
3 Реализация межпроцессного взаимодействия в ОС Unix








3.1 Базовые средства реализации взаимодействия процессов в ОС Unix
Сразу[R16] необходимо отметить, что во всех иллюстрациях организаций взаимодействия процессов будем рассматривать полновесные процессы, т.е. те «классические» процессы, которые представляются в виде обрабатываемой в системе программы, обладающей эксклюзивными правами на оперативную память, а также правами на некоторые дополнительные ресурсы.
Если посмотреть на проблемы взаимодействия процессов, то можно выделить две группы взаимодействия. Первая группа — это взаимодействие процессов, функционирующих под управлением одной ОС на одной локальной ЭВМ. Вторая группа взаимодействия — это взаимодействие в пределах сети. В зависимости от того, к какой группе относится тот или иной механизм, он будет обладать соответствующими свойствами и особенностями.
Рассмотрим взаимодействие в рамках локальной ЭВМ (одной ОС). Первым делом встает общая для обеих упомянутых групп проблема именования взаимодействующих процессов, которая заключается в ответе на вопрос, как, т.е. посредством каких механизмов, взаимодействующие процессы смогут «найти друг друга». В рамках взаимодействия внутри одной ОС можно выделить две основных группы решений данной задачи (Рис. 87).

Рис. 87. Способы организации взаимодействия процессов.
Первая группа способов основана на взаимодействии родственных процессов. При взаимодействии родственных процессов, т.е. процессов, связанных некоторой иерархией родства, ОС обычно предоставляет возможность наследования некоторых характеристик родительских процессов дочерними процессами. И именно за счет наследования различных характеристик возможно реализовать то самое именование. К примеру, в ОС Unix можно передавать по наследству от отца сыну дескрипторы открытых файлов. В данном случае именование будет неявным, поскольку не указываются непосредственно имена процессов.
Другим решением в рамках данной группы взаимодействующих родственных процессов является взаимодействие по цепочке предок–потомок, причем известно, кто из процессов является предком, а кто — потомком. В этом случае существует возможность процессу-предку обращаться к своему потомку посредством явного именования. В качестве имени, например, может выступать идентификатор процесса (PID). А потомок, зная имя предка, может также к нему обратиться.
Так или иначе, но данная группа реализаций взаимодействия родственных процессов основана на том факте, что некоторая необходимая для взаимодействия информация может быть передана по наследству.
Следующая группа — это взаимодействие произвольных процессов в рамках одной локальной машины. Очевидно, что в этом случае отсутствует факт наследования, и поэтому для решения проблемы именования логично использовать следующие механизмы. Во-первых, прямое именование, когда процессы для указания своих партнеров по взаимодействию используют уникальные имена партнеров (например, используя идентификаторы процессов или же по-иному: PID привязывается к некоторому новому уникальному имени, и обращение при взаимодействии происходит с использованием системы этих новых имен). Во-вторых, это может быть взаимодействие посредством общего ресурса. Но в этом случае встает проблема именования этих общих ресурсов.
Итак, мы рассмотрели модели взаимодействия процессов в рамках локальной машины. ОС Unix предоставляет целый спектр механизмов взаимодействия по каждой из указанных групп. В частности, для взаимодействия родственных процессов могут быть использованы такие механизмы, как неименованные каналы и трассировка.
Неименованный канал — это некоторый ресурс, наследуемый сыновьями процессами, причем этот механизм может быть использован для организации взаимодействия произвольных родственников (т.е., условно говоря, можно организовать неименованный канал между «сыном» и его «племянником», и т.п.).
Неименованные каналы — это пример симметричного взаимодействия, т.е., несмотря на то, что ресурс неименованного канала передается по наследству, взаимодействующие процессы в общем случае, абстрагируясь от семантики программы, имеют идентичные права.
Другой моделью взаимодействия является несимметричная модель, которую иногда называют модель «главный–подчиненный». В этом случае среди взаимодействующих процессов можно выделить процессы, имеющие больше полномочий, чем у остальных. Соответственно, у главного процесса (или процессов) есть целый спектр механизмов управления подчиненными процессами.
Для организации взаимодействия произвольных процессов система предоставляет целый спектр средств взаимодействия, среди которых преобладают средства симметричного взаимодействия (т.е. процессам при взаимодействии предоставляются равные права).
Именованные каналы — это ресурс, принадлежащий взаимодействующим процессам, посредством которого осуществляется взаимодействие. При этом не обязательно знать имена процессов-партнеров по взаимодействию.
Передача сигналов — это средство оказания воздействия одним процессом на другой процесс в общем случае (в частности, одним из процессов в этом виде взаимодействия может выступать процесс операционной системы). При этом используются непосредственные имена процессов.
Система IPC (Inter-Process Communication), предоставляющая взаимодействующим процессам общие разделяемые ресурсы, среди которых ниже будут рассмотрены общая память, массив семафоров и очередь сообщений, посредством которых осуществляется взаимодействие процессов. Отметим, что система IPC является некоторым альтернативным решением именованным каналам.
Аппарат сокетов — унифицированное средство организации взаимодействия. На сегодняшний момент сокеты — это не столько средства ОС Unix, сколько стандартизированные средства межмашинного взаимодействия. В аппарате сокетов именование осуществляется посредством связывания конкретного процесса (его идентификатора PID) с конкретным сокетом, через который и происходит взаимодействие.
Итак, мы перечислили некоторые средства взаимодействия процессов в рамках одной локальной машины (точнее сказать, в рамках ОС Unix), но это лишь малая часть существующих в настоящий момент средств организации взаимодействия.
Второй блок организации взаимодействия — это взаимодействие в пределах сети. В данном случае ставится задача организовать взаимодействие процессов, находящихся на разных машинах под управлением различных операционных систем. Та же проблема именования процессов в рамках сети решается достаточно просто.
Пускай у нас есть две машины, имеющие сетевые имена A и B, на которых работают соответственно процессы P1 и P2. Тогда, чтобы именовать процесс в сети, достаточно использовать связку «сетевой имя машины + имя процесса внутри этой машины». В нашем примере это будут пары (A–P1) и (B–P2).
Но тут встает следующая проблема. В рамках сети могут взаимодействовать машины, находящиеся под управлением операционных систем различного типа (т.е. в сети могут оказаться Windows-машины, FreeBSD-машины, Macintosh-машины и пр.). И система именования должна быть построена так, чтобы обеспечить возможность взаимодействия произвольных машин, т.е. это должно быть стандартизованным (унифицированным) средством. На сегодняшний день наиболее распространенными являются аппарат сокетов и система MPI.
Аппарат сокетов можно рассматривать как базовое средство организации взаимодействия. Этот механизм лежит на уровне протоколов взаимодействия. Он предполагает для обеспечения взаимодействия использование т.н. сокетов, и взаимодействие осуществляется между сокетами. Конкретная топология взаимодействующих процессов зависит от задачи (можно организовать общение одного сокета со многими, можно установить связь один–к–одному и т.д.). В конечном счете, именование сокетов также зависит от топологии: в одном случае необходимо знать точные имена взаимодействующих сокетов, в другом случае имена некоторых сокетов могут быть произвольными (например, в случае клиент–серверной архитектуры обычно имена клиентских сокетов могут быть любыми).
Система MPI (интерфейс передачи сообщений) также является достаточно распространенным средством организации взаимодействия в рамках сети. Эта система иллюстрирует механизм передачи сообщений, речь о котором шла выше (см. раздел 2.4.2). Система MPI может работать на локальной машине, в многопроцессорных системах с распределенной памятью (т.е. может работать в кластерных системах), в сети в целом (в частности, в т.н. GRID-системах).
Далее речь пойдет о конкретных средствах взаимодействия процессов (как в ОС Unix, так и в некоторых других).
3.1.1 Сигналы
В ОС Unix присутствует т.н. аппарат сигналов, позволяющий одним процессам оказывать воздействия на другие процессы. Сигналы могут рассматриваться как средство уведомления процесса о некотором наступившем в системе событии. В некотором смысле аппарат сигналов имеет аналогию с аппаратом прерываний, поскольку последний есть также уведомление системы о том, что в ней произошло некоторое событие. Прерывание вызывает определенную детерминированную последовательность действий системы, точно так же приход сигнала в процесс вызывает в нем определенную последовательность действий.
Инициатором отправки сигнала процессу может быть как процесс или ОС. Для иллюстрации приведем следующий пример. Пускай в ходе выполнения некоторого процесса произошло деление на ноль, вследствие чего в системе происходит прерывание, управление передается операционной системе. ОС «видит», что это прерывание «деление на ноль», и отправляет сигнал процессу, в теле которого произошла данная ошибка. Дальше процесс реагирует на получение сигнала, но об этом чуть позже.
Инициатором посылки сигнала может выступать другой процесс. В качестве примера можно привести следующую ситуацию. Пользователь ОС Unix запустил некоторый процесс, который в некоторый момент времени зацикливается. Чтобы снять этот процесс со счета, пользователь может послать ему сигнал об уничтожении (например, нажав на клавиатуре комбинацию клавиш Ctrl+C, а это есть команда интерпретатору команд послать код сигнала SIGINT). В данном случае процесс интерпретатора команд пошлет сигнал пользовательскому процессу.
Аппарат сигналов является механизмом асинхронного взаимодействия, момент прихода сигнала процессу заранее неизвестен. Так же, как и аппарат прерываний, имеющий фиксированное количество различных прерываний, Unix-системы имеют фиксированный набор сигналов. Перечень сигналов, реализованных в конкретной операционной системе, обычно находится в файле signal.h. В этом файле перечисляется набор пар «имя сигнала — его целочисленное значение».
При получении процессом сигнала возможны 3 типа реакции на него. Во-первых, это обработка сигнала по умолчанию. В подавляющем большинстве случаев обработка сигнала по умолчанию означает завершение процесса. В этом случае системным кодом завершения процесса становится номер пришедшего сигнала.
Во-вторых, процесс может перехватывать обработку пришедшего сигнала. Если процесс получает сигнал, то вызывается функция, принадлежащая телу процесса, которая была специальным образом зарегистрирована в системе как обработчик сигнала. Следует отметить, что часть реализованных в ОС сигналов можно перехватывать, а часть сигналов перехватывать нельзя. Примером неперехватываемого сигнала может служить сигнал SIGKILL (код 9), предназначенный для безусловного уничтожения процесса. А упомянутый выше сигнал SIGINT (код 2) перехватить можно.
В-третьих, сигналы можно игнорировать, т.е. приход некоторых сигналов процесс может проигнорировать. Как и в случае с перехватываемыми сигналами, часть сигналов можно игнорировать (например, SIGINT), а часть — нет (например, SIGKILL).
Для отправки сигнала в ОС Unix имеется системный вызов kill().
#include <sys/types.h>
#include <signal.h>
int kill(pid_t pid, int sig);
В данной функции первый параметр (pid) — идентификатор процесса, которому необходимо послать сигнал, а второй параметр (sig) — номер передаваемого сигнала. Если первый параметр отличен от нуля, то он трактуется как идентификатор процесса-адресата; если же он нулевой, то сигнал посылается всем процессам данной группы. При удачном выполнении возвращает 0, иначе возвращается -1.
Чтобы установить реакцию процесса на приходящий сигнал, используется системный вызов signal().
#include <signal.h>
void (*signal (int sig, void (*disp)(int)))(int);
Аргумент sig определяет сигнал, реакцию на приход которого надо изменить. Второй аргумент disp определяет новую реакцию на приход указанного сигнала. Итак, disp — это либо определенная пользователем функция-обработчик сигнала, либо одна из констант: SIG_DFL (обработка сигнала по умолчанию) или SIG_IGN (игнорирование сигнала). В случае успешного завершения системного вызова signal() возвращается значение предыдущего режима обработки данного сигнала (т.е. либо указатель на функцию-обработчик, либо одну из указанных констант).
Если мы успешно установили в качестве обработчика сигнала свою функцию, то при возникновении сигнала выполнение процесса прерывается, фиксируется точка возврата, и управление в процессе передается данной функции, при этом в качестве фактического целочисленного параметра передается номер пришедшего сигнала (тем самым возможно использование одной функции в качестве обработчика нескольких сигналов). Соответственно, при выходе из функции-обработчика управление передается в точку возврата, и процесс продолжает свою работу.
Стоит обратить внимание на то, что возможны и достаточно часто происходят ситуации, когда сигнал приходит во время вызова процессом некоторого системного вызова. В этом случае последующие действия зависят от реализации системы. В одном случае системный вызов прерывается с отрицательным кодом возврата, а в переменную errno заносится код ошибки. Либо системный вызов «дорабатывает» до конца. Мы будем придерживаться первой стратегии (прерывание системного вызова).
Рассмотрим ряд примеров.
Пример. Перехват и обработка сигнала. В данной программе 4 раза можно нажать CTRL+C (послать сигнал SIGINT), и ничего не произойдет. На 5-ый раз процесс обработает сигнал обработчиком по умолчанию и поэтому завершится.
#include <sys/types.h>
#include <signal.h>
#include <stdio.h>
int count = 1;
/* обработчик сигнала */
void SigHndlr(int s)
{
printf(“\nI got SIGINT %d time(s)\n”, count++);
if(count == 5)
{
/* установка обработчика по умолчанию */
signal(SIGINT, SIG_DFL);
}
}
/* тело программы */
int main(int argc, char **argv)
{
/* установка собственного обработчика */
signal(SIGINT, SigHndlr);
while(1);
return 0;
}
Пример. Удаление временного файла при завершении программы. Ниже приведена программа, которая и в случае «дорабатывания» до конца, и в случае получения сигнала SIGINT перед завершением удаляет созданный ею временный файл.
#include <unistd.h>
#include <signal.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
const char *tempfile = “abc”;
void SigHndlr(int s)
{
/* удаление временного файла */
unlink(tempfile);
/* завершение работы */
exit(0);
}
int main(int argc, char **argv)
{
signal(SIGINT, SigHndlr);
...
/* открытие временного файла */
creat(tempfile, 0666);
...
/* удаление временного файла */
unlink(tempfile);
return 0;
}
Пример. Программа «будильник». При запуске программа просит ввести имя и ожидает ввод этого имени. А дальше в цикле будут происходить следующие действия. Если по прошествии некоторого времени пользователь так и не ввел имени, то программа повторяет свою просьбу.
#include <unistd.h>
#include <signal.h>
#include <stdio.h>
void Alrm(int s)
{
printf(“\n жду имя \n”);
alarm(5);
}
int main(int argc, char **argv)
{
char s[80];
signal(SIGALRM, Alrm);
alarm(5);
printf(“Введите имя\n”);
for(;;)
{
printf(“имя:”);
if(gets(s) != NULL) break;
}
printf(“OK!\n”);
return 0;
}
В данном примере происходит установка обработчика сигнала SIGALRM. Затем происходит обращение к системному вызову alarm(), который заводит будильник на 5 единиц времени. Поскольку продолжительность единицы времени зависит от конкретной реализации системы, то мы будем считать в нашем примере, что происходит установка будильника на 5 секунд. Это означает, что по прошествии 5 секунд процесс получит сигнал SIGALRM. Дальше управление передается бесконечному циклу for, выход из которого возможен лишь при вводе непустой строки текста. Если же по истечении 5 секунд ввода так и не последовало, то приходит сигнал SIGALRM, управление передается обработчику Alrm, который печатает на экран напоминание о необходимости ввода имени, а затем снова устанавливает будильник на 5 секунд. Затем управление возвращается в функцию main в бесконечный цикл. Далее последовательность действий повторяется.
Пример. Двухпроцессный вариант программы «будильник». Данный пример будет повторять предыдущий, но теперь функции ввода строки и напоминания будут разнесены по разным процессам.
#include <signal.h>
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
Void Alrm(int s)
{
printf(“\nБыстрее!!!\n”);
}
int main(int argc, char **argv)
{
char s[80];
int pid;
signal(SIGALRM, Alrm);
if(pid = fork())
{
/* ОТЦОВСКИЙ ПРОЦЕСС */
for(;;)
{
sleep(5);
kill(pid, SIGALRM);
}
}
else
{
/* СЫНОВИЙ ПРОЦЕСС */
printf(“Введите имя\n”);
for(;;)
{
printf(“имя: “);
if(gets(s) != NULL) break;
}
printf(“OK!\n”);
/* уничтожение отцовского процесса */
kill(getppid, SIGKILL);
}
return 0;
}
В этом примере происходит установка обработчика сигнала SIGALRM. Затем происходит обращение к системному вызову fork(), который породит дочерний процесс. Далее отцовский процесс в бесконечном цикле производит одну и ту же последовательность действий. Засыпает на 5 единиц времени (посредством системного вызова sleep()), затем шлет сигнал SIGALRM своему сыну с помощью системного вызова kill(). Первым параметром данному системному вызову передается идентификатор дочернего процесса (PID), который был получен после вызова fork().
Дочерний процесс запрашивает ввод имени, а дальше в бесконечном цикле ожидает ввода строки текста до тех пор, пока не получит непустую строку. При этом он периодически получает от отцовского процесса сигнал SIGALRM, вследствие чего выводит на экран напоминание. После получения непустой строки он печатает на экране подтверждение успешности ввода (“OK!”), посылает процессу-отцу сигнал SIGKILL и завершается. Послать сигнал безусловного завершения отцовскому процессу необходимо, поскольку после завершения дочернего процесса тот будет некорректно слать сигнал SIGALRM (возможно, что идентификатор процесса-сына потом получит совершенно иной процесс со своей логикой работы, а процесс-отец так и будет слать на его PID сигналы SIGALRM).
3.1.2 Неименованные каналы
Неименованный[R17] канал (или программный канал) представляется в виде области памяти на внешнем запоминающем устройстве, управляемой операционной системой, которая осуществляет выделение взаимодействующим процессам частей из этой области памяти для совместной работы, т.е. это область памяти является разделяемым ресурсом.
Для доступа к неименованному каналу система ассоциирует с ним два файловых дескриптора. Один из них предназначен для чтения информации из канала, т.е. с ним можно ассоциировать файл, открытый только на чтение. Другой дескриптор предназначен для записи информации в канал. Соответственно, с ним может быть ассоциирован файл, открытый только на запись.
Организация данных в канале использует стратегию FIFO, т.е. информация, первой записанная в канал, будет и первой прочитанной из канала. Это означает, что для данных файловых дескрипторов недопустимы работы по перемещению файлового указателя. В отличие от файлов канал не имеет имени. Кроме того, в отличие от файлов неименованный канал существует в системе, пока существуют процессы, его использующие. Предельный размер канала, который может быть выделен процессам, декларируется параметрами настройки операционной системы.
Для создания неименованного канала используется системный вызов pipe().
#include <unistd.h>
int pipe(int *fd);
Аргументом данного системного вызова является массив fd из двух целочисленных элементов. Если системный вызов pipe() прорабатывает успешно, то он возвращает код ответа, равный нулю, а массив будет содержать два открытых файловых дескриптора. Соответственно, в fd[0] будет содержаться дескриптор чтения из канала, а в fd[1] — дескриптор записи в канал. После этого с данными файловыми дескрипторами можно использовать всевозможные средства работы с файлами, поддерживающие стратегию FIFO, т.е. любые операции работы с файлами, за исключением тех, которые касаются перемещения файлового указателя.
Неименованные каналы в общем случае предназначены для организации взаимодействия родственных процессов, осуществляющегося за счет передачи по наследству ассоциированных с каналом файловых дескрипторов. Но иногда встречаются вырожденные случаи использования неименованного канала в рамках одного процесса.
Пример. Использование неименованного канала. В нижеприведенном примере производится копирование текстовой строки с использованием канала. Этот пример является «надуманным»: он иллюстрирует случай использования канала в рамках одного процесса.
int main(int argc, char **argv)
{
char *s = “channel”;
char buf[80];
int pipes[2];
pipe(pipes);
write(pipes[1], s, strlen(s) + 1);
read(pipes[0], buf, strlen(s) + 1);
close(pipes[0]);
close(pipes[1]);
printf(“%s\n”, buf);
return 0;
}
В приведенном примере имеется текстовая строка s, которую хотим скопировать в буфер buf. Для этого дополнительно декларируется массив pipes, в котором будут храниться файловые дескрипторы, ассоциированные с каналом. После обращения к системному вызову pipe() элемент pipe[1] хранит открытый файловый дескриптор, через который можно писать в канал, а pipe[0] — файловый дескриптор, через который можно писать из канала. Затем происходит обращение к системному вызову write(), чтобы скопировать содержимое строки s в канал, а после этого идет обращение к системному вызову read(), чтобы прочитать данные из канала в буфер buf. Потом закрываем дескрипторы и печатаем содержимое буфера на экран.
Можно[R18] отметить следующие особенности организации чтения данных из канала. Если из канала читается порция данных меньшая, чем находящаяся в канале, то эта порция считывается по стратегии FIFO, а оставшаяся порция непрочитанных данных остается в канале.
Если делается попытка прочесть порцию данных большую, чем та, которая находится в канале, и при этом существуют открытые дескрипторы записи в данный канал, то процесс считывает имеющуюся порцию данных и блокируется до появления недостающих данных. Заметим, что блокировка происходит лишь при условии, что есть хотя бы один открытый дескриптор записи в канал. Если закрывается последний дескриптор записи в данный канал, то в канал помещается код конца файла EOF. В этом случае процесс, заблокированный на чтение, будет разблокирован, и ему будет передан код конца файла. Соответственно, если заблокированы два и более процесса на чтение, то порядок разблокировки определяется конкретной реализацией. Отметим, что в системе имеется системный вызов fcntl(), посредством которого можно установить режим чтения из канала без блокировки.
Теперь рассмотрим особенности организации записи в канал. Если процесс пытается записать в канал порцию данных, превосходящую доступное в канале свободное пространство, то часть этой порции данных, равная размеру свободного пространства канала, помещается в канал, и процесс блокируется до появления в канале необходимого свободного пространства. Можно избежать блокировки, используя системный вызов fcntl().
Если процесс пытается записать информацию в канал, с которым в данный момент не связан ни один открытый дескриптор чтения, то процесс получает сигнал SIGPIPE. Таким образом система уведомляет процесс, что произвести операцию записи в канал в настоящий момент нельзя, поскольку нет читающей стороны (а в случае неименованных каналов восстановить ее невозможно).
В общем случае возможна многонаправленная работа процессов с каналом, т.е. возможна ситуация, когда с одним и тем же каналом взаимодействуют два и более процесса, и каждый из взаимодействующих каналов пишет и читает информацию в канал. Но традиционной схемой организации работы с каналом является однонаправленная организация, когда канал связывает два, в большинстве случаев, или несколько взаимодействующих процесса, каждый из которых может либо читать, либо писать в канал.
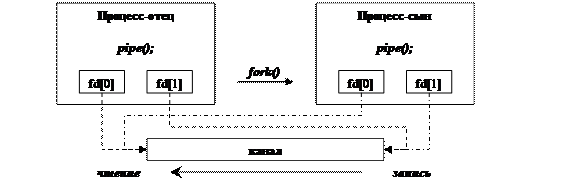
Рис. 88. Схема взаимодействия процессов с использованием неименованного канала.
Пример. Схема организации взаимодействия процессов с использованием канала (Рис. 88). Схема всегда такова: некоторый родительский процесс внутри себя порождает канал, после этого идут обращения к системным вызовам fork() — создается дерево процессов, но за счет того, что при порождении процесса открытые файловые дескрипторы наследуются, дочерний процесс также обладает файловыми дескрипторами, ассоциированными с каналом, который создал его предок. За счет этого можно организовать взаимодействие родственных процессов.
В следующем примере организуется неименованный канал между отцовским и дочерним процессами, причем процесс-отец будет писать в канал, а процесс-сын — читать из него.
int main(int argc, char **argv)
{
int fd[2];
pipe(fd);
if(fork())
{
close(fd[0]);
write(fd[1],...);
...
close(fd[1]);
...
}
else
{
close(fd[1]);
while(read(fd[0], ...))
{
...
}
...
}
}
В рассмотренном примере после создания канала посредством системного вызова pipe() и порождения дочернего процесса посредством системного вызова fork() отцовский процесс закрывает дескриптор, открытый на чтение из канала, потом производит различные действия, среди которых он пишет некоторую информацию в канал, после чего закрывает дескриптор записи в канал, и, наконец, после некоторых действий завершается. Процесс-сын первым делом закрывает дескриптор записи в канал, а после этого циклически считывает некоторые данные из канала. Стоит обратить внимание, что закрытие дескриптора записи в канал в отцовском процессе можно не делать, т.к. при завершении процесса все открытые файловые дескрипторы будут автоматически закрыты. Но в дочернем процессе закрытие дескриптора записи в канал обязателен: в противном случае, поскольку дочерний процесс читает данные из канала циклически (до получения кода конца файла), он не сможет получить этот код конца файла, а потому он зациклится. А код конца файла не будет помещен в канал, потому что при закрытии дескриптора записи в канал в отцовском процессе с каналом все еще будет ассоциирован открытый дескриптор записи дочернего процесса.
Пример. Реализация конвейера. Приведенный ниже пример основан на том факте, что при порождении процесса в ОС Unix он заведомо получает три открытых файловых дескриптора: дескриптор стандартного ввода (этот дескриптор имеет нулевой номер), дескриптор стандартного вывода (имеет номер 1) и дескриптор стандартного потока ошибок (имеет номер 2). Обычно на стандартный ввод поступают данные с клавиатуры, а стандартный вывод и поток ошибок отображаются на дисплей монитора. В системе можно организовывать цепочки команд, когда стандартный вывод одной команды поступает на стандартный ввод другой команды, и такие цепочки называются конвейером команд. В конвейере могут участвовать две и более команды.
В предлагаемом примере реализуется конвейер команд print| wc, в котором команда print осуществляет печать некоторого текста, а команда wc выводит некоторые статистические характеристики входного потока (количество байт, строк и т.п.).
int main(int argc, char **argv)
{
int fd[2];
pipe(fd); /* организовали канал */
if(fork())
{
/* ПРОЦЕСС-РОДИТЕЛЬ */
/* отождествим стандартный вывод с файловым
дескриптором канала, предназначенным для записи */
dup2(fd[1],1);
/* закрываем файловый дескриптор канала,
предназначенный для записи */
close(fd[1]);
/* закрываем файловый дескриптор канала,
предназначенный для чтения */
close(fd[0]);
/* запускаем программу print */
execlp(“print”,”print”,0);
}
/* ПРОЦЕСС-ПОТОМОК */
/*отождествляем стандартный ввод с файловым дескриптором
канала, предназначенным для чтения */
dup2(fd[0],0);
/* закрываем файловый дескриптор канала, предназначенный для
чтения */
close(fd[0]);
/* закрываем файловый дескриптор канала, предназначенный для
