
6 Управление внешними устройствами








6.1 Общие концепции
6.1.1 Архитектура организации управления внешними устройствами
Как[R36] отмечалось ранее, при организации взаимодействия работы процессора и внешних устройств различают два потока информации: поток управляющей информации (т.е. поток команд какому-либо устройству управления) и поток данных (поток информации, участвующей в обмене обычно между ОЗУ и внешним устройствами). Рассматривая историю вопроса, необходимо отметить, что управление внешними устройствами претерпело достаточно большие изменения.
Первой исторической моделью стало непосредственное управление центральным процессором внешними устройствами (Рис. 134.А), когда процессор на уровне микрокоманд полностью обеспечивал все действия по управлению внешними устройствами. Иными словами, поток управления полностью шел через ЦПУ, а наравне с ним через процессор шел и поток данных. Эта модель иллюстрирует синхронное управление: если начался обмен, то, пока он не закончится, процессор не продолжает вычисления (поскольку занят обменом).
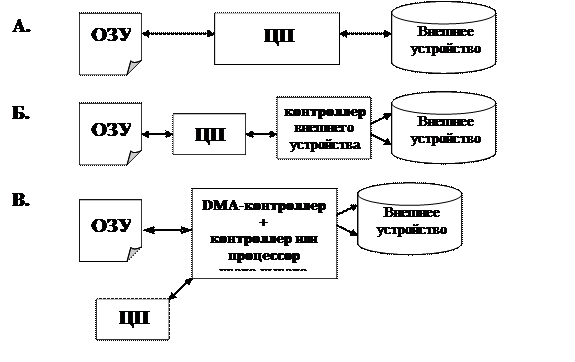
Рис. 134. Модели управления внешними устройствами: непосредственное (А), синхронное/асинхронное (Б), с использованием контроллера прямого доступа или процессора (канала) ввода-вывода.
Вторая модель, появившаяся с развитием вычислительной техники, связана с появлением специализированных контроллеров устройств, которые концептуально располагались между центральным процессором и соответствующими внешними устройствами (Рис. 134.Б). Контроллеры позволяли процессору работать с более высокоуровневыми операциями при управлении внешними устройствами. Таким образом, процессор частично освобождался от потока управления внешними устройствами за счет того, что вместо большого числа микрокоманд конкретного устройства он оперировал меньшим количеством более высокоуровневых операций. Но и эта модель оставалась синхронной.
Следующим этапом стало развитие предыдущей модели до асинхронной модели, осуществление которой стало возможным благодаря появлению аппарата прерываний. Данная модель позволяла запустить обмен для одного процесса, после этого поставить на счет другую задачу (или же текущий процесс может продолжить выполнять свои какие-то вычисления), а по окончании обмена, успешного или неуспешного, в системе возникнет прерывание, сигнализирующее возможность дальнейшего выполнения первого процесса. Но и эти две модели предполагали, что поток данных идет через процессор.
Кардинальным решением проблемы перемещения обработки потока данных из процессора стало использование появившихся контроллеров прямого доступа к памяти (или DMA-контроллеров, Direct Memory Access, Рис. 134.В). Процессор генерировал последовательность управляющих команд, указывая координаты в оперативной памяти, куда надо положить или откуда взять данные, а DMA-контроллер занимался перемещением данных между ОЗУ и внешним устройством. Таким образом, поток данных шел в обход процессора.
И, наконец, можно отметить последнюю модель, основанную на том, что управление внешними устройствами осуществляется с использованием специализированным процессором (или даже специализированных компьютеров) или каналов ввода-вывода. Данная модель подразумевает снижение нагрузки на центральный процессор с точки зрения обработки потока управления: ЦПУ теперь оперирует макрокомандами, являющимися функционально-емкими. Решение задачи осуществления непосредственного обмена, а также решение всех связанных с обменом вопросов (в т.ч. оптимизация операций обмена, например, за счет использования аппаратной буферизации в процессоре ввода-вывода) ложится «на плечи» специализированного процессора.
6.1.2 Программное управление внешними устройствами
Рассмотрим архитектуру программного управления внешними устройствами, которую можно представить в виде некоторой иерархии (Рис. 135). В основании лежит аппаратура, а далее следуют программные уровни, начиная с уровня программ обработки прерываний, затем — драйверы физических устройств, а на вершине иерархии лежит уровень драйверов логических устройств, причем каждый уровень строится на основании нижележащего уровня.

