
Информационная система требует создания в памяти ЭВМ динамически обновляемой модели внешнего мира с использованием единого хранилища - базы данных.








1. Для чего нужны базы данных? Основные термины и определения. Компоненты СУБД.
Информационная система требует создания в памяти ЭВМ динамически обновляемой модели внешнего мира с использованием единого хранилища - базы данных.
Предметная область - часть реального мира, подлежащая изучению с целью организации управления и автоматизации.
Обновляемая означает, что соответствие базы данных текущему состоянию предметной области обеспечивается не периодически, а в режиме реального времени.
Отличительной чертой баз данных следует считать то, что данные хранятся совместно с их описанием, а в прикладных программах описание данных не содержится. Независимые от программ пользователя данные обычно называются метаданными.
Система управления базой данных (СУБД) - важнейший компонент информационной системы. Для создания и управления информационной системой СУБД необходима в той же степени, как для разработки программы на алгоритмическом языке необходим транслятор.
СУБД содержит следующие компоненты:
- ядро, которое отвечает за управление данными во внешней и оперативной памяти и журнализацию;
- процессор языка базы данных, обеспечивающий оптимизацию запросов на извлечение и изменение данных и создание, как правило, машинно-независимого исполняемого внутреннего кода;
- подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД;
- сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы.
2. Системы, основанные на файлах. Свойства, недостатки и пути их устранения.
Рассмотрим в общих чертах идею построения систем, основанных на файлах.
Допустим, что мы планируем создать программу, хранящую сведения об именах и днях рождений наших сотрудников. Получивший задание программист поступает следующим образом.
Во-первых, он готовит структуру, подходящую для хранения указанных данных. Для этого программист просматривает список персонала и выясняет максимальное число символов в фамилии, имени и отчестве (допустим, это значения: 20, 15 и 15 байтов). Затем программист выделяет какое-то число байтов для хранения даты (пусть это будет 8 байтов). Узнав все необходимые размерности, разработчик описывает структуру непосредственно в коде программы.
Во-вторых, программист разрабатывает процедуры, осуществляющие основные операции по работе с файлом. Как минимум это добавление новой записи, редактирование, удаление и чтение записи. Ни одну из этих операций невозможно осуществить без знания размерности и состава полей исходной структуры.
При вставке новой строки в файл к нему следует добавить 20+15+15+8=58 байтов, причем процедура добавления должна знать, что фамилия начинается с 1-го байта, имя с 21-го и т. д. При просмотре файла необходимо осуществлять последовательные операции чтения порциями по 58 байтов, опять же процедура чтения должна иметь информацию, сколько байт отводится тому или иному полю. Операции редактирования и удаления не являются исключением из правил и также нуждаются в знаниях об исходной структуре. Эти сведения искать не нужно — все данные о составе полей нашей программе хорошо известны, ведь описание структуры спрятано внутри нее.
Недостатки систем:
- зависимость от данных
- несовместимость файлов
- разделение и изоляция файлов
- разрастание количества приложений
- избыточность данных
Пути устранения недостатков:
Во-первых, разработчики в принципе отказались от хранения физической структуры данных в коде приложений. Вместо этого описание данных стали выносить в отдельное хранилище, называемое системным каталогом (systemcatalog).Таким образом, во всех современных БД помимо собственно хранимых в них данных еще имеются метаданные.
Во-вторых, стали предпринимать активные попытки стандартизировать способы описания и хранения данных. Наличие стандарта, единого для всех разработчиков, значительно упростило доступ к данным.
В-третьих, возникла необходимость создания единого универсальногоязыка, позволяющего производить с данными наиболее важные операции: (вставки, редактирования, удаления и просмотра).
3. Основные типы данных и их классификация. Модели данных и их компоненты. Типы моделей СУБД.
Любые данные могут быть отнесены к одному из двух типов: основному (простому), форма представления которого определяется архитектурой ЭВМ, или сложному, конструируемому пользователем для решения конкретных задач.
Данные простого типа это - символы, числа и т.п. элементы, дальнейшее дробление которых не имеет смысла. Из элементарных данных формируются структуры (сложные типы) данных.
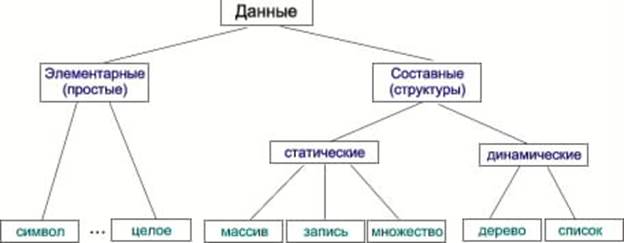
Классификация типов данных