записи */
close(fd[1]);
/* запускаем программу wc */
execl(“/usr/bin/wc”,”wc”,0);
}
В приведенной программе открывается канал, затем порождается дочерний процесс. Далее отцовский процесс обращается к системному вызову dup2(), который закрывает файл, ассоциированный с файловым дескриптором 1 (т.е. стандартный вывод), и ассоциирует файловый дескриптор 1 с файлом, ассоциированным с дескриптором fd[1]. Таким образом, теперь через первый дескриптор стандартный вывод будет направляться в канал. После этого файловые дескрипторы fd[0] и fd[1] нам более не нужны, мы их закрываем, а в родительском процессе остается ассоциированным с каналом файловый дескриптор с номером 1. После этого происходит обращение к системному вызову execlp(), который запустит команду print, у которой выходная информация будет писаться в канал.
В дочернем процессе производятся аналогичные действия, только здесь идет работа со стандартным вводом, т.е. с нулевым файловым дескриптором. И в конце запускается команда wc, у которой входная информация будет поступать из канала. Тем самым мы запустили конвейер этих команд: синхронизация этих процессов будет происходит за счет реализованной в механизме неименованных каналов стратегии FIFO.
Пример. «Пинг-понг» (совместное использование сигналов и каналов). В данном примере рассматривается корректную организацию двунаправленной работы, когда каждый из взаимодействующих процессов могут и читать, и писать из канала.
Итак, пускай есть два процесса, которые через канал будут перекидывать «мячик»-счетчик, подсчитывающий количество своих бросков в канал, некоторое предопределенное число раз. Извещение процесса о получении управления (когда он может взять «мячик» из канала, увеличить его на 1 и снова бросить в канал) будет происходить на основе механизма сигналов.
#include <signal.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#define MAX_CNT 100
int target_pid, cnt;
int fd[2];
int status;
void SigHndlr(int s)
{
/* в обработчике сигнала происходит и чтение, и запись */
signal(SIGUSR1, SigHndlr);
if(cnt < MAX_CNT)
{
read(fd[0], &cnt, sizeof(int));
printf("%d\n", cnt);
cnt++;
write(fd[1], &cnt, sizeof(int));
/* посылаем сигнал второму: пора читать из канала */
kill(target_pid, SIGUSR1);
}
else if(target_pid == getppid())
{
/* условие окончания игры проверяется потомком */
printf("Child is going to be terminated\n");
close(fd[1]);
close(fd[0]);
/* завершается потомок */
exit(0);
}
else
kill(target_pid, SIGUSR1);
}
int main(int argc, char **argv)
{
/* организация канала */
pipe(fd);
/* установка обработчика сигнала для обоих процессов*/
signal(SIGUSR1, SigHndlr);
cnt = 0;
if(target_pid = fork())
{
/* Предку остается только ждать завершения
потомка */
wait(&status);
printf("Parent is going to be terminated\n");
close(fd[1]);
close(fd[0]);
return 0;
}
else
{
/* процесс-потомок узнает PID родителя */
target_pid = getppid();
/* потомок начинает пинг-понг */
write(fd[1], &cnt, sizeof(int));
kill(target_pid, SIGUSR1);
for(;;); /* бесконечный цикл */
}
}
Для синхронизации взаимодействующих процессов используется сигнал SIGUSR1. Обычно в операционных системах присутствуют сигналы, которые не ассоциированы с событиями, происходящими в системе, и которые процессы могут использовать по своему усмотрению. Количество таких пользовательских сигналов зависит от конкретной реализации. В приведенном примере реализован следующий принцип работы: процесс получает сигнал SIGUSR1, берет счетчик из канала, увеличивает его на 1 и снова помещает в канал, после чего посылает своему напарнику сигнал SIGUSR1. Далее действия повторяются, пока счетчик не возрастет до некоторой фиксированной величины MAX_CNT, после чего происходят завершения процессов.
В качестве счетчика в данной программе выступает целочисленная переменная cnt. Посмотрим на функцию обработчика сигнала SIGUSR. В ней проверяется, не превзошло ли значение cnt величины MAX_CNT. В этом случае из канала читается новое значение cnt, происходит печать нового значения, после этого увеличивается на 1 значение cnt, и оно помещается в канал, а напарнику посылается сигнал SIGUSR1 (посредством системного вызова kill()).
Если же значение cnt оказалось не меньше MAX_CNT, то начинаются действия по завершению процессов, при этом первым должен завершиться дочерний процесс. Для этого проверяется идентификатор процесса-напарника (target_pid) на равенство идентификатору родительского процесса (значению, возвращаемому системным вызовом getppid()). Если это так, то в данный момент управление находится у дочернего процесса, который и инициализирует завершение. Он печатает сообщение о своем завершении, закрывает дескрипторы, ассоциированные с каналом, и завершается посредством системного вызова exit(). Если же указанное условие ложно, то в данный момент управление находится у отцовского процесса, который сразу же передает его дочернему процессу, посылая сигнал SIGUSR1, при этом ничего не записывая в канал, поскольку у сына уже имеется значение переменной cnt.
В самой программе (функции main) происходит организация канала, установка обработчика сигнала SIGUSR1 и инициализация счетчика нулевым значением. Затем происходит обращение к системному вызову fork(), значение которого присваивается переменной целевого идентификатора target_pid. Если мы находимся в родительском процессе, то в этой переменной будет находиться идентификатор дочернего процесса. После этого отцовский процесс начинает ожидать завершения дочернего процесса посредством обращения к системному вызову wait(). Дождавшись завершения, отцовский процесс выводит сообщение о своем завершении, закрывает дескрипторы, ассоциированные с каналом, и завершается.
Если же системный вызов fork() возвращает нулевое значение, то это означает, что в данный момент мы находимся в дочернем процессе, поэтому первым делом переменной target_pid присваивается значение идентификатора родительского процесса посредством обращения к системному вызову getppid(). После чего процесс пишет в канал значение переменной cnt, посылает отцовскому процессу сигнал SIGUSR1, тем самым, начиная «игру», и входит в бесконечный цикл.
3.1.3 Именованные каналы
Файловая система ОС Unix поддерживает некоторую совокупность файлов различных типов. Файловая система рассматривает каталоги как файлы специального типа каталог, обычные файлы, с которым мы имеем дело в нашей повседневной жизни, — как регулярные файлы, устройства, с которыми работает система, — как специальные файлы устройств. Точно так же файловая система ОС Unix поддерживает специальные файлы, которые называются FIFO-файлами (или именованными каналами). Файлы этого типа очень схожи с обыкновенными файлами (в них можно писать и из них можно читать информацию), за исключением того факта, что они организованы по стратегии FIFO (т.е. невозможны операции, связанные с перемещением файлового указателя).
Таким образом, файлы FIFO могут использоваться для организации взаимодействия процессов, при этом в отличие от неименованных каналов эти файлы могут существовать независимо от процессов, взаимодействующих через них. Эти файлы хранятся на внешних запоминающих устройствах, поэтому возможно открыть этот файл, записать в него информацию, а через любой промежуток времени (в течение которого допустимы перезагрузки системы) прочитать записанную информацию.
Для создания файлов FIFO в различных реализациях используются разные системные вызовы, одним из которых может являться mkfifo()[1].
int mkfifo(char *pathname, mode_t mode);
Первым параметром является имя создаваемого файла, а второй параметр отвечает за флаги владения, права доступа и т.п.
После создания именованного канала любой процесс может установить с ним связь посредством системного вызова open(). При этом действуют следующие правила:
- если процесс открывает FIFO-файл для чтения, он блокируется до тех пор, пока какой-либо процесс не откроет тот же канал на запись;
- если процесс открывает FIFO-файл на запись, он будет заблокирован до тех пор, пока какой-либо процесс не откроет тот же канал на чтение;
- процесс может избежать такого блокирования, указав в вызове open() специальный флаг (в разных версиях ОС он может иметь разное символьное обозначение — O_NONBLOCK или O_NDELAY). В этом случае в ситуациях, описанных выше, вызов open() сразу же вернет управление процессу.
Правила работы с именованными каналами, в частности, особенности операций чтения-записи, полностью аналогичны неименованным каналам.
Пример. «Клиент-сервер». В нижеприведенном примере один из процессов является сервером, предоставляющим некоторую услугу, другой же процесс, который хочет воспользоваться этой услугой, является клиентом. Клиент посылает серверу запросы на предоставление услуги, а сервер отвечает на эти запросы.
/* процесс-сервер */
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/file.h>
int main(int argc, char **argv)
{
int fd;
int pid;
mkfifo("fifo", FILE_MODE | 0666);
fd = open("fifo", O_RDONLY | O_NONBLOCK);
while(read(fd, &pid, sizeof(int)) == -1);
printf("Server %d got message from %d !\n", getpid(), pid);
close(fd);
unlink("fifo");
}
/* процесс-клиент */
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/file.h>
int main(int argc, char **argv)
{
int fd;
int pid = getpid();
fd = open("fifo", O_RDWR);
write(fd, &pid, sizeof(int));
close(fd);
}
В рассмотренном примере процесс-сервер создает FIFO-файл с некоторыми опциями и правами доступа, разрешающими всем писать и читать из этого файла, затем подключается к созданному FIFO-файлу в режиме только чтения без блокировок. Затем сервер ожидает появления информации в канале. Получив ее, он печатает соответствующее сообщение, закрывает дескриптор, ассоциированный с данным FIFO-файлом, и уничтожает сам файл.
Клиентский процесс открывает FIFO-файл в режиме чтения-записи, пишет в канал свой идентификатор процесса, а затем закрывает файловый дескриптор, ассоциированный с данным FIFO-файлом.
3.1.4 Модель межпроцессного взаимодействия «главный–подчиненный»
Достаточно часто при организации многопроцессной работы необходимо наличие возможности, когда один процесс является главным по отношению к другому процессу. В частности, это необходимо для организации средств отладки, когда есть процесс-отладчик и отлаживаемый процесс. Для механизма отладки оказалось бы полезным, чтобы отладчик мог в произвольные моменты времени останавливать отлаживаемый процесс и, когда отлаживаемый процесс остановлен, осуществлять действия по его отладке: просматривать содержимое тела процесса, при необходимости корректировать тело процесса и т.д. Также является полезным возможность обеспечения контрольных точек в отлаживаемом процессе. Очевидно, что полномочия процесса-отладчика по отношению к отлаживаемому процессу являются полномочиями главного, т.е. отладчик может осуществлять управление, в то время как отлаживаемый процесс может лишь подчиняться.
Для организации взаимодействия «главный–подчиненный» ОС Unix предоставляет системный вызов ptrace().
#include <sys/ptrace.h>
int ptrace(int cmd, int pid, int addr, int data);
В этом системном вызове параметр cmd обозначает код выполняемой команды, pid — идентификатор процесса-потомка (который мы хотим трассировать), addr — некоторый адрес в адресном пространстве процесса-потомка, и, наконец, data — слово информации.
Посредством системного вызова ptrace() можно решать две задачи. С одной стороны, с помощью этого вызова подчиненный процесс может разрешить родительскому процессу проводить свою трассировку: для этого в качестве параметра cmd необходимо указать команду PTRACE_TRACEME. С другой стороны, с помощью этого же системного вызова процесс отладчик может манипулировать отлаживаемым процессом. Для этого используются остальные значения параметра cmd.
Системный вызов ptrace() позволяет выполнять следующие действия:
1. читать данные из сегмента кода и сегмента данных отлаживаемого процесса;
2. читать некоторые данные из контекста отлаживаемого процесса (в частности, имеется возможность чтения содержимого регистров);
3. осуществлять запись в сегмент кода, сегмент данных и в некоторые области контекста отлаживаемого процесса (в т.ч. модифицировать содержимое регистров). Следует отметить, что производить чтение и запись данных (а также осуществлять большинство управляющих команд над отлаживаемым процессом) можно лишь, когда трассируемый процесс приостановлен;
4. продолжать выполнение отлаживаемого процесса с прерванной точки или с предопределенного адреса сегмента кода;
5. исполнять отлаживаемый процесс в пошаговом режиме. Пошаговый режим — это режим, обеспечиваемый аппаратурой компьютера, который вызывает прерывание после исполнения каждой машинной команды отлаживаемого процесса (т.е. после исполнения каждой машинной команды процесс приостанавливается); и т.д.
Ниже приводится список возможных значений параметра cmd.[R19]
- cmd = PTRACE_TRACEME — сыновний процесс вызывает в самом начале своей работы ptrace с таким кодом операции, позволяя тем самым трассировать себя.
- cmd = PTRACE_PEEKDATA — чтение слова из адресного пространства отлаживаемого процесса.
- cmd = PTRACE_PEEKUSER — чтение слова из контекста процесса (из пользовательской составляющей, содержащейся в <sys/user.h>).
- cmd = PTRACE_POKEDATA — запись данных в адресное пространство процесса-потомка.
- cmd = PTRACE_POKEUSER — запись данных в контекст трассируемого процесса.
- cmd = PTRACE_GETREGS, PTRACE_GETFREGS — чтение регистров общего назначения (в т.ч. с плавающей точкой) трассируемого процесса.
- cmd = PTRACE_SETREGS, PTRACE_SETFREGS — запись в регистры общего назначения (в т.ч. с плавающей точкой) трассируемого процесса.
- cmd = PTRACE_CONT — возобновление выполнения трассируемого процесса.
- cmd = PTRACE_SYSCALL, PTRACE_SINGLESTEP — возобновляется выполнение трассируемой программы, но снова останавливается после выполнения одной инструкции.
- cmd = PTRACE_KILL — завершение выполнения трассируемого процесса.
Рассмотрим типовую схему организации трассировки. Будем рассматривать взаимодействие родительского процесса-отладчика с подчиненным дочерним процессом (Рис. 89).
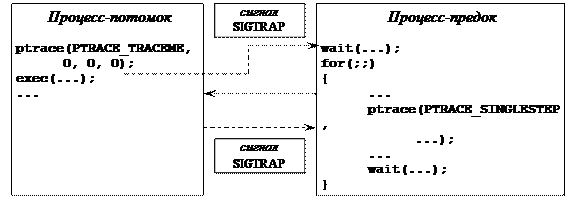
Рис. 89. Общая схема трассировки процессов.
Отцовский процесс формирует дочерний процесс и ожидает его завершения посредством обращения к системному вызову wait(). Дочерний процесс подтверждает право родителя его трассировать (обращаясь к системному вызову ptrace() с кодом cmd = PTRACE_TRACEME и нулевыми оставшимися аргументами). После чего он меняет свое тело на тело процесса, которое необходимо отлаживать (посредством обращения к одному из системных вызовов exec()). После смены тела данный процесс приостановится на точке входа и пошлет сигнал SIGTRAP родительскому процессу. Именно с этого момента начинается отладка: отлаживаемый процесс загружен, он готов к отладке и находится в начальной точке процесса. Дальше родительский трассирующий процесс может делать все те действия, которые ему необходимы по отладке: запустить процесс с точки останова, читать содержимое различных переменных, устанавливать контрольные точки и т.п.
Отладчики бывают двух типов: адресно-кодовыми и символьными. Адресно-кодовые отладчики оперируют адресами тела отлаживаемого процесса, в то время как символьные отладчики позволяют оперировать объектами языка, т.е. переменными языка и операторами языка.
Механизм организации контрольной точки в адресно-кодовом отладчике достаточно простой. Пускай нам необходимо по некоторому адресу A установить контрольную точку, т.е. чтобы при приходе управления в эту точку программы процесс всегда приостанавливался, и управление передавалось процессу-отладчику. В отладчике имеется таблица контрольных точек, в каждой строке которой присутствует адрес некоторой контрольной точки и оригинальный код отлаживаемого процесса, взятый по данному адресу. Для установки контрольной точки по адресу A необходимо тем или иным способом остановить отлаживаемый процесс (либо он останавливается при входе, либо отладчик посылает ему соответствующий сигнал). Затем отладчик читает из сегмента кода машинное слово по адресу A (посредством обращения к системному вызову ptrace()), которое он записывает в соответствующую строку таблицы контрольных точек, тем самым, сохраняя оригинальное содержимое тела трассируемого процесса. Далее по адресу A в сегмент кода записывается команда, которая вызывает прерывание и, соответственно, приход предопределенного события. Примером может служить команда деления на ноль. После этого запускаем отлаживаемый процесс на исполнение.
Итак, трассируемый процесс исполняется, и управление, наконец, передается на машинное слово по адресу A. Происходит деление на ноль. Соответственно, происходит прерывание, система передает сигнал. И отладчик через системный вызов wait() получает код возврата и «понимает», что в дочернем процессе случилось деление на ноль. Отладчик посредством системного вызова ptrace() читает адрес остановки в контексте дочернего процесса. Далее анализируется причина остановки. Если причина остановки явилось деление на ноль, то возможны две ситуации: это действительно деление на ноль, как ошибка, либо деление на ноль, как контрольная точка. Для идентификации этой ситуации отладчик обращается к таблице контрольных точек и ищет там адрес останова подчиненного процесса. Если в данной таблице указанный адрес встретился, то это означает, что отлаживаемый процесс пришел на контрольную точку (иначе деление на ноль отрабатывается как ошибка).
Находясь в контрольной точке, отладчик может производить различные манипуляции с трассируемым процессом (читать данные, устанавливать новые контрольные точки и т.п.). Далее встает вопрос, как корректно продолжить подчиненный процесс. Для этого производится следующие действия. По адресу A записывается оригинальное машинное слово. После этого системным вызовом ptrace() включаем шаговый режим. И выполняем одну команду (которую только что записали по адресу A). Из-за включенного режима пошаговой отладки подчиненный процесс снова остановится. Затем отладчик выключает режим пошаговой отладки и запускает процесс с текущей точки.
Для организации контрольных точек в символьных отладчиках необходима информация, собранная на этапах компиляции и редактирования связей. Если с компилятором связан символьный отладчик, то компилятор формирует некоторую специализированную базу данных, в которой находится информация по всем именам, используемым в программе. Для каждого имени определены диапазоны видимости и существования этого имени, его тип (статическая переменная, автоматическая переменная, регистровая переменная и т.п.). А также данная база содержит информацию обо всех операторах (диапазон начала и конца оператора, и т.п.).
Предположим, необходимо просмотреть содержимое некоторой переменной v. Для этого трассируемый процесс должен быть остановлен. По адресу останова можно определить, в какой точке программы произошел останов. На основании информации об этой точке программы можно, обратившись к содержимому базы данных, определить то пространство имен, доступных из этой точки. Если интересующая нас переменная v оказалась доступна, то продолжается работа: происходит обращение к базе данных и определяется тип данной переменной. Если тип переменной v — статическая переменная, то в соответствующей записи будет адрес, по которому размещена данная переменная (этот адрес станет известным на этапе редактирования связей). И с помощью ptrace() отладчик берет содержимое по этому адресу. Также из базы данных берется информация о типе переменной (char, float, int и т.п.), и на основе этой информации пользователю соответствующим образом отображается значение указанной переменной v.
Пускай переменная v оказалась автоматической переменной или формальным параметром. Переменные этих типов обычно реализуются в вершине стека (т.е. для этих переменных в качестве адреса фиксируется смещение от вершины стека). Чтобы прочитать содержимое переменной подобного типа, необходимо обратиться к контексту процесса, считать значение регистра-указателя на стек, после этого к содержимому регистра прибавить смещение, и по получившемуся адресу обратиться к соответствующему сегменту.
Если переменная v — регистровая переменная, то происходит обращение к базе данных, считывается номер регистра, затем идет обращение к сегменту кода [R20] и считывается содержимое нужного регистра.
Для записи значений в переменные происходит та же последовательность действий.
Если необходимо установить контрольную точку на оператор, то через базу данных определяется диапазон адресов оператора, определяется начальный адрес, а дальше производятся действия по описанной выше схеме.
3.2 Система межпроцессного взаимодействия IPC
(Inter-Process Communication)
Система[R21] IPC (известная так же, как IPC System V) позволяет обеспечивать взаимодействие произвольных процессов в пределах локальной машины. Для этого она предоставляет взаимодействующим процессам возможность использования общих, или разделяемых, ресурсов трех типов.
- Общая, или разделяемая, память, которая представляется процессу как указатель на область памяти, которая является общей для двух и более процессов. Т.е. внутри процесса некоторый указатель можно установить на начало данной области и работать далее с этой областью, как с массивом. Все изменения, которые сделает данный процесс, будут видны другим процессам. Разделяемая память IPC почти не обладает никакими средствами синхронизации (т.е. существует очень слабо развитый механизм взаимных блокировок, но мы на нем не будем останавливаться).
- Массив семафоров — ресурс, представляющий собой массив из N элементов, где N задается при создании данного ресурса, и каждый из элементов является семафором IPC (а не семафором Дейкстры: семафор Дейкстры так или иначе является формализмом, не опирающимся ни на какую реализацию, а семафор IPC — конкретной программной реализацией в ОС). Семафоры IPC предназначены, в первую очередь, для использования в качестве средств организации синхронизации.
- Очередь сообщений — это разделяемый ресурс, позволяющий организовывать очереди сообщений: один процесс может в эту очередь положить сообщение, а другой процесс — прочитать его. Данный механизм имеет возможность блокировок, поэтому его можно использовать и как средство передачи информации между взаимодействующими процессами, и как средство их синхронизации.
Для организации совместного использования разделяемых ресурсов необходим некоторый механизм именования ресурсов, используя который взаимодействующие процессы смогут работать с данным конкретным ресурсом. Для этих целей используется система ключей: при создании ресурса с ним ассоциируется ключ — целочисленное значение. Жесткого ограничения к выбору этих ключей нет. Т.е. при создании ресурса, предположим, общая память процесс-создатель ассоциирует с ним конкретный ключ — например, 25. Теперь все процессы, желающие работать с той же общей памятью, должны, во-первых, обладать соответствующими правами, а во-вторых, заявить, что они желают работать с ресурсом общая память с ключом 25. И они будут с ней работать. Но тут возможны коллизии из-за случайного совпадения ключей различных ресурсов.
Во избежание коллизий система предлагает некоторую унификацию именования IPC-ресурсов. Для генерации уникальных ключей в системе имеется библиотечная функция ftok().
#include <sys/types.h>
#include <sys/ipc.h>
key_t ftok(char *filename, char proj);
Первый параметр данной функции — полное имя существующего файла. Второй параметр — это уточняющая информация (в частности, он может использоваться для поддержания разных версий программы).
Итак, функция ftok() обращается к указанному файлу, считывает его атрибуты и, используя значение второго аргумента, генерирует уникальный ключ (уникальное целое число). Стоит особо обратить внимание, что первый параметр должен указывать на существующий файл, и, что не менее важно, при генерации ключа используются его атрибуты. Это означает, что если один процесс для генерации ключа ссылается на некоторый файл, создает ресурс, потом этот файл уничтожается, создается другой файл с тем же именем (но, скорее всего, с другими атрибутами), то другой процесс, желающий получить ключ к созданному ресурсу, не сможет этого сделать, т.к. функция ftok() будет генерировать иное значение.
Каждый ресурс IPC имеет атрибут владельца. Владельцем считается тот процесс (его идентификация), который создал данный ресурс, и, соответственно, удалить данный ресурс может только владелец. Но стоит отметить, что существует механизм передачи прав владения от процесса процессу.
С каждым ресурсом, так же как и с файлами, связаны три категории прав (права владельца, группы и остальных пользователей). Но в каждой категории имеются лишь права на чтение и запись: право на выполнение нет.
Ресурсы IPC могут существовать без процессов, их создавших. Это означает, что созданный разделяемый ресурс будет существовать до тех пор, пока его явно не удалят либо до перезапуска системы.
Итак, имеется три группы IPC-ресурсов, с каждой из которой связан свой набор функций по работе с конкретным типом ресурса. Но функциональная структура идентична. В частности, среди этих наборов можно выделить функции, имеющие суффикс get (а префиксная часть представляет собою аббревиатуру имени ресурса). Среди параметров данных функций присутствует ключ, о котором шла речь в начале выше, а также некоторые флаги. Соответственно, эти функции в зависимости от флагов позволяют создавать или подключаться к существующему ресурсу IPC, ассоциированному с указываемым ключом.
<ResourceName>get(key, ..., flags);
Параметр флаги (flags) является один из важных параметров. Он может быть комбинацией различных флагов. Основные из них приведены ниже.
- IPC_PRIVATE — данный флаг определяет создание IPC-ресурса, не доступного остальным процессам. Т.е. функция get при наличии данного флага всегда открывает новый ресурс, к которому никто другой не может подключиться. Данный флаг позволяет использовать разделяемый ресурс между родственными процессами (поскольку дескриптор созданного ресурса передается при наследовании дочерним процессам).
- IPC_CREAT — если данного флага нет среди параметров функции get, то это означает, что процесс хочет подключиться к существующему ресурсу. В этом случае, если такой ресурс существует, и права доступа к нему позволяют к нему обратиться, то процесс получит дескриптор ресурса и продолжит работу. Иначе функция get вернет -1, а переменная errno будет содержать код ошибки. Если же при вызове функции get данный флаг установлен, то функция работает на создание или подключение к существующему ресурсу. В данном случае возможно возникновение ошибки из-за нехватки прав доступа в случае существования ресурса. Но при установленном флаге встает вопрос, кто является владельцем ресурса, и, соответственно, кто его должен удалять (поскольку каждый процесс либо подключается к существующему ресурсу, либо создает новый). Для разрешения данной проблемы используется следующий флаг.
- IPC_EXCL — используя данный флаг в паре с флагом IPC_CREAT, функция get будет работать только на создание нового ресурса. Если же ресурс будет уже существовать, то функция get вернет -1, а переменная errno будет содержать код соответствующей ошибки.
Ниже приводится список некоторых ошибок, возможных при вызове функции get, возвращаемых в переменной errno:
- ENOENT — ресурс не существует, и не указан флаг IPC_CREAT;
- EEXIST — ресурс существует, и установлены флаги IPC_CREAT | IPC_EXCL;
- EACCESS — не хватает прав доступа на подключение.
3.2.1 Очередь сообщений IPC
Система предоставляет возможность создания некоторого функционально расширенного аналога канала, но главное отличие заключается в том, что сообщения в очереди сообщений IPC типизированы. Каждое сообщение помимо содержательной своей части имеет атрибут тип сообщения. Тогда очередь сообщений можно рассматривать с двух позиций: во-первых, как сквозную очередь (когда тип сообщения не важен, они все находятся в единой очереди), а, во-вторых, как суперпозицию очередей однотипных сообщений (Рис. 90). При этом способ интерпретации допускает одновременно различные типы интерпретации. Непосредственный выбор интерпретации определяется в момент считывания сообщения из очереди.

