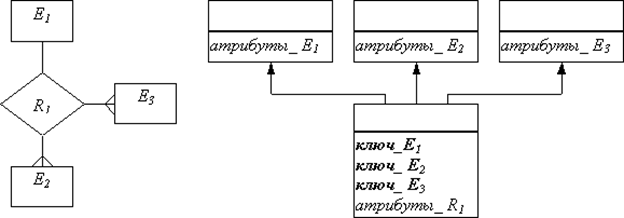
| n : m | 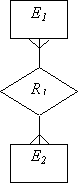
| В этом случае всегда используются три отношения: по одному для каждой сущности, причем ключ каждой сущности служит первичным ключом соответствующего отношения, и одно отношение для связи. Последнее отношение должно иметь среди своих атрибутов внешние ключи, по одному от каждой сущности. |
|
• N - арные связи
Общее правило: для представления n-сторонней связи всегда требуется n+1 отношение. Например, в случае трехсторонней связи необходимо использовать четыре отношения, по одному для каждой сущности (причем ключ сущности служит первичным ключом соответствующего отношения), и одно для связи. Отношение, порождаемой для связи, будет иметь среди своих атрибутов ключи от каждой сущности
• Иерархические связи
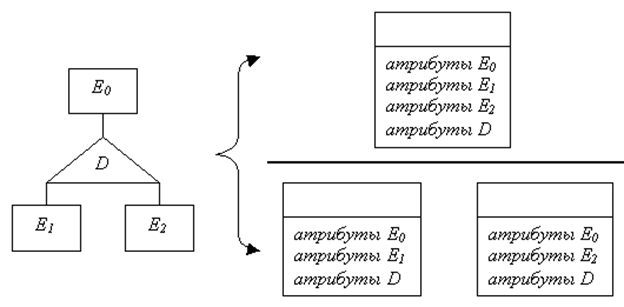
• К сожалению, надо признать, что реляционная модель мало подходит для отображения отношений наследования между сущностями (иерархических связей). Напомним, что в таких связях дочерние сущности наследуют все атрибуты родительской, и каждая из них обладает своим уникальным набором дополнительных атрибутов. Ранее приведен пример такой связи между родительской сущностью ЗАКАЗЧИК и дочерними - ЗАРУБЕЖНОЕ_ПРЕДПРИЯТИЕ и ОТЕЧЕСТВЕННОЕ_ПРЕДПРИЯТИЕ.
• В этом случае возможны два варианта построения реляционных отношений. Согласно первому для иерархической структуры создается одно отношение, которое содержит атрибуты связи и всех сущностей. Для приведенного ранее примера мы должны создать отношение
ЗАКАЗЧИК(НАЦ_ПРИНАДЛЕЖНОСТЬ, ВАЛЮТА, ЯЗЫК, ФОРМА_СОБСТВЕННОСТИ).
• Недостаток такого способа - для каждого кортежа часть атрибутов всегда будет неопределенна. Т.е. для отечественного предприятия всегда будут иметь значения NULL атрибуты ВАЛЮТА и ЯЗЫК, а для зарубежного атрибут ФОРМА_СОБСТВЕННОСТИ. Более того, этот факт является требованием целостности сущности, следовательно, для СУБД должны быть явно указаны несколько списков атрибутов (по числу дочерних сущностей), причем определенные значения могут быть присвоены только членам одного из них. Реляционная модель не поддерживает такого ограничения, на практике его реализуют с помощью триггеров.
• По второму способу генерируется по одному отношению для каждой дочерней сущности. Каждое из этих отношений включает атрибуты родительской сущности и связи кроме атрибутов - дискриминантов т.е. ЗАРУБЕЖНОЕ_ПРЕДПРИЯТИЕ(ВАЛЮТА, ЯЗЫК) и ОТЕЧЕСТВЕННОЕ_ПРЕДПРИЯТИЕ( ФОРМА_СОБСТВЕННОСТИ ). Недостатком данного способа является невозможность получить в одном запросе список всех заказчиков.
• Оба описанных способа представлены на рисунке:
• Эта реляционная структура называется логической моделью.
• Синим цветом на диаграмме выделены первичные ключи, красным - внешние. Отношения, созданные для представления связей, обозначены серыми прямоугольниками, для сущностей - желтыми прямоугольниками.