Рис. 135. Иерархия архитектуры программного управления внешними устройствами.
Можно выделить следующие цели программного управления устройствами. Во-первых, это унификация программных интерфейсов доступа к внешним устройствам. Иными словами, это стандартизация правил использования различных устройств. Преследуя данную цель, мы абстрагируемся от аппаратных характеристик обмена. Если данная цель достигнута, то, например, пользователь, пожелавший распечатать текстовый файл, не надо будет заботиться об организации управления конкретным печатающим устройством, ему достаточно воспользоваться некоторым общим программным интерфейсом.
Следующая цель — это обеспечение конкретной модели синхронизации при выполнении обмена (синхронный или асинхронный обмен). Отметим здесь, что, несмотря на то, что синхронный вид обмена появился хронологически одним из первых, он остается актуальным и по сей день. Таким образом, ставится цель поддерживать оба вида обмена, а выбор конкретного типа зависит от пользователя.
Еще одной целью является выявление и локализация ошибок, а также устранение их последствий. Для любой системы справедливо, что чем более она сложна, тем больше статистически в ней возникает сбоев. Соответственно, система должна быть организована таким образом, чтобы она могла выявить момент появления сбоя и стараться обработать эту сбойную ситуацию: либо самостоятельно ее обойти, либо известить пользователя.
Следующая цель — буферизация обмена — связана с различной производительностью основных компонентов системы. Заведомо известно, что любое внешнее устройство работает медленнее центральной части компьютера, и, соответственно, стоит проблема сглаживания разброса производительностей различных компонент системы. Причем, если речь идет об устройствах, не являющихся устройствами оперативного доступа, т.е. не является устройством, к которому идет массовое обращение на обмен от процессов, то для таких устройств проблема сглаживания отодвигается на второй план. Например, если это медленное устройство печати, то для него особо не требуется реализации буфера, а если дело касается магнитного диска, рассчитанного для использования в качестве массового устройства, то тут операции обмена должны обрабатываться по возможности быстро. Решением указанной задачи является организация разного рода кэширования в системе.
Также необходимо отметить такую цель, как обеспечение стратегии доступа к устройству (распределенный или монопольный доступ). Во время рассмотрения файловых систем ОС Unix говорилось, что один и тот же файл может быть доступен через множество файловых дескрипторов, которые могут быть распределены между различными процессами, т.е. файл может быть многократно открыт в системе, и система позволяет организовывать распределенный доступ к его информации. Система позволяет организовать управление этим доступом и синхронизацию. Система также позволяет организовать и монопольный доступ к устройству.
И, наконец, последней целью, которую стоит отметить, является планирование выполнения операций обмена. Это важная проблема, поскольку от качества планирования может во многом зависеть эффективность функционирования вычислительной системы. Неправильно организованное планирование очереди заказов на обмен может привести к деградации системы, связанной, к примеру, с началом голодания каких-то процессов и, соответственно, зависания их функциональности.
6.1.3 Планирование дисковых обменов
Рассмотрим различные стратегии организации планирования дисковых обменов. При этом преследуется цель проиллюстрировать то многообразие подходов к решению данной проблемы, которые имеют место в мире, с краткими результатами и выводами.
Будем рассматривать некоторое дисковое устройство, обмен с которым осуществляется дорожками (т.е. происходит обращение и считывание соответствующей дорожки). Пускай имеется очередь запросов к следующим дорожкам: 4, 40, 11, 35, 7, 14. Изначально головка дискового устройства позиционирована на 15-ой дорожке. Замети, что время на обмен складывается из трех компонентов: выход головки на позицию, вращение диска и непосредственно обмен. Для оценки эффективности алгоритмов будем подсчитывать суммарный путь, выраженный в количестве дорожек, который пройдет головка для осуществления всех запросов на обмен из указанной очереди.
Первая стратегия, которую мы рассмотрим, — стратегия FIFO (First In First Out). Эта стратегия основывается лишь на порядке появления запроса в очереди. В нашем случае (Рис. 136) головка сначала начинает двигаться с 15 дорожки на 4, потом на 40 и т.д. После обработки всей указанной очереди суммарная длина пути составляет 135 дорожек, что в среднем можно охарактеризовать, как 22,5 дорожки на один обмен.

