
Оператор декартового произведения








Реляционная алгебра: ATIMESB
Оператор SQL:
SELECT A.Поле1, A.Поле2, …, B.Поле1, B.Поле2, …
FROM A, B;
или
SELECT A.Поле1, A.Поле2, …, B.Поле1, B.Поле2, …
FROM A CROSS JOIN B;
• Оператор проекции
Реляционная алгебра: A[X, Y,…, Z]
Оператор SQL:
SELECT DISTINCT X, Y, …, Z
FROM A;
• Оператор выборки
Реляционная алгебра: AWHEREc
Оператор SQL:
SELECT *
FROM A
WHERE c;
• Оператор объединения
Реляционная алгебра: AUNIONB
Оператор SQL:
SELECT *
FROM A
UNION
SELECT *
FROM B;
• Оператор вычитания
Реляционная алгебра:A MINUS B
Оператор SQL:
SELECT *
FROM A
EXCEPT
SELECT *
FROM B
• Реляционный оператор переименования RENAME выражается при помощи ключевого слова AS в списке отбираемых полей оператора SELECT. Таким образом, язык SQL является реляционно-полным.
• Остальные операторы реляционной алгебры (соединение, пересечение, деление) выражаются через примитивные, следовательно, могут быть выражены операторами SQL. Тем не менее, для практических целей приведем их.
• Оператор соединения
Реляционнаяалгебра: (ATIMESB) WHEREc
Оператор SQL:
SELECT A.Поле1, A.Поле2, …, B.Поле1, B.Поле2, …
FROM A, B
WHERE c;
или
SELECT A.Поле1, A.Поле2, …, B.Поле1, B.Поле2, …
FROM A CROSS JOIN B
WHERE c;
• Оператор пересечения
Реляционная алгебра: AINTERSECTB
Оператор SQL:
SELECT *
FROM A
INTERSECT
SELECT *
FROM B;
• Оператор деления
Реляционная алгебра: A( X, Y)DEVIDBYB( Y)
Оператор SQL:
SELECT DISTINCT A.X
FROM A
WHERE NOT EXIST
(SELECT *
FROM B
WHERE NOT EXIST
(SELECT *
FROM A A1
WHERE
A1.X = A.X AND
A1.Y = B.Y));
37.Язык SQL . Использование представлений ( View ). Изменение данных в представлениях. Хранимые процедуры. Триггеры .
• До сих пор мы говорили о таблицах, которые реально хранятся в базе данных. Это, так называемые, базовые таблицы (basetables). Существует другой вид таблиц, получивший название "представления" (иногда их называют"представляемые таблицы").
Определение:
Представление (view) - это таблица, содержимое которой берется из других таблиц посредством запроса. При этом новые копии данных не создаются
• Когда содержимое базовых таблиц меняется, СУБД автоматически перевыполняет запросы, создающие view, что приводит к соответствующим изменениям в представлениях.
• Представление определяется с помощью команды
CREATE VIEW <имя_представления> [<имя_столбца>,...] AS <запрос>
• При этом должны соблюдаться следующие ограничения:
- представление должно базироваться на единственном запросе (UNION не допустимо);
- выходные данные запроса, формирующего представление, должны быть не упорядочены (ORDER BY не допустимо).
• Другой пример:
SELECT author,count(title)
FROM books
GROUP BY author
• Из приведенного выше примера достаточно ясен смысл использования представлений. Если запросы типа "выбрать все книги данного автора с указанием издательств" выполняются достаточно часто, то создание представляемой таблицы books значительно сократит накладные расходы на выполнение соединения четырех базовых таблиц authors, titles, publishers и titleauthors. Кроме того, в представлении может быть представлена информация, явно не хранимая ни в одной из базовых таблиц. Например, один из столбцов представления может быть вычисляемым:
CREATE VIEW amount (publisher, books_count) AS
SELECT publishers.publisher, count(titles.title)
FROM titles,publishers
WHERE titles.pub_id=publishers.pub_id
GROUP BY publisher;
• Здесь использована еще одна, ранее не описанная, возможность SQL - присвоение новых имен столбцам представления. В приведенном примере число изданий, осуществленных каждым издателем, будет хранится в столбце с именем books_count. Заметим, что если мы хотим присвоить новые имена столбцам представления, нужно указывать имена для всех столбцов. Тип данных столбца представления и его нулевой статус всегда зависят от того, как он был определен в базовой таблице (таблицах).
• Запрос на выборку данных к представлению выглядит абсолютно аналогично запросу к любой другой таблице. Однако на изменение данных в представлении накладываются ограничения. Кратко о них можно сказать следующее:
- Если представление основано на одной таблице, изменения данных в нем допускаются. При этом изменяются данные в связанной с ним таблице.
- Если представление основано более чем на одной таблице, то изменения данных в нем не допускаются, т.к. в большинстве случаев СУБД не может правильно восстановить схему базовых таблиц из схемы представления.
Хранимые процедурымногие поставщики СУБД предлагают собственные процедурные расширения SQL (PL/SQL компании Oracle и т.д.). Эти расширения содержат логические операторы (IF ... THEN ... ELSE), операторы перехода по условию (SWITCH ... CASE ...), операторы циклов (FOR, WHILE, UNTIL) и операторы передачи управления в процедуры (CALL, RETURN). С помощью этих средств создаются функциональные модули, которые хранятся на сервере вместе с базой данных. Обычно такие модули называют хранимые процедуры (StoredProcedures) . Они могут быть вызваны с передачей параметров любым пользователем, имеющим на то соответствующие права.
• В некоторых системах хранимые процедуры могут быть реализованы и в виде внешних по отношению к СУБД модулей на языках общего назначения, таких как C или Pascal.
• Вызов созданной функции осуществляется из оператора SELECT (также, как вызываются функции агрегирования).
• ТриггерыДля каждой таблицы может быть назначена хранимая процедура без параметров, которая вызывается при выполнении оператора модификации этой таблицы (INSERT, UPDATE, DELETE). Такие хранимые процедуры получили название триггеров. Триггеры выполняются автоматически, независимо от того, что именно является причиной модификации данных - действия человека оператора или прикладной программы.
• "Усредненный" синтаксис оператора создания триггера:
CREATE TRIGGER <имя _триггера >
ON <имя _таблицы >
FOR { INSERT | UPDATE | DELETE }
[, INSERT | UPDATE | DELETE ] ...
AS <SQL_оператор>
• Ключевое слово ON задает имя таблицы, для которой определяется триггер, ключевое слово FOR указывает какая команда (команды) модификации данных активирует триггер. Операторы SQL после ключевого слова AS описывают действия, которые выполняет триггер и условия выполнения этих действий. Здесь может быть перечислено любое число операторов SQL, вызовов хранимых процедур и т.д. Использование триггеров очень удобно для выполнения операций контроля ограничений целостности.
38.Транзакции, блокировки и многопользовательский доступ к данным.
• Целостность БД может нарушаться и во время обработки одной команды SQL. Пусть выполняется операция увеличения зарплаты всех сотрудников фирмы на 20%:
UPDATE employers SET salary=salary*1.2
• При этом СУБД последовательно обрабатывает все записи, подлежащие обновлению, т.е. существует временной интервал, когда часть записей содержит новые значения, а часть - старые.
• Во избежание таких ситуаций в СУБД вводится понятие транзакции - атомарного действия над БД, переводящего ее из одного целостного состояния в другое целостное состояние.
• Другими словами, транзакция - это последовательность операций, которые должны быть или все выполнены или все не выполнены (все или ничего).
• Методом контроля за транзакциями является ведение журнала, в котором фиксируются все изменения, совершаемые транзакцией в БД. Если во время обработки транзакции происходит сбой, транзакция откатывается - из журнала восстанавливается состояние БД на момент начала транзакции.
• В СУБД различных поставщиков начало транзакции может задаваться явно (например, командой BEGIN TRANSACTION), либо предполагаться неявным (так определено в стандарте SQL), т.е. очередная транзакция открывается автоматически сразу же после удачного или неудачного завершения предыдущей. Для завершения транзакции обычно используют команды SQL:
- COMMIT - успешно завершить транзакцию;
- ROLLBACK - откатить транзакцию, т.е. вернуть БД в состояние, в котором она находилась на момент начала транзакции.