Рис. 90. Очередь сообщений IPC.
Для организации работы с очередью предусмотрен набор функций. Во-первых, это уже упомянутая функция создания/доступа к очереди сообщений.
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/message.h>
int msgget(key_t key, int msgflag);
У данной функции два параметра: ключ и флаги. В случае успешного выполнения функция возвращает положительный дескриптор очереди, иначе возвращается -1.
Существует блок функций использования очереди: в частности, функции отправки и приема сообщения. Сначала рассмотрим функцию отправки сообщений.
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
int msgsnd(int msqid, const void *msgp, size_t msgsz,
int msgflg);
Первый аргумент данной функции — идентификатор очереди, полученный в результате вызова msgget(). Второй аргумент — указатель на буфер, содержащий реальные данные и тип сообщения, подлежащего посылке в очередь, в третьем аргументе указывается размер буфера. В качестве буфера необходимо указывать структуру, содержащую следующие поля:
- long msgtype — тип сообщения (только положительное длинное целое);
- char msgtext[] — данные (тело сообщения).
Последний аргумент функции — это флаги. Среди разнообразных флагов можно выделить те, которые определяют режим блокировки при отправке сообщения. Если флаг равен 0, то вызов будет блокироваться, если для отправки недостаточно системных ресурсов. Можно установить флаг IPC_NOWAIT, который позволяет работать без блокировки: тогда в случае возникновения ошибки при отправке сообщения, вызов вернет -1, а переменная errno будет содержать соответствующий код ошибки.
Для получения сообщений используется функция msgrcv().
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
int msgrcv(int msqid, void *msgp, size_t msgsz,
long msgtyp, int msgflg);
Первые три аргумента аналогичны аргументам предыдущего вызова: дескриптор очереди, указатель на буфер, куда следует поместить данные, и максимальный размер (в байтах) тела сообщения, которое можно туда поместить. Буфер, используемый для приема сообщения, должен иметь структуру, описанную выше.
Четвертый аргумент указывает тип сообщения, которое процесс желает получить. Если значение этого аргумента есть 0, то будет получено сообщение любого типа (т.е. идет работа со сквозной очередью). Если значение аргумента msgtyp больше 0, из очереди будет извлечено сообщение указанного типа. Если же значение аргумента msgtyp отрицательно, то тип принимаемого сообщения определяется как наименьшее значение среди типов, которые меньше модуля msgtyp. В любом случае, как уже говорилось, из подочереди с заданным типом (или из общей очереди, если тип не задан) будет выбрано самое старое сообщение.
Последним аргументом является комбинация (побитовое сложение) флагов. Если среди флагов не указан IPC_NOWAIT, и в очереди не найдено ни одного сообщения, удовлетворяющего критериям выбора, процесс будет заблокирован до появления такого сообщения. (Однако, если такое сообщение существует, но его длина превышает указанную в аргументе msgsz, то процесс заблокирован не будет, и вызов сразу вернет -1; сообщение при этом останется в очереди). Если же флаг IPC_NOWAIT указан, и в очереди нет ни одного необходимого сообщения, то вызов сразу вернет -1.
Процесс может также указать флаг MSG_NOERROR: в этом случае он может прочитать сообщение, даже если его длина превышает указанную емкость буфера. Тогда в буфер будет записано первые msgsz байт из тела сообщения, а остальные данные отбрасываются.
В случае успешного завершения функция возвращает количество успешно прочитанных байтов в теле сообщения.
Следующая группа функций — это функции управления ресурсом. Эти функции обеспечивают в общем случае изменение режима функционирования ресурса, в т.ч. и удаление ресурса.
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
int msgctl(int msqid, int cmd, struct msgid_ds *buf);
Данная функция используется для получения или изменения управляющих параметров, связанных с очередью, и уничтожения очереди. Ее аргументы — идентификатор ресурса, команда, которую необходимо выполнить, и структура, описывающая управляющие параметры очереди. Тип msgid_ds представляет собой структуру, в полях которой хранятся права доступа к очереди, статистика обращений к очереди, ее размер и т.п.
Возможные значения аргумента cmd:
- IPC_STAT — скопировать структуру, описывающую управляющие параметры очереди по адресу, указанному в параметре buf;
- IPC_SET — заменить структуру, описывающую управляющие параметры очереди, на структуру, находящуюся по адресу, указанному в параметре buf;
- IPC_RMID — удалить очередь.
Пример. Использование очереди сообщений. В приведенном ниже примере участвуют три процесса: основной процесс и процессы A и B. Основной процесс считывает из стандартного ввода текстовую строку. Если она начинается на букву A, то эта строка посылается процессу A, если на B — то процессу B, если на Q — то обоим процессам (в этом случае основной процесс ждет некоторое время, затем удаляет очередь сообщений и завершается). Процессы A и B считывают из очереди адресуемые им сообщения и распечатывают их на экране. Если пришедшее сообщение начинается с буквы Q, то процесс завершается.
/* ОСНОВНОЙ ПРОЦЕСС */
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/message.h>
#include <stdio.h>
/* декларация структуры сообщения */
struct
{
long mtype; /* тип сообщения */
char Data[256]; /* сообщение */
} Message;
int main(int argc, char **argv)
{
key_t key;
int msgid;
char str[256];
/*получаем уникальный ключ, однозначно определяющий
доступ к ресурсу данного типа */
key = ftok("/usr/mash",'s');
/* создаем новую очередь сообщений,
0666 определяет права доступа */
msgid = msgget(key, 0666 | IPC_CREAT | IPC_EXCL);
/* запускаем вечный цикл */
for(;;)
{
gets(str); /* читаем из стандартного ввода строку */
/* и копируем ее в буфер сообщения */
strcpy(Message.Data, str);
/* анализируем первый символ прочитанной строки */
switch(str[0])
{
case 'a':
case 'A':
/* устанавливаем тип 1 для ПРОЦЕССА A*/
Message.mtype = 1;
/* посылаем сообщение в очередь */
msgsnd(msgid, (struct msgbuf*) (&Message),
strlen(str)+1, 0);
break;
case 'b':
case 'B':
/* устанавливаем тип 2 для ПРОЦЕССА A*/
Message.mtype = 2;
msgsnd(msgid, (struct msgbuf*) (&Message),
strlen(str)+1, 0);
break;
case 'q':
case 'Q':
Message.mtype = 1;
msgsnd(msgid, (struct msgbuf*) (&Message),
strlen(str)+1, 0);
Message.mtype = 2;
msgsnd(msgid, (struct msgbuf*) (&Message),
strlen(str)+1, 0);
/* ждем получения сообщений
процессами А и В */
sleep(10);[2]
/* уничтожаем очередь */
msgctl(msgid, IPC_RMID, NULL);
exit(0);
default:
/* игнорируем остальные случаи */
break;
}
}
}
/* ПРИНИМАЮЩИЙ ПРОЦЕСС A (процесс B будет аналогичным) */
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/message.h>
#include <stdio.h>
struct
{
long mtype; /* тип сообщения */
char Data[256]; /* сообщение */
} Message;
int main(int argc, char **argv)
{
key_t key;
int msgid;
/* получаем ключ по тем же параметрам */
key = ftok("/usr/mash",'s');
/*подключаемся к очереди сообщений */
msgid = msgget(key, 0666);
/* запускаем вечный цикл */
for(;;)
{
/* читаем сообщение с типом 1 для ПРОЦЕССА A */
msgrcv(msgid, (struct msgbuf*) (&Message), 256, 1, 0);[3]
printf("%s", Message.Data);
if(Message.Data[0] == 'q' || Message.Data[0] == 'Q')
break;
}
return 0;
}
Пример. Очередь сообщений. Модель «клиент-сервер». В приведенном ниже примере имеется совокупность взаимодействующих процессов. Эта модель несимметричная: один из процессов назначается сервером, и его задачей становится обслуживание запросов остальных процессов-клиентов. В данном примере сервер принимает запросы от клиентов в виде сообщений (из очереди сообщений) с типом 1. Тело сообщения-запроса содержит идентификатор клиентского процесса, который выслал данный запрос. Для каждого запроса сервер генерирует ответ, которое также посылает через очередь сообщений, но посылаемое сообщение будет иметь тип, равный идентификатору процесса-адресата. В свою очередь, клиентский процесс будет брать из очереди сообщений сообщения с типом, равным его идентификатору.
/* СЕРВЕР */
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include <stdlib.h>
#include <string.h>
int main(int argc, char **argv)
{
struct
{
long mestype;
char mes[100];
} messageto;
struct
{
long mestype;
long mes;
} messagefrom;
key_t key;
int mesid;
key = ftok("example", 'r');
mesid = msgget (key, 0666 | IPC_CREAT | IPC_EXCL );
while(1)
{
msgrcv(mesid, &messagefrom, sizeof(messagefrom) –
sizeof(long), 1, 0);
messageto.mestype = messagefrom.mes;
strcpy(messageto.mes, "Message for client");
msgsnd (mesid, &messageto, sizeof(messageto) –
sizeof(long),0);
}
}
/* КЛИЕНТ */
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
int main(int argc, char **argv)
{
struct
{
long mestype;
long mes;
} messageto;
struct
{
long mestype;
char mes[100];
} messagefrom;
key_t key;
int mesid;
long pid = getpid();
key = ftok("example", 'r');
mesid = msgget (key, 0666);
messageto.mestype = 1;
messageto.mes = pid;
msgsnd(mesid, &messageto, sizeof(messageto) –
sizeof(long),0);
msgrcv(mesid,&messagefrom, sizeof(messagefrom) –
sizeof(long),pid,0);
printf("%s", messagefrom.mes);
return 0;
}
В серверном процессе декларируются две структуры для принимаемого (meassagefrom) и посылаемого (messageto) сообщений, а также ключ key и дескриптор очереди сообщений mesid. Затем сервер предпринимает традиционные действия: получает ключ, а по нему — дескриптор очереди сообщений. Затем он входит в бесконечный цикл, в котором и обрабатывает клиентские запросы. Каждая итерация цикла выглядит следующим образом. Из очереди выбирается сообщение с типом 1 (это сообщения с запросами от клиентов). Из тела этого сообщения считывается информация об идентификаторе клиента, и этот идентификатор сразу заносится в поле типа посылаемого сообщения. Затем сервер генерирует тело посылаемого сообщения, после чего отправляет созданное сообщение в очередь. На этом итерация цикла завершается.
Клиентский процесс имеет аналогичные декларации (за исключением того, что теперь посылаемое и принимаемое сообщения поменялись ролями). Далее клиент получает свой идентификатор процесса, записывает его в тело сообщения запроса, которому устанавливает тип 1. После этого отправляет запрос в очередь, принимает из очереди ответ (сообщение с типом, равным его собственному идентификатору процесса) и завершается.
3.2.2 Разделяемая память IPC
Механизм разделяемой памяти позволяет нескольким процессам получить отображение некоторых страниц из своей виртуальной памяти на общую область физической памяти. Благодаря этому, данные, находящиеся в этой области памяти, будут доступны для чтения и модификации всем процессам, подключившимся к данной области памяти.
Процесс, подключившийся к разделяемой памяти, может затем получить указатель на некоторый адрес в своем виртуальном адресном пространстве, соответствующий данной области разделяемой памяти. После этого он может работать с этой областью памяти аналогично тому, как если бы она была выделена динамически (например, путем обращения к malloc()), однако, как уже говорилось, разделяемая область памяти не уничтожается автоматически даже после того, как процесс, создавший или использовавший ее, перестанет с ней работать.[R22]
Рассмотрим набор системных вызовов для работы с разделяемой памятью. Для создания/подключения к ресурсу разделяемой памяти IPC используется функция shmget().
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
int shmget (key_t key, int size, int shmflg);
Аргументы данной функции: key — ключ для доступа к разделяемой памяти; size задает размер области памяти, к которой процесс желает получить доступ. Если в результате вызова shmget() будет создана новая область разделяемой памяти, то ее размер будет соответствовать значению size. Если же процесс подключается к существующей области разделяемой памяти, то значение size должно быть не более ее размера, иначе вызов вернет -1. Заметим, что если процесс при подключении к существующей области разделяемой памяти указал в аргументе size значение, меньшее ее фактического размера, то впоследствии он сможет получить доступ только к первым size байтам этой области.[R23]
Третий параметр определяет флаги, управляющие поведением вызова. Подробнее алгоритм создания/подключения разделяемого ресурса был описан выше.
В случае успешного завершения вызов возвращает положительное число — дескриптор области памяти, в случае неудачи возвращается -1. Но наличие у процесса дескриптора разделяемой памяти не дает ему возможности работать с ресурсом, поскольку при работе с памятью процесс работает в терминах адресов. Поэтому необходима еще одна функция, которая присоединяет полученную разделяемую память к адресному пространству процесса, — это функция shmat().
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
char *shmat(int shmid, char *shmaddr, int shmflg);
При помощи этого вызова процесс подсоединяет область разделяемой памяти, дескриптор которой указан в shmid, к своему виртуальному адресному пространству. После выполнения этой операции процесс сможет читать и модифицировать данные, находящиеся в области разделяемой памяти, адресуя ее как любую другую область в своем собственном виртуальном адресном пространстве.
В качестве второго аргумента процесс может указать виртуальный адрес в своем адресном пространстве, начиная с которого необходимо подсоединить разделяемую память. Чаще всего, однако, в качестве значения этого аргумента передается 0, что означает, что система сама может выбрать адрес начала разделяемой памяти. Передача конкретного адреса (положительного целого) в этом параметре имеет смысл лишь в определенных случаях, и это означает, что процесс желает связать начало области разделяемой памяти с конкретным адресом. В подобных случаях необходимо учитывать, что возможны коллизии с имеющимся адресным пространством.
Третий аргумент представляет собой комбинацию флагов. В качестве значения этого аргумента может быть указан флаг SHM_RDONLY, который указывает на то, что подсоединяемая область будет использоваться только для чтения. Реализация тех или иных флагов будет зависеть от аппаратной поддержки соответствующего свойства. Если аппаратура не поддерживает защиту памяти от записи, то при установке флага SHM_RDONLY ошибка, связанная с модификацией содержимого памяти, не сможет быть обнаружена (поскольку программным способом невозможно выявить, в какой момент происходит обращение на запись в данную область памяти).
Эта функция возвращает адрес (указатель), начиная с которого будет отображаться присоединяемая разделяемая память. И с этим указателем можно работать стандартными средствами языка C. В случае неудачи вызов возвращает -1.
Соответственно, для открепления разделяемой памяти от адресного пространства процесса используется функция shmdt().
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
int shmdt(char *shmaddr);
Данный вызов позволяет отсоединить разделяемую память, ранее присоединенную посредством вызова shmat(). Параметр shmaddr — адрес прикрепленной к процессу памяти, который был получен при вызове shmat(). В случае успешного выполнения функция вернет значение 0, в случае неудачи возвращается -1.
И, напоследок, рассмотрим функцию shmctl() управления ресурсом разделяемая память.
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
Данный вызов используется для получения или изменения процессом управляющих параметров, связанных с областью разделяемой памяти, наложения и снятия блокировки на нее и ее уничтожения. Аргументы вызова — дескриптор области памяти, команда, которую необходимо выполнить, и структура, описывающая управляющие параметры области памяти.
Возможные значения аргумента cmd:
- IPC_STAT — скопировать структуру, описывающую управляющие параметры области памяти;
- IPC_SET — заменить структуру, описывающую управляющие параметры области памяти, на структуру, находящуюся по адресу, указанному в параметре buf;
- IPC_RMID — удалить ресурс;
- SHM_LOCK, SHM_UNLOCK — блокировать или разблокировать область памяти. Это единственные средства синхронизации в данном ресурсе, их реализация должна поддерживаться аппаратурой.
Пример. Работа с общей памятью в рамках одного процесса. В данном примере процесс создает ресурс разделяемая память, размером в 100 байт (и соответствующими флагами), присоединяет ее к своему адресному пространству, при этом указатель на начало данной области сохраняется в переменной shmaddr. Дальше процесс производит различные манипуляции, а перед своим завершением он удаляет данную область разделяемой памяти.
int main(int argc, char **argv)
{
key_t key;
char *shmaddr;
key = ftok(“/tmp/ter”, ’S’);
shmid = shmget(key, 100, 0666 | IPC_CREAT | IPC_EXCL);
shmaddr = shmat(shmid, NULL, 0);
/* работаем с разделяемой памятью, как с обычной */
putm(shmaddr);
waitprocess();
shmctl(shmid, IPC_RMID, NULL);
return 0;
}
3.2.3 Массив семафоров IPC
Семафоры представляют собой одну из форм IPC и используются для организации синхронизации взаимодействующих процессов. Рассмотрение функций для работы с семафорами мы начнем традиционно с функции создания/доступа к данному ресурсу — функции semget().
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
int semget(key_t key, int nsems, int semflag);
Первый параметр функции semget() — ключ, второй — количество семафоров (длина массива семафоров), и третий параметр — флаги. Через флаги можно определить права доступа и те операции, которые должны выполняться (открытие семафора, проверка, и т.д.). Функция semget() возвращает целочисленный идентификатор созданного разделяемого ресурса, либо -1 в случае ошибки. Необходимо отметить, что если процесс подключается к существующему ресурсу, то возможно появление коллизий, связанных с неверным указанием длины массива семафоров.
Основная функция для работы с семафорами — функция semop().
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
int semop(int semid, struct sembuf *semop, size_t nops);
Первый аргумент — идентификатор ресурса, второй аргумент является указателем на начало массива структур, определяющих операции, которые необходимо произвести над семафорами. Третий параметр — количество структур в указанном массиве. Каждый элемент данного массива — это структура определенного вида, предназначенная для выполнения операции над соответствующим семафором в массиве семафоров. Ниже приводится указанная структура.
struct sembuf
{
short sem_num; /* номер семафора в массиве */
short sem_op; /* код производимой операции */
short sem_flg; /* флаги операции */
}
Поле операции интерпретируется следующим образом. Пускай значение семафора с номером num равно val. Тогда порядок работы с семафором можно записать в виде следующей схемы.
Если sem_op = 0 то
если val ≠ 0 то
пока (val ≠ 0) [процесс блокирован]
[возврат из вызова]
Если sem_op ≠ 0 то
если val + sem_op < 0 то
пока (val + sem_op < 0) [процесс блокирован]
val = val + sem_op
Понимать данную последовательность действий надо так. Если код операции равен нулю, а значение данного семафора не равно нулю, то процесс будет блокирован до тех пор, пока значение семафора не обнулится. Если же и код операции нулевой, и значение семафора нулевое, то никаких блокировок не произойдет, и операция завершится. Если код операции отличен от нуля (т.е. процесс желает скорректировать значение семафора), то в этом случае делается следующая проверка. Если сумма текущего значения семафора и кода операции отрицательная, то процесс будет блокирован. Как только он разблокируется, происходит коррекция. Замети, что если указанная сумма значения семафора и кода операции неотрицательная, то коррекция происходит без блокировок.
Для управления данным типом разделяемых ресурсов используется системный вызов semctl().
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
int semctl(int semid, int num, int cmd, union semun arg);
Параметрами данной функции являются, соответственно, дескриптор массива семафоров, индекс семафора в массиве, команда и управляющие параметры. Среди множества команд, которые можно выполнять с помощью данной функции, можно особо отметить две: команду удаления ресурса (IPC_RMID) и команду инициализации и модификации значения семафора (IPC_SET). Используя последнюю команду, можно использовать массив семафоров уже не как средство синхронизации, а как средство передачи информации между взаимодействующими процессами (что само по себе является, как минимум, неэффективным, поскольку семафоры создавались именно как средства синхронизации).
Данная функция возвращает значение, соответствующее выполнявшейся операции (по умолчанию 0), или -1 в случае неудачи. Ниже приводится определение типа последнего параметра.
<sys/sem.h>
union semun
{
int val; /* значение одного семафора */
struct semid_ds *buf; /* параметры массива семафоров в целом (количество, права доступа, статистика доступа)*/
ushort *array; /* массив значений семафоров */
}
Пример. Использование разделяемой памяти и семафоров. В рассматриваемом примере моделируется двухпроцессная система, в которой первый процесс создает ресурсы разделяемая память и массив семафоров. Затем он начинает читать информацию со стандартного устройства ввода, считанные строки записываются в разделяемую память. Второй процесс читает строки из разделяемой памяти. Данная задача требует синхронизации, которая будет осуществляться на основе механизма семафоров. Стоит обратить внимание на то, что с одним и тем же ключом одновременно создаются ресурсы двух разных типов (в случае использования ресурсов одного типа подобные действия некорректны).
/* 1-ый процесс */
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
#include <string.h>
#define NMAX 256
int main(int argc, char **argv)
{
key_t key;
int semid, shmid;
struct sembuf sops;
char *shmaddr;
char str[NMAX];
/* создаем уникальный ключ */
key = ftok(“/usr/ter/exmpl”, ’S’);
/* создаем один семафор с определенными правами доступа */
semid = semget(key, 1, 0666 | IPC_CREAT | IPC_EXCL);
/*создаем разделяемую память на 256 элементов */
shmid = shmget(key, NMAX, 0666 | IPC_CREAT | IPC_EXCL);
/* подключаемся к разделу памяти, в shmaddr – указатель на буфер с разделяемой памятью */
shmaddr = shmat(shmid, NULL, 0);
/* инициализируем семафор значением 0 */
semctl(semid, 0, SETVAL, (int) 0);
sops.sem_num = 0;
sops.sem_flg = 0;
/* запуск цикла */
do
{
printf(“Введите строку:”);
if(fgets(str, NMAX, stdin) == NULL)
/* пишем признак завершения – строку “Q” */
strcpy(str, “Q”);
/* в текущий момент семафор открыт для этого процесса*/
/* копируем строку в разд. память */
strcpy(shmaddr, str);
/* предоставляем второму процессу возможность войти */
sops.sem_op = 3; /* увеличение семафора на 3 */
semop(semid, &sops, 1);
/* ждем, пока семафор будет открыт для 1го процесса –
для следующей итерации цикла*/
sops.sem_op = 0; /* ожидание обнуления семафора */
semop(semid, &sops, 1);
} while (str[0] != ‘Q’);
/* в данный момент второй процесс уже дочитал из
разделяемой памяти и отключился от нее – можно ее удалять*/
shmdt(shmaddr); /* отключаемся от разделяемой памяти */
/* уничтожаем разделяемую память */
shmctl(shmid, IPC_RMID, NULL);
/* уничтожаем семафор */
semctl(semid, 0, IPC_RMID, (int) 0);
return 0;
}
/* 2-ой процесс */
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
#include <string.h>
#define NMAX 256
int main(int argc, char **argv)
{
key_t key;
int semid, shmid;
struct sembuf sops;
char *shmaddr;
char str[NMAX];
/* создаем тот же самый ключ */
key = ftok(“/usr/ter/exmpl”, ’S’);
semid = semget(key, 1, 0666);
shmid = shmget(key, NMAX, 0666);
/* аналогично предыдущему процессу –
инициализация ресурсов */
shmaddr = shmat(shmid, NULL, 0);
sops.sem_num = 0;
sops.sem_flg = 0;
/* запускаем цикл */
do
{
printf(“Waiting...\n”);
/* ожидание на семафоре */
sops.sem_op = -2;
/* будем ожидать, пока “значение семафора” + ”значение
sem_op” не станет неотрицательным, т.е. пока значение
семафора не станет, как минимум, 2 (2 - 2 >= 0) */
semop(semid, &sops, 1);
/* теперь значение семафора равно 1 */
/* критическая секция - работа с разделяемой памятью –
в этот момент первый процесс к разделяемой памяти
доступа не имеет */
/* копируем строку из разд. памяти */
strcpy(str, shmaddr);
if(str[0] == ‘Q’)
/* завершение работы - освобождаем разд. память*/
shmdt(shmaddr);
/* после работы – обнулим семафор */
sops.sem_op = -1;
semop(semid, &sops, 1);
printf(“Read from shared memory: %s\n”, str);
} while (str[0] != ‘Q’);
return 0;
}
3.3 Сокеты[R24] — унифицированный интерфейс программирования распределенных систем
Средства межпроцессного взаимодействия ОС UNIX, представленные в системе IPC, решают проблему взаимодействия двух процессов, выполняющихся в рамках одной операционной системы. Однако, очевидно, их невозможно использовать, когда требуется организовать взаимодействие процессов в рамках сети. Это связано как с принятой системой именования, которая обеспечивает уникальность только в рамках данной системы, так и вообще с реализацией механизмов разделяемой памяти, очереди сообщений и семафоров, — очевидно, что для удаленного взаимодействия они не годятся. Следовательно, возникает необходимость в каком-то дополнительном механизме, позволяющем общаться двум процессам в рамках сети. При этом механизм должен быть унифицированным: он должен в определенной степени позволять абстрагироваться от расположения процессов и давать возможность использования одних и тех же подходов для локального и нелокального взаимодействия. Кроме того, как только мы обращаемся к сетевому взаимодействию, встает проблема многообразия сетевых протоколов и их использования. Понятно, что было бы удобно иметь какой-нибудь общий интерфейс, позволяющий пользоваться услугами различных протоколов по выбору пользователя.
Обозначенные проблемы был призван решить механизм, впервые появившийся в Берклиевском UNIX — BSD, начиная с версии 4.2, и названный сокетами (sockets). Ниже подробно рассматривается этот механизм.[R25]
Механизм сокетов обеспечивает два типа соединений. Во-первых, это соединение, обеспечивающее установление виртуального канала (т.е. обеспечиваются соответствующие свойства, в частности, гарантируется порядок передачи сообщения), его прямым аналогом является протокол TCP. Во-вторых, это дейтаграммное соединение (соответственно, без обеспечения порядка передачи и т.п.), аналогом которого является протокол UDP.
Именование сокетов для организации работы с ними определяется т.н. коммуникационным доменом. Аппарат сокетов в общем случае поддерживает целый спектр коммуникационных доменов, среди которых нас будут интересовать два из них: домен AF_UNIX (семейство имен в ОС Unix) и AF_INET (семейство имен для сети Internet, определяемое стеком протоколов TCP/IP).
Для создания сокета используется системный вызов socket().
#include <sys/types.h>
#include <sys/socket.h>
int socket(int domain, int type, int protocol);
Первый параметр данного системного вызова определяет код коммуникационного домена. Коммуникационный домен, в свою очередь, определяет структуру именования, которая может быть использована для сокета. Как говорилось выше, на сегодняшний день существует целый ряд доменов, мы же остановимся на доменах, обозначаемых константами AF_UNIX и AF_INET.
Второй параметр отвечает за тип сокета: либо SOCK_STREAM (тип виртуальный канал), либо SOCK_DGRAM (дейтаграммный тип сокета).
Последний параметр вызова — протокол. Выбор значения данного параметра зависит от многих факторов — и в первую очередь, от выбора коммуникационного домена и от выбора типа сокета. Если указывается нулевое значение этого параметра, то система автоматически выберет протокол, учитывая значения первых аргументов вызова. А можно указать константу, связанную с именем конкретного протокола: например, IPPROTO_TCP для протокола TCP (домена AF_INET) или IPPROTO_UDP для протокола UDP (домена AF_INET). Но в последнем случае необходимо учесть, что могут возникать ошибочные ситуации. Например, если явно выбран домен AF_INET, тип сокета виртуальный канал и протокол UDP, то возникнет ошибка. Однако, если домен будет тем же, тип сокета дейтаграммный и протокол TCP, то ошибки не будет: просто дейтаграммное соединение будет реализовано на выбранном протоколе.
В случае успешного завершения системный вызов socket() возвращает открытый файловый дескриптор, ассоциированный с созданным сокетом. Как отмечалось выше, сокеты представляют собой особый вид файлов в файловой системе ОС Unix. Но данный дескриптор является локальным атрибутом: это лишь номер строки в таблице открытых файлов текущего процесса, в которой появилась информация об этом открытом файле. И им нельзя воспользоваться другим процессам, чтобы организовать взаимодействие с текущим процессом посредством данного сокета. Необходимо связать с этим сокетом некоторое имя, доступное другим процессам, посредством которого они смогут осуществлять взаимодействие. Для организации именования используется системный вызов bind().
#include <sys/types.h>
#include <sys/socket.h>
int bind(int sockfd, struct sockaddr *myaddr, int addrlen);
Посредством данного системного вызова возможно связывание файлового дескриптора (первого параметра), ассоциированного с открытым сокетом, с некоторой структурой, в которой будет размещаться имя (или адрес) данного сокета. Для разных коммуникационных доменов структура данного имени различна. Например, для домена AF_UNIX она выглядит следующим образом:
#include <sys/un.h>
struct sockaddr_un
{
short sun_family; /* == AF_UNIX */
char sun_path[108];
};
Первое поле в данной структуре — это код коммуникационного домена, а второе поле — это полное имя. Для домена AF_INET структура выглядит несколько иначе:
#include <netinet/in.h>
struct sockaddr_in
{
short sin_family; /* == AF_INET */
u_short sin_port; /* номер порта */
struct in_addr sin_addr; /* IP-адрес хоста */
char sin_zero[8]; /* не используется */
};
В данной структуре присутствует различная информация, в частности, IP-адрес, номер порта и т.п.
И, наконец, последний аргумент addrlen рассматриваемого системного вызова характеризует размер структуры второго аргумента (т.е. размер структуры sockaddr).
В случае успешного завершения данный вызов возвращает значение 0, иначе — -1.
Механизм сокетов включает в свой состав достаточно разнообразные средства, позволяющие организовывать взаимодействие различной топологии. В частности, имеется возможность организации взаимодействия с т.н. предварительным установлением соединения. Данная модель ориентирована на организацию клиент-серверных систем, когда организуется один серверный узел процессов (обратим внимание, что не процесс, а именно узел процессов), который принимает сообщения от клиентский процессов и их как-то обрабатывает. Общая схема подобного взаимодействия представлена ниже (Рис. 91). Заметим, что тип сокета в данном случае не важен, т.е. можно использовать сокеты, являющиеся виртуальными каналами, так и дейтаграммными.
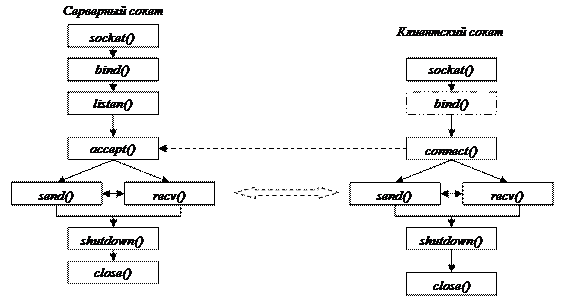
Рис. 91. Схема работы с сокетами с предварительным установлением соединения.
В данной модели можно выделить две группы процессов: процессы серверной части и процессы клиентской части. На стороне сервера открывается основной сокет. Поскольку необходимо обеспечить возможность другим процессам обращаться к серверному сокету по имени, то в данном случае необходимо связывание сокета с именем (вызов bind()). Затем серверный процесс переводится в т.н. режим прослушивания (посредством системного вызова listen()): это означает, что данный процесс может принимать запросы на соединение с ним от клиентских процессов. При этом, в вызове listen() оговаривается очередь запросов на соединение, которая может формироваться к данному процессу серверной части.
Каждый клиентский процесс создает свой сокет. Заметим, что на стороне клиента связывать сокет необязательно (поскольку сервер может работать с любым клиентом, в частности, и с «анонимным» клиентом). Затем клиентский процесс может передать серверному процессу сообщение, что он с ним хочет соединиться, т.е. передать запрос на соединение (посредством системного вызова connect()). В данном случае возможны три альтернативы.
Во-первых, может оказаться, что клиент обращается к connect() до того, как сервер перешел в режим прослушивания. В этом случае клиент получает отказ с уведомлением, что сервер в данный момент не прослушивает сокет.
Во-вторых, клиент может обратиться к connect(), а у серверного процесса в данный момент сформирована очередь необработанных запросов, и эта очередь пока не насыщена. В этом случае запрос на соединение встанет в очередь, и клиентский процесс будет ожидать обслуживания.
И, наконец, в-третьих, может оказаться, что указанная очередь переполнена. В этом случае клиент получает отказ с соответствующим уведомлением, что сервер в данный момент занят.
Итак, данная схема организована таким образом, что к одному серверному узлу может иметь множество соединений. Для организации этой модели имеется системный вызов accept(), который работает следующим образом. При обращении к данному системному вызову, если в очереди имеется необработанная заявка на соединение, создается новый локальный сокет, который связывается с клиентом. После этого клиент может посылать сообщения серверу через этот новый сокет. А сервер, в свою очередь, получая через данный сокет сообщения от клиента, «понимает», от какого клиента пришло это сообщение (т.е. клиент получает некоторое внутрисистемное именование, даже если он не делал связывание своего сокета). И, соответственно, в этом случае сервер может посылать ответные сообщения клиенту.
Завершение работы состоит из двух шагов. Первый шаг заключается в отключении доступа к сокету посредством системного вызова shutdown(). Можно закрыть сокет на чтение, на запись, на чтение-запись. Тем самым системе передается информация, что сокет более не нужен. С помощью этого вызова обеспечивается корректное прекращение работы с сокетом (в частности, это важно при организации виртуального канала, который должен гарантировать доставку посланных данных). Второй шаг заключается в закрытии сокета с помощью системного вызова close() (т.е. закрытие сокета как файла).
Далее эту концептуальную модель можно развивать. Например, сервер может порождать дочерний процесс для каждого вызова accept(), и тогда все действия по работе с данным клиентом ложатся на этот дочерний процесс. На родительский процесс возлагается задача прослушивание «главного» сокета и обработка поступающих запросов на соединение. Вот почему речь идет не об одном процессе сервере, а о серверном узле, в котором может находиться целый набор процессов.
Теперь рассмотрим модель сокетов без предварительного соединения. В этой модели используются лишь дейтаграммные сокеты. В отличие от предыдущей модели, которая была иерархически организованной, то эта модель обладает произвольной организацией взаимодействия. Это означает, что в данной модели у каждого взаимодействующего процесса имеется сокет, через который он может получать информацию от различных источников в отличие от предыдущей модели, где имеется «главный» известный всем клиентам сокет сервера, через который неявно передается управляющая информация (заказы на соединение), а затем с каждым клиентом связывается один локальный сокет. Этот механизм позволяет серверу взаимодействовать с клиентом, не зная его имя явно. В текущей модели ситуация симметричная: любой процесс через свой сокет может послать информацию любому другому сокету. Это означает, что механизм отправки имеет соответствующую адресную информацию (т.е. информацию об отправителе и получателе).
Поскольку в данной модели используются дейтаграммные сокеты, то необходимость обращаться к вызову shutdown() отпадает: в этой модели сообщения проходят (и уходят) одной порцией данных, поэтому можно сразу закрывать сокет посредством вызова close().
Далее будут более подробно рассмотрены упомянутые системные вызовы для работы с сокетами.
Для посылки запроса на соединение используется системный вызов connect().
#include <sys/types.h>
#include <sys/socket.h>
int connect(int sockfd, struct sockaddr *serv_addr,
int addrlen);
Первый параметр функции — дескриптор «своего» сокета, через который будет посылаться запрос на соединение. Второй параметр — указатель на структуру, содержащую адрес сокета, с которым производится соединение, в формате, который обсуждался выше. Третий параметр — длина структуры, передающейся вызову во втором аргументе.
В случае успешного завершения вызов возвращает значение 0, иначе возвращается -1, а в переменную errno заносится код ошибки.
Для перехода серверного процесса в режим прослушивания сокета используется системный вызов listen().
#include <sys/types.h>
#include <sys/socket.h>
int listen(int sockfd, int backlog);
Параметры вызова — дескриптор сокета и максимальный размер очереди необработанных запросов на соединение. В случае успешного завершения вызов возвращает значение 0, иначе возвращается -1, а в переменную errno заносится код ошибки.
Для подтверждения соединения используется системный вызов accept(). Этот вызов ожидает появление запроса на соединение (в очереди необработанных запросов), при появлении последнего формируется новый сокет, и его дескриптор возвращается в качестве значения функции.
#include <sys/types.h>
#include <sys/socket.h>
int accept (int sockfd, struct sockaddr *addr,
int *addrlen);
Первый параметр данной функции — дескриптор «главного» сокета. Второй параметр — указатель на структуру, в которой возвращается адрес клиентского сокета, с которым установлено соединение (если адрес клиента не интересует, передается NULL). В последнем параметре возвращается реальная длина упомянутой структуры.
Для модели с предварительным установлением соединения можно использовать системные вызовы чтения и записи в файл — соответственно, read() и write() (в качестве параметра этим функциям передается дескриптор сокета), а также системные вызовы send() (посылка сообщения) и recv() (прием сообщения).
#include <sys/types.h>
#include <sys/socket.h>
int send(int sockfd, const void *msg, int msglen,
unsigned int flags);
int recv(int sockfd, void *buf, int buflen, unsigned int flags);
Параметры: sockfd — дескриптор сокета, через который передаются данные; msg — указатель на начало сообщения; msglen — длина посылаемого сообщения; buf — указатель на буфер для приема сообщения; buflen — первоначальный размер буфера; и, наконец, параметр flags может содержать комбинацию специальных опций. Например:
- MSG_OOB — флаг сообщает ОС, что процесс хочет осуществить прием/передачу экстренных сообщений;
- MSG_PEEK — при вызове recv() процесс может прочитать порцию данных, не удаляя ее из сокета. Последующий вызов recv() вновь вернет те же самые данные.
Для организации приема и передачи сообщений в модели без предварительного установления соединения (Рис. 92) используется пара системных вызовов sendto() и recvfrom().
#include <sys/types.h>
#include <sys/socket.h>
int sendto(int sockfd, const void *msg,
int msglen, unsigned int flags,
const struct sockaddr *to, int tolen);
int recvfrom(int sockfd, void *buf,
int buflen, unsigned int flags,
struct sockaddr *from, int *fromlen);
Первые четыре параметра каждого из вызовов имеют ту же семантику, что и параметры вызовов send() и recv() соответственно. Остальные параметры имеют следующий смысл: to — указатель на структуру, содержащую адрес получателя; tolen — размер структуры to; from — указатель на структуру с адресом отправителя; fromlen — размер структуры from.
Рис. 92. Схема работы с сокетами без предварительного установления соединения.
Для завершения работы с сокетом используется системный вызов shutdown().
#include <sys/types.h>
#include <sys/socket.h>
int shutdown (int sockfd, int mode);
Первый параметр — дескриптор сокета, второй — режим закрытия соединения:
- 0 — сокет закрывается для чтения;
- 1 — сокет закрывается для записи;
- 2 — сокет закрывается и для чтения, и для записи.
Для закрытия сокета используется системный вызов close(), в котором в качестве параметра передается дескриптор сокета.[R26]
4 Файловые системы
4.1 Основные концепции
Под[R27] файловой системой (ФС) мы будем понимать часть операционной системы, представляющую собой совокупность организованных наборов данных, хранящихся на внешних запоминающих устройствах, и программных средств, гарантирующих именованный доступ к этим данным и их защиту.
Файловая система является с точки зрения пользователя первым виртуальным ресурсом (который появился в операционных системах), достаточно понятным и достаточно просто используемым во время его работы за машиной. Если сравнить ФС с другим виртуальным ресурсом — например, виртуальной памятью, то рядовому пользователю ПК может быть совсем не понятным, зачем нужен механизм виртуальной памяти. Появление ФС кардинально изменило взгляд на использование вычислительных систем. Почти сразу с момента использования вычислительной техники возникла проблема размещения данных во внешней памяти. Необходимость поддержки этого размещения обуславливалось несколькими причинами. Во-первых, была тривиальная необходимость сохранения данных: время «одноразовых» решений задач (когда требовалось, грубо говоря, лишь вычислить значение некой формулы) прошло достаточно быстро. Появились задачи, требующие больших объемов начальных данных, которые, в свою очередь, являлись результатом решения другой задачи. И эти данные надо было где-то сохранять, причем, сохранять без наличия программ, которые их используют. Как следствие, возникла проблема эффективности доступа к этим данным. Вторая необходима проблема — это само сохранение информации (и программ, и данных). Имеется в виду, сам факт долгосрочного хранения информации.
С точки зрения аппаратной поддержки можно выделить следующие этапы развития. Одним из первых внешних запоминающих устройств (ВЗУ) была магнитная лента. Магнитная лента — это устройство последовательного доступа, информация на котором хранится в виде записей (фиксированного или переменного размера). Запись структурно состоит из последовательности содержательной информации, ограниченной маркерами начала и конца записи. Для доступа к информации необходимо иметь номер соответствующей записи на ленте. Соответственно, если пользователь хотел сохранять данные на магнитной ленте, то ему было необходимо знать магнитную ленту как носитель (по номеру или по расположению в хранилище, и т.п.) и номер своей записи на этой ленте. Отметим, что относительно эффективная работа с лентой может быть достигнута лишь при персональном использовании: в случае, когда одновременно с одной лентой работают два пользователя, возникают достаточно большие накладные расходы (в частности, частое перематывание ленты на начало), что может привести даже к ее порче (разрыву). Решение проблемы корректности организации данных на магнитной ленте лежало на пользователе: если пользователь некорректно организовал запись своих данных, то он мог тем самым испортить и свои данные, и чужие записи на ленте.
На следующем этапе развития появились устройства прямого доступа (барабаны и магнитные диски), что естественно сказалось на адресации данных на носителе. Например, чтобы получить доступ к информации на диске, достаточно знать номер диска, номер поверхности, номер цилиндра и номер сектора. Но каждое устройство прямого доступа имело и свои особенности — в частности, размеры блока: у одних дисков блоки имели размер 256 байт, у других — 512 байт, и т.д. И эти особенности должен был учитывать пользователь при работе с данными устройствами. Чтобы разместить свой файл на диске, пользователь должен был разбить этот файл на блоки (в зависимости от конкретного устройства хранения), найти на диске свободные блоки, чтобы в них разместить весь свой файл, сохранить файл и запомнить координаты и последовательность блоков, в которых был сохранен файл. Заметим, что диски ориентированы на массовое использование, т.е. предполагается работа с ним двух и более пользователей, что накладывало дополнительные трудности на корректное размещение данных на диске — задачу, совершенно нетривиальную для рядового пользователя.
Подобный подход к хранению данных продлился примерно до середины 60-х — начала 70-х годов, когда в машинах второго поколения появился программный компонент операционной системы, который получил название файловая система. Повторимся, файловая система — это компонент операционной системы, обеспечивающий корректный именованный доступ к данным пользователя. Данные в файловой системе представляются в виде файлов, каждый из которых имеет имя. Главными словами в определении файловой системы являются именованный доступ и корректная работа. Последнее означает, что файловая система обеспечивает корректное управление свободным и занятым пространством на ВЗУ (заметим, что не обязательно на физическом устройстве: в качестве ВЗУ может выступить и виртуальное устройство), а также защиту от несанкционированного доступа к информации. Большинство современных файловых систем обеспечивают корректную организацию распределенного доступа к одному и тому же файлу (когда с ним могут работать два и более пользователя). Это не означает, что система будет отвечать за корректную семантику данных внутри файла: гарантируется, что система обеспечит корректный доступ пользователей к файлу с точки зрения системной организации. Также многие современные файловые системы поддерживают возможность синхронизации доступа к информации.
4.1.1 Структурная организация файлов
С точки зрения структурной организации файлов имеется целый спектр различных подходов. Существует некоторая установившаяся систематизация методов структурной организации файлов. Рассмотрим модели в соответствии с хронологией их появления.
Первой моделью файла явилась модель файла как последовательности байтов. В этом случае содержимое файла представляется как неинтерпретируемая информация (или интерпретируемая примитивным образом). Задача интерпретации данных ложится на пользователя. Данная модель файла наиболее распространена на сегодняшний день: большинство широко используемых файловых систем поддерживают возможность представлять содержимое файла как последовательности байтов, а это означает, что программные интерфейсы, обеспечивающие доступ к содержимому файла, позволяют считывать и записывать произвольные порции данных.
Следующие модели представляют файл как последовательность записей переменной и постоянной длины. Первая из этих моделей является аналогом магнитной ленты. Соответственно, эта организация файла и рассчитана на работу с магнитными лентами. В этом случае возникают проблемы, такие как коррекция данных в середине файла, вследствие чего меняется размер файла, и появляется необходимость сдвигать «хвост» файла на ленте.
Модель файла как последовательности записей постоянной длины является также аппаратно-ориентированной: она является аналогом перфокарты. Перфокарта представляет собою картонный листок прямоугольной формы, на котором изображены двенадцать строк по 80 позиций в каждой. Каждая позиция соответствует одному биту информации. Соответственно, перфокарта может хранить лишь фиксированное количество данных, поэтому для отображения колоды перфокарт в файл подходит модель файла как последовательности записей фиксированного размера (каждая запись являлась образом одной перфокарты). Данная модель имеет следующие недостатки. Во-первых, из-за того, что каждая запись имеет фиксированный размер, возникает внутренняя фрагментация: т.е. если хотя бы один байт занят в записи, то занят и весь объем записи. Также остаются проблемы, возникающие при необходимости вставить или удалить запись из середины файла.
И, наконец, модель иерархической организации файла. В данной модели организация файла имеет сложную логическую структуру, позволяющую организовывать динамическую работу с данными. Одной из наиболее распространенных структур является дерево, в узлах которого расположены записи. Каждая запись состоит из двух полей: поле ключа и поле данных. В качестве ключа может выступать номер записи. Данная модель является удобной для редактирования файла, но с другой стороны требует достаточной сложной реализации.
Еще одной исторической характеристикой файлов были режимы доступа, отражавшие организацию внешних устройств. Были файлы прямого доступа и файлы последовательного доступа. Режим доступа задавался на этапе создания файла. В современных файловых системах эти режимы не используются. Зато актуальны режимы доступа с точки зрения разрешения или запрета на определенные операции: возможно иметь доступ только по чтению, только по записи или по чтению-записи информации в файл.
4.1.2 Атрибуты файлов
Каждый файл обладает фиксированным набором параметров, характеризующих свойства и состояния файла, причем и долговременное (стратегическое), и оперативное состояния. Совокупность этих параметров называют атрибутами файла. В набор атрибутов может входить достаточно большое количество параметров, и состав атрибутов зависит от конкретной реализации системы. Среди атрибутов часто можно встретить следующие параметры: имя файла, права доступа, персонификация (создатель/владелец), тип файла, размер записи (блока), размер файла, указатель чтения/записи, время создания, время последней модификации, время последнего обращения, предельный размер файла и т.п.
Под именем файла понимается последовательность символов, используя который организуется именованный доступ к данным файла. В одних файловых системах имя файла воспринимается в качестве атрибута, другие ФС разделяют файл (его содержимое), имя и отдельно набор атрибутов.
Следующим немаловажным атрибутом являются права доступа. Данный атрибут характеризует возможность доступа к содержимому файла различным категориям пользователей. Структура категорий пользователей, по которой организуется доступ, зависит от конкретной операционной системы. В частности, существуют операционные системы, в которых прав доступа нет: файлы доступны любому пользователю системы.
Следующий атрибут — персонификация — связан с предыдущим. Соответственно, данный атрибут содержит информацию о принадлежности файла. В общем случае здесь может находиться несколько параметров: например, информация о создателе файла, а также информация о владельце файла. Зачастую эти параметры совпадают, но возможны ситуации, когда они отличаются.
Тип файла — информация о способе организации файла и интерпретации его содержимого. Говоря о способе организации, можно привести пример файловой системы ОС Unix, которая поддерживает разные типы файлов. Среди прочих имеются т.н. файлы устройств, соответствующие тем устройствам, которые обслуживает данная ОС; и через эти файлы устройств происходит фактически обращение к драйверам устройств. Совсем иначе организованы регулярные файлы, которые могут хранить различную информацию (текстовую, графическую и пр.). О различных способах организации речь пойдет ниже.
Если речь идет об интерпретации, то она может быть явной и неявной, т.е. возможно указание, как интерпретировать содержимое файла. Например, можно указать, является ли данный файл исполняемым или неисполняемым. Исполняемый файл можно запустить как процесс, в отличие от неисполняемого. Таким образом, атрибут типа файла может содержать многоуровневую комплексную информацию.
Размер записи (или размер блока). В системе имеется возможность указать, что какой-то файл организован в виде последовательности блоков данного размера, при этом размер определяется пользователем (пользовательским процессом). Размер может быть стационарным, когда при создании файла указывается фиксированный размер блоков, и нестационарным, когда размер блока задается каждый раз при открытии файла.
Размер файла. Данный атрибут имеет достаточно простой смысл, заметим, что обычно размер файла задается в байтах.
Указатель чтения/записи — это указатель, относительно которого происходит чтение или запись информации. В общем случае с каждым файлом ассоциируются два указателя (и на чтение, и на запись), хотя бывают файловые системы, в которых используется единый указатель чтения/записи. Соответственно, операции чтения/записи оперируют данными, следующими за указателями.
Среди прочих атрибутов файла возможны атрибуты, отражающие системную и статистическую информацию о файле: например, время последней модификации, время последнего обращения, предельный размер файла и т.д. Еще одной важной группой атрибутов являются атрибуты, хранящие информацию о размещении содержимого файла, т.е. где в файловой системе организовано хранение данных файла, и как оно организовано.
4.1.3 Основные правила работы с файлами. Типовые программные интерфейсы
Практически все файловые системы при организации работы с файлами действуют по схожим сценариям, которые в общем случае состоят из трех основных блоков действий.
Во-первых, это начало работы с файлом (или открытие файла). Большинство систем для процессов, желающих работать с файлом, предполагают наличие операции открытия файла. Посредством данной операции процесс передает файловой системе запрос на работу с конкретным файлом. Получив запрос, файловая система производит соответствующие проверки возможности (в т.ч. на наличие полномочий) работы с файлом, в случае успеха выделяет внутри себя необходимые ресурсы для работы процесса с указанным файлом. В частности, для каждого открытого файла создается т.н. файловый дескриптор, в котором отражается актуальное состояние открытого файла (режимы, позиции указателей и т.п.). Файловый дескриптор, как системная структура данных, может размещаться как в адресном пространстве процесса, так и в пространстве памяти операционной системы. Соответственно, при открытии файла процесс получает либо номер файлового дескриптора, либо указатель на начало данной структуры. Все последующие операции с содержимым файла происходят с указанием именно файлового дескриптора, и эти операции образуют следующий блок действий.
Второй блок действий образуют операции по работе с содержимым файла (чтение и запись), также операции, изменяющие атрибуты файла (режимы доступа, изменение указателей чтения/записи и т.п.).
Последний этап — это закрытие файла: уведомление системы о закрытии процессом файлового дескриптора (а не файла). Подчеркнем, что процесс прекращает работу не с файлом, а с конкретным файловым дескриптором, поскольку даже в рамках одного процесса можно открыть один и тот же файл два и более раза, и на каждое открытие будет предоставлен новый файловый дескриптор. После операции закрытия операционная система выполняет необходимые действия по корректному завершению работы с файловым дескриптором, а если закрывается последний открытый дескриптор — то корректное завершение работы с файлом: в частности, по необходимости освобождаются системные ресурсы, в т.ч. разгрузка кэш-буферов файловых обменов, и т.д.
Структурно каждая операционная система предлагает унифицированный набор интерфейсов, посредством которых можно обращаться к системным вызовам работы с файлами. Обычно этот набор содержит следующие основные функции:
- open — открытые/создание файла;
- close — закрытие;
- read/write — читать/писать (относительно указателя чтения/записи соответственно);
- delete — удалить файл из файловой системы;
- seek — позиционирование указателя чтения/записи;
- read_ attributes/write_ attributes — чтение/модификация некоторых атрибутов файла (в файловых системах, рассматривающих имя файла не как атрибут, возможны дополнительная функция переименования файла — rename).
Практически все файловые системы включают в свой состав некоторый специальный компонент, посредством которого можно установить соответствие между именем файла и его атрибутами. Используя это соответствие, можно получить информацию о размещении данных в файловой системе и организовать доступ к данным. И этим компонентом является каталог. Итак, каталог — это системная структура данных файловой системы, в которой находится информация об именах файлов, а также информация, обеспечивающая доступ к атрибутам и содержимому файла.
Рассмотрим типовые модели организации каталогов (в соответствии с хронологическим порядком их появления).
Первой исторической моделью является одноуровневая файловая система (система с одноуровневым каталогом). В файловой системе данного типа (Рис. 93) присутствует единственный каталог, в котором перечислены всевозможные имена файлов, находящихся в данной системе. Этот каталог устроен простым способом: о каждом файле хранится информация об его имени, расположении первого блока и размере файла. Эта простота влечет за собой и простоту доступа к информации файлов, но эта модель не предполагает многопользовательской работы. В данном случае возможны коллизии имен (когда возникают попытки создания файлов с одним именем). Данная модель в настоящее время используется в бытовой технике, которая выполняет фиксированный набор действий.