Рис. 136. Планирование дисковых обменов. Модель FIFO.
Альтернативой FIFO является стратегия LIFO (Last In First Out). Этот алгоритм в нашем случае имеет примерно те же характеристики, что и FIFO. Но данная стратегия оказывается полезной, когда поступают цепочки связанных обменов: процесс считывает информацию, изменяет ее и обратно записывает. Для таких процессов эффективнее всего будет выполнение именно цепочки обмена, иначе после считывания он не сможет продолжаться, т.к. будет ожидать записи (Рис. 137).

Рис. 137. Планирование дисковых обменов. Модель LIFO.
Следующая стратегия — SSTF (Shortest Service Time First) — основана на «жадном» алгоритме. Термин «жадного» алгоритма обычно применяется к итерационным алгоритмам для выделения среди них класса алгоритмов, которые на каждой итерации ищут наилучшее решение. Применительно к нашей задаче данный алгоритм на каждом шаге осуществляет поиск в очереди запросов номер дорожки, требующей минимального перемещения головки диска. В итоге в нашем примере получаются достаточно хорошие результаты, но данный алгоритм имеет существенный недостаток: ему присуща проблема голодания крайних дорожек (Рис. 138).

Рис. 138. Планирование дисковых обменов. Модель SSTF.
Еще один алгоритм — алгоритм, основанный на приоритетах процессов (PRI). Данный алгоритм подразумевает, что каждому процессу присваивается некоторый приоритет, тогда в заказе на обмен присутствует еще и приоритет. И, соответственно, очередь запросов обрабатывается согласно приоритетам. Здесь встает серьезная проблема корректной организации выдачи приоритета, иначе будут возникать случаи голодания низкоприоритетных процессов.
Следующий алгоритм, который мы рассмотрим, — «лифтовый» алгоритм, или алгоритм сканирования (SCAN). Данный алгоритм основан на том, что головка диска перемещается сначала в одну сторону до границы диска, выбирая каждый раз из очереди запрос с номером обозреваемой головкой дорожки, а затем — в другую. Тогда заведомо известно, что для любого набора запросов потребуется перемещений не больше удвоенного числа дорожек на диске. Данный алгоритм может приводить к деградации системы вследствие голодания некоторых процессов в случае, когда идет интенсивный обмен с некоторой локальной областью диска (Рис. 139).

Рис. 139. Планирование дисковых обменов. Модель SCAN.
Некоторой альтернативой является алгоритм циклического сканирования (С-SCAN). Этот алгоритм основан на том, что сканирование всегда происходит в одном направлении. В очереди запросов ищется запрос с минимальным (или максимальным) номером, головка передвигается к дорожке с этим номером, а затем за один проход по диску обрабатывается вся очередь запросов. Но проблемы остаются те же самые, что и для алгоритма сканирования (Рис. 140).