• Логическая модель рассмотренного примера 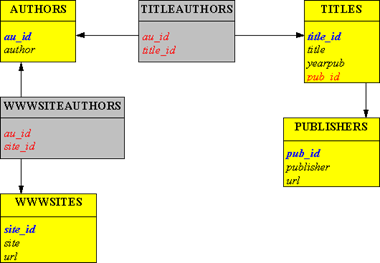
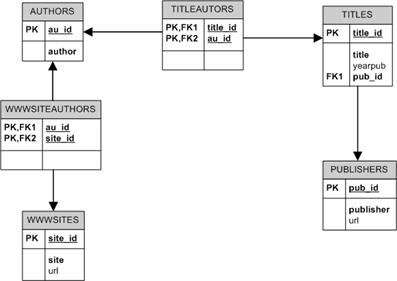
• Для отображения логической модели так же используются различные нотации и кроме того, в логическую модель могут включать разный набор элементов, характеризующих реляционные данные. Далее будут приведены ещё некоторые варианты отображения логической модели из рассмотренного примера.
• Логическая модель рассмотренного примера (построена в Visio)
• Для построения физической модели необходимо определить используемую СУБД. Для нашего примера выберем СУБД FireBird.
• Физическую модель отобразим с помощью утилиты IBExpert. (NN сокращение от NotNull).
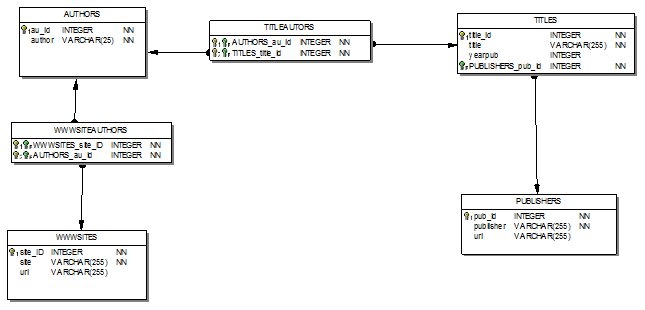
43.Проектирование реляционной базы данных на основе декомпозиции универсального отношения.
• Как мы видели из предыдущего материала, проектирование реляционной базы данных фактически сводится к устранению избыточных функциональных зависимостей (а при необходимости избыточных многозначных зависимостей и зависимостей по соединению) из предварительного набора отношений, полученного каким-либо способом (например, из диаграммы сущность связь). В том случае, когда проектируемая база данных сравнительно невелика (общее число атрибутов не превышает 20-30), предварительный набор отношений можно представить в виде одного отношения, называемого универсальным. В него включаются все представляющие интерес атрибуты.
• В качестве примера построим универсальное отношение для базы данных publications:
PUBLICATIONS(AUTHOR, TITLE, YEARPUB, PUBLISHER, PUBL_URL, SITE, SITE_URL)
•
здесь:
AUTHOR - имя автора;
TITLE - название книги;
YEARPUB - год издания книги;
PUBLISHER - наименование издательства;
PUBL_URL - ссылка на веб-сервер издательства;
SITE - наименование Internet-ресурса;
SITE_URL - указатель на Internet-ресурс.
• Функциональные зависимости, имеющиеся в полученном отношении, представлены на следующей схеме:
(1) TITLE --> YEARPUB
| (2) -----> PUBLISHER --> PUB_URL
(3) SITE ---> SITE_URL
• Для устранения избыточной функциональной зависимости (3) декомпозируем исходное отношение на два:
PUBLICATIONS(AUTHOR, TITLE, YEARPUB, PUBLISHER, PUBL_URL, SITE)
WWWSITES(SITE,SITE_URL)
• Приняв во внимание, что атрибут SITE требует типа данных "строка" и следовательно его использование в качестве первичного ключа не очень удобно, введем в отношении WWWSITES первичный ключ SITE_ID, основанный на целом типе данных. (Такая подстановка, хотя и ведет к избыточности с точки зрения теории, на практике позволяет ускорить обработку данных.Поэтому, в дальнейшем примем за правило заменять подобным образом строковые первичные ключи, не оговаривая это в каждом
отдельном случае).
• Теперь наши отношения примут вид:
PUBLICATIONS(AUTHOR, TITLE, YEARPUB, PUBLISHER, PUBL_URL, SITE_ID)
WWWSITES(SITE_ID,SITE,SITE_URL)
• Устраним функциональную зависимость (2):
PUBLICATIONS(AUTHOR, TITLE, YEARPUB, PUB_ID, SITE_ID) PUBLISHERS(PUB_ID,PUBLISHER,PUBL_URL) WWWSITES(SITE_ID,SITE,SITE_URL)
• Теперь мы имеем следующие избыточные функциональные зависимости в отношении PUBLICATIONS:
TITLE --> YEARPUB
| -----> PUB_ID
• Для их устранения необходимо вынести атрибуты TITLE, YEARPUB и PUB_ID в отдельное отношение:
• PUBLICATIONS(AUTHOR, TITLE_ID, SITE_ID) TITLES(TITLE_ID,TITLE,YEARPUB,PUB_ID) PUBLISHERS(PUB_ID,PUBLISHER,PUBL_URL) WWWSITES(SITE_ID,SITE,SITE_URL)
• Теперь наша база данных находится в третьей нормальной форме, однако мы видим, что полученный набор отношений не совпадает с набором, полученным из модели "сущность-связь". Для того, чтобы разобраться в причинах этого противоречия, рассмотрим отношение PUBLICATIONS вместе с его данными. Добавим автора, который имеет две книги и две web-страницы:
| AUTHOR | TITLE_ID | SITE_ID |
|--------|----------|---------|
| J.Doe | 1 | 1 |
| J.Doe | 2 | 1 |
| J.Doe | 1 | 2 |
| J.Doe | 2 | 2 |
• Из этой таблицы становится ясно, что в рассматриваемом отношении существует многозначная зависимость AUTHOR ->> TITLE_ID | SITE_ID. Для ее устранения приведем отношение к четвертой нормальной форме, для чего разобьем его на три.