Рис. 93. Модель одноуровневой файловой системы.
Следующей моделью является двухуровневая файловая система (Рис. 94). Данная модель предполагает работу нескольких пользователей: файловая система этого типа позволяет группировать файлы по принадлежности тому или иному пользователю. Эта модель лучше одноуровневой (в частности, не возникают коллизии имен файлов разных пользователей), но и она обладает недостатками: зачастую неудобно и даже нежелательно расположение всех файлов одного пользователя в одном месте (в одном каталоге). В частности, остается проблема коллизии имен для файлов одного пользователя.
Отметим, что двух-, трех- и вообще N-уровневые (N – фиксированное) модели остаются актуальными и по сей день. Объясняется это тем, что они, в первую очередь, достаточно просты по своей структуре и организации работы с ними. Если мы посмотрим на простейший мобильный телефон, имеющий несколько уровней меню, в них обычно реализованы именно подобные файловые системы.
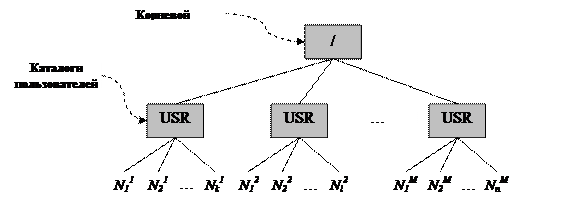
Рис. 94. Модель двухуровневой файловой системы.
И, наконец, последняя модель, которую мы рассмотрим, — иерархическая файловая система (Рис. 95). Современные многопользовательские файловые системы основываются на использовании иерархических структур данных, в частности, на использовании деревьев.
Вся информация в файловой системе представляется в виде дерева, имеющего корень. Это т.н. корневая файловая система. В узлах дерева, отличных от листьев, находятся каталоги, которые содержат информацию о размещенных в них файлах. Иерархические файловые системы обычно имеют специальный тип файлов-каталогов. Т.е. каталог представляется не как отдельная выделенная структура данных, а как файл особого типа. Листом дерева может быть либо файл-каталог, либо любой файл файловой системы.
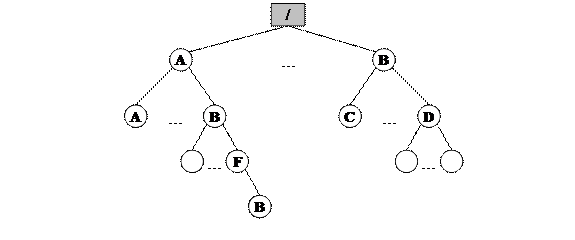
Рис. 95. Модель иерархической файловой системы.
Иерархическая (или древообразная) организация файловой системы предоставляет возможность использования уникального именования файлов. Оно основывается на том, что в дереве существует единственный путь от корня до любого узла. Приведенная схема именования (от корня до конкретного узла дерева) является принципиальной схемой именования файлов в иерархических файловых системах. При этом обычно используются следующие характеристики. Текущий каталог — это каталог, на работу с которым в данный момент настроена файловая система. Текущим каталогом может стать любой каталог файловой системы, и обозревание файлов в файловой системе происходит относительно этого каталога. Файлы, находящиеся непосредственно в текущем каталоге доступны «просто» по имени. Таким образом, имя файла — это имя файла, находящего в текущем каталоге, а полное имя файла — это перечень всех имен файлов от корня до узла с данным файлом. Признаком полного имени обычно является присутствие специального префиксного символа, обозначающего корневой каталог (например, в ОС Unix в качестве корневого каталога выступает символ “/”).
Иерархическая файловая система позволяет использовать т.н. относительные имена файлов — это путь от некоторого каталога до данного файла. Для данного способа именования необходимо указать явно или неявно каталог, относительно которого строится это именование. Например, если существует файл с полным именем /A/B/ C/D, то относительно каталога B файл будет иметь имя C/D. Чтобы использовать это относительное имя, необходимо либо явно задать каталог B (по сути это означает задание полного имени), либо сделать каталог B текущим.
Иерархические файловые системы обычно используют еще одну характеристику — т.н. домашний каталог. Суть его заключается в том, что для каждого зарегистрированного в системе пользователя (или для всех пользователей) задается полное имя каталога, который должен стать текущим каталогом при входе пользователя в систему.
4.1.4 Подходы в практической реализации файловой системы
Рассмотрим[R28] некоторые подходы в практической реализации файловой системы. Снова вернемся к понятию системного устройства — устройства, на котором, как считается аппаратурой компьютера, должна присутствовать операционная система. Почти в любом компьютере можно определить некоторую цепочку внешних устройств, которые при загрузке компьютера рассматриваться как системные устройства. В этой цепочке имеется определенный приоритет. Во время старта вычислительная система (компьютер) перебирает данную цепочку в порядке убывания приоритета до тех пор, пока не обнаружит готовое к работе устройство. Система предполагает, что на этом устройстве имеется необходимая системная информация и пытается загрузить с него операционную систему. Например, допустим, что компьютер сконфигурирован таким образом, что первым системным устройством является флоппи-дисковод, вторым — дисковод оптических дисков (CDROM), а третьим — жесткий диск. Мы поместили во флоппи-дисковод дискету и включили компьютер. Аппаратный загрузчик обращается к первому системному устройству, поскольку в дисководе присутствует дискета, то считается, что дисковод готов к работе. Тогда происходит попытка загрузки операционной системы с дисковода, и если это будет неуспешно, то будет выведено сообщение об ошибке загрузки системы. Если же дискеты во флопе-дисководе не будет, но будет находиться диск в CDROM, то точно так же будет предпринята попытка загрузить операционную систему, но уже с оптического диска. Если же не будет ни флоппи-дискеты, ни оптического диска, то загрузчик попытается загрузить операционную систему с жесткого диска. Обычно в штатном режиме загрузка происходит с жесткого диска, но в ситуации, например, краха системы и невозможности загрузиться с жесткого диска приведенная модель позволяет загрузить систему со съемного носителя и произвести некие действия по восстановлению работоспособности поврежденной системы.
В приведенной модели работа аппаратного загрузчика основана на предположении о том, что любое системное устройство имеет некоторую предопределенную структуру. В начальном блоке системного устройства располагается основной программный загрузчик (MBR — Master Boot Record).В качестве основного программного загрузчика может выступать как загрузчик конкретной операционной системы, так и некоторый унифицированный загрузчик, имеющий информацию о структуре системного диска и способный загружать по выбору пользователя одну из альтернативных операционных систем.