Рис. 140. Планирование дисковых обменов. Модель C-SCAN.
Для решения проблемы зависания при интенсивном обмене с локальной областью диска применяются многошаговый алгоритм (N- step- SCAN). В этом случае очередь запросов каким-либо образом (способ разделения может быть произвольным, в частности, по локализации запросов, по времени поступления и т.д.) делится на N подочередей, затем по какой-либо стратегии выбирается очередь, которая будет обрабатываться (например, по порядку их формирования), и начинается ее обработка. Во время обработки очереди блокируется попадание новых запросов в эту очередь (тогда эти запросы могут сформировать новую очередь), другие очереди могут получать заявки. Сама обработка очереди может осуществляться, например, по алгоритму сканирования. Данный алгоритм «уходит» от проблемы голодания.
Итак, мы проиллюстрировали некоторые стратегии организации планирования дисковых обменов. Еще раз отметим, что эти модель очень упрощенные: они основаны на использовании минимальной информации о заказе на обмен. Реальные системы, реальные очереди содержат не одиночные заказы на обмен, а целые цепочки заказов на обмен, которые произвольным образом обрабатывать нельзя. Например, если идет заказ на считывание данных, потом процесс их изменяет, а затем обратно записывает, то эти считывание и запись могут следовать лишь в одном порядке.
6.1.4 RAID-системы. Уровни RAID
Аббревиатура RAID может раскрываться двумя способами. RAID — Redundant Array of Independent (Inexpensive) Disks, или избыточный массив независимых (недорогих) дисков. На сегодняшний день обе расшифровки не совсем корректны. Понятие недорогих дисков родилось в те времена, когда большие быстрые диски стоили достаточно дорого, и перед многими организациями, желающими сэкономить, стояла задача построения такой организации набора более дешевых и менее быстродействующих и емких дисков, чтобы их суммарная эффективность не уступала одному богатому диску. На сегодняшний день цены между различными по характеристикам дисками более сглажены, но бывают и исключения, когда новейший диск чуть ли не на порядок опережает по цене своих предыдущих собратьев. Что касается независимости дисков, то она соблюдается не всегда.
RAID-система — это совокупность физических дисковых устройств, которая представляется в операционной системе как одно устройство, имеющее возможность организации параллельных обменов. Помимо этого образуется избыточная информация, используемая для контроля и восстановления информации, хранимой на этих дисках.
RAID-системы предполагают размещение на разных устройствах, составляющих RAID-массив, порции данных фиксированного размера, называемые полосами, которым осуществляется обмен в данных системах. Размер полосы зависит от конкретного устройства (при обсуждении файловых систем была упомянута иерархия различных блоков, так RAID добавляет в эту иерархию дополнительный уровень — уровень полос RAID).
На сегодняшний день выделяют семь моделей RAID-систем (от нулевой модели до шестой). Рассмотрим их по порядку.
RAID 0 (Рис. 141). В этой модели полоса соизмерима с дисковыми блоками, соседние полосы находятся на разных устройствах. Организация RAID нулевого уровня чем-то напоминает расслоение оперативной памяти. С каждым диском обмен может происходить параллельно. Каждое устройство независимое, т.е. движение головок в каждом из устройств не синхронизировано. Данная модель не хранит избыточную информацию, поэтому в ней могут храниться данные объемом, равным суммарной емкости дисков, при этом за счет параллельного выполнения обменов доступ к информации становится более быстрым.

Рис. 141. RAID 0.
RAID 1, или система зеркалирования (Рис. 142). Предполагается наличие двух комплектов дисков. При записи информации она сохраняется на соответствующем диске и на диске-дублере. При чтении информации запрос направляется лишь одному из дисков. К диску-дублеру происходит обращение при утере информации на первом экземпляре диска.

