
Система программирования — комплекс программ, обеспечивающий поддержание этапов жизненного цикла программы в вычислительной системе.








Прикладная система — программная система, ориентированная на решение или автоматизацию решения задач из конкретной предметной области.
1.2 Основы компьютерной архитектуры
Изучение принципов структурной организации и функционирования основных компонентов операционной системы невозможно без рассмотрения основ архитектуры компьютера. Настоящая глава посвящена рассмотрению концепций организации компьютера в контексте его функционирования в составе вычислительной системы. Многие функциональные возможности операционных систем, такие как организация асинхронной работы с внешними устройствами, защита памяти от несанкционированного доступа, организация виртуальной оперативной памяти, невозможно рассматривать вне поддержки этих функций в аппаратуре компьютера. На самом деле верно и обратное: многие возможности аппаратуры компьютера сложно представить вне их использования в рамках операционной системы. В процессе рассмотрения основ архитектуры мы будем использовать обобщенную модель организации и свойств основных компонентов, составляющих компьютер, достаточную для построения представления о существующих взаимосвязях аппаратных и программных компонентов вычислительной системы, а также для понимания принципов построения операционных систем.
1.2.1 Структура, основные компоненты
Середина 40-х годов прошлого века может вправе считаться сроком зарождения современной вычислительной техники. С этой датой связана публикация американского математика венгерского происхождения Джона фон Неймана (John Von Neumann) отчета по результатам проектирования компьютера EDVAC (Electronic Discrete Variable Computer — Электронный Компьютер Дискретных Переменных) под названием «Предварительный доклад о компьютере EDVAC» (A First Draft Report on the EDVAC). В данном отчете декларировались основные концепции организации компьютеров, которые должны были быть реализованы в EDVAC. Основными разработчиками этого компьютера были Джон Мочли (John Mauchly) и Джон Преспер Эккерт (John Presper Eckert). Следует отметить, что к тому времени Мочли и Эккерт имели успешный опыт разработки компьютера ENIAC (Electronic Numerical Integrator And Computer). Скандальность данной ситуации состояла в том, что внутрикорпоративный отчет, основанный на предложениях Моучли и Эккерта или предложениях, полученных совместно Моучли, Эккертом и фон Нейманом, был подготовлен и опубликован за авторством только Джона фон Неймана. Распространение данного отчета в научной среде породило появление "принципов фон Неймана", которые как минимум должны были именоваться принципами Мочли, Эккерта, фон Неймана. Мы не вправе и не в силах изменить ход истории и сложившуюся терминологию, поэтому в дальнейшем также будем использовать термин "принципы построения компьютера фон Неймана". Итак, в чем же состояли принципы организации машины фон Неймана?
1. Принцип двоичного кодирования информации: все поступающие и обрабатываемые компьютером данные кодируются при помощи двоичных сигналов.
2. Принцип программного управления. Программа состоит из команд, в которых закодированы операция и операнды, над которыми должна выполниться данная операция. Выполнение компьютером программы — это автоматическое выполнение определенной последовательности команд, составляющих программу. В компьютере имеется устройство, обеспечивающее выполнение команд, — процессор. Последовательность выполняемых процессором команд определяется последовательностью команд и данных, составляющих программу.
3. Принцип хранимой программы. Для хранения команд и данных программы используется единое устройство памяти, которое представляется в виде вектора слов. Все слова имеют последовательную адресацию. Команды и данные представляются единым образом. Интерпретация информации памяти и, соответственно, ее идентификация как команды или как данных происходит неявно при выполнении очередной команды. К примеру, содержимое слова, адрес которого используется в команде перехода в качестве операнда, интерпретируется как команда. Если то же слово используется в качестве операнда команды сложения, то его содержимое интерпретируется как данные. Это свойство определяет возможность программной генерации команд с последующим их выполнением.

Рис. 20. Структура компьютера фон Неймана.
Рассмотрим упрощенную структуру компьютера фон Неймана (Рис. 20):
- Оперативное запоминающее устройство (ОЗУ), или основная память, — устройство хранения данных, в котором находится исполняемая в настоящее время программа.
- Внешние устройства — программно управляемые устройства, входящие в состав компьютера, т.е. устройства, с которыми выполняемая программа может обмениваться данными.
- Процессор, или центральный процессор (ЦП), — основной компонент компьютера, обеспечивающий выполнение программ, процессор координирует работу внешних устройств и оперативной памяти. Процессор состоит из арифметико-логического устройства (АЛУ) и устройства управления (УУ). Устройство управления обеспечивает последовательную выборку команд, составляющих программу, из памяти, выделение и анализ кода операции, получение значений операндов. В зависимости от кода операции команда выполняется либо в устройстве управления (обычно это могут быть команды передачи управления), либо код операции и операнды передаются для выполнения в АЛУ. После чего выбирается из памяти следующая команда программы, и т.д. В системе команд компьютера предусмотрены команды обмена с внешними устройствами.
Современные компьютеры по многим показателям не соответствуют модели фон Неймана. Ниже мы рассмотрим базовые структурные и функциональные особенности современных компьютеров (Рис. 21), уделив особое внимание организации компьютера, как системы, объединяющей разнородные по назначению и производительности аппаратные компоненты, работающей под управлением операционной системы. Скорости обработки информации в процессоре, доступа к данным, размещенным в оперативной памяти, обмена данными с внешними устройствами могут отличаться друг от друга на порядки. И если в системе не будут предусмотрены средства, компенсирующие этот дисбаланс, то итоговая производительность будет определяться наименее производительным элементом, активно используемым в работе системы.
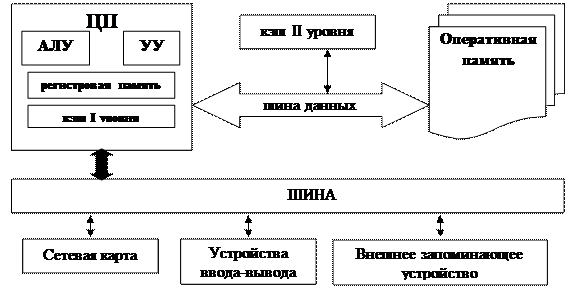
Рис. 21. Базовая архитектура [R5] современных компьютеров.
Итоговая производительность вычислительной системы во многом определяется решениями на уровнях аппаратуры и операционной системы, которые позволяют минимизировать последствия дисбаланса в производительности как аппаратных, так и программных компонентов.
1.2.2 Оперативное запоминающее устройство
Оперативное запоминающее устройство (RAM — Random-Access Memory) — это устройство хранения данных компьютера, в котором находится исполняемая в данный момент программа. ОЗУ еще называют основной памятью, или оперативной памятью. Команды программы, исполняемые компьютером, поступают в процессор исключительно из ОЗУ. Хранение программы, которая выполняется в настоящее время компьютером, является основным назначением оперативной памяти. Оперативная память состоит из ячеек памяти. Ячейка памяти — это устройство, в котором возможно хранение информации. Ячейка памяти может состоять из двух полей (Рис. 22). Первое поле — поле машинного слова, второе — поле служебной информации (или ТЕГ). Рассмотрим назначение каждого из них.

Рис. 22. Ячейка памяти.
Машинное слово — поле программно изменяемой информации. В машинном слове могут располагаться машинные команды (или части машинных команд) или данные, с которыми может оперировать программа. Машинное слово имеет фиксированный для данной ЭВМ размер. Обычно под размером машинного слова понимается количество двоичных разрядов, размещаемых в машинном слове. Когда используется термины «16-тиразрядный компьютер», или «32-хразрядный компьютер», или «64-хразрядный компьютер», это означает, что речь идет о компьютерах, оперативная память которых имеет машинные слова размером 16, 32 или 64 разряда соответственно.
Служебная информация — ТЕГ (tag — ярлык, бирка) — поле ячейки памяти, в котором схемами контроля процессора и ОЗУ автоматически размещается информация, необходимая для осуществления контроля за целостностью и корректностью использования данных, размещаемых в машинном слове.
Использование в компьютере содержимого поля служебной информации может осуществляться в следующих целях.
- Контроль целостности данных. Содержимое поля используется для контрольного суммирования кода, размещенного в машинном слове. При каждой записи информации в машинное слово автоматически происходит контрольное суммирование и формирование содержимого поля служебной информации. При чтении данных из машинного слова также автоматически происходит контрольное суммирование кода, находящегося в машинном слове, а затем полученный код контрольной суммы сравнивается с кодом, размещенным в поле служебной информации. Совпадение кодов говорит о том, что данные, записанные в машинном слове, не потеряны. Несовпадение говорит о том, что произошел сбой в ОЗУ, и информация, находящаяся в машинном слове, потеряна, в этом случае в процессоре происходит прерывание (прерывания будут рассматриваться несколько позднее). На Рис. 23 изображена ячейка памяти с 16-тиразрядным машинным словом и одноразрядным полем ТЕГа. Контрольный разряд дополняет код машинного слова до четности. Вариант А: содержимое машинного слова корректное (здесь следует отметить, что одноразрядное контрольное суммирование может "пропускать" потери пар единиц в коде машинного слова — вариант В), вариант Б — ошибка.
- Контроль доступа к командам/данным. Рассмотрим проблемы, возникающие в машинах фон Неймана. Первая — ситуация "потери" управления в программе, т.е. ситуация, при которой из-за ошибок в программе в качестве исполняемых команд начинают выбираться процессором и исполняться данные. Вторая проявляется тогда, когда программа из-за ошибки сама затирает свою кодовую часть: на место команд записываются данные. Отладка подобных ошибок достаточно трудоемка, т.к. возникновение ошибки в программе и ее проявление могут быть существенно разнесены по коду программы и по времени проявления. Контроль доступа к командам/данным обеспечивает защиту от возникновения подобных проблем. Суть этого решения заключается в следующем. При включении специального режима работы процессора запись машинных команд в оперативную память сопровождается установкой в ТЕГе специального кода, указывающего, что в данном машинном слове размешена команда. Также соответствующий признак устанавливается при записи данных. При выборке очередной команды из памяти автоматически проверяется содержимое соответствующих разрядов ТЕГа: если в машинном слове размещена команда, то будет продолжена ее обработка и выполнение. Если возникает попытка выполнения в качестве команды кода, записанного как данные, то происходит прерывание. Т.е. фиксируется возникновение ошибки. Здесь мы видим первый случай отхода от одного из принципов организации компьютеров фон Неймана — введение контроля за семантикой размещенной в машинном слове информации.