Рис. 96. Структура «системного» диска.
В общем случае после блока основного программного загрузчика на диске следует последовательность блоков, в которых находится т.н. таблица разделов. В современных жестких дисках имеется возможность разбивать все физическое пространство диска на некоторые области, которые называются разделами (partition). Внутри каждого раздела может быть помещена в общем случае своя операционная система. Соответственно, границы каждого раздела (его конец и начало) регистрируются в указанной таблице разделов. Еще одно важное применение данной таблицы связано с тем, что современные диски имеют настолько большие емкости, что для адресации произвольной точки диска не хватает разрядной сетки процессора. И за счет косвенной адресации (адресации относительно начала раздела) использование подобной таблицы позволяет решить данную проблему.
Логическая структура раздела имеет следующий вид. В начальном блоке раздела находится загрузчик конкретной операционной системы. Все остальное пространство раздела обычно занимает файловая система. Зачастую в файловой системе часть пространства выделяется т.н. суперблоку, в котором хранятся настройки (размеры блоков, режимы работы и т.п.) и информация об актуальном состоянии (информация о свободных и занятых блоках и т.п.) файловой системы. Все оставшееся пространство файловой системы состоит из свободных и занятых блоков, т.е. блоков, способных хранить системные и пользовательские данные.
Прежде, чем продолжить изучение способов организации файловых систем, хотелось бы остановиться и еще раз просмотреть, что происходит при загрузке компьютера. При включении компьютера управление передается аппаратному загрузчику, который просматривает согласно приоритетам список системных устройств, определяет готовое к работе устройство и передает управление основному программному загрузчику этого устройства. Последний является программным компонентом и может загрузить конкретную операционную систему, а может являться мультисистемным загрузчиком, способным предложить пользователю выбрать, какую из операционных систем, расположенных в различных разделах диска, загрузить. В одном разделе может находиться, например, ОС Microsoft Windows XP, в другом — Linux, в третьем — FreeBSD, и т.д. Данный мультисистемный загрузчик владеет информацией, какая операционная система в каком разделе диска находится. После того, как пользователь сделал свой выбор, загрузчик по таблице разделов определяет координаты соответствующего раздела и передает управление загрузчику операционной системы указанного раздела. Соответственно, загрузчик операционной системы производит непосредственную загрузку этой ОС.
Говоря об иерархии блоков, у многих создается впечатление, что такие понятия, как, например, блоки файла, блоки файловой системы, блоки устройств и т.п., обозначают одно и то же, что, в общем случае, неверно. Большинство современных операционных систем поддерживают целую иерархию блоков, используемую при организации работы с блок-ориентированными устройствами. В основе этой иерархии лежит блоки физического устройства, т.е. это те порции данных, которыми можно совершать обмен с данным физическим устройством. Более того, размер блока физического устройства зависит от конкретного устройства. Соответственно, детали этого уровня иерархии скрываются следующим уровнем абстракции — блоками виртуального диска. Следующий уровень иерархии — уровень блоков файловой системы. Эти блоки используются при организации структуры файловой системы. Размер блока файловой системы, равно как и виртуального диска, является стационарной характеристикой, определяемой при настройке системы, и в динамике эта характеристика не меняется. И, наконец, последний уровень представляют блоки файла. Размер данных блоков может определить пользователь при открытии или создании файла (как об этом говорилось выше). Отметим, что размер блока, в конечном счете, влияет на эффективность работы, которая будет несколько выше, если размеры всех блоков будут хотя бы кратны друг другу.
4.1.5 Модели реализации файлов
Первой тривиальной и самой эффективной с точки зрения минимизации накладных расходов является модель непрерывных файлов (Рис. 97). Данная модель подразумевает размещение каждого файла в непрерывной области внешнего устройства. Эта организация достаточно простая: для обеспечения доступа к файлу среди атрибутов должны присутствовать имя, блок начала и длина файла. Но тут возникают следующие проблемы. Во-первых, внутренняя фрагментация (хотя это проблема почти всех блок-ориентированных устройств). В качестве иллюстрации можно привести следующее: если необходимо хранить всего один байт, то для этого будет выделен целый блок, который, по сути, будет пустым. Во-вторых, это фрагментация между файлами (эта проблема обсуждалась при рассмотрении моделей организации работы оперативной памяти). Но данная система имеет и некоторые достоинства, и немаловажное из них — отсутствие фрагментации файла по диску: поскольку файл хранится в единой непрерывной области диска, то при считывании файла головка жесткого диска совершает минимальное количество механических движений, что означает более высокую производительность системы. Соответственно, при реализации данной модели должна решаться важная проблема, возникающая при модификации файла, в частности, при увеличении его содержательной части. Чтобы несколько упростить эту задачу, зачастую используют такой прием: при создании файла к запрошенному объему добавляют некоторое количество свободного пространства (например, 10% от запрошенного объема), но этот же прием ведет к увеличению внутренней фрагментации. Еще одной немаловажной проблемой является фрагментация свободного пространства. Файловые системы, реализующие данную модель хранения файла, являются деградирующими: в ходе эксплуатации фрагментация свободного пространства увеличивается, и в итоге на диске имеется множество мелких свободных участков, имеющих очень большой суммарный объем, но из-за своего небольшого размера эти участки использовать не представляется возможным. Для разрешения этой проблемы необходимо запускать процесс компрессии (дефрагментации), который занимается тем, что сдвигает файлы с учетом зарезервированного для каждого файла «запаса», «прижимая» их друг к другу. Эта операция трудоемкая, продолжительная и опасная, поскольку при перемещении файла возможен сбой.