Рис. 142. RAID 1.
Данная модель является достаточно дорогой, причем дороговизна заключается не в непосредственной стоимости дисков (если предположить, что средняя цена диска 100 USD, то организация на покупку 10 основных дисков и 10 дисков-дублеров должна потратить порядка 2000 USD, что не является большой суммой для юридического лица). Цена вопроса встает при обслуживании данной системы: 20 дисков занимают много места, потребляют довольно приличную мощность и выделяют много тепла. К этому можно добавить расходы на обеспечение резервного питания: чтобы эти 20 дисков не отключались при перебоях с электропитанием необходимо закупить источники бесперебойного питания с очень емкими аккумуляторами.
Отметим, что модели RAID нулевого и первого уровней могут реализовываться программным способом.
Следующие две модели (RAID 2, Рис. 143, и RAID 3, Рис. 144) — это модели с т.н. синхронизированными головками, что, в свою очередь, означает, что в массиве используются не независимые устройства, а специальным образом синхронизированные. Эти модели обычно имеют полосы незначительного размера (например, байт или слово). Данные модели содержат избыточную информацию, позволяющие восстановить данные в случае выхода из строя одного из устройств. В частности, RAID 2 использует коды Хэмминга (т.е. коды, исправляющие одну ошибку и выявляющие двойные ошибки). Модель RAID 3 более проста, она основана на четности с чередующимися битами. Для этого один из дисков назначается для хранения избыточной информации — полос, дополняющих до четности соответствующие полосы на других дисках (т.е., по сути, в каждой позиции должно быть суммарное число единиц на всех дисках должно быть четным). И в том, и в другом случае при сбое одного из устройства за счет избыточной информации можно восстановить потерянные данные.
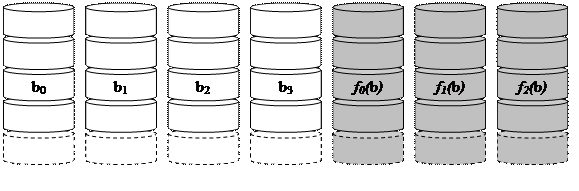
Рис. 143. RAID 2. Избыточность с кодами Хэмминга (Hamming, исправляет одинарные и выявляет двойные ошибки).
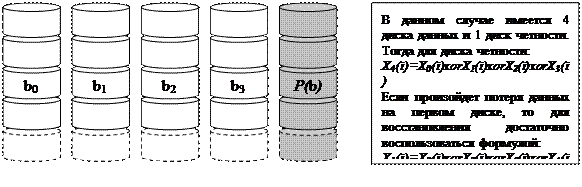
Рис. 144. RAID 3. Четность с чередующимися битами.
RAID 4 является упрощением RAID 3 (Рис. 145). Это массив несинхронизированных устройств. Соответственно, появляется проблема поддержания в корректном состоянии диска четности. Для этого каждый раз происходит пересчет по соответствующей формуле.
Модели RAID 5 (Рис. 146) и RAID 6 (Рис. 147) спроектированы так, чтобы повысить надежность системы по сравнению с RAID 3 и 4 уровней. Опасно оказывается хранить важную информацию (в данном случае полосы четности) на одном носителе, т.к. при каждой записи происходит всегда обращение к одному и тому же устройству, что может спровоцировать его скорейший выход из строя. Надежнее разнести служебную информацию по разным дискам. Соответственно, RAID 5 распределяет избыточную информацию по дискам циклическим образом, а RAID 6 использует двухуровневую избыточную информацию (которая также разнесена по дискам).

Рис. 145. RAID 4.
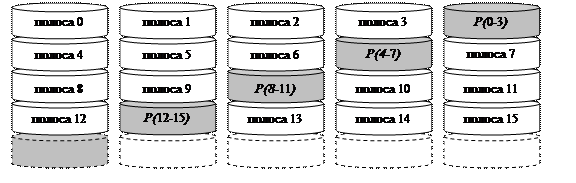
Рис. 146. RAID 5. Распределенная четность (циклическое распределение четности).
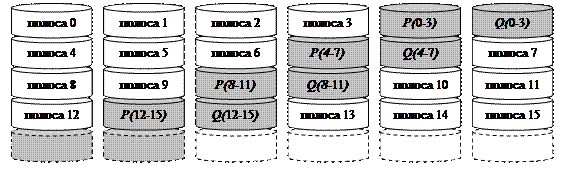
Рис. 147. RAID 6. Двойная избыточность (циклическое распределение четности с использованием двух схем контроля; требуется N+2 диска).