• Стандарт SQL определяет, что транзакция начинается с первого SQL-оператора, инициируемого пользователем или содержащегося в прикладной программе. Все последующие SQL-операторы составляют тело транзакции. Транзакция завершается одним из возможных способов:
- оператор COMMIT означает успешное завершение транзакции, все изменения, внесенные в базу данных делаются постоянными;
- оператор ROLLBACK прерывает транзакцию и отменяет все внесенные ею изменения;
- успешное завершение программы, инициировавшей транзакцию, означает успешное завершение транзакции (как использование COMMIT);
- ошибочное завершение программы прерывает транзакцию (как ROLLBACK).
• Грязное чтение (DirtyRead) - транзакция Т1 модифицировала некий элемент данных. После этого другая транзакция Т2 прочитала содержимое этого элемента данных до завершения транзакции Т1. Если Т1 завершается операцией ROLLBACK, то получается, что транзакция Т2 прочитала не существующие данные.
• Неповторяемое (размытое) чтение (Non-repeatableorFuzzyRead) - транзакция Т1 прочитала содержимое элемента данных. После этого другая транзакция Т2 модифицировала или удалила этот элемент. Если Т1 прочитает содержимое этого элемента заново, то она получит другое значение или обнаружит, что элемент данных больше не существует.
• Фантом (фиктивные элементы) (Phantom) - транзакция Т1 прочитала содержимое нескольких элементов данных, удовлетворяющих некому условию. После этого Т2 создала элемент данных, удовлетворяющий этому условию и зафиксировалась. Если Т1 повторит чтение с тем же условием, она получит другой набор данных.
• Как уже было сказано, ни одна из этих ситуаций не может возникнуть при последовательном выполнении транзакций. Отсюда возникло понятие сериализуемости (способности к упорядочению) параллельной обработки транзакций. Т.е. чередующееся (параллельное) выполнение заданного множества транзакций будет верным, если при его выполнении будет получен такой же результат, как и при последовательном выполнении тех же транзакций.
• Все описанные выше ситуации возникли только потому, что чередующееся выполнение транзакций Т1 и Т2 не было упорядочено, т.е. не было эквивалентно выполнению сначала транзакции Т1, а затем Т2, либо, наоборот, сначала транзакции Т2, а затем Т1.
• Принудительное упорядочение транзакций обеспечивается с помощью механизма блокировок. Суть этого механизма в следующем: если для выполнения некоторой транзакции необходимо, чтобы некоторый объект базы данных (кортеж, набор кортежей, отношение, набор отношений,…) не изменялся непредсказуемо и без ведома этой транзакции, такой объект блокируется. Основными видами блокировок являются:
- блокировка со взаимным доступом, называемая также S-блокировкой (от Sharedlocks) и блокировкой по чтению;
- монопольная блокировка (без взаимного доступа), называемая также X-блокировкой от (eXclusivelocks) или блокировкой по записи. Этот режим используется при операциях изменения, добавления и удаления объектов.
• При этом:
- если транзакция налагает на объект X-блокировку, то любой запрос другой транзакции с блокировкой этого объекта будет отвергнут;
- если транзакция налагает на объект S-блокировку, то:
– запрос со стороны другой транзакции с X-блокировокй на этот объект будет отвергнут;
– запрос со стороны другой транзакции с S-блокировокй этого объекта будет принят.
• Транзакция, запросившая доступ к объекту, уже захваченному другой транзакцией в несовместимом режиме, останавливается до тех пор, пока захват этого объекта не будет снят.
• Доказано, что сериализуемость транзакций (или, иначе, их изоляция) обеспечивается при использовании двухфазного протокола блокировок (2LP - Two-PhaseLocks), согласно которому все блокировки, произведенные транзакцией, снимаются только при ее завершении. Т.е. выполнение транзакции разбивается на две фазы: (1) - накопление блокировок, (2) - освобождение блокировок в результате фиксации или отката.
• К сожалению, применение механизма блокировки приводит к замедлению обработки транзакций, поскольку система вынуждена ожидать пока освободятся данные, захваченные конкурирующей транзакцией. Решить эту проблему можно за счет уменьшения фрагментов данных, захватываемых транзакцией
• В зависимости от захватываемых объектов различают несколько уровней блокировки:
- блокируется вся база данных - очевидно, этот вариант неприемлем, поскольку сводит многопользовательский режим работы к однопользовательскому;
- блокируются отдельные таблицы;
- блокируются страницы (страница - фрагмент таблицы размером обычно 2-4 Кб, единица выделения памяти для обработки данных системой);
- блокируются записи;
- блокируются отдельные поля.
• Современные СУБД, как правило, могут осуществлять блокировку на уровне записей или страниц.
• Язык SQL также предоставляет способ косвенного управления скоростью выполнения транзакций с помощью указания уровня изоляции транзакции. Под уровнем изоляции транзакции понимается возможность возникновения одной из описанных выше ошибочных ситуаций. В стандарте SQL определены 4 уровня изоляции:
| Уровень изоляции | Грязное чтение | Размытое чтение | Фантом |
| Незафиксированное чтение (READ UNCOMMITTED) | возможно | возможно | возможно |
| Зафиксированное чтение (READ COMMITED) | невозможно | возможно | возможно |
| Повторяемое чтение (REPEATABLE READ) | невозможно | невозможно | возможно |
| Сериализуемость (SERIALIZABLE) | невозможно | невозможно | невозможно |
• Для определения характеристик транзакции используется оператор
SET TRANSACTION <режим_доступа>, <уровень_изоляции>
• Список уровней изоляции приведен в таблице. Режим доступа по умолчанию используется READ WRITE (чтение запись), если задан уровень изоляции READ UNCOMMITED, то режим доступа должен быть READ ONLY (только чтение).
• Одним из наиболее серьезных недостатков метода сериализации транзакций на основе механизма блокировок является возможность возникновения тупиков (deadlocks) между транзакциями. Пусть, например, транзакция Т1 наложила монопольную блокировку на объект О1 и претендует на доступ к объекту О2, который уже монопольно заблокирован транзакцией Т2, ожидающей доступа к объекту О1. В этом случае ни одна из транзакций продолжаться не может, следовательно, блокировки объектов О1 и О2 никогда не будут сняты. Естественного выхода из такой ситуации не существует, поэтому тупиковые ситуации обнаруживаются и устраняются искусственно. При этом СУБД откатывает одну из транзакций, попавших в тупик ("жертвует" ею), что дает возможность продолжить выполнение другой транзакции.
39.Этапы проектирования данных. Трехуровневая схема (модель ANSI/SPARC). Концептуальное, логическое и физическоепроектирование.
• Предметная область - часть реального мира, подлежащая изучению с целью организации управления и, в конечном счете, автоматизации. Предметная область представляется множеством фрагментов, например, предприятие - цехами, дирекцией, бухгалтерией и т.д. Каждый фрагмент предметной области характеризуется множеством объектов и процессов, использующих объекты, а также множеством пользователей, характеризуемых различными взглядами на предметную область.
• Данные, используемые для описания предметной области, представляются в виде трехуровневой схемы (так называемая модель ANSI/SPARC):
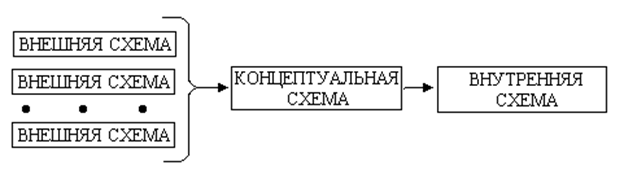
• Внешнее представление (внешняя схема) данных является совокупностью требований к данным со стороны некоторой конкретной функции, выполняемой пользователем.
• Концептуальная схема является полной совокупностью всех требований к данным, полученной из пользовательских представлений о реальном мире.
• Внутренняя схема - это сама база данных.
• Отсюда вытекают основные этапы, на которые разбивается процесс проектирования базы данных информационной системы:
1. Концептуальное проектирование;
2. Логическое проектирование;