Рис. 97. Модель непрерывных файлов.
Следующей моделью является модель файлов, имеющих организацию связанного списка (Рис. 98). В этой модели файл состоит из блоков, каждый из которых включает в себя две составляющие: данные, хранимые в файле, и ссылка на следующий блок файла. Эта модель также является достаточно простой, достаточно эффективной при организации последовательного доступа, а также эта модель решает проблему фрагментации свободного пространства. С другой стороны, обозначенная модель не предполагает прямого доступа: чтобы обратиться к i-ому блоку, необходимо последовательно просмотреть все предыдущие. Также эта модель предполагает фрагментацию файла по диску, т.е. содержимое файла может быть рассредоточено по всему дисковому пространству, а это означает, что при последовательном считывании содержимого файла добавляется значительная механическая составляющая, снижающая эффективность доступа. И еще одним недостатком данной модели является то, что в каждом блоке присутствует и системная, и пользовательская информация. Возможна ситуация, что при необходимости считать данные, объемом в один логический блок, реально происходит чтение двух блоков.
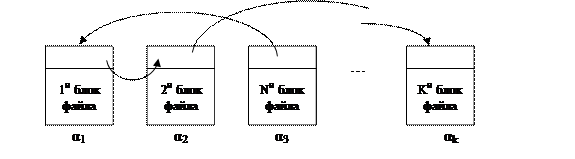
Рис. 98. Модель файлов, имеющих организацию связанного списка.
Другой подход иллюстрирует модель, основанная на использовании т.н. таблицы размещения файлов (File Allocation Table — FAT, Рис. 99). В этой модели операционная система создает программную таблицу, количество строк в которой совпадает с количеством блоков файловой системы, предназначенных для хранения пользовательских данных. Также имеется отдельный каталог (или система каталогов), в котором для каждого имени файла имеется запись, содержащая номер начального блока. Соответственно, таблица размещения имела позиционную организацию: i-ая строка таблицы хранит информацию о состоянии i-ого блока файловой системы, а, кроме того, в ней указывается номер следующего блока файла. Чтобы получить список блоков файловой системы, в которых хранится содержимое конкретного файла, необходимо по имени в указанном каталоге найти номер начального блока, а затем, последовательно обращаясь к таблице размещения и извлекая из каждой записи номер следующего блока, возможно построение искомого списка. Данное решение выглядит эффективнее предыдущего. Во-первых, в этом решении весь блок используется полностью для хранения содержимого файла. Во-вторых, при открытии файла можно составить список блоков данного файла и, следовательно, осуществлять прямой доступ. Заметим, что для максимальной эффективности необходимо, чтобы эта таблица целиком размещалась в оперативной памяти, но для современных дисков, имеющих огромные объемы, данная таблица будет иметь большой размер (например, для 60ти-гигабайтного раздела и блоков, размером 1 килобайт, потребуется 60 000 000*4(байта) = 240 мегабайт), что является одним из недостатков рассматриваемой модели. Другим недостатком является ограничение на размер файла в силу ограниченности длины списка блоков, принадлежащих данному файлу.
Рис. 99. Таблица размещения файлов (FAT).
Следующая модель — модель организации файловой системы с использованием т.н. индексных узлов (дескрипторов). Принцип модели состоит в том, что в атрибуты файла добавляется информация о номерах блоков файловой системы, в которых размещается содержимое файла. Это означает, что при открытии файла можно сразу получить перечень блоков. Соответственно, необходимость использования FAT-таблицы отпадает, зато, с другой стороны, при предельных размерах файла размер индексного дескриптора становится соизмеримым с размером FAT-таблицы. Для разрешения этой проблемы существует два принципиальных решения. Во-первых, это тривиальное ограничение на максимальный объем файла. Во-вторых, это построение иерархической организации данных о блоках файла в индексном дескрипторе. В последнем случае вводятся иерархические уровни представления информации: часть (первые N) блоков перечисляются непосредственно в индексном узле, а оставшиеся представляются в виде косвенной ссылки. Это решение имеет следующие преимущества. Нет необходимости в размещении в ОЗУ информации всей FAT обо всех файлах системы, в памяти размещаются атрибуты, связанные только с открытыми файлами. При этом индексный дескриптор имеет фиксированный размер, а файл может иметь практически «неограниченную» длину.
4.1.6 Модели реализации каталогов
Существуют несколько подходов организации каталогов. Во-первых, каталог может представляться в виде таблицы, у которой в одной колонке находятся имена файлов, а в остальных — все атрибуты. Эта модель хороша тем, что все необходимые данные находятся в оперативной доступности, зато размер записи в таблице каталога, да и сама таблица, может быть большой (например, из-за большого числа атрибутов), что влечет за собой долгий поиск в каталоге. Другой подход заключается в том, что каталог также представляется в виде таблицы, в которой один столбец хранит имена, а в другом хранится ссылка на системную таблицу, содержащую атрибуты соответствующего файла. Этот подход имеет дополнительное преимущество, заключающееся в том, что для разных типов файлов можно иметь различный набор атрибутов.
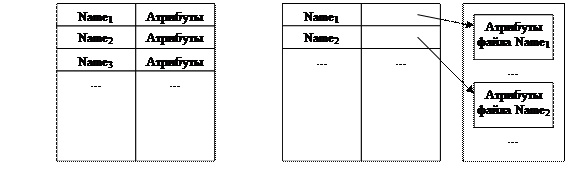
Рис. 100. Модели организации каталогов.
Одной из проблем, встречающейся в организации каталогов, является проблема длины имени. Изначально эта проблема решалась достаточно просто: имя файла было ограничено шестью или восемью символами. В современных системах разрешается присваивать файлам достаточно длинные имена. И, как следствие, встает иная проблема: для эффективной работы с каталогом необходимо, чтобы информация в каталогах хранилась в сжатом виде, в т.ч. и имена файлов должны быть короткими. О некоторых решениях данной проблемы речь пойдет ниже при обсуждении файловой системы ОС Unix.
4.1.7 Соответствие имени файла и его содержимого
Еще один момент, на который стоит обратить внимание при рассмотрении организации файловых систем, — это проблема соответствия между именем файла и содержимым этого файла.
Как отмечалось выше, у любого файла есть его имя как отдельная характеристика файла или же как один из атрибутов файла. В различных файловых системах по-разному решается указанная проблема соответствия имени и содержимого. Первый очевидный подход заключается в том, что устанавливается взаимнооднозначное соответствие, т.е. для каждого содержимого файла в системе существует единственное имя, ассоциированное с этим содержимым, и обратно — для каждого имени существует единственное содержимое.
На сегодняшний день почти все современные файловые системы позволяют нарушать это взаимнооднозначное соответствие путем предоставления возможности установления для одного и того же содержимого файла двух и более имен. При этом, существуют несколько моделей организации данного подхода.
Первая модель — это симметричное, или равноправное, именование. В этом случае с одним и тем же содержимым ассоциируется группа имен, каждое из которых равноправное. Это означает, что какое бы из имен, ассоциированных с данным содержимым, не взяли, мы посредством этого имени можем выполнить все операции, и они будут выполнены одинаково. Такая модель реализована в некоторых файловых системах посредством установления т.н. жесткой связи (Рис. 101). В этом случае среди атрибутов есть счетчик имен, ссылающихся на данное содержимое. Уничтожая файл с одним из этих имен, производится следующий порядок действий. Файловая система уменьшает счетчик имен на единицу; если счетчик обнулился, то в этом случае удаляется содержимое, иначе файловая система удаляет только указанное имя файла из соответствующего каталога. Заметим, что при такой организации древовидность файловой системы (древовидность размещения файлов) нарушается, поскольку имена, ассоциированные с одним и тем же содержимым, можно разместить в разных узлах дерева, т.е. произвольных каталогах файловой системы. Но сохраняется древовидность именования файлов.

Рис. 101. Пример жесткой связи.
Следующей модель организации — это «мягкая» ссылка, или символическая связь (хотя здесь лучше бы подошло название символьной связи, Рис. 102). Данное именование является несимметричным, суть которого заключается в следующем. Пускай существует содержимое файла, с которым жесткой связью ассоциировано некоторое имя (Name2). К этому файлу теперь можно организовать доступ через файл-ссылку. Это означает, что создается еще один файл некоторого специального типа (типа файла-ссылки), в атрибутах которого указывается его тип и то, что он ссылается на файл с именем Name2. Теперь можно работать с содержимым файла Name2 посредством косвенного доступа через файл-ссылку. Но некоторые операции с файлом-ссылкой будут происходить иначе. Например, если вызывается операция удаления файла-ссылки, то удаляется именно файл-ссылка, а не файл с именем Name2. Если же явно удалить файл Name2, то в этом случае файл-ссылка окажется висячей ссылкой.
Рис. 102. Пример символической связи.
4.1.8 Координация использования пространства внешней памяти
С точки зрения организации использования пространства внешней памяти файловой системой существует несколько аспектов, на которые необходимо обратить внимание. Первый момент связан с проблемой выбора размера блока файловой системы. Задача определения оптимального размера блока не имеет четкого решения. Если файловая система предоставляет возможность квотировать размер блока, то надо учитывать, что больший размер блока ведет к увеличению производительности файловой системы (поскольку данные файла оказываются локализованными на жестком диске, из чего следует, что при доступе снижается количество перемещений считывающей головки). Но недостатком является то, что чем больше размер блока, тем выше внутренняя фрагментация, а, следовательно, неэффективность использования пространства ВЗУ (если, блок, к примеру, имеет размер 1024 байт, а файл занимает 1 байт, то теряются 1023 байта). Альтернативой являются блоки меньшего размера, которые снижают внутреннюю фрагментацию, но при выборе меньшего размера блока повышаются накладные расходы при доступе к файлу в связи фрагментация файла по диску.
Еще одна проблема, на которую стоит обратить внимание, — это проблема учета свободных блоков файловой системы. Здесь тоже существует несколько подходов решения, среди которых нельзя выбрать наилучший: каждый из них имеет свои достоинства и недостатки.
Первый подход заключается в том, что вся совокупность свободных блоков помещается в единый список, т.е. номера свободных блоков образуют связный список, который располагается в нескольких блоках файловой системы. Для более эффективной работы первый блок, содержащий начальную часть списка, должен располагаться в ОЗУ, чтобы файловая система могла к нему оперативно обращаться. Заметим, что размер списка может достигать больших размеров: если размер блока 1 Кбайт, т.е. его можно представить в виде 256 четырехбайтных слов, то такой блок может содержать в себе 255 номеров свободных блоков и одну ссылку на следующий блок со списком, тогда для жесткого диска, емкостью 16 Гбайт, потребуется 16794 блока. Но размер списка не столь важен, поскольку по мере использования свободных блоков этот список сокращается, при этом освобождающиеся блоки, хранившие указанный список, ничем не отличаются от других свободных блоков файловой системы, а значит, их можно использовать для хранения файловых данных.
Вторая модель основана на использовании битовых массивов. В этом случае каждому блоку файловой системе ставится в соответствие двоичный разряд, сигнализирующий о незанятости данного блока. Для организации данной модели необходимо подсчитать количество блоков файловой системы, рассчитать количество разрядов массива, а также реализовать механизм пересчета номера разряда в номер блока и наоборот. Заметим, что операция пересчета достаточно трудоемка, к тому же эта модель требует выделение под массив стационарного ресурса: так, для 16-тигигабайтного жесткого диска потребуется 2048 блоков для хранения битового массива.
4.1.9 Квотирование пространства файловой системы
Как отмечалось выше, файловая система должна обеспечивать контроль использования двух видов системных ресурсов — это регистрация файлов в каталогах (т.е. контроль количества имен файлов, которое можно зарегистрировать в каталоге) и контроль свободного пространства (чтобы не возникла ситуация, когда один процесс заполнил все свободное пространство, тем самым не давая другим пользователям возможность сохранять свои данные). Для решения поставленных задач в файловой системе вводятся квотирование имен (т.е. числа) файлов и квотирование блоков.
В общем случае модель квотирования может иметь два типа лимитов: жесткий и гибкий. Для каждого пользователя при регистрации его в системе для него определяются два типа квот. Жесткий лимит — это количество имен в каталогах или блоков файловой системы, которое он превзойти не может: если происходит превышение жесткого лимита, работа пользователя в системе блокируется. Гибкий лимит — это значение, которое устанавливается в виде лимита; с ним ассоциировано еще одно значение, называемое счетчиком предупреждений. При входе пользователя в систему происходит подсчет соответствующего ресурса (числа имен файлов либо количества используемых пользователем блоков файловой системы). Если вычисленное значение не превосходит гибкий лимит, то счетчик предупреждений сбрасывается на начальное значение, и пользователь продолжает свою работу. Если же вычисленное значение превосходит установленный гибкий лимит, то значение счетчика предупреждений уменьшается на единицу, затем происходит проверка равенства его значения нулю. Если равно нулю, то вход пользователя в систему блокируется, иначе пользователь получает предупреждение о том, что соответствующий гибкий лимит израсходован, после чего пользователь может работать дальше. Таким образом, система позволяет пользователю привести свое «файловое пространство» в порядок в соответствии с установленными квотами.

Рис. 103. Квотирование пространства файловой системы.
Рассмотренная модель имеет большую эффективность при использовании именно пары этих параметров. Если в системе реализовано лишь гибкий лимит, то можно реализовать упоминавшуюся картину: пользовательский процесс может «забить» все свободное пространство файловой системы. Данную проблему решает жесткий лимит. Если же в системе реализована модель лишь жесткого лимита, то возможны ситуации, когда пользователь получает отказ от системы, поскольку он «неумышленно» превзошел указанную квоту (например, из-за ошибки в программе был сформирован очень большой файл).
4.1.10 Надежность файловой системы
Понятие надежности файловой системы включает в себя множество требований, среди которых, в первую очередь, можно выделить то, что системные данные файловой системы должны обладать избыточной информацией, которая позволяла бы в случае аварийной ситуации минимизировать ущерб (т.е. минимизировать потерю информации) от этих сбоев.
Минимизация потери информации при аварийных ситуациях может достигаться за счет использования различных систем архивирования, или резервного копирования. Архивирование может происходить как автоматически по инициативе некоторого программного робота, так и по запросу пользователя. Но целиком каждый раз копировать всю файловую систему неэффективно и дорого. И тут перед нами встает одна из проблем резервного копирования — минимизировать объем копируемой информации без потери качества. Для решения поставленной задачи предлагается несколько подходов. Во-первых, это избирательное копирование, когда намеренно не копируются файлы, которые заведомо восстанавливаются. К таким файлам могут быть отнесены исполнительные файлы ОС, систем программирования, прикладных систем, поскольку считается, что в наличии есть дистрибутивные носители, с которых можно восстановить эти файлы (но файлы с данными копировать, конечно же, придется). Также можно не копировать исполняемые файлы, если для них имеется в наличии дистрибутив или исходных код, который можно откомпилировать и получить данный исполняемый файл. Также можно не копировать файлы определенных категорий пользователей (например, файлы студентов в машинном зале, которые имеют небольшие объемы, их можно достаточно легко восстановить, переписав заново, но количество этих файлов огромно, что повлечет огромные накладные расходы при архивировании).
Следующая модель заключается в т.н. инкрементном архивировании. Эта модель предполагает создание в первое архивирование полной копии всех файлов — это т.н. мастер-копия (master- copy). Каждая следующая копия будет включать в себя только те файлы, которые изменились или были созданы с момента предыдущего архивирования.
Также при архивировании могут использоваться дополнительные приемы, в частности, компрессия. Но тут встает дилемма: с одной стороны сжатие данных при архивировании дает выигрыш в объеме резервной копии, с другой стороны компрессия крайне чувствительна к потере информации. Потеря или приобретение лишнего бита в сжатом архиве может повлечь за собой порчу всего архива.
Еще одна проблема, которая может возникнуть при резервном копировании, — это копирование на ходу, когда во время резервного копирования какого-то файла пользователь начинает с ним работать (модифицировать, удалять и т.п.). Если для примера рассмотреть инкрементное архивирование, то мастер-копию стоит создать в полном отсутствии пользователей в системе (этот процесс зачастую занимает довольно продолжительное время). Но последующие копии вряд ли удастся создавать в отсутствии пользователей, поэтому необходимо грамотно выбирать моменты для архивирования: понятно, что если большая часть пользователей работает в дневное время суток, то подобные операции стоит проводить в ночные часы, когда в системе почти никто не работает.
Еще один полезный прием заключается в распределенном хранении резервных копий. Всегда желательно иметь две копии, причем храниться они должны в совершенно разных местах, чтобы не могла возникнуть ситуация, когда пожар в офисе уничтожает компьютеры и все резервные копии, хранящиеся в этом офисе, иначе польза от резервного копирования может оказываться нулевой.
Среди стратегий копирования можно выделить физическое и логическое копирование. Физическое копирование заключается в поблочном копировании данных с носителя («один в один»). Понятно, что такой способ копирования неэффективен, поскольку копируются и свободные блоки. Следующей модификацией этого способа стало интеллектуальное физическое копирования лишь занятых блоков. Так или иначе, но данный стратегия имеет проблему обработки дефектных блоков: сталкиваясь при копировании с физически дефектным блоком, невозможно связать данный блок с конкретным файлом. Альтернативой физическому копированию является логическая архивация. Эта стратегия подразумевает копирование не блоков, а файлов (например, файлов, модифицированных после заданной даты).
4.1.11 Проверка целостности файловой системы
Далее речь пойдет о моделях организации контроля и исправления ошибочных ситуаций, связанных с целостностью файловой системы. Обратим внимание, что будет рассматриваться целостность именно файловой системы, а не файлов. Если произошел сбой (например, сломался центральный процессор или оперативная память), то гарантированно потери будут, и эти потери будут двух типов. Во-первых, это потеря актуального содержимого одного или нескольких открытых файлов. Это проблема, но при соответствующей организации резервного копирования она разрешается. Вторая проблема связана с тем, что во время сбоя может нарушиться корректность системной информации. Вторая проблема более существенна и требует более тонких механизмов ее решения.
Для выявления непротиворечивости и исправления возможных ошибочных ситуаций файловая система использует избыточную информацию, т.е. данные тем или иным образом (явно или косвенно) дублируются. Далее рассмотрим организацию контроля целостности блоков файловой системы.
Рассмотрим модельный пример. В системе формируются две таблицы, каждая из которых имеет размеры, соответствующие реальному количеству блоков файловой системы. Одна из таблиц называется таблицей занятых блоков, вторая — таблицей свободных блоков. Изначально содержимое таблиц обнуляется.
На втором шаге система запускает процесс анализа блоков на предмет их незанятости. Для каждого свободного блока увеличивается на 1 соответствующая ему запись в таблице свободных блоков.
На следующем шаге запускается аналогичный процесс, но уже анализа индексных узлов. Для каждого блока, номер которого встретился в индексном дескрипторе, увеличивается на 1 соответствующая ему запись в таблице занятых блоков.
На последнем шаге запускается процесс анализа содержимого этих таблиц и коррекции ошибочных ситуаций.
Рассмотрим, какие ситуации могут возникнуть, и посмотрим, как файловая система поступает в том или ином случае. Допустим, что рассматриваемая файловая система состоит из шести блоков.
Если при анализе таблиц для каждого номера блока сумма содержимого ячеек с данным номером дает 1, то считается, что система не выявила противоречий (Рис. 104).

Рис. 104. Проверка целостности файловой системы. Непротиворечивость файловой системы соблюдена.
Если же находится блок, о котором нет информации ни в таблице свободных, ни в таблице занятых блоков (т.е. и в соответствующих ячейка стоят нули), то считается, что этот блок потерян из списка свободных блоков (Рис. 105). Данная ситуация не катастрофическая, соответственно, не требует оперативного разрешения (т.е. может быть отложенной): информацию о данном блоке система может внести в таблицу свободных блоков спустя некоторое время.

Рис. 105. Проверка целостности файловой системы. Зафиксирована пропажа блока.
Если в ходе анализа блок получается свободным, но индекс свободности его больше 1 (т.е. соответствующая ячейка таблицы свободных блоков хранит значение, большее 1), то считается, что нарушен список свободных блоков, и начинается процесс пересоздания таблицы свободных блоков (Рис. 106).

Рис. 106. Проверка целостности файловой системы. Зафиксировано дублирование свободного блока.
Если же возникает аналогичная ситуация, но уже для таблицы занятых блоков, то это означает, что данным файлом владеют несколько файлов, что является ошибкой (Рис. 107). Автоматически определить, какой из файлов ошибочно хранит ссылку на этот блок, не представляется возможным: необходимо анализировать содержимое этих файлов. Для разрешения данной проблемы файловая система может предпринять следующие действия. Пускай конфликтуют файлы с именами Name1 и Name2. Тогда файловая система сначала создает копии этих файлов (соответственно, с именами Name12 и Name22), затем удаляет файлы с исходными именами Name1 и Name2, запускает процесс переопределение списка свободных блоков и, наконец, обратно переименовывает эти копии с фиксацией факта их возможной некорректности.

Рис. 107. Проверка целостности файловой системы. Зафиксировано дублирование занятого блока.
И, наконец[R29] , для проверки корректности файловой системы может выполняться проверка соответствия числа реального количества жестких связей тому значению, которое хранится среди атрибутов файла (Рис. 108). Если эти значения совпадают, то считается, что данный файл находится в корректном состоянии, иначе происходит коррекция атрибута-счетчика жестких связей.

Рис. 108. Проверка целостности файловой системы. Контроль жестких связей.
4.2 Примеры реализаций файловых систем
В[R30] качестве примеров реализаций файловых систем рассмотрим файловые системы, реализованные в ОС Unix. Выбор наш объясняется тем, что создатели ОС Unix изначально выбрали удачную архитектуру файловой системы, причем эту файловую систему нельзя рассматривать в отрыве от самой ОС: ОС Unix строится на понятии файла как одном из фундаментальных понятий (напомним, что вторым важным понятием является понятие процесса). Необходимо заметить, что, как утверждают авторы системы, архитектура файловой системы была заимствована и развита из ОС Multix (файловую систему которой скорее можно назвать экспериментальной, и, как следствие, она не была массово распространена).
В качестве одного из главных достоинств ОС Unix является то, что именно эта система стала одной из первых систем, в которой была реализована иерархическая файловая система. Сама же операционная система строится на понятиях процесса и файла, т.е. все то, с чем мы работаем, является файлом, а это, в свою очередь, означает, что в системе реализованы унифицированные интерфейсы доступа и организации информации.
Еще одно важное достоинство, которое необходимо отметить у ОС Unix, — это то, что она стала одной из первых операционных систем, открытых для расширения набора команд системы. До ее создания практически все команды, которые были доступны пользователю, представлялись в виде набора жестких правил общения человека с системой (сравнимые с современными интерпретаторами команд), модифицировать который не представлялось возможным. Если же требовалось внести коррективы в существующие команды, то необходимо было обратиться к разработчику операционной системы, и тот, по сути, создавал новую систему. В ОС Unix все исполняемые команды принадлежат одной из двух групп: команды, встроенные в интерпретатор команд (например, pwd, cd и т.д.), и команды, реализация которых представляется в виде исполняемых файлов, расположенных в одном из каталогов файловой системы (это либо исполняемый бинарный файл, либо текстовый файл с командами для исполнения интерпретатором команд). Данный подход означает, что, варьируя правами доступа к файлам, уничтожая при необходимости или добавляя новые исполняемые файлы, пользователь способен самостоятельно выстраивать функциональное окружение, необходимое для решения его задач.
Еще одним достоинством этой операционной системы является элегантная организация идентификации доступа и прав доступа к файлам (об этом речь пойдет ниже). Так или иначе, но обозначенные фундаментальные концепции лежат в основе современных операционных систем семейства Unix до сих пор.
4.2.1 Организация файловой системы ОС Unix. Виды файлов. Права доступа
Файл ОС Unix — это специальным образом именованный набор данных, размещенных в файловой системе. Файлы ОС Unix могут быть разных типов:
- обычный файл (regular file) — это те файлы, с которыми регулярно имеет дело пользователь в своей повседневной работе (например, текстовый файл, исполняемый файл и т.п.);
- каталог (directory) — файл данного типа содержит имена и ссылки на атрибуты, которые содержатся в данном каталоге;
- специальный файл устройств (special device file) — как отмечалось выше, каждому устройству, с которым работает ОС Unix, должен быть поставлен в соответствие файл данного типа. Через имя файла устройства происходит обращение к устройству, а через содержимое данного файла (которое достаточно специфично) можно обратиться к конкретному драйверу этого устройства;
- именованный канал, или FIFO-файл (named pipe, FIFO file) — о файлах этого типа шла речь выше при обсуждении базовых средств организации взаимодействия процессов в ОС Unix (см. 3.1.3);
- файл-ссылка, или символическая связь (link) — файлы данного типа рассматривались выше при изучении вопросов соответствия имени файла и его содержимого (см. 4.1.7);
- сокет (socket) — файлы данного типа используются для реализации унифицированного интерфейса программирования распределенных систем (см. 3.3).
Так или иначе, но с файлом каждого из указанных типов возможно осуществлять работу (в той или иной степени) посредством стандартных интерфейсов работы с файлами. С каждым файлом также ассоциированы такие характеристики, как права доступа к файлу, которые регламентируют чтение содержимого файла, запись и исполнение файла. Подобная интерпретация прав доступа свойственна регулярным файлам, для других типов файлов интерпретация прав доступа отличается (например, для файлов-каталогов).
Права на доступ к файлу разделяются на три категории пользователей — это права пользователя-владельца файла, права группы, к которой принадлежит владелец файла, без этого владельца, и, наконец, права всех оставшихся пользователей системы (без указанной группы владельца). Соответственно, для каждой из категорий определяются вышеперечисленные права доступа.
4.2.2 Логическая структура каталогов
Одной[R31] из характеристик ОС Unix является характеристика, кажущаяся на первый взгляд достаточно странной: система рекомендует размещать системную и пользовательскую информацию по некоторым правилам. Вообще говоря, эти правила нежесткие, их можно нарушать, но обычно, следуя им, пользователь системы получает дополнительное удобство.
Прежде всего, необходимо отметить, что файловая система ОС Unix является иерархической древовидной файловой системой (Рис. 109), т.е. у нее есть корневой каталог /, из которого за счет каталогов разных уровней вложенности «вырастает» целое дерево имен файлов.
Рис. 109. Логическая структура каталогов.
Система предполагает, что в корневом каталоге всегда расположен некоторый файл, в котором размещается код ядра операционной системы. Сразу оговоримся, что мы рассматриваем некоторую модельную системы: в действительности файл с кодом ядра и упоминаемые в будущем каталоги могут иметь иное расположение в системе и другие имена. Вообще говоря, в корневом каталоге можно размещать любые файлы (с учетом прав доступа), но система предполагает наличие совокупности каталогов с предопределенными именами. Рассмотрим основные каталоги системы.
В каталоге / bin находятся команды общего пользования (точнее говоря исполняемые файлы, реализующие указанные команды).
Каталог / etc содержит системные таблицы и команды, обеспечивающие работу с этими таблицами. В частности, в этом каталоге хранится таблица (файл) passwd, содержащую информацию о зарегистрированных в системе пользователей.
Каталог / tmp является каталогом временных файлов, т.е. в этом каталоге система и пользователи могут размещать свои файлы на некоторый ограниченный промежуток времени, при этом при перезагрузке системы нет гарантии, что файлы не будут удалены из этого каталога.
Каталог / mnt традиционно используют для монтирования различных файловых систем к данной системе. Операция монтирования в общих чертах заключается в том, что корень монтируемой файловой системы ассоциируют с данным каталогом (или с одним из его подкаталогов), после чего доступ к файлам подмонтированной системы осуществляется уже через этот каталог (т.н. точку монтирования).
В каталоге / dev размещаются специальные файлы устройств, посредством которых осуществляется регистрация обслуживаемых в системе устройств и связь этих устройств с тем или иным драйвером. Соответственно, все устройства, с которыми работает операционная система, именуются посредством имен этих специальных файлов устройств.
Каталог / usr можно охарактеризовать, как каталог пользовательской информации. Предполагается, что это каталог имеет свою специфичную структуру подкаталогов. В частности, каталог / usr/ lib обычно содержит инструменты работы пользователей, не относящихся напрямую к взаимодействию с операционной системой (например, тут могут храниться системы программирования, C-компилятор, C-отладчик и т.п.). Еще один достаточно важным каталогом является каталог / usr/ include, который содержит файлы заголовков (или include-файлы) с расширением *.h, и именно в этом каталоге будет искать препроцессор C-компилятора соответствующие файлы заголовков, указанные в программе в угловых скобках. Каталог / usr/ bin — это каталог команд, которые введены на данной вычислительной установке (например, тут могут храниться команды, связанные с непосредственной деятельностью организации). И, наконец, в каталоге / usr/ user размещаются домашние каталоги зарегистрированных в системе пользователей.
Итак, мы рассмотрели основные аспекты логической структуры каталогов ОС Unix. Еще раз отметим, что, придерживаясь рекомендаций системы в плане размещения тех или иных файлов, легче и удобнее поддерживать систему «в порядке».
4.2.3 Внутренняя организация файловой системы: модель версии System V
Рассмотрение внутренней организации файловой системы мы начнем с модели файловой системы, реализованной в ОС Unix версии System V. Данная файловая система была реализована одной из первых в ОС Unix и имеет название s5fs.
Рис. 110. Структура файловой системы версии System V.
Данная файловая система имеет следующую структуру (Рис. 110). Файловая система занимает часть того раздела, в котором она находится (назовем его системным разделом, чтобы отличать его от разделов с другими файловыми системами, имеющими схожую организацию, и которые можно примонтировать к данной системе), начиная с нулевого блока и заканчивая некоторым фиксированным блоком. Эта часть состоит из трех подпространств: суперблока, области индексных дескрипторов и блоков файлов.
Итак, первое подпространство — это суперблок. Он содержит данные, определяющие статические параметры и характеристики данной файловой системы (например, информация о размере блока файла, информация о размере всей файловой системы в блоках или байтах или же информация о количестве индексный дескрипторов в системе). Также суперблок хранит информацию об оперативном состоянии файловой системы. Суперблок является частью файловой системы, которая резидентно находится в оперативной памяти. Среди прочего суперблок хранит информацию о наличии свободных ресурсов файловой системы — наличие свободных блоков в рабочем пространстве файловой системы и наличие свободных индексных дескрипторов. Забегая вперед, отметим, что для этих целей используются соответственно массив номеров свободных блоков и массив индексных дескрипторов.
Следующее подпространство — это область индексных дескрипторов. Индексные дескрипторы были описаны нами выше, мы их рассматривали как некоторые системные структуры данных фиксированного размера, содержащих комплексную информацию о размещении, актуальном состоянии и содержимом конкретного файла.
Последнее подпространство — это блоки файлов (если быть более точным, то данное пространство корректнее было бы назвать рабочим пространством файловой системы). Здесь размещаются блоки файлов (с содержимым этих файлов), а также системная информация, которая не поместилась в суперблоке и области индексных дескрипторов.
4.2.3.1 Работа с массивами номеров свободных блоков
Изначально номера всех свободных блоков файловой системы выстраиваются в единый связный список (Рис. 111), который размещается в нескольких блоках. Первый блок располагается в суперблоке (а значит, в оперативной памяти). Каждый блок хранит номера свободных блоков, а также номер следующего блока данного массива.
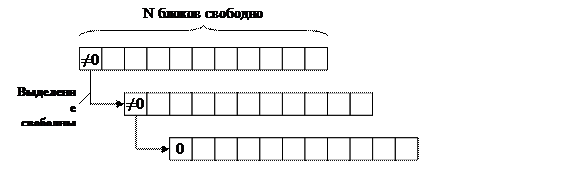
Рис. 111. Работа с массивами номеров свободных блоков.
Работа с массивом номеров свободных блоков достаточно проста. При запросе на получение свободного блока происходит поиск в первом блоке массива ячейки с содержательной (ненулевой) информацией, обнуление найденной ячейки, а блок с найденным номером выдается в ответ на запрос. Если же происходит обнуление последней ячейки блока, ссылающейся на следующий блок массива, то предварительно содержимое этого блока загружается в суперблок и используется уже как первый блок этого массива. Если же какой-то блок освобождается, то выполняются противоположные действия в обратном порядке.
На первый взгляд может показаться, что хранение в блоках массива свободных блоков уменьшают рабочее пространство файловой системы (т.е. пользователь не сможет воспользоваться блоками, хранящими массив), но это не так: если представить граничную ситуацию, когда нет свободных блоков, тогда нет и номеров свободных блоков, а значит, нет и блоков, хранящих эти номера, т.е. файловая система занята на 100%.
4.2.3.2 Работа с массивом свободных индексных дескрипторов
Массив номеров свободных индексных дескрипторов — это массив фиксированного количества элементов. Изначально данный массив заполнен номерами свободных индексных дескрипторов.
Если происходит освобождение индексного дескриптора (т.е. происходит удаление файла), то происходит обращение к данному массиву. Если в массиве есть свободные места, то происходит запись номера освободившегося индексного дескриптора в первое встретившееся свободное место массива, иначе номер дескриптора «забывается».
При создании файла происходят обратные действия. Идет обращение к массиву, если он не пуст, то из него изымается первый содержательный элемент, который представляет собой номер свободного индексного дескриптора. Если же при обращении к массиву оказалось, что он пуст, а в суперблоке присутствует информация о наличии свободных индексных дескрипторах, то система запускает процесс обновления рассматриваемого массива. Этот процесс обращается к области индексных дескрипторов, последовательно перебирает их и в зависимости от их содержимого делает однозначный вывод о занятости или свободности дескриптора. Номера свободных индексных дескрипторов процесс помещает в массив.
Рассмотренные массивы свободных блоков и свободных индексных дескрипторов исполняют роль специализированных КЭШей: происходит буферизация обращений к системе за свободным ресурсом.
4.2.3.3 Индексные дескрипторы. Адресация блоков файла
Выше уже отмечалось, что индексный дескриптор (Рис. 112) является системной структурой данных, содержащей атрибуты файла, а также всю оперативную информацию об организации и размещении данных. Система устроена таким образом, что между содержимым файла и его индексным дескриптором существует взаимнооднозначное соответствие. Заметим, что содержимое файла не обязательно размещается в рабочем пространстве файловой системы: существуют некоторые типы файлов, для которых содержимое хранится в самом индексном дескрипторе. Примером тут может послужить тип специального файла устройств.

Рис. 112. Индексные дескрипторы.
Для каждого индексного дескриптора существует, по меньшей мере, одно имя, зарегистрированное в каталогах файловой системы. И еще раз повторимся, сказав, что, говоря о древовидности файловой системы, то понимают древовидности не с точки зрения размещения файла, а с точки зрения размещения имен файлов.
Индексный дескриптор хранит информацию о типе файла, правах доступа, информацию о владельце файла, размере файла в байтах, количестве имен, зарегистрированных в каталогах файловой системы и ссылающихся на данный индексный дескриптор. В частности, признаком свободного индексного дескриптора является нулевое значение последнего из указанных атрибутов.
В индексном дескрипторе также собирается различная статистическая информация о времени создания, времени последней модификации, времени последнего доступа. И, наконец, в индексном дескрипторе находится массив блоков файла.
Организация блоков файла — еще одна удачная особенность файловой системы ОС Unix. Структура организации блоков файла выглядит следующим образом. Массив блоков файла состоит из 13 элементов. Первые 10 элементов используются для указания номеров первых десяти блоков файла, оставшиеся три элемента используются для организации косвенной адресации блоков. Так, одиннадцатый элемент ссылается на массив из N номеров блоков файла, двенадцатый — на массив из N ссылок, каждая из которых ссылается на массив из N блоков файла, тринадцатый элемент используется уже для трехуровневой косвенной адресации блоков.
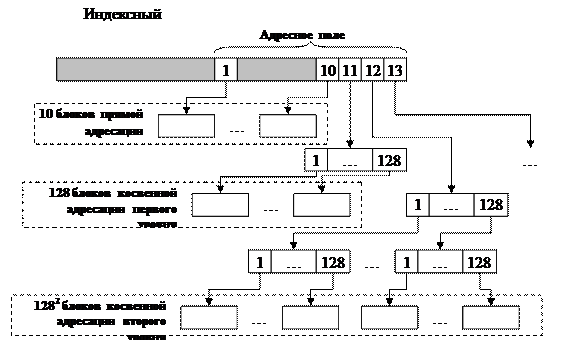
Рис. 113. Адресация блоков файла.
Рассмотрим пример системы (Рис. 113), в которой размер блока равен 512 байтам (т.е. 128 четырехбайтовых чисел). Если количество блоков файла больше 10, то сначала используется косвенная адресация первого уровня. Суть ее заключается в том, что в одиннадцатом элементе хранится номер блока, состоящем в нашем случае из 128 номеров блоков файла, которые следуют за первыми десятью блоками. Иным словами, посредством одиннадцатого элемента массива адресуются 11-ый – 138-ой блоки файла. Если же блоков оказывается больше, чем 138, то начинает использоваться косвенность второго уровня, и для этих целей задействуют двенадцатый элемент массива. Этот элемент массива содержит номер блока, в котором (опять-таки для нашего примера) могут находиться до 128 номеров блоков, в каждом из которых может находиться до 128 номеров блоков файла. Когда размеры файла оказываются настолько большими, что для хранения номеров его блоков не хватает двойной косвенной адресации, используется тринадцатый элемент массива и косвенная адресация третьего уровня. Итак, в рассмотренной модели (размер блока равен 512 байтам) максимальный размер файла может достигать (10+128+1282+1283)*512 байт. На сегодняшний день файловые системы с таким размером блока не используются, наиболее типичны размеры блока 4, 8, вплоть до 64 кбайт.
Обратим внимание, что рассмотренная модель адресации блоков файла является достаточно компактной и эффективной, поскольку для обращения к блоку файла с использованием тройной косвенности потребуется всего три обмена, а если учесть, что в системе реализована буферизация блочных обменов, то накладные расходы становятся еще меньше.
4.2.3.4 Файл-каталог
Каталог файловой системы версии System V — это файл специального типа, его содержимое так же, как и у регулярных файлов, находится в рабочем пространстве файловой системы и по организации данных ничем не отличается от организации данных регулярных файлов.
Файлы-каталоги (Рис. 114) имеют следующую структурную организацию. Каждая запись в ней нем имеет фиксированный размер: длина записи довольно сильно варьировалась, мы будем считать, что длина записи 16 байт. Первые два байта хранят номер индексного дескриптора файла, а оставшиеся 14 байтов — это имя файла (т.е. в нашей модели имя файла в системе ограничено 14 символами). При создании каталога он получает две предопределенные записи, которые невозможно модифицировать и удалять. Первая запись — это запись, для которой используется унифицированное имя “.”, интерпретируемая как ссылка на сам этот каталог. Соответственно, в этой записи указывается номер индексного дескриптора данного файла-каталога. Второй записью, для которой используется унифицированное имя “..”, является ссылка на родительский для данного файла каталог, и соответственно, в этой записи хранится номер индексного дескриптора родительского каталога.
Рис. 114. Файл-каталог.
Отвлекаясь от файловой системы версии System V, отметим, что многие более развитые файловые системы ОС Unix поддерживают средства установления связей (Рис. 115) между индексным дескриптором и именами файла. Можно устанавливать как жесткие связи, так и символические связи. Жесткая связь позволяет с одним индексным дескриптором связать два и более равноправных имени. Соответственно, при удалении имени, участвующего в жесткой связи, то первым делом удаляется имя из каталога, затем уменьшается счетчик жестких связей в индексном дескрипторе. В случае обнуления этого счетчика происходит удаление содержимого файла и освобождение данного индексного дескриптора.
Для организации символической связи создается файла специального типа — типа ссылки. Файл данного типа содержит полный путь к тому файлу, на который ссылается данный файл-ссылка. Используя такую косвенную адресацию, можно добраться до целевого файла. Такой подход иллюстрирует ассиметричное именование (права файла ссылки будут отличаться от прав файла, на который он ссылается).

Рис. 115. Установление связей.
4.2.3.5 Достоинства и недостатки файловой системы модели System V
Среди достоинств рассматриваемой файловой системы стоит отметить, что данная система является иерархичной. Также надо отметить, что за счет использования системного кэширования оптимизирована работа с массивом свободных блоков и свободных индексных дескрипторов. И, наконец, в данной файловой системе найдено удачное решение организации блоков файлов за счет использования «нарастающей» косвенности адресации.
С другой стороны, данная система не лишена недостатков, большая часть которых следует из ее достоинств. Первым недостатком является тот факт, что в суперблоке концентрируется ключевая информация файловой системы. Соответственно, потеря суперблока приводит к достаточно серьезным проблемам.
Следующая проблема опять-таки связана с концентрацией информации в суперблоке. Несмотря на то, что суперблок резидентно размещается в ОП, система периодически «сбрасывает» его копию на диск — это делается для того, чтобы при сбое минимизировать потери актуальной информации из суперблока. Это, в свою очередь, означает, что система регулярно обращается к одной и той же точке дискового пространства, и, соответственно, вероятность выхода из строя именно данной области диска со временем сильно увеличивается.
Следующий недостаток связан с фрагментацией блоков файла по диску. Здесь имеется в виду, что при интенсивной работе файловой системы (когда в ней со временем создается, модифицируется и уничтожается достаточно большое число файлов) складывается ситуация, когда блоки одного файла оказываются разбросанными по всему доступному дисковому пространству. В этом случае, если потребуется прочитать последовательные блоки файла (что бывает достаточно часто), то головка жесткого диска начинает совершать довольно много механических передвижений, что отрицательно сказывается на эффективности работы файловой системы.
И в заключение отметим такой недостаток, как ограничение, накладываемое на длину имени файла (6, 8, 14 байт для представления имени — величины достаточно небольшие на сегодняшний день: возникают ситуации, когда необходимо создать имена с относительно длинными именами).
4.2.4 Внутренняя организация файловой системы: модель версии Fast File System (FFS) BSD
Разработчики[R32] файловой системы Fast File System (FFS), оставив основные положительные характеристики предыдущих файловых систем (в т.ч. и файловой системы версии System V), пошли по следующему пути (Рис. 116). Они представили раздел как последовательность дисковых цилиндров, которую разбили на порции фиксированного размера. В каждом из образовавшихся кластеров размещается копия суперблока, блоки файлов, которые мы назвали рабочим пространством файловой системы, информация об индексных дескрипторах, ассоциированных с данным кластером, а также информация о свободных ресурсах этого кластера. При этом разбиение устройства на кластеры происходит аппаратно-зависимо таким образом, чтобы суперблоки не оказывались на «опасно близком» расстоянии (например, на одной поверхности). Такой подход обеспечивает большую надежность файловой системы.
Рис. 116. Структура файловой системы версии FFS BSD.
4.2.4.1 Стратегии размещения
Работа системы основывается на трех концепциях. Первой концепцией является оптимизация размещения каталога. При создании каталога система осуществляет поиск кластера, наиболее свободного в данный момент с точки зрения использования индексных дескрипторов, т.е. ищутся кластеры, количество свободных индексных дескрипторов в которых превосходит некоторую среднюю величину, и среди найденных кластеров выбирается кластер с наименьшим количеством каталогов.
Следующей стратегией является равномерность использования блоков данных. Во время создания файла он делится на несколько частей. Часть файла, которая имела непосредственную адресацию из индексного дескриптора, по возможности размещается в том же кластере, что и индексный дескриптор. Оставшиеся части файла делятся на равные порции, которые файловая система размещает в отдельных кластерах. Перечисленные стратегии призваны для борьбы фрагментации файла по разделу: файл либо целиком размещается в одном кластере, либо он размещается в нескольких кластерах, но тогда в них размещаются достаточно большие фрагменты подряд идущих блоков.
И, наконец, третья стратегия размещения — технологическое размещение последовательных блоков файлов (Рис. 117). Представим следующую ситуацию: пускай необходимо прочитать два последовательных блока с магнитного диска (будем считать, что эти блоки находятся на одной дорожке магнитного диска). Это означает, что данная задача требует двух последовательных обращений к системным вызовам. Соответственно, между окончанием физического считывания первого блока и началом физического считывания второго блока потратится некоторое время Δt на накладные расходы (в частности, вход и выход из системного вызова). Это время хоть и мало, но за данный промежуток диск успеет повернуться на угол ω*Δt (где ω — скорость вращения диска). Если следующий второй блок расположен на диске непосредственно за первым, то за время Δt головка пропустит начало второго блока, и когда будет предпринята попытка физически прочесть второй блок, то придется ожидать полного оборота диска, что является относительно протяженным промежутком времени. Чтобы избежать подобных накладных расходов, связанных с необходимостью ожидать полного оборота диска, необходимо расположить второй блок с некоторым отступом от первого. В этом и заключается технологическое размещение блоков на диске.

Рис. 117. Стратегия размещения последовательных блоков файлов.
4.2.4.2 Внутренняя организация блоков
Размер блока в файловой системе FFS может варьироваться в достаточно широком диапазоне: предельный размер блока — 64 Кбайт. Как отмечалось выше, проблема выбора оптимального размера блока достаточно сложна: и крупные блоки, и малоразмерные имеют свои плюсы и минусы, и от администратора системы требуются хорошие навыки, чтобы подобрать оптимальные для данной системы, решающей задачи конкретного типа, размеры блоков файловой системы.
Создатели рассматриваемой файловой системы пошли по пути увеличения размера блока. За счет этого 1) уменьшается фрагментация файла по диску и 2) уменьшаются накладные расходы при чтении подряд идущих данных файла (эффективнее считать за 1 раз большую порцию информации, чем два раза считать по «половинке»). Но главным недостатком крупных блоков — большая степень внутренней фрагментации. Для борьбы с внутренней фрагментацией в системе реализован еще один уровень структурной организации: каждый блок файловой системы поделен на фиксированное количество т.н. фрагментов (обычно число фрагментов в блоке кратно степени 2 — 2, 4, 8 и т.д.).
Размещение файла по блокам файловой системы строится на основе следующей концепции (Рис. 118). Начиная с первого и заканчивая предпоследним, эти блоки целиком заполнены содержимым данного файла. Соответственно, номера этих блоков хранятся среди атрибутов файла. Последний блок выделен отдельно: помимо его номера в атрибутах файла хранятся и номера занятых в нем фрагментов, принадлежащих данному файлу. Информация о блоках и фрагментах могла быть представлена разными способами: например, двоичная маска, или же номер первого фрагмента в этом блоке, занятым данным файлом (количество фрагментов тогда можно вычислить на основании длины файла в байтах), и т.д.
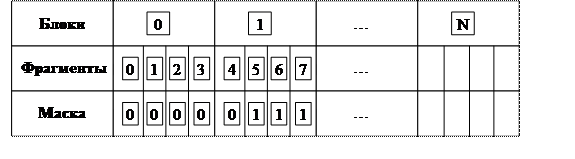
Рис. 118. Внутренняя организация блоков (блоки выровнены по кратности).
4.2.4.3 Выделение пространства для файла
Рассмотрим алгоритм выделения пространства для файлов на следующем примере. Будем считать, что блок файловой системы поделен на 4 фрагмента. Пускай в системе хранятся файлы petya.txt и vasya.txt (Рис. 119), для которых в соответствующих индексных дескрипторах хранится информация об их размерах и номеров блоков, принадлежащих файлам, в виде стартовых фрагментов. Соответственно, файл petya.txt расположен в нулевом блоке (стартовый фрагмент № 00), первом (стартовый фрагмент № 04) и второго блока (начинающегося с 08 фрагмента). Если учесть длину файла (5120 байт), то получается, что во втором блоке этот файл занимает 08 и 09 фрагменты. Файл vasya.txt расположен в третьем блоке (стартовый фрагмент № 12), четвертом (стартовый фрагмент № 16) и втором (стартовый фрагмент № 10), при этом во втором блоке файлу принадлежит только 10 фрагмент (т.к. размер файла 4608 байт). Итак, очевидно, что данная система нарушает концепцию файловой системы ветви System V, в которой каждый блок мог принадлежать только одному файлу; в FFS последний блок можно разделять между различными файлами.

Рис. 119. Выделение пространства для файла.
Если, например, размер файла petya.txt увеличивается на столько, что конец файла не помещается в 08 и 09 фрагментах, то система начинает поиск блока с тремя подряд идущими свободными фрагментами. (Соответственно, если размер файл увеличивается на большую величину, то сначала для него отводятся полностью свободные блоки, в которых файл занимает все фрагменты, а для размещения последних фрагментов ищется блок с соответствующим числом подряд идущих свободных фрагментов.) Когда система находит такой блок, то происходит перемещение последних фрагментов файла petya.txt в этот блок.
4.2.4.4 Структура каталога FFS
Каталог файловой системы FFS позволяет использовать имена файлов, длиной до 255 символов (Рис. 120). Каталог состоит из записей переменной длины, состоящих из блоков, размером в 4[R33] байта. Начальная запись содержит номер индексного дескриптора, размер записи (т.е. ссылка на последний элемент записи) и длина имени файла, после этого следует дополненное до кратности в 4 байта имя файла (максимальная длина имени файла — 255 символов). Работа системы организована следующим образом: если происходит удаление файла из каталога, то освобождающееся пространство, занимаемое раньше записью данного файла, присоединяется к предыдущей записи. Это означает, что размер предыдущей записи увеличивается, но длина хранимого в ней имени не меняется (т.е. остается реальной). Удаление первой записи выражается в обнулении номера индексного дескриптора в этой записи. Такая модель позволяет при удалении файла практически не заботиться о высвобождаемом пространстве внутри файла-каталога: получаемые при удалении «дыры» ликвидируются не счет той же компрессии, а за счет тривиального «склеивания» с предыдущей записью.
Рис. 120. Структура каталога FFS BSD.
Таким образом, система позволяет использовать имена файлов произвольной длины вплоть до 255 символов, что достаточно удобно для пользователя. Но такое преимущество оборачивается тем, что система несет накладные расходы как по использованию дискового пространства (в каталогах присутствует внутренняя фрагментация), так и по времени (осуществление поиска в системах с фиксированными размерами записей в большинстве случаев эффективнее, чем в системах с переменными размерами записей).
4.2.4.5 Блокировка доступа к содержимому файла
Организация файловой системы ОС Unix позволяет открывать и работать с одним и тем же файлом произвольному числу процессов. Более того, один и тот же файл может быть многократно открыт в рамках одного процесса. При этом система поддерживает модель синхронизации работы с файлами. Для этого используется системный вызов fcntl() (данный системный вызов предназначен вообще для организации управления работы с файлом), который может обеспечивать блокировку как файла в целом, так и отдельных областей внутри файла (т.е. сделать какую-то область файла недоступной для других процессов). Различают два типа блокировок: исключающие и распределенные.
Исключающая блокировка (exclusive lock) — это «жесткая» блокировка: если произошла такая блокировка области, то любой другой процесс не сможет осуществить операции обмена с данной областью (в этом случае процесс будет либо приостановлен в ожидании разблокирования области, либо получит отказ в зависимости от установленного режима работы). Данный вид блокировок является блокировкой с монополизацией, области с исключающими блокировками пересекаться не могут.
Альтернативой исключающей блокировке является распределенная блокировка (shared lock), или «мягкая», рекомендательная блокировка. Процесс может установить для области блокировку этого типа, а другие процессы при работе могут на нее не обращать внимания, т.е. при установленной блокировке все равно разрешены чтение и запись информации из блокированной области. Для обеспечения корректной работы с файлом необходимо средство определения установки блокировки на той или иной области, для этого опять-таки используется системный вызов fcntl(). Области с рекомендательными блокировками могут пересекаться[R34] .