Рис. 23. Контроль четности.
- Контроль доступа к машинным типам данных. Развитием контроля за семантикой информации, размещенной в оперативной памяти, является появление средств контроля за использованием компьютерных типов данных. Как известно, каждый компьютер имеет так называемые машинные типы данных. Это означает, что существуют группы машинных команд, которые оперируют с данными одного типа (целые, вещественные с фиксированной точкой, вещественные с плавающей точкой, символьные, логические). Т.е. при выполнении команды используемые операнды интерпретируются согласно машинному типу данных в соответствии с типом команды. Согласно одному из принципов фон Неймана способ интерпретации информации в оперативной памяти зависит исключительно от характера использования этой информации. Т.е. любой код, записанный в машинное слово, может быть использован в качестве кода машинной команды, если устройство управления обратилось за очередной командой к этому машинному слову, и этот же код может быть проинтерпретирован как код любого машинного типа данных, если он используется в качестве операнда команды соответствующего типа. Контроль доступа к машинным типам данных осуществляется за счет фиксации в поле ТЕГа кода типа данных при их записи в машинное слово, а при использовании этих данных в качеств операндов команд осуществляется автоматическая проверка совпадения типа операнда и типа команды. Если они совпадают, то команда продолжает свое выполнение, если нет, то происходит прерывание. Как видим, контроль за использованием машинных типов данных является еще одним проявлением отхода архитектуры компьютеров от принципов фон Неймана.
Наличие или отсутствие поля служебной информации в ячейке памяти, характер его использования зависят от конкретного типа компьютеров. В каких-то компьютерах это поле ячейки памяти может отсутствовать, и в этом случае размер ячейки памяти совпадает с машинным словом. В каких-то — поле со служебной информацией ячейки памяти есть и используется для организации контроля за целостностью данных и корректностью их использования.
В ОЗУ все ячейки памяти имеют уникальные имена, имя — адрес ячейки памяти. Обычно адрес — это порядковый номер ячейки памяти (нумерация ячеек памяти возможна как подряд идущими номерами, так и номерами, кратными некоторому значению). Доступ к содержимому машинного слова осуществляется при непосредственном (например, считать содержимое слова с адресом А) или косвенном использовании адреса (например, считать значение слова, адрес которого находится в машинном слове с адресом В). Одной из характеристик оперативной памяти является ее производительность, которая определяет скорость доступа процессора к данным, размещенным в ОЗУ. Обычно производительность ОЗУ определяется по значениям двух параметров. Первый — время доступа (access time — taccess) — это время между запросом на чтение слова из оперативной памяти и получением содержимого этого слова. Второй параметр — длительность цикла памяти (cycle time — tcycle) — это минимальное время между началом текущего и последующего обращения к памяти. Обычно, длительность цикла превосходит время доступа (tcycle>taccess). Реальные соотношения между длительностью цикла и временем доступа зависят от конкретных технологий, применяемых для организации ОЗУ (в некоторых ОЗУ tcycle/taccess>2). Последнее утверждение говорит о том, что возможна ситуация, при которой для чтения N слов из памяти потребуется времени больше, чем N×taccess.
Вернемся к обозначенной в конце предыдущего пункта проблеме дисбаланса производительности аппаратных компонентов компьютера. Скорость обработки данных в процессоре в несколько раз превышает скорость доступа к информации, размещенной в оперативной памяти. Необходимо, чтобы итоговая скорость выполнения команды процессором как можно меньше зависела от скорости доступа к коду команды и к используемым в ней операндам из памяти. Это составляет проблему, которая системным образом решается на уровне архитектуры ЭВМ. В аппаратуре компьютера применяется целый ряд решений, призванных сгладить эту разницу. Одно из таких решений — расслоение памяти.
Расслоение ОЗУ — один из аппаратных путей решения проблемы дисбаланса в скорости доступа к данным, размещенным в оперативной памяти, и производительностью процессора. Суть расслоения состоит в следующем (Рис. 24, Рис. 25).
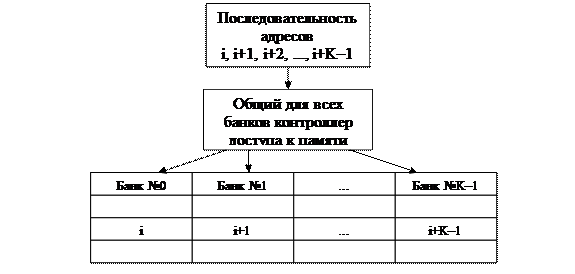
Рис. 24. ОЗУ без расслоения памяти — один контроллер на все банки.
Все ОЗУ состоит из K банков, каждый из которых может работать независимо. Ячейки памяти распределены между банками таким образом, что у любой ячейки ее соседи размещаются в соседних блоках. Что дает подобная организация памяти? Расслоение памяти позволяет во многом сократить задержки, возникающие из-за несоответствия времени доступа и цикла памяти при выполнении последовательного доступа к ячейкам памяти, т.к. при расслоении ОЗУ задержки, связанные с циклом памяти, будут возникать только в тех случаях, когда подряд идущие обращения попадают в один и тот же банк памяти. Используя организацию параллельной работы банков, в идеальном случае, можно повысить производительность работы ОЗУ в K раз. Для этих целей необходимо использовать более сложную архитектуру системы управления памятью.
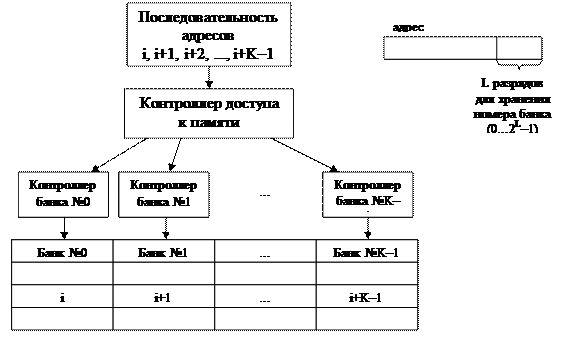
Рис. 25. ОЗУ с расслоением памяти — каждый банк обслуживает отдельный контроллер.
Другие свойства и характеристики оперативного запоминающего устройства мы будем рассматривать позднее по мере знакомства с основами архитектуры компьютеров и организацией и функционированием компонентов операционных систем.
1.2.3 Центральный процессор
Процессор, или центральный процессор (ЦП), компьютера обеспечивает последовательное выполнение машинных команд, составляющих программу, размещенную в оперативной памяти. Термин «центральный процессор» соответствует ситуации сегодняшнего дня, когда современный компьютер имеет в своем составе значительное количество специализированных управляющих компьютеров. Подобные компьютеры могут осуществлять управление контроллерами устройств, быть встроены в сами устройства, выполнять специализированные операции над данными программы.
Рассмотрим основные компоненты обобщенной структурной организации центрального процессора (Рис. 26).

Рис. 26. Структура организации центрального процессора.
1.2.3.1 Регистровая память
Регистровый файл (register file), или регистровая память, — совокупность устройств памяти процессора — т.н. регистров, предназначенных для временного хранения управляющей информации, операндов и/или результатов выполняемых команд. Регистровый файл обычно включает в себя регистры общего назначения (general-purpose register) и специальные регистры (special-purpose register).
Регистры общего назначения (РОН) состоят из доступных для программ пользователей регистров, предназначенных для хранения операндов, адресов операндов, результатов выполнения команд. Скорость доступа к содержимому регистров сравнима со скоростью обработки информации процессором, поэтому одной из основных причин появления регистров общего назначения было сглаживание дисбаланса в производительности процессора и скорости доступа к оперативной памяти. Наиболее часто используемые в программе операнды размещались на регистрах общего назначения, тем самым происходило сокращение количества реальных обращений в оперативную память, что, в итоге, повышало суммарную производительность компьютера. Состав регистров общего назначения существенно зависит от архитектуры конкретного компьютера.
Специальные регистры предназначены для координации информационного взаимодействия основных компонентов процессора. В их состав могут входить специальные регистры, обеспечивающие управление устройствами компьютера, регистры, содержимое которых используется для представления информации об актуальном состоянии выполняемой процессором программы и т.д. Так же, как и в случае регистров общего назначения, состав специальных регистров определяется архитектурой конкретного процессора. К наиболее распространенным специальным регистрам относятся: счетчик команд (program counter), указатель стека (stack pointer), слово состояния процессора (processor status word). Счетчик команд — специальный регистр, в котором размещается адрес очередной выполняемой команды программы. Счетчик команд изменяется в устройстве управления согласно алгоритму, заложенному в программу. Более подробно использование счетчика команд проиллюстрируем несколько позднее при рассмотрении рабочего цикла процессора. Указатель стека — регистр, содержимое которого в каждый момент времени указывает на адрес слова в области памяти, являющегося вершиной стека. Обычно данный регистр присутствует в процессорах, система команд которых поддерживает работу со стеком (операции чтения и записи данных из/в стек с автоматической коррекцией значения указателя стека). Слово состояния процессора — регистр, содержимое которого определяет режимы работы процессора, значения кодов результата операций и т.п.
1.2.3.2 Устройство управления. Арифметико-логическое устройство
Устройство управления (control unit) — устройство, которое координирует выполнение команд программы процессором. Арифметико-логическое устройство (arithmetic/logic unit) обеспечивает выполнение команд, предусматривающих арифметическую или логическую обработку операндов. Эти устройства являются своего рода «мозгом» процессора, т.к. именно функционирование устройства управления и арифметико-логического устройства обеспечивают выполнение программы. Рассмотрим упрощенную схему выполнения программы (Рис. 27) в модельном компьютере.

Рис. 27. Схема выполнения программы.
Пусть в начальный момент времени в счетчике команд СчК находится адрес первой команды программы. Для упрощения изложения будем считать, что система команд компьютера и система адресации оперативной памяти таковы, что любая команда размещается в одном машинном слове, адреса соседних машинных слов отличаются на единицу. Итак, рассмотрим последовательность действий в устройстве управления процессора при выполнении программы.
1. По содержимому счетчика команд СчК выбирается команда для выполнения. Формируется адрес следующей команды: СчК = СчК + 1.
2. Осуществляется анализ кода операции:
- Если это код арифметической или логической операции, то вычисляются исполнительные адреса операндов, выбираются значения операндов, команда передается для исполнения в арифметико-логическое устройство (передается код операции и значения операндов). В арифметико-логическом устройстве происходит выполнение команды, а также происходит формирование кода признака результата в регистре слова состояния процессора или в специальном регистре результата. Переход на п.1.
- Если это команда передачи управления, то происходит анализ условий перехода (анализируется содержимое кода признака результата предыдущей арифметико-логической команды с условиями перехода, соответствующими команде). Если условие перехода не выполняется, то переход на п.1. Иначе, вычисляется исполнительный адрес операнда Аперехода , затем: СчК = Аперехода, переход на п.1.
- Если команда загрузки данных из памяти в регистры общего назначения, то вычисляются исполнительные адреса операндов, выбираются значения операндов из памяти, значения записываются в соответствующие регистры. Переход на п.1.
Последовательность действий, происходящая в процессоре при выполнении программы, называется рабочим циклом процессора. По ходу рассмотрения материала мы будем уточнять рабочий цикл нашего обобщенного модельного компьютера.
1.2.3.3 КЭШ-память
Ключевой проблемой функционирования компьютеров является проблема несоответствия производительности центрального процессора и скорости доступа к информации, размещенной в оперативной памяти. Мы рассмотрели аппаратные и программно-аппаратные средства, применение которых позволяет частично сократить этот дисбаланс. Однако, ни организация расслоения памяти, ни использование регистров общего назначения для размещения наиболее часто используемых операндов не предоставили кардинального решения проблемы. Решение, которое на сегодняшний день является наиболее эффективным, основывается на аппаратных средствах, позволяющих при выполнении программы автоматически минимизировать количество реальных обращений в оперативную память за операндами и командами программы за счет кэширования памяти — размещения части данных в более высокоскоростном запоминающем устройстве. Таким средством является КЭШ-память (cache memory) — высокоскоростное устройство хранения данных, используемое для буферизации работы процессора с оперативной памятью. В общем случае, кэш представляет собою аппаратную «емкость», в которой аккумулируются наиболее часто используемые данные из оперативной памяти. Обмен данными при выполнении программы (чтение команд, чтение значений операндов, запись результатов) происходит не с ячейками оперативной памяти, а с содержимым КЭШа. При необходимости из КЭШа «выталкивается» часть данных в ОЗУ или загружаются из ОЗУ новые данные. Варьируя размеры КЭШа, можно существенно минимизировать частоту реальных обращений к оперативной памяти. Размещение и команд, и данных в одном КЭШе может приводить к тому, что команды и данные начинают вытеснять друг друга, увеличивая при этом обращения к оперативной памяти. Для исключения недетерминированной конкуренции в КЭШе между командами программы и обрабатываемыми данными современные компьютеры имеют два независимых КЭШа: КЭШ данных и КЭШ команд, каждый из которых работает со своим потоком информации — потоком команд и потоком операндов.
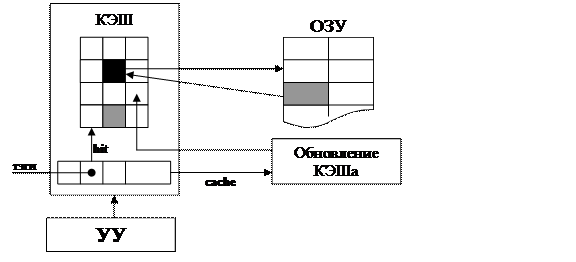
Рис. 28. Общая схема работы КЭШа.
Общая организация КЭШа следующая (Рис. 28).
1. Условно, вся память разделяется на блоки одинакового размера. Обмен данными между КЭШем и оперативной памятью осуществляется блоками (размер блока может соответствовать машинному слову или группе машинных слов). Здесь мы можем видеть возможное проявление преимущества использования памяти с расслоением, так как загрузка блока из оперативной памяти в КЭШ осуществляется с использованием параллелизма работы «расслоенной» оперативной памяти.
2. Каждому блоку КЭШа ставится в соответствие адресный тег, по содержимому которого возможно однозначно адресовать содержимое блока. Таким образом, после вычисления исполнительного адреса операнда или команды устройство управления может определить, находится ли соответствующая информация в одном из блоков КЭШ-памяти или нет. Факт нахождения искомых данных в КЭШе называется попаданием (hit). Если искомых данных нет в КЭШе, то фиксируется промах (cache miss).
3. При возникновении промаха происходит обновление содержимого КЭШа. Для этого выбирается блок-претендент на вытеснение, т.е. блок, содержимое которого будет заменено. Стратегия этого выбора зависит от конкретной организации процессора. Существуют КЭШи, вытеснение блоков которых осуществляется случайным образом, т.е. номер блока, который должен быть вытеснен, определяется с использованием встроенного генератора случайных чисел. Альтернативой случайного вытеснения является вытеснение наименее «популярного» блока, т.е. блока, к содержимому которого происходило наименьшее число обращений (LRU — Least-Recently Used).
4. Отдельно следует обратить внимание на организацию вытеснения блока в КЭШе данных, т.к. содержимое блоков КЭШа может не соответствовать содержимому памяти: это возникает при обработке команд записи данных в память. В этом случае также возможно использование нескольких стратегий. Первая — сквозное кэширование (write-through caching): при выполнении команды записи данных обновление происходит как в КЭШе, так и в оперативной памяти. Таким образом, при вытеснении блока из КЭШа происходит только загрузка содержимого нового блока. Данная стратегия оправдана, т.к. статистические исследования показывают, что частота чтения данных превосходит частоту их записи на порядок. Другой стратегией является кэширование с обратной связью (write-back caching), суть которой заключается в использовании специального тега модификации (dirty bit). При выполнении команды записи по адресу, содержимое которого кэшируется в одном из блоков, происходит обновление соответствующей этому адресу информации в блоке КЭШа, а также установка в блоке тега модификации. Соответственно, при вытеснении блока осуществляется контроль за содержимым тега. Если тег модификации установлен, то содержимое блока перед вытеснением «сбрасывается» в память. Тем самым минимизируется частота выполнения операции записи в память.
Кэширование памяти в современных вычислительных системах применяется не только для оптимизации взаимодействия центрального процессора и оперативной памяти. В настоящем пункте мы рассмотрели модельный аппарат КЭШ как компонент процессора — это т.н. КЭШ первого уровня. Современные компьютеры могут включать в свой состав иерархию устройств, кэширующих более медленные устройства хранения данных. Рассмотрению этого вопроса будет посвящен отдельный раздел.
Организация и использование КЭШ-памяти в процессоре развивает рабочий цикл модельного компьютера, рассмотренный выше: при выборке очередных команд, получении операндов команд и записи результатов выполнения команд в ОЗУ добавляются схемы организации использования КЭШ-памяти.
1.2.3.4 Аппарат прерываний
Если мы обратим внимание на представленный выше рабочий цикл процессора, то увидим, что такая схема не предусматривает возможности обработки ошибочной ситуации, которая может возникнуть в системе в ходе выполнения программы. Что будет с компьютером, если в программе, которую он выполняет, встретится команда с кодом операции, обработка которого не предусмотрена аппаратурой? Что будет, если выполняется корректная команда, но значения операндов приводят к невозможности выполнения соответствующей команде операции, например, деление на ноль? Что будет, если при программном обращении к внешнему устройству оно сломалось? В первых компьютерах происходила остановка работы всего компьютера, обработка ситуации, вызвавшей аварийную остановку (АВОСТ). Современные вычислительные системы не могут позволить себе остановку работы всей системы из-за возникновения тех или иных проблем в программе или в компонентах компьютера. Для решения проблем автоматизации обработки событий, возникающих в вычислительной системе, в современных компьютерах предусмотрен аппарат прерываний.
Прерыванием называется событие в компьютере, при возникновении которого в процессоре происходит предопределенная последовательность действий. Состав прерываний — множество разновидностей событий, на возникновение которых предусмотрена стандартная реакция центрального процессора, — фиксирован и определяется конструктивно при разработке компьютера. Аппарат прерываний компьютера позволяет организовывать стандартную обработку всех прерываний, возникающих при функционировании вычислительной системы. Традиционно прерывания разделяются на две группы: внутренние прерывания и внешние прерывания.
Внутренние прерывания инициируются схемами контроля работы процессора. К примеру, внутреннее прерывание может возникнуть в процессоре при попытке выполнения команды деления, операнд-делитель которой равен нулю. Также внутреннее прерывание возникнет в ситуации, когда при обработке очередной команды адрес одного из операндов выходит за пределы адресного пространства оперативной памяти.
Внешние прерывания — события, возникающие в компьютере в результате взаимодействия центрального процессора с внешними устройствами. Примером внешнего прерывания может служить событие, связанное с вводом символа с клавиатуры персонального компьютера.
Обработка прерывания предполагает две стадии: аппаратную, которая включает реакцию процессора на возникновение прерывания, и программную, которая предполагает выполнение специальной программы обработки прерывания, являющейся частью операционной системы.
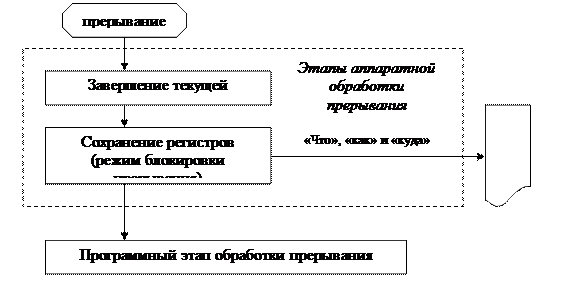
Рис. 29. Схема обработки прерывания.
Рассмотрим обобщенную модель последовательности действий, происходящих в ВС при возникновении прерывания (Рис. 29). Сначала рассмотрим этап аппаратной обработки прерывания.
1. Завершается выполнение текущей команды (за исключением случаев, когда прерывание возникает по причине некорректного выполнения команды).
2. Обработка прерывания предполагает остановку выполнения текущей программы, запуск специальной программы обработки прерывания, а затем, возможно, продолжение выполнения прерванной программы. Поэтому аппаратный этап обработки прерываний регламентирует перечень регистров, которые автоматически будут сохранены процессором. Это специальные регистры, содержимое которых описывает состояние процессора в точке прерывания выполнения программы (счетчик команд, регистр результатов, регистры, содержащие режимы работы процессора), а также несколько регистров общего назначения, которые могут быть использованы программой обработки прерываний в начальный момент времени. Процедура аппаратного сохранения регистров в различных компьютерах может происходить по-разному. Простейшая модель следующая. Включается режим блокировки прерываний. При этом режиме в системе запрещается инициализация новых прерываний: возникающие в это время прерывания могут либо игнорироваться, либо откладываться (зависит от конкретной аппаратуры компьютера и типа прерывания).
3. Аппаратное копирование содержимого сохраняемых регистров. Включенный режим блокировки прерывания гарантирует сохранность этих данных до момента завершения предварительной обработки прерывания и выключения блокировки прерываний.
4. Переход на программный этап обработки прерываний. Для перехода на программный этап обработки прерываний необходимо решить вопрос, как аппаратура передаст операционной системе информацию о том, какое прерывание произошло. Существует несколько моделей аппаратного решения этого вопроса.
- Первая модель — использование специального регистра прерываний, каждый разряд которого соответствует конкретному прерыванию, т.е. если, к примеру, в разряде, соответствующем прерыванию от клавиатуры появляется единица, это означает, что произошло соответствующее прерывание. Для расширения числа обрабатываемых прерываний возможно использование иерархической модели регистров прерывания (Рис. 30). Она предполагает, что имеется главный регистр прерывания и периферийные. В главном регистре прерывания выделяются разряды, индицирующие не только появление конкретных прерываний, но и разряды, индицирующие появление прерываний в периферийных регистрах. В данной модели управление передается в операционную систему на адрес входа в программу.
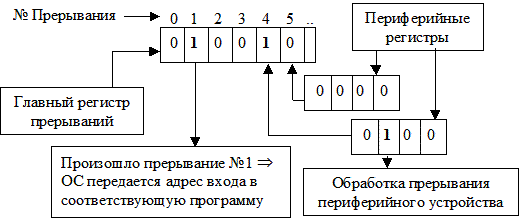
Рис. 30. Использование иерархической модели регистров прерывания.
- Вторая модель — использование регистра слова состояния процессора. В этом случае в данном регистре резервируется часть разрядов, в которых отображается номер возникшего прерывания. Управление также передается на фиксированный адрес входа в программу обработки прерываний.
- Третья модель — использование вектора прерываний. Предполагается, что по количеству возможных прерываний в ОЗУ выделена группа машинных слов — вектор прерываний. Каждое слово вектора прерываний содержит адрес программы, обрабатывающей данное прерывание (31). При возникновении прерывания после сохранения регистров осуществляется передача прерывания по адресу, соответствующему номеру прерывания.
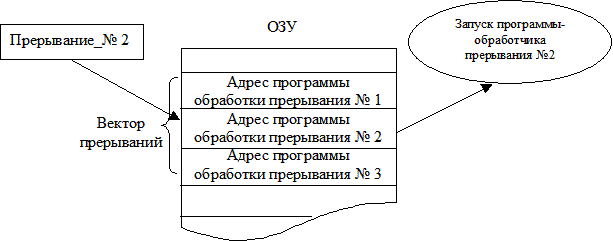
Рис. 31. Использование вектора прерываний.
Теперь рассмотрим этап программной обработки прерывания. Управление передано на адрес программы ОС, занимающейся обработкой прерывания. При входе в эту точку часть ресурсов ЦП, используемых программами, освобождена (результат аппаратного сохранения регистров). Поэтому будет запущена программа ОС, которая может использовать только освобожденные ресурсы ЦП (перечень доступных в этот момент регистров — характеристика аппаратуры). Выполняется следующая последовательность действий (Рис. 32).
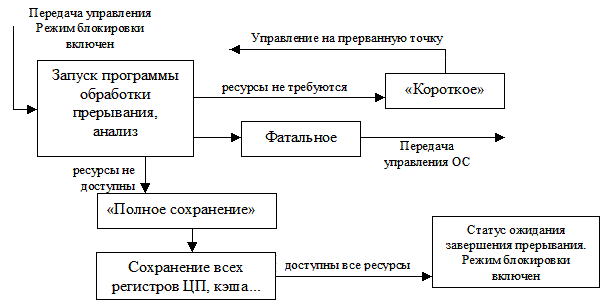
Рис. 32. Этап программной обработки прерываний.
1. Анализ и предварительная обработка прерывания. Происходит идентификация типа прерывания, определяются причины.
- Если прерывание «короткое», т.е. обработка не требует дополнительных ресурсов ЦП и времени, то прерывание обрабатывается, выключается режим блокировки прерываний, восстанавливается состояние процессора, соответствующее точке прерывания исходной программы, и передается управление на прерванную точку. Примером подобного «короткого» прерывания может служить прерывание от таймера для коррекции времени в системе. Если прерывание требует использования всех ресурсов ЦП, то переходим к следующему шагу (п.2).
- Если прерывание является «фатальным» для программы, т.е. после этого прерывания продолжить выполнение программы невозможно (например, в программе произошло обращение к несуществующему в ОЗУ адресу), то выключается режим блокировки прерываний, и управление передается в ту часть ОС, которая прекратит выполнение прерванной программы.
2. «Полное сохранение»: осуществляется полное сохранение всех регистров ЦП, использовавшихся прерванной программой, в специальную программную таблицу. В данную таблицу копируется содержимое регистровой или КЭШ-памяти, содержащей сохраненные значения ресурсов ЦП, а также копируются все оставшиеся регистры ЦП, используемые программно, но не сохраненные аппаратно. После данного шага программе обработки прерываний становятся доступны все ресурсы ЦП, а прерванная программа получает статус ожидания завершения обработки прерывания. В общем случае, программ, ожидающих завершения обработки прерывания, может быть произвольное количество.
3. До данного момента времени все действия происходили в режиме блокировки прерываний. Почему? Потому что режим блокировки прерываний — единственная гарантия того, что не придет новое прерывание, и при его обработке не потеряются данные, необходимые для продолжения прерванной программы (регистры, режимы, таблицы ЦП). После полного сохранения регистров происходит снятие режима блокировки прерываний, то есть включается стандартный режим работы процессора, при котором возможно появление прерываний.
4. Операционная система завершает обработку прерывания.
Мы рассмотрели модельную, упрощенную схему обработки прерывания: в реальных системах она может иметь отличия и быть существенно сложнее. Но основные идеи обычно остаются неизменными. Аппарат прерываний позволяет системе фиксировать и корректно обрабатывать различные события, возникающие как внутри компьютера, так и вне него.
1.2.4 Внешние устройства
Внешние[R6] устройства во многом определяют эксплуатационные характеристики как компьютера, так и вычислительной системы в целом. Размер экрана монитора, объем и производительность магнитных дисков, наличие печатающих устройств, модемов, и т.д. — характеристики компьютера на которые зачастую в первую очередь обращает внимание массовый пользователь. Значимость внешних устройств компьютера в вычислительной системе возрастала по мере развития сфер применения вычислительной техники. Если основным применением первых компьютеров было численное решение задач моделирования физических процессов, и для этих целей было достаточным иметь в компьютере высокопроизводительный (по меркам того времени) процессор, достаточный для решения задач данного класса объем оперативной памяти, простейшие устройства печати и ввода данных, внешнее запоминающее устройство для хранения исходных и промежуточных данных, то спектр внешних устройств современных компьютеров несоизмеримо шире, что соответствует разнообразию задач, решаемых средствами современных вычислительных систем (Рис. 33).

Рис. 33. Внешние устройства.
Мы более подробно остановимся на характеристиках и особенностях использования внешних запоминающих устройств, как наиболее интенсивно используемых и значимых внешних устройствах вычислительных систем.
1.2.4.1 Внешние запоминающие устройства
Внешние запоминающие устройства (ВЗУ) предназначены для организации хранения данных и программ. Обычно операции чтения или записи с ВЗУ происходят некоторыми порциями данных, которые называются записями. Данные, размещенные на ВЗУ, представляются в виде последовательности записей. Существует категория ВЗУ, называемые блочными устройствами, которые допускают выполнение обменов исключительно записями фиксированного размера — блоками. Примером блочных устройств могут служить различные типы магнитных дисков. Обычно размер блоков (физических блоков), обмен которыми может осуществляться с блочными устройствами, определяется аппаратно и может зависеть от конкретной модели и типа устройства. Альтернативой блочным ВЗУ являются устройства, аппаратно допускающие обмен записями произвольного размера. Примером таких устройств являются устройства хранения информации на магнитных лентах.
ВЗУ могут разделяться на две группы по возможностям доступа к хранящимся данным. Первая группа — устройства, аппаратно допускающие как операции чтения, так и операции записи. Примером устройств данной группы может служить жесткий диск. Вторая группа — устройства, позволяющие выполнять только операции чтения данных, например, в эту группу входят устройства CD-ROM (compact disk read-only memory), DVD-ROM (digital video/versatile disc read-only memory).
Внешние запоминающие устройства могут, также подразделяться на устройства прямого доступа и устройства последовательного доступа. Рассмотрим принципы организации и общие характеристики устройств, принадлежащих каждой из этих групп.
Устройства последовательного доступа — это устройства, при доступе к содержимому произвольной записи которых «просматриваются» все записи, предшествующие искомой. Рассмотрим в качестве примера ВЗУ последовательного доступа устройство хранения данных на магнитной ленте. На магнитной ленте каждая запись имеет специальные маркеры начала и конца. Также, на каждой ленте размещаются маркеры начала и конца ленты (Рис. 34).
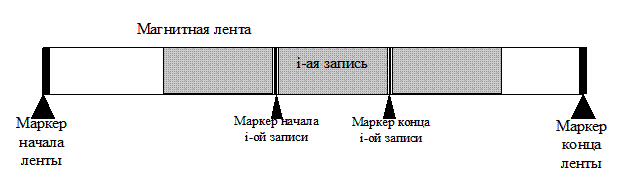
Рис. 34. Магнитная лента.
Каждая запись на ленте имеет свой логический номер. При возникновении запроса на чтение записи с номером i выполняется следующая последовательность действий:
- устройство перематывает ленту до маркера начала ленты;
- осуществляется последовательный поиск маркеров начала записей, после нахождения i-го маркера считается, что устройство «вышло» на начало искомой записи;
- происходит чтение i-ой записи.
Устройство прямого доступа обеспечивает выполнение операций чтения/записи без считывания дополнительной информации. Примером устройств прямого доступа могут служить магнитные диски, или дисковые устройства.
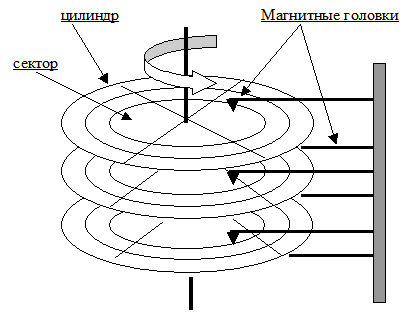
Рис. 35. Принцип устройства магнитного диска.
Магнитные диски являются самыми распространенными устройствами внешней памяти современных компьютеров. Рассмотрим принципиальную схему организации магнитного диска (Рис. 35). Устройство представляет собою вал, вращающийся с достаточно высокой постоянной скоростью. На валу закреплены диски, поверхности которых покрыты материалом, способным на основе магнитоэлектрических эффектов сохранять информацию. Количество дисков варьируется в зависимости от типа дискового устройства. Также в дисковом устройстве присутствует система головок чтения/записи. Количество головок соответствует количеству поверхностей дисков, и каждая головка может работать со своей фиксированной поверхностью. Все головки устройства составляют блок головок магнитного диска. Блок головок может перемещаться от края поверхностей к центру. Перемещение блока головок осуществляется дискретно, каждая позиция остановки блока головок над поверхностями (с учетом вращения дисков) образует цилиндр. Таким образом, каждое дисковое устройство характеризуется фиксированным количеством цилиндров, которые соответствуют позициям, на которых может размещаться блок головок.
Все цилиндры пронумерованы (0,1,....Nцилинд). Условные линии пересечения цилиндров с поверхностями образуют дорожки. Дорожки, относящиеся к одному цилиндру пронумерованы (0,1,....Nдорожки). Дорожки, принадлежащие одной поверхности, формируют концентрические круги. Все дорожки разделены на фиксированное для данного устройства число равных частей — секторов. Секторы каждой дорожки пронумерованы (0,1,....Nсектор). Начала всех одноименных секторов лежат в одной плоскости, проходящей через вал. При работе магнитного диска предусмотрена возможность индикации факта прохода блока головок через каждую точку начала сектора (это решается с использованием механических или оптических датчиков секторов), таким образом, блок головок всегда может «знать», над каким сектором он находится. В каждый момент времени в блоке головок может проходить обмен с одним из секторов. Рассмотрим пример выполнения операции обмена данными, размещенными в одном из секторов. Для задания координат конкретного сектора в устройство управления магнитным диском должны быть переданы:
- номер цилиндра, в котором расположен данный сектор, — Nc;
- номер дорожки, на которой размещается сектор, — Nt;
- номер сектора — Ns.
После получения координат сектора (Nc, Nt, Ns) выполняется следующая последовательность действий:
- шаговый двигатель перемещает блок головок в цилиндр Nc;
- включается головка чтения/записи, соответствующая номеру дорожки Nt;
- как только головка чтения/записи позиционируется над началом искомого сектора Ns, запускается выполнение операции чтения (или записи).
Таким образом, мы видим, что для выполнения операций обмена с магнитным диском не производится чтение какой-либо дополнительной информации с диска, т.е. обеспечивается «прямой доступ» к информации.
Производительность внешнего запоминающего устройства — время доступа к хранящейся информации — во многом определяется наличием и продолжительностью механических операций, которые необходимо провести при обмене. Так, время обмена с магнитным диском будет определяться в основном временем выдвижения блока головок в соответствующий цилиндр (это время перемещения блока головок из начального положения к цилиндру с максимальным номером), а также временем позиционирования головки в начало сектора, с которым будет осуществляться обмен (это время не больше времени полного оборота вала). При работе с магнитной лентой механическая составляющая обмена существенно больше, поэтому магнитные диски являются более высокопроизводительными устройствами и применяются для оперативного хранения обрабатываемых данных. Магнитные ленты используются для организации архивирования и долговременного хранения данных.
Следующее устройство, которое мы рассмотрим, — это магнитный барабан (Рис. 36). В данном приборе также имеется электродвигатель, к оси которого прикреплен массивный барабан, поверхность которого покрыта электромагнитным слоем. Двигатель раскручивает барабан до достаточно высокой постоянной скорости. Помимо этого имеется фиксированная штанга, на которой расположены головки чтения-записи. Под каждой головкой логически можно выделить дорожку, которая называется треком. Так же, как и в диске, все дорожки разделены на сектора. Для адресации блока данных в этом случае используется только номер дорожки (Nтрека) и номер сектора (Nсектора). Для того, чтобы произвести операцию чтения или записи, устройство управления должно включить головку, соответствующей указанному номеру дорожки, а после этого происходит ожидание механического поворота цилиндра до выхода головки на начало искомого сектора. Таким образом, по сравнению с жесткими дисками, в этом устройстве отсутствует механическая составляющая выхода головки на нужный трек, поэтому данный тип устройств считается более высокоскоростным.
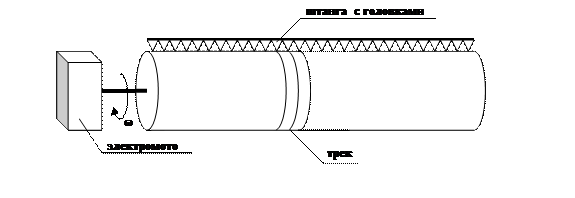
Рис. 36. Принцип устройства магнитного барабана.
Напоследок отметим, что магнитные барабаны на сегодняшний день являются в некотором роде экзотическими устройствами: они используются в основном лишь в больших специализированных высокопроизводительных компьютерах обычно для временного хранения данных из оперативной памяти.
И, наконец, отметим т.н. память на магнитных носителях (доменах). Под доменом понимается некоторая элементарная единица, способная сохранять свою намагниченность в течение длительного промежутка времени. Домен может быть намагничен одним из двух способов (отмеченные на Рис. 37 либо как «плюс-минус», либо как «минус-плюс»).
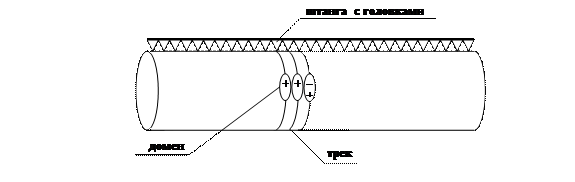
Рис. 37. Принцип устройства памяти на магнитных доменах.
Принцип работы устройства памяти на магнитных доменах основан на том, что под воздействием магнитно-электронных эффектов магнитные домены разгоняются вдоль своего трека до некоторой постоянной скорости. В остальном же принцип работы данного класса устройств ничем не отличается от работы магнитных барабанов. Соответственно, из-за того, что в данном устройстве нет механической составляющей, оно является еще более высокоскоростным по сравнению с предыдущими устройствами.
Для считывания или записи информации на данный носитель устройство управления включает необходимую головку, которая по таймеру синхронизируется с «приходом» начала искомого сектора, после чего происходит обмен с найденным сектором.
1.2.4.2 Модели синхронизации при обмене с внешними устройствами
Важной характеристикой, во многом определяющей эффективность функционирования вычислительной системы, является модель синхронизации, поддерживаемая аппаратурой компьютера при взаимодействии центрального процессора с внешними устройствами.
Для иллюстрации рассмотрим пример. Пусть выполняемой в компьютере программе необходимо записать блок данных на магнитный диск. Что будет происходить в системе при обработке заказа на данный обмен? Возможны две модели реализации обмена, рассмотрим их.
Синхронная работа с ВУ. При синхронной организации обмена в момент обращения к внешнему устройству программа будет приостановлена до завершения обмена (Рис. 38). Тем самым в системе возникали задержки, которые снижали эффективность функционирования ВС.
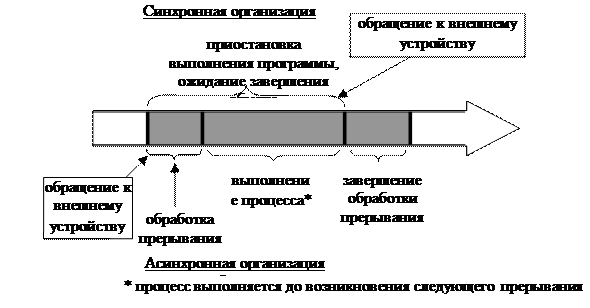
Рис. 38. Синхронная и асинхронная работа с ВУ.
Асинхронная работа с ВУ. При асинхронной организации работы внешних устройств последовательность событий, происходящих в системе, следующая:
1. Для простоты изложения будем считать, что в системе прерываний компьютера имеется специальное внутреннее прерывание «обращение к системе», которое инициируется выполнением программой специальной команды. Программа инициирует прерывание «обращение к системе» и передает заказ на выполнение обмена, параметры заказа могут быть переданы через специальные регистры, стек и т.п. В операционной системе происходит обработка прерывания, при этом конкретному драйверу устройства передается заказ на выполнение обмена.
2. После завершения обработки «обращения к системе» программа может продолжить свое выполнение, или может быть запущено выполнение другой программы.
3. По завершении выполнения обмена происходит прерывание, после обработки которого программа, выполнявшая обмен, может продолжить свое выполнение.
Асинхронная схема обработки обращений к ВУ позволяет сглаживать дисбаланс в скорости выполнения машинных команд и скоростью доступа к ВУ.
В заключении отметим следующее. Представленная выше схема организации обмена является достаточно упрощенной. Она не затрагивает случаев синхронизации доступа к областям памяти, участвующим в обмене. Проблема состоит в том, что, например, записывая область данных на ВЗУ, после обработки заказа на обмен, но до завершения обмена программа может попытаться обновить содержимое области, что является некорректным. Поэтому в реальных системах для синхронизации работы с областями памяти, находящимися в обмене, используется возможность ее аппаратного закрытия на чтение и/или запись. То есть при попытке обмена с закрытой областью памяти произойдет прерывание. Это позволяет остановить выполнение программы до завершения обмена, если программа попытается выполнить некорректные операции с областью памяти, находящейся в обмене (попытка чтения при незавершенной операции чтения с ВУ или записи при незавершенной операции записи данной области на ВУ).
1.2.4.3 Потоки данных. Организация управления внешними устройствами
При рассмотрении работы любого компьютера имеют место два потока информации. Первый поток — это управляющая информация, второй поток — это поток данных, над которыми осуществляется обработка в программе. Если рассматривать эти потоки информации в контексте организации работы ВЗУ, то можно выделить также поток управляющей информации, включающий в себя команды, обеспечивающие управление внешним устройством, а также поток данных, перемещающихся между данным ВЗУ и оперативной памятью. Рассмотрим теперь различные модели организации управления ВЗУ.
Простейшей моделью является непосредственное управление процессором внешними устройствами (Рис. 39). Это означает, что центральный процессор фактически «интегрирован» со схемами управления внешними устройствами, имеет специальные команды управления ими, а также путем интерпретации последовательности команд управления осуществляет управление обменом. Т.е. процессор подает команды устройству на перемещение головок обмена, на включение той или иной головки, на ожидание и синхронизации прихода содержательной информации и пр. Помимо указанного потока команд через центральный процессор обрабатывает и поток данных: он считывает информацию, участвующую в обмене, со специальных регистров и переносит ее в оперативную память (либо же производит обратные манипуляции). Таким образом, и поток управления, и поток данных проходит через центральный процессор, что само по себе является трудоемкой задачей, к тому же эта модель подразумевает лишь синхронную реализацию.

Рис. 39. Непосредственное управление центральным процессором внешнего устройства.
Следующая модель предлагает синхронное управление внешними устройствами с использованием контроллеров внешних устройств (Рис. 40). Данная модель появилась вслед за появлением внешних устройств, для которых имелись электронные схемы управления этими устройствами — контроллеры, — взявшие на себя часть работ центрального процессора по управлению обменами. В этом случае контроллер взаимодействует с центральным процессором блоками больших размеров, при этом контроллер может самостоятельно выполнять некоторые работы по непосредственному управлению ВЗУ (например, пытаться локализовать и исправить возможные ошибки, которые могут случиться при чтении или записи данных). Но исторически такой тип управления ВЗУ изначально был синхронным: процессор посылает устройству команды на обмен и ожидает, когда этот обмен завершится. Что касается потока данных, то ничего нового в данной модели не представлено: процессор по-прежнему считывает их со специальных регистров внешнего устройства и помещает их в оперативную память.

Рис. 40. Синхронное/асинхронное управление внешними устройствами с использованием контроллеров внешних устройств.
Вслед за предыдущим типом устройств появились устройства, позволяющие осуществлять асинхронное управление с использованием контроллеров ВЗУ (Рис. 40). В этом случае центральный процессор подает команду на обмен и не дожидается, когда эту команду отработают контроллер и устройство, т.е. он может продолжить обработку каких-то задач. Но для осуществления указанной модели необходимо, чтобы в системе был реализован аппарат прерываний.
Затем исторически появились т.н. контроллеры прямого доступа к памяти (DMA — Direct Memory Access, Рис. 41). Контроллеры данного типа исключили центральный процессор из обработки потока данных, взяв эту функцию на себя. В данной модели предполагается, что центральный процессор занимается лишь обработкой потоком управляющей информации, а данные перемещаются между ВЗУ и ОЗУ уже без его участия.

Рис. 41. Использование контроллера прямого доступа к памяти (DMA) или процессора (канала) ввода-вывода при обмене.
И, наконец, последняя модель основана на использовании процессора или канала ввода-вывода (Рис. 41). В этом случае предполагается наличие специализированного компьютера, который имеет свой процессорный элемент, свою оперативную память, который функционирует под управлением своей ОС, и этот компьютер располагается логически между центральным процессором и внешними устройствами. В функции подобных процессоров или каналов входит высокоуровневое управление внешних устройств. В этом случае центральный процессор оперирует с внешними устройствами в форме высокоуровневых заказов на обмен. Соответственно, реализация непосредственного управления конкретным ВЗУ осуществляется в процессоре ввода-вывода (в частности, в нем может происходить многоуровневая фиксация ошибок, он может осуществлять аппаратное кэширование обменов, и пр.).
1.2.5 Иерархия памяти
Рассматривая вычислительную систему, или компьютер, можно выстроить некоторую последовательность устройств, предназначенных для хранения информации в некотором ранжированном порядке, иерархии. Этот порядок можно определять на основе различных критериев: например, по стоимости хранения единицы информации или по скорости доступа к данным, но так или иначе устройства будут располагаться примерно в одном порядке (Рис. 42).
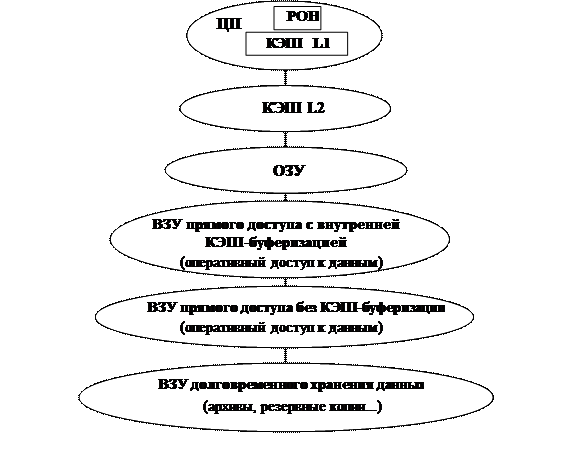
Рис. 42. Иерархия памяти.
Самой дорогостоящей и наиболее высокопроизводительной памятью является память, которая размещается в центральном процессоре (это регистровая память и КЭШ первого уровня (L1)).
Следующим звеном в этой иерархии может являться КЭШ второго уровня (L2). Это устройство логически располагается между процессором и оперативной памятью, оно является более дешевым и менее скоростным, чем КЭШ первого уровня, но более дорогое и более скоростное, чем ОЗУ, которое располагается на следующей ступени иерархии. Одним из основных свойств оперативной памяти являет то, что в ней располагается исполняемая в данный момент центральным процессором программа, т.е. процессор «берет» очередные операнды и команды для исполнения именно из оперативной памяти.
Ниже ОЗУ в приведенной иерархии следуют устройства, предназначенные для оперативного хранения программной информации пользователей и ОС. Сначала естественным образом следуют ВЗУ прямого доступа с внутренней КЭШ-буферизацией. Это дорогостоящие устройства, они предназначены для наиболее оперативного обмена. Так, на этих устройствах операционная система может размещать свои всякого рода информационные таблицы.
Следом за предыдущим типом устройств следуют ВЗУ прямого доступа без КЭШ-буферизации, которые также обеспечивают оперативных доступ, но уже на более низких скоростях. На подобных устройствах может находиться файловая система пользователей, код ОС (поскольку для системного устройства, с которого происходит загрузка ОС, скорость не особенно актуальна в отличие от устройства, хранящего данные работающей ОС).
И в самом низу иерархии располагаются ВЗУ долговременного хранения данных. Это системы резервирования, системы архивирования и т.д. Назначения данного класса устройств могут быть самыми разными, но все они характеризуются низкой скоростью доступа к данным и достаточно низкой стоимостью хранения единицы информации.
1.2.6 Аппаратная поддержка операционной системы и систем программирования
Если[R7] мы обратим свое внимание на рассмотрение компьютеров первого поколения, то это были компьютеры (computer — вычислитель) в прямом смысле слова, т.е. производители первых компьютеров ставили перед собой целью создание автоматических вычислений (причем достаточно в большом количестве). Но со временем круг пользователей расширялся, что привело к возникновению необходимости в присутствии в аппаратуре компьютера компонентов, предназначенных не столько для организации автоматизации вычислений, сколько для организации управления этими вычислениями. Этот раздел посвящен таким компонентам компьютера, которые изначально предназначались для аппаратной поддержки функционирования программного обеспечения, в частности, операционной системы и систем программирования.
1.2.6.1 Требования к аппаратуре для поддержки мультипрограммного режима
Выше уже речь уже шла о мультипрограммном режиме, когда в обработке могут находиться две и более программы пользователей, и каждая из этих программ может находиться в одном из трех состояний: во-первых, программа может выполняться на процессоре (т.е. ее команды исполняются центральным процессором), во-вторых, программа может ожидать завершения запрошенного ею обмена (для продолжения ее выполнения необходимо окончания обмена), и, наконец, в-третьих, программы могут находиться в ожидании освобождения центрального процессора (эти программы готовы к выполнению на процессоре, но процессор в данный момент занят иной программой). Мультипрограммный режим — это режим наиболее эффективной загрузки центрального процессора. На сегодняшний день мультипрограммный режим позволяет обрабатываться на компьютере большому числу процессов (задач), предоставляющих пользователю широкий круг различных услуг.
Рассмотрим схему организации мультипрограммного режима (Рис. 43). Пускай в начальный момент времени на процессоре обрабатывается Программа 1, которая в некоторый момент времени t1 выдает запрос на обмен, при этом дальнейшая обработка на процессоре невозможна до завершения этого обмена. В случае синхронной организации Программа 1 будет приостановлена, и процессор будет простаивать до завершения обмена Программы 1. Соответственно, со временем последовало естественное предложение запускать на обработку центральным процессором других программ, пока Программа 1 ожидает завершения своего обмена. На рисунке проиллюстрирована ситуация, когда при запуске обмена для Программы 1 на счет ставится Программа 2, которая выполняется до некоторого момента времени t2, после чего она приостанавливается по тем или иным причинам, и запускается Программа 3. После завершения обмена на обработку вновь ставится Программа 1, сменяя Программу 3 в момент времени t3.

Рис. 43. Мультипрограммный режим.
Естественно, для предложенного подхода возникает вопрос, какие аппаратные средства необходимы для корректного функционирования указанной системы. Под корректным функционированием мы будем понимать, что в независимости от степени мультипрограммирования (от количества обрабатываемых в системе программ) результат работы конкретной программы не зависит от наличия и деятельности других программ. Чтобы понять, какие требования предъявляются подобным системам, разберем сначала, какие трудности и проблемы могут возникнуть при мультипрограммном режиме.
Первая проблема, которая может возникнуть, — это влияние программ друг на друга. Очень нежелательна ситуация, когда одна программа может обратиться в адресное пространство другой программы и считать оттуда данные (поскольку все-таки необходимо обеспечивать конфиденциальность информации), и уж совсем плоха ситуация, когда другая программа может что-то записать в чужое адресное пространство. Соответственно, для корректного мультипрограммирования система должна обеспечивать эксклюзивное владение программ выделенными им участками памяти. Если возникает задача обеспечения множественного доступа к памяти, то это должно осуществляться с согласия владельца этой памятью. Итак, первое требование к системе — это наличие т.н. аппарата защиты памяти. Сразу отметим, что режим защиты памяти нельзя делать чисто программным способом, поскольку если данный режим будет обеспечивать операционная система (т.е. каждый раз сравнивать получаемый исполнительный адрес, не вышел ли он за границы дозволенного программе диапазона адресов), то производительность вычислительной системы в целом будет крайне низкой.
Реализация аппарата защиты памяти может быть достаточно простой: в процессоре могут быть специальные регистры (регистры границ), в которых устанавливаются границы диапазона доступных для исполняемой задачи адресов оперативной памяти. Соответственно, когда устройство управления в центральном процессоре вычисляет очередной исполнительный адрес (это может быть адрес следующей команды или же адрес необходимого операнда), автоматически проверяется, принадлежит ли полученный адрес заданному диапазону. Если адрес принадлежит диапазону, то продолжается обработка задачи, иначе же в системе возникает прерывание (т.н. прерывание по защите памяти). Отметим, что предложенная модель в реальной аппаратуре может быть реализована множеством способов, но главное, что при постановке программы на обработку операционная система (программным способом) задает значения указанных регистров границ, а дальнейшая проверка адресов осуществляется аппаратным способом.
Рассмотрим следующий круг возникающих при мультипрограммном режиме проблем. Предположим, в нашей мультипрограммной системе имеется единственное печатающее устройство, и есть несколько программ, которые выводят свои данные на печать данному устройству. Соответственно, если каждая программа будет иметь доступ к командам управления конечных физических устройств, то при совместной работе в режиме мультипрограммирования эти программы будут вперемешку обращаться к печатающему устройству и печатать на нем порции своих данных, что в итоге приведет к невозможности интерпретации напечатанной информации.
Другим примером может служить только что обсуждавшийся механизм защиты памяти. Значения указанных регистров границ устанавливаются посредством специальных машинных команд. Представьте ситуацию, когда к указанным командам смогут обращаться произвольные программы: тогда смысла в аппарате защиты памяти просто не будет — любая программа сможет обойти этот режим подменой своих регистров границ.
Рассмотрение представленных примеров должно наводить на мысль, что система должна каким-то способом ранжировать и в соответствии с этим ранжированием ограничивать доступ пользователей различных категорий к машинным командам. Решением стала аппаратная возможность работы центрального процессора в двух режимах: в режиме работы операционной системы (или привилегированном режиме, или режиме супервизора) и в пользовательском режиме (или непривилегированном режиме, еще раньше использовался термин математического режима). В режиме работы ОС процессор исполняет абсолютно все команды, представленные в программе. Если же программа исполняется в пользовательском режиме, то ей доступны для исполнения лишь некоторое подмножество машинных команд (если же при обработке такой программы встретится недопустимая команда, то в системе возникнет прерывание по запрещенной команде).
Тогда возникает вопрос, что должна делать программа, обрабатываемая в пользовательском режиме, для печати, например, своих данных. Решений здесь может быть достаточно много, одним из которых может быть наличие в системе специальных команд, интерпретируемых как обращения к операционной системе (которые в некоторых системах рассматриваются как прерывания, в других системах — не как прерывания; мы будем рассматривать их как прерывания по обращению к операционной системе). Тогда программа, работающая в непривилегированном режиме, может вызывать команды обращения к операционной системе, а через параметры, положим, передавать необходимые данные, которые могут свидетельствовать о желании данной программы распечатать какую-то информацию на устройстве печати. Тогда схема организации печати данных на устройстве печати может выглядеть следующим образом. Операционная система получает от пользователей (т.е. от пользовательских программ) заказы на печать, и для каждой из программы она формирует некоторую таблицу или область памяти, в которой будет аккумулироваться информация, которую необходимо вывести на принтер. Тогда каждый запрос программ на печать порции данных не является реальным обращением к устройству печати, но свидетельствует лишь о том, что передаваемая порция данных должна быть распечатана, а ОС их аккумулирует. Реальная печать будет осуществляться при возникновении одного из трех событий. Во-первых, программа, посылающая данные на печать, успешно завершилась. Это означает, что гарантированно она не будет более посылать данные на печать. Во-вторых, в программе обнаружилась фатальная ошибка, что ведет к безусловному завершению этой программы, что опять-таки гарантирует отсутствие будущих запросов данной программы на печать. И, в-третьих, операционная система может получить (от некоторого виртуального оператора, т.н. планировщика) команду разгрузить буфер печати данной конкретной программы.
И, наконец, еще одна серьезная проблема, которая может возникнуть при организации мультипрограммного режима, связана с тем, что в выполняемой в текущий момент программе встретилась семантическая ошибка — программа зациклилась. Соответственно, если в этом цикле не встречаются команды, которые могут привести к тем или иным прерываниям, то в этом случае вся вычислительная система «зависает»: никакие новые задачи не ставятся на счет и пр. Решение данной проблемы может быть довольно простым: необходима функция управления временем. Это означает, что операционная система должна контролировать время использования центрального процессора программами пользователя. Для этих целей компьютеру требуется прерывание по таймеру. Резюмируя, можно сказать, что для реализации мультипрограммного режима необходимо наличие аппарата прерываний, и этот аппарат, как минимум, должен включать в себя аппарат прерывания по таймеру. В этом случае зацикленная программа будет периодически прерываться, управление периодически будет попадать операционной системе, что даст возможность поставить на счет другую программу либо снять со счета (например, по команде пользователя) эту зависшую программу.
Итак, требуются три аппаратных средства компьютера, необходимых для поддержки мультипрограммного режима: аппарат защиты памяти, специальные режимы исполнения команд и аппарат прерываний, состоящий, как минимум, из аппарата прерывания по таймеру. Отметим, что специальных режимов может быть больше двух: т.е. часть команд доступна всем программам, часть команд могут выполняться лишь в защищенном режиме, еще часть — в более защищенном режиме, и т.д.
Может возникнуть резонный вопрос, как происходит включение режима супервизора. Ответ здесь будет зависеть от архитектуры конкретной системы. Например, в некоторых архитектурах считается, что операционная система занимает некоторое предопределенное адресное пространство физической памяти. И если управление попадает на эту область, то включается режим операционной системы. А вот выключение режима операционной системы может происходить программно: например, операционная система, запуская процесс, может предварительно программным способом установить его в непривилегированный режим.
1.2.6.2 Проблемы, возникающие при исполнении программ
Рассмотрим круг проблем, которые, так или иначе, возникают при исполнении программ.
Вложенные обращения к подпрограммам (Рис. 44). Несколько лет назад проводились исследования, которые анализировали распределение времени исполнения программы на разных компонентах программного кода, и выяснилось, что в системах, рассчитанных не только (и не столько) для выполнения математических вычислений (например, в системах обработки текстовой информации), порядка 70% времени тратится на обработку входов и выходов из подпрограмм. Это объясняется тем, что при обращении к подпрограмме необходимо зафиксировать адрес возврата, сформировать параметры, передаваемые вызываемой подпрограмме, как-то сохранить регистровый контекст (т.е. сохранить содержимое тех регистров, которые использовались в программе на данном текущем уровне).

Рис. 44. Вложенные обращения к подпрограммам.
Накладные расходы при смене обрабатываемой программы. Это аналогичная проблема, связанная со сменой обрабатываемых программ (или процессов): операционная система должна сохранить контексты процессов. К этому необходимо добавить, что в современных компьютерах количество одновременно обрабатываемых процессов очень велико, что лишь увеличивает объем возникающих накладных расходов.
Перемещаемость программы по ОЗУ (Рис. 45). Рассмотрим процесс получения исполняемого кода программы. После того, как исходный текст программы попадает на вход компилятору, образуется объектный модуль. А уже из пользовательских модулей и библиотечных формируется исполняемый код, т.е. тот модуль, который можно загрузить в оперативную память и начать его исполнять, причем момент создания исполняемого модуля и момент запуска его на исполнение разнесены во времени. Исторически первые исполняемые модули настраивались на те адреса оперативной памяти, в рамках которых он должен был исполняться. Это означает, что если память в данный момент занята другой программой, то эту программу поставить на счет не удастся (пока память не освободится). И, соответственно, возникает проблема перемещаемости программы по ОЗУ: ресурс свободной памяти в ОЗУ может быть достаточно большим, чтобы в ней разместилась вновь запускаемая программа, но в силу привязки каждой программы к конкретным адресам ОЗУ эту программу запустить не удается.

Рис. 45. Перемещаемость программы по ОЗУ.
Фрагментация памяти. Положим, что предыдущая проблема, связанная с перемещаемостью кода, решена в нашей системе: любой исполняемый модуль может быть загружен в произвольное место ОЗУ для дальнейшего выполнения. Но в этом случае возникает иная проблема.
Пускай наша система работает в мультипрограммном режиме. И в начале работы были запущены на исполнение Программа 1, Программа 2 и т.д., вплоть до некоторого номера K. Со временем некоторые задачи завершаются, а, соответственно, место, занимаемое ими в ОЗУ, высвобождается. Операционная система способна оценивать свободное пространство оперативной памяти и из буфера программ, готовых к исполнению, выбрать ту программу, которая может поместиться в свободный фрагмент памяти. Но зачастую размер загружаемой программы несколько меньше того фрагмента, который был свободен. И постепенно проявляется т.н. проблема фрагментации оперативной памяти (Рис. 46). В некоторый момент может оказаться, что в ОЗУ находится несколько процессов, между которыми имеются фрагменты свободной памяти, каждый из которых не достаточен для того, чтобы загрузить какую-либо готовую к исполнению программу. Но количество подобных фрагментов может быть настолько большим, что суммарно свободное пространство ОЗУ позволил бы разместить в нем хотя бы один готовый к исполнению процесс. Таким образом, система начинает деградировать: имея ресурс свободной памяти, мы не можем его использовать, а это означает, что система используется в усеченном качестве.

Рис. 46. Фрагментация памяти.
После того, как мы указали основные проблемы, возникающие при исполнении программ, рассмотрим, как эти проблемы могут решаться.
1.2.6.3 Регистровые окна
Одно из более или менее новых решений, предназначенное для минимизации накладных расходов, связанных с обращениями к подпрограммам, основано на использовании в современных процессорах т.н. регистровых окон (register windows). Суть этого решения заключается в следующем (Рис. 47). В процессоре имеется некоторое количество K физических регистров, предназначенных для использования в пользовательских программах. Эти регистры пронумерованы от 0 до K–1. Также имеется понятие регистрового окна — это набор регистров, по количеству меньший K, который в каждый момент времени доступен для программы пользователя. Соответственно, эти K физических регистров разделяются на регистровые окна некоторым способом. Один из способов предполагает, что с нулевого физического регистра начинается нулевое физическое окно, причем в этом нулевом физическом окне программе пользователя доступны физические регистры с номерами от 0 до L–1. Первое физическое окно представляет собою очередные L регистров, которые внутри окна также имеют нумерацию от 0 до L–1, но в реальности им соответствуют физические регистры с номерами, начинающимися с L–1. Т.е. окна организованы таким способом, что последний регистр предыдущего окна отображается на тот же физический регистр, что и нулевой регистр следующего окна.
Итак, имеющиеся K физических регистров разбиты на N окон, в каждом из которых регистры имеют номера от 0 до L–1. Соответственно, в системе организована логика таким способом, что все окна расположены в циклическом списке: нулевое окно пересекается с первым, первое — со вторым, и так далее, вплоть до N–1-ого окна, которое пересекается снова с нулевым. Также в системе имеется команда смены окна. Соответственно, при обращении к подпрограмме через пересекающиеся точки передаются адреса возвратов, а внутри окна можно работать с регистрами, причем при обращении к подпрограмме не встает необходимость их сохранения. Считается, что достигается эффект оптимизации при четырех окнах, что означает, что средний уровень вложенности подпрограмм не более четырех. Недостатком такого решения является фиксированный размер каждого окна, что на практике часто оказывается неоптимальным (т.к. иногда требуется больше регистров, иногда — меньше). Ниже на Рис. 48 приведены схемы работы с регистровыми окнами.
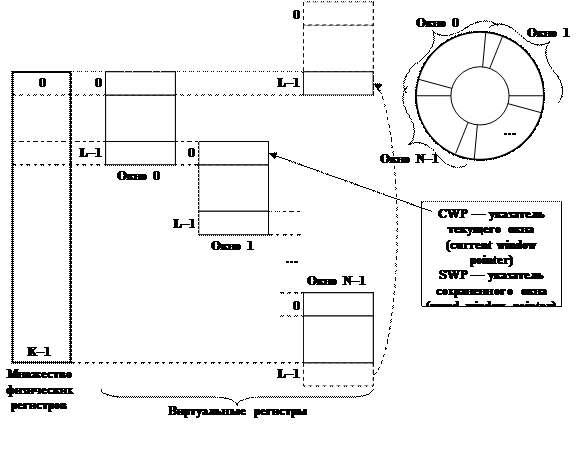
Рис. 47. Регистровые окна.
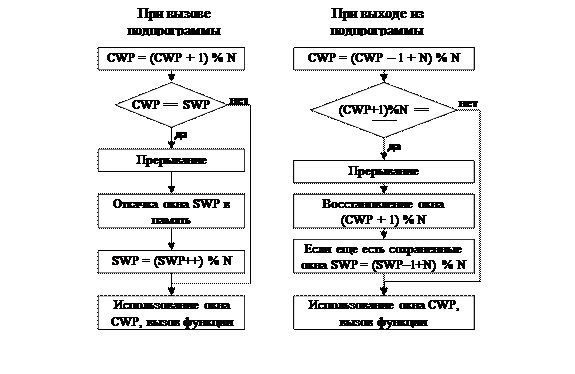
Рис. 48. Регистровые окна. Вход и выход из подпрограммы.
Модель организации регистровой памяти в Intel Itanium. В современных компьютерах имеется возможность варьирования размера регистрового окна. В частности, в 64-разрядных процессорах Itanium компании Intel размер окна динамический. В данном процессоре в регистровом файле первые 32 регистра (с номерами от 0 до 31) являются общими, а на регистрах с номерами от 32 по 127 организуются регистровые окна, причем окно может быть произвольного размера (например, от 32-ого регистра до регистра с номером 32+N, где N=0..95). Такая организация позволяет оптимизировать работу с точки зрения входов-выходов из функций и замены функциональных контекстов.
1.2.6.4 Системный стек
Будем рассматривать системы, в которых имеется аппаратная поддержка стека. Это означает, что имеется регистр, который ссылается на вершину стека, и есть некоторый механизм, который поддерживает работу со стеком. Системный стек может применяться для оптимизации работ, связанных со сменой контекстов программ. В частности, этот механизм может использоваться при обработке прерывания: если в системе возникает прерывание, процессор просто скидывает в стек содержимое необходимых регистров. Если же возникнет второе прерывание, то процессор поверх предыдущих данных скинет в стек новое содержимое регистров, чтобы обработать вновь пришедшее прерывание.
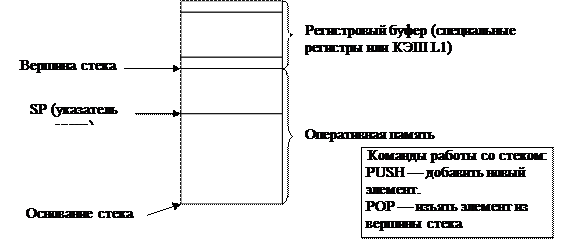
Рис. 49. Системный стек.
Но у данного подхода есть и недостаток. Поскольку стек располагается в оперативной памяти, то при каждой обработке прерывания процессору придется обращаться к оперативной памяти, что сильно снижает производительность системы при частых возникновениях прерываний. Решений может быть несколько (Рис. 49). Во-первых, в процессоре могут использоваться специальные регистры, исполняющие роль буфера, аккумулирующего вершину стека непосредственно в процессоре. Во-вторых, работу со стеком можно организовать посредством буферизации в КЭШе первого уровня (L1).
1.2.6.5 Виртуальная память
Следующий аппарат компьютера, который также сильно связан с поддержкой программного обеспечения, — это аппарат виртуальной памяти. Что понимается под виртуальной памятью и виртуальным адресным пространством? Неформально виртуальное адресное пространство можно определить как то адресное пространство, которое используется внутри программ (написанных, например, на языках программирования высокого уровня). Ведь когда программист пишет программу, оперируя теми или иными адресами, он зачастую не задумывается, где реально будут размещены, к каким физическим адресам привязаны. Виртуальные адреса существуют «вне машины». Соответственно, стоит проблема привязки виртуального адресного пространства физической памяти. И эта проблема решается за счет аппарата виртуальной памяти.
Итак, аппарат виртуальной памяти — это аппаратные средства компьютера, обеспечивающие преобразование (установление соответствия) программных адресов, используемых в программе, адресам физической памяти, в которой размещена программа при выполнении. И реализацией одной из моделей аппарата виртуальной памяти является аппарат базирования адресов.
Механизм базирования адресов основан на двоякой интерпретации получаемых в ходе выполнения программы исполнительных адресов (Aисп.прог.). С одной стороны, его можно интерпретировать как абсолютный исполнительный адрес, когда физический адрес в некотором смысле соответствует исполнительному адресу программы (Aисп.физ.= Aисп.прог.). Например, требуется «прочитать ячейку с адресом (абсолютным адресом) 0», или «передать управление по адресу входа в обработчик прерывания». С другой стороны, исполнительный адрес программы можно проинтерпретировать как относительный адрес, т.е. адрес, зависящий от места дислокации программы в ОЗУ. Иными словами, имеется оперативная память с ячейками с номерами от 0 до некоторого A–1, и, начиная с некоторого адреса K, расположена программа. Тогда адрес Aисп.прог. внутри программы можно трактовать, как отступ от физической ячейки с адресом K на величину Aисп.прог.. Для реализации модели базирования используется специальный регистр базы, в который в момент загрузки процесса в оперативную память операционная система записывает начальный адрес загрузки (т.е. K). Тогда реальный физический адрес получается, исходя из формулы Aисп.физ.= Aисп.прог.+<Rбазы>.
Аппарат базирования позволяет разрешить проблему перемещаемости программ по ОЗУ, поскольку процесс можно загрузить в любую область памяти. Но при этом необходимо помнить, что программа представляется в виде непрерывной области виртуальной памяти, которая загружается в непрерывный фрагмент физической памяти.
Развитием аппарата виртуальной памяти является аппарат страничной организации памяти. Ниже мы рассмотрим модельный сильно упрощенный пример страничной памяти. Данная модель представляет все адресное пространство оперативной памяти в виде последовательности страниц. Страница — это область адресного пространства фиксированного размера: обычно размер страницы кратен степени двойки, будем считать, что размер страницы 2k. Тогда все адресное пространство представимо в виде последовательности страниц (нулевая, первая и т.д.). Сказанное означает, что структура адреса представима в виде двух полей (Рис. 50): правые k разрядов представляют адрес внутри страницы, а оставшиеся разряды отвечают за номер страницы. Тогда количество страниц в системе ограничено разрядностью поля «Номер страницы».

Рис. 50. Страничная организация памяти.
В центральном процессоре имеется аппаратная таблица, называемая таблицей страниц, предназначенная для следующих целей. Количество строк в этой таблице определяется максимальным числом виртуальных страниц, ограниченное схемами работы процессора и максимальной адресной разрядностью процессора. Каждой виртуальной странице ставится в соответствие строка таблицы страниц с тем же номером (нулевой странице соответствует нулевая строка, и т.п.). Внутри каждой записи таблицы страниц находится номер физической страницы, в которой размещается соответствующая виртуальная страница программы. Соответственно, аппарат виртуальной страничной памяти позволяет автоматически (т.е. аппаратно) преобразовывать номер виртуальной страницы на номер физической страницы посредством обращения к таблице страниц (Рис. 51). Программных действий при таком подходе требуется минимально: при выборе операционной системой очередного процесса, который ставится на обработку на центральный процессор, она должна лишь корректно заполнить аппаратную таблицу страниц процессора для данного процесса.

Рис. 51. Страничная организация памяти. Преобразование виртуального адреса в физический.
Типовая схема преобразования адресов достаточно проста (Рис. 52). Пускай в таблице страниц имеется N строк. Это означает, что в компьютере дозволено использовать N страниц. Содержимое каждой i-ой строки таблицы — αi, оно определяется операционной системой в момент запуска процесса. Пускай в нашем модельном примере если αi >= 0, то это номер физической страницы, которая соответствует i-ой виртуальной странице. Если αi < 0, то это означает, что данной страницы у программы нет, и если в ходе обработки процесса процессор обращается к строке таблицы страниц с отрицательным содержимым, происходит прерывание по защите памяти. Причин возникновения прерывания в данном случае может две. Во-первых, может оказаться, что действительно i-ой виртуальной страницы у программы нет, что свидетельствует об ошибке в программе. Во-вторых, может оказаться, что соответствующей страницы нет в оперативной памяти, она расположена на внешнем запоминающем устройстве (ВЗУ), т.е. данная i-ая виртуальная страница легальна, но в данный момент ее нет в ОЗУ. Так или иначе, операционная система анализирует причину возникновения прерывания и для последнего случая осуществляет подкачку из ВЗУ в ОЗУ требуемой страницы.
Отметим, что страничная организация памяти решает все вышеперечисленные проблемы, связанные с выполнением программ. Здесь имеется механизм защиты памяти (в этой схеме процесс никогда не сможет обратиться к «чужой» странице), но также имеется возможность разделять некоторые страницы между несколькими процессами (в этом случае операционная система каждому из процессов допишет в таблицу страниц номер общей страницы). Данная схема обладает достаточной производительностью, поскольку ее функционирование построено на использовании регистров. Также данный подход решает проблему фрагментации, поскольку все программы оперируют в терминах страниц (каждая из которых имеет фиксированный размер). Помимо этого решается еще и проблема перемещаемости программ по ОЗУ, причем даже в рамках одной программы соответствие между виртуальными и физическими страницами может оказаться произвольным: ее нулевая виртуальная страница может располагаться в одной физической странице, первая виртуальная — в другой (совершенно не связанной с первой) физической странице, и т.д. Еще одним важным достоинством страничной организации памяти заключается в том, что нет необходимости держать в оперативной памяти весь исполняемый процесс. Реально в ОЗУ может находиться лишь незначительное число страниц, в которых расположены команды и требуемые для текущих вычислений операндов, а все оставшиеся страницы могут находиться на внешней памяти — в областях подкачки. Как следствие только что сказанного является то, что размеры физической и виртуальной памяти могут быть произвольными. Может оказаться, что физической памяти в компьютере больше, чем размеры адресного пространства виртуальной памяти, а может оказаться и наоборот: физической памяти существенно меньше виртуальной. Но во всех этих случаях система окажется работоспособной.
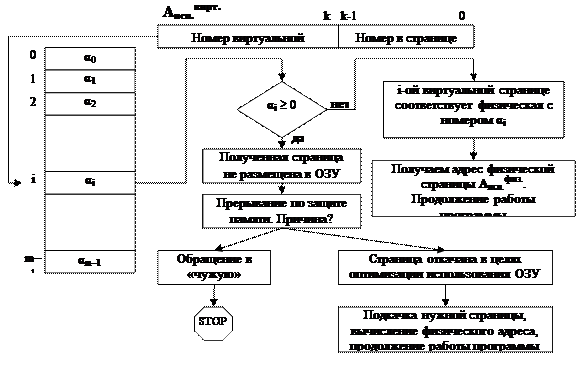
Рис. 52. Страничная организация памяти. Схема преобразования адресов.
Но данный подход имеет и свои недостатки. Во-первых, это страничная фрагментация, или внутренняя (скрытая) фрагментация: если в странице используется хотя бы один байт, то вся страница отводится процессу (т.е., решив вопрос с т.н. внешней фрагментацией, в указанном случае не используется память, размером со страницу минус один байт). К тому же описанная выше модель является вырожденной: если таблица страниц целиком располагается на регистровой памяти, то в силу дороговизны последней размеры подобной таблицы будут слишком малы (а следовательно, будет невелико количество физических страниц). Реальные современные системы имеют более сложную логическую организацию, и речь о ней пойдет ниже.
Напоследок заметим, что данное нами определение аппарата виртуальной памяти расходится с определениями некоторых других источников. Повторим, что мы рассматриваем механизм виртуальной памяти как механизм преобразования виртуального адресного пространства в физическое. Во многих изданиях, посвященных рассмотрению операционных систем, виртуальной памятью считается то, что позволяет часть программы размещать на внешних устройствах, т.е. считают механизм виртуальной памяти как средство увеличения объема физической памяти. Мы считаем такое определение некорректным. Если рассматривать, например, виртуальную память как механизм увеличения объема, то возникает вопрос: в случае большого объема физической памяти разве виртуальная память отсутствует? Соответственно, возникают проблемы с подобным определением.
И еще одно важное замечание. В компьютере имеется физическое адресное пространство и виртуальное. Физическое пространство — это та оперативная память, которая физически может быть подключена к компьютеру, а виртуальное адресное пространство — это то пространство, которое доступно программе. И возникает вопрос, что и каким способом задает максимальные размеры этих адресных пространств. На размер виртуального адресного пространства влияет разрядность исполнительных адресов, получаемых в ходе обработки программы на центральном процессоре. Размеры физического пространства определяется характеристикой компьютера: зависит от того, сколько физически можно подключить памяти к машине, и какова разрядность внутренней аппаратной шины. Но и то, и другое являются аппаратными характеристиками компьютера.
1.2.7 Многомашинные, многопроцессорные ассоциации
В[R8] настоящее время одиночный компьютер можно сравнить с телефонным аппаратом без телефонной сети. Т.е., говоря об ЭВМ, мы подразумеваем машину в некотором окружении и взаимодействии с другими машинами. В зависимости от степени интегрированности машин в рамках одного комплекса различают многопроцессорные ассоциации, где степень связанности машин довольно велика, и многомашинные ассоциации, в которых наблюдаются слабые связи между машинами (в некоторых случаях говорят о сетях ЭВМ).
Начиная данную тему, мы, следуя традиционному научному подходу, сначала рассмотрим классификацию — это позволит выявить среди большого разнообразия машинных ассоциаций группы с идентичными свойствами, которые помогут нам познакомиться с наиболее общими подходами, абстрагируясь от деталей реализации.
Для классификации существуют множество методов, проводящих деление по различным характеристикам (например, по производительности). Одна из наиболее простых классических классификаций — это классификация по Флинну (M.Flynn), основанная на оценке некоторых характеристик потоков информации в машине.
В контексте машины можно выделить два потока информации: поток управления (для передачи управляющих воздействий на конкретное устройство) и поток данных (циркулирующий между оперативной памятью и внешними устройствами). Возможны некоторые оптимизации данных потоков. В потоке команд — это переход от команд низкого уровня к высокоуровневым (когда ЦП вместо работы с микрокомандами начинает вырабатывать высокоуровневые команды, которые передаются «умному» устройству управления, непосредственно реализующему данные команды); в потоке данных — это исключение участия ЦП в обменах между внешними устройствами и оперативной памятью.
В классификации по Флинну выделяют следующие четыре архитектуры:
- ОКОД (одиночный поток команд, одиночный поток данных, или SISD — single instruction, single data stream) — это традиционная однопроцессорная система (близкая машине фон Неймана).
- ОКМД (одиночный поток команд, множественный поток данных, или SIMD — single instruction, multiple data stream) — например, векторные компьютеры, способные оперировать векторами данных. Обычно для этих целей в данных машинах существуют векторные регистры, а также обычно имеются векторные операции, предполагающие векторную обработку.
- МКОД (множественный поток команд, одиночный поток данных, или MISD — multiple instruction, single data stream) — данный класс архитектур является спорным. Существуют различные точки зрения о существовании каких-либо систем данного класса, и если таковые имеются, то какие именно. В некотором смысле сюда можно отнести специализированные системы обработки видео- и аудиоинформации, а также конвейерные системы.
- МКМД (множественный поток команд, множественный поток данных, или MIMD — multiple instruction, multiple data stream) — это системы, которые содержат не менее двух устройств управления (это может быть один сложный процессор с множеством устройств управления). На сегодняшний день данная категория во многом определяет свойства и характеристики многопроцессорных и параллельных вычислительных систем.
Среди систем МКМД можно выделить два подкласса: системы с общей оперативной памятью и системы с распределенной памятью (Рис. 53). Для систем первого типа характерно то, что любой процессор имеет непосредственный доступ к любой ячейке этой общей оперативной памяти. Слово «непосредственно» означает, что любой адрес может появляться в произвольной команде в любом из устройств управления. Системы с распределенной памятью представляют собою обычно объединение компьютерных узлов. Под узлом понимается самостоятельный процессор со своей локальной оперативной памятью. В данных системах любой процессор не может произвольно обращаться к памяти другого процессора. Указанные системы иллюстрируют противоположные подходы, на практике обычно встречаются промежуточные решения.
Рис. 53. Классификация МКМД.
Рассмотрение систем с общей оперативной памятью начнем с UMA. UMA (uniform memory access) — система с однородным доступом в память. В данной модели произвольный процессорный элемент имеет доступ к произвольной точке оперативной памяти (доступ с одинаковым временем). Развитием архитектуры UMA стала модель SMP (symmetric multiprocessor — симметричная мультипроцессорная система). В этой модели (Рис. 54) к общей системной шине, или магистрали, подсоединяются несколько процессоров и блок общей оперативной памяти. У данного решения можно отметить следующие недостатки. Во-первых, это централизованная система, и шина в ней является «узким горлом», поэтому данная модель накладывает существенные ограничения на количество подключаемых процессоров (обычно 2, 4, 8, вплоть до 32). Во-вторых, возникают дополнительные проблемы с КЭШ первого уровня каждого процессора. Решений тут как минимум два: либо не использовать КЭШ, либо реализовать КЭШ-память со слежением. В последнем случае каждый КЭШ слушает шину и реагирует на ситуацию в системе. Различные ситуации приведены в следующей таблице:
| Действия локального КЭШа (в том ЦП, где выполняется операцию) | Действия «внешнего КЭШа» (на других процессорах) | |
| R– (промах при чтении) | M → C (идет чтение из ОП в кэш) | ничего |
| R+ (попадание при чтении) | USE C (использование кэш) | ничего (т.к. ничего не увидит) |
| W– (промах по записи) | → M (обновление памяти, кэш не обновляется) | ничего |
| W+ (попадание при записи) | → C → M (обновление и КЭШа, и памяти) | соответствующая запись из КЭШа будет удалена |
Замечание. При промахе по записи производится только обновление памяти, т.к. реализуется стратегия, ориентированная на преимущественное чтение.

Рис. 54. SMP-система.
Иной подход к реализации систем с общей оперативной памятью предлагает архитектура NUMA (non-uniform memory access — система с неоднородным доступом в память). Для данных систем (Рис. 55) характерны следующие свойства:
- общее адресное пространство;
- характеристики доступа процессора к области оперативной памяти зависит от того, к каким областям идет обращение.
Модификацией модели NUMA является модель ccNUMA (Cache coherent NUMA) — это NUMA-система с когерентными КЭШами. Данные системы позволяют подключать несколько сотен процессоров, но остаются ограничения, связанные с использованием системной шины, а также возникают ограничения, связанные с cc-архитектурой: появляются системные потоки служебной информации, что ведет к дополнительным накладным расходам.
Теперь рассмотрим системы с распределенной оперативной памятью. Данный класс систем является наиболее перспективным с точки зрения их массового распространения и использования. Среди них можно выделить два основных класса: MPP (Massively Parallel Processors — процессоры с массовым параллелизмом) и COW (Cluster of Workstations — кластеры рабочих классов).

Рис. 55. NUMA-система.
MPP обычно являются дорогостоящими специализированными многопроцессорными системами, поэтому не находят массового применения. Системы данного класса имеют разнообразные формы архитектур: это могут быть макроконвейерные архитектуры, кубы и гиперкубы.
Что касается COW, то это многомашинные системы, состоящие из множества узлов, каждый из которых может быть обыкновенным компьютером. В качестве минимального узла может выступать процессор со своей локальной оперативной памятью и аппаратурой сопряжения с другими вычислительными узлами. Для сопряжения с другими вычислительными узлами используют специализированные компьютерные сети.
Кластеры могут создавать для достижения следующих основных целей:
- построение кластера как высокопроизводительной вычислительной системы, т.е. вычислительного кластера (критерием эффективности выступает скорость обработки информации);
- построение кластера, обеспечивающего надежность. Данный тип кластеров строится для решения конкретной прикладной задачи (например, сервер базы данных авиабилетов), при этом выход из строя некоторых узлов не означает отказ системы: система продолжается функционировать пускай и со сниженной производительностью.
Для построения вычислительных кластеров зачастую используют Unix-системы, а для кластеров надежности — Windows-системы. На сегодняшний день кластеры — это специализированные системы с соответствующей архитектурой (например, alpha-системы), при этом речь идет о супервычислительных кластерах, включающих в себя сотни – тысячи узлов. Основными проблемами кластерных систем являются отвод тепла и коммуникация (если будет использоваться единственная магистраль, то она «захлебнется» от потоков передаваемой информации, а большинство узлов будут простаивать).
Напоследок хочется отметить, что в рейтингах наиболее высокоскоростных вычислительных систем (Top100, Top500 и пр.) верхние строчки занимают именно кластерные системы.
Теперь рассмотрим проблемы сетевого взаимодействия.
1.2.8 Терминальные комплексы (ТК)