PUBLICATIONS(AUTHOR,TITLE_ID,SITE_ID) ->
AUTHORS(AU_ID,AUTHOR) TITLEAUTHORS(TITLE_ID,AU_ID) WWWSITEAUTHORS(AU_ID,SITE_ID)
• Окончательно получим:
AUTHORS(AU_ID,AUTHOR) TITLEAUTHORS(TITLE_ID,AU_ID) WWWSITEAUTHORS(AU_ID,SITE_ID) TITLES(TITLE_ID,TITLE,YEARPUB,PUB_ID) PUBLISHERS(PUB_ID,PUBLISHER,PUBL_URL) WWWSITES(SITE_ID,SITE,SITE_URL)
• Теперь схема базы данных соответствует структуре, полученной другими способами. Анализ показывает, что избыточные функциональные зависимости в ней отсутствуют.
44.Создание приложений, работающих с базами данных при помощи языка SQL . Общие подходы. Специализированные библиотеки доступа. CLI -интерфейс уровня вызова.
• Почти все способы организации взаимодействия пользователя с базой данных, рассматриваемые ниже, основаны на модели "клиент-сервер". Т.е. предполагается, что каждое приложение обработки данных разбито, как минимум, на две части:
- клиента, который отвечает за организацию пользовательского интерфейса;
- сервер, который собственно хранит данные, обрабатывает запросы и посылает их результаты клиенту для отображения.
• При этом предполагается, что каждая часть приложения функционирует на отдельном компьютере, т.е. к выделенному серверу БД с помощью локальной сети подключены персональные компьютеры пользователей (клиенты). Это наиболее популярная сегодня схема организации вычислительной среды. Более подробно архитектура "клиент-сервер" и различные способы ее реализации будут обсуждаться далее.
• Язык SQL позволяет только манипулировать данными, но в нем отсутствуют средства создания экранного интерфейса, что необходимо для пользовательских приложений.
• Для создания этого интерфейса служат универсальные языки третьего поколения (C, C++, С#, Pascal) или проблемно-ориентированные языки четвертого поколения (xBase, Informix 4Gl, Progress, Jam,...). Эти языки содержат необходимые операторы ввода / вывода на экран, а также операторы структурного программирования (цикла, ветвления и т.д.). Также эти языки допускают определение структур, соответствующих записям таблиц обрабатываемой базы данных.
• Библиотека доступа - это, как правило, объектный файл, исходный код которого создан на универсальном языке типа C. Эта библиотека содержит набор функций, позволяющих пользовательскому приложению соединятся с базой данных, передавать запросы серверу и получать ответные данные. Типичный набор функций такой библиотеки (имена функций зависят от используемой библиотеки):
• DB_connect(char *имя_базы_данных, char *имя_пользователя, char *пароль) - устанавливает соединение с базой данной, возвращает указатель на структуру db, описывающую характеристики этого соединения;
• DB_exec(db, char *запрос) - выполнить запрос к базе данных, определяемой структурой db. Применяется для любых запросов кроме SELECT. Возвращает код выполнения запроса (0 - удачно, либо код ошибки);
• DB_select(db, char *запрос) - выполнить запрос на извлечение данных (SELECT). Возвращает структуру result, содержащую результаты выполнения запроса (реляционное отношение).
• DB_fetch(result) - извлечь следующую запись из структуры result.
• DB_close(db) - закрыть соединение с базой данных.
• Разумеется это минимальный набор функций для работы с базой данных. Обычно в библиотеке присутствуют также функции, позволяющие определить характеристики структуры result (число, порядок и имена столбцов, число строк, номер текущей строки), передвигаться по этой структуре не только вперед, но и назад (DB_next, DB_prev) и т.д. Пример программы, использующей библиотеку связи с базой данных: