
Энергонезаваисимая память (NVRAM,Flash)








Всякая память сохраняющая данные при отключении внешнего источника питания может считаться энергонезависимой - NonVolatile Memory, однако этот термин больше утвердился за статической оперативной памятью:
· с встроенной в микросхему литиевой батарейкой большой емкости,
· с дополнительной EEPROM на том же кристалле, причем обмен данными между SRAM и EEPROM производится, либо программно, либо автоматически при падении/восстановлении напряжения.
Увеличение разрядности ячейки памяти
Если требуется хранить данные размером в n-бит, а длина слова ячейки памяти m-бит (n>m), то прибегают к наращиванию длины слова . Делается это путем объединения n / m - микросхем в группы, причем все одноименные входы, кроме информационных, соединяются между собой. Например, если требуется динамическая память емкостью 256K с длиной слова равной байту, то необходимо объединить 8 / 1 = 8 микросхем типа 565РУ7, как это показано на рис.7.19
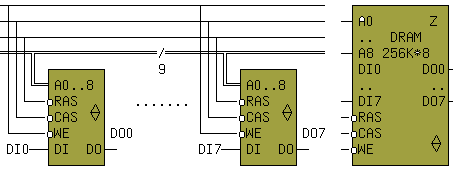
Рис.7.19
На рисунке девять линий адреса показаны в виде шины - т.е. группы проводников, объединенных по функциональному признаку .
Увеличение количества ячеек памяти
Увеличение адресного пространства ЗУ в 2k раз требует столько же микросхем памяти и "k" дополнительных линий адреса, к уже имеющимся "n"линиям An+k-1, . .An+0, An-1, An-2, ... A1, A0. Дополнительные адресные линии An+k-1 .. An+0 должны разбивать требуемое адрес- ное поле на 2k неперекрывающихся интервалов, покрываемых объемом памяти каждой отдельной микросхемы. Для решения этой задачи требуется дополнительный дешифратор "k в 2k". Например, если нужен блок ПЗУ емкостью 2K*4, то потребуется 8 микросхем 256*4 типа 541РТ1 и один дешифратор "3 в 8", как показано на рис. 7.20
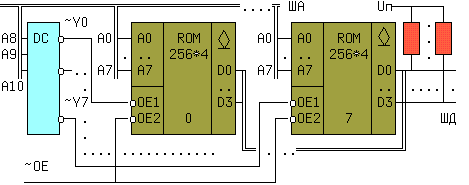
рис. 7.20
Одноименные j- е выходы микросхем с открытым коллектором соединены с общим нагрузочным резистором Rj. Три старших дополнительных бита адреса A10,A9,A8 выбирают одну из восьми микросхем, а восемь младших бит адреса выводят содержимое одной из 256-ти ячеек памяти на шину данных (ШД).Пусть на шину адреса (ША) поступил код A10..A0 = 11000011010 = 61A. На всех выходах дешифратора, кроме шестого (A10..A8 = 110 =6) будет высокий уровень. Нулевой сигнал ~Y6 = 0 на входе ~OE1 шестой микросхемы разрешит прохождение записанной информации на выходы, а код 1 1010 = 1A(HEX) = 26(DEC) на адресных входах A7..A0 извлечет содержимое 26-ой ЯП и поместит его на четыре линии шины данных (ШД).
Особенностью метода является необходимость объединения по ИЛИ(И) одноименных выходов микросхем. Это можно выполнить или подключением одноименных выходов к 2n- входовым схемам ИЛИ(И) для каждого разряда, или выполнять выходные структуры микросхем памяти по схеме допускающей монтажное ИЛИ(И) с открытым коллектором или с третьим состоянием, что целесообразней. По этой причине все микроросхемы памяти выпускаются с такими выходами .
8. PCI – шина данных
Высокоскоростной интерфейс: 32-64 разрядный с мультеплексированной ША данных.
Назначение :
Универсальный интерфейс (соединение процессора с переферийными элементами и системой процессора памяти). Имеется встроенная поддержка кэширования (механизм слежения за шиной – интерференция данных).
Скорость : 33,66,133 МГц.
Пересылки : 32 и 64 бит , следовательно ширина ШД : 4-8 байт
Групповые пересылки разрешаются (Burst) . Реализован скрытый арбитраж : арбитраж осуществляется в то время когда когда на шину идут пересылки (время не тратится). Низкая стоимость , определяется малым числом выводов (49 для ”мастер” и 47 для Slave). Простота использования : реализована функция авто конфигурирования системы. Высокая надёжность : при пересылки осуществляется контроль чёткости адреса данных.
 |

 AD0-AD7 AD72+AD63
AD0-AD7 AD72+AD63
 |  | |||||
 |  | |||||

 CBE CBE (4-7)
CBE CBE (4-7)
PAR PAR 64
 |  |
FRANE LOCK
| | | ||||
 | |||||
TROY INT A
 |  | ||||
 | |||||
IRDY INT B
| | | ||||
 | |||||
STOP INT C
| | |
DEVSEL INT D
 |
IP SEL SDONE
PERR TDO
SERR TDI
 REQ TCK
REQ TCK
GNT TRAS
| |
CLK TRST
| |
 RST
RST
RST – сброс
AD – мультиплексированная шина команд и подтверждение байтов
SBE – подтверждение байтов
PAR – чётность контроль : контроллируются все выше указанные разряды
FRAME – уравляется мастером или задатчиком шин ; указывает начало и конец пересылок
TRDY – устройство подчинено и готово к обмену
IRDY – мастер (инициатор) готов к обмену
STOP – требование к мастеру прекратить пересылки
hock – сигнал захвата шины
DEVSEL – подчинённое устр-во (slave) распознало свой адрес
IDSEL – сигнал выбора устр-ва при инициализации системы
PERR – ошибка чётности
SERR – системная ошибка
REQ – запрос мастера к арбитру на обладание шины
GNT – подтверждение арбитра мастеру , что шина ему предоставлена
INT A,B,C,D – запрос на преревание
Основные циклы
1.Чтение (система с изолированной шиной и каждое устр-во имеет свой дешефратор адреса)
а) позитивная дешефрация (устр-во опознаёт свой собственный диапазон адресов)
б) вычитательная дешифрация (на шине 1 устр-во , которое отвечает за все остальные не заполненные адреса) .
PCI : Реализованный синхронный алгоритм обмена синхронного сигнала – даёт приемушество в быстродействии
 |  | | | | | ||||||



 CLK 1 2 3 4 5
CLK 1 2 3 4 5
 | | ||||
 | |||||
FRAME
CIBE



 WRITE bite enables bite enables BE2
WRITE bite enables bite enables BE2
ADO-
ADN 


 ADDRESS данные D2 D2
ADDRESS данные D2 D2
 IRDY Мастер не готов
IRDY Мастер не готов



 TRDY slave не готов
TRDY slave не готов
IRDY = 1 и FRAME = 1 - обмен завершён.
Такт 1 : инициатор (мастер шины выставляет сигнал FRAME , который говорит ,что шина захвачена и выставлен сигнал IRDy ,следовательно устройство (мастер ) готово к обмену.
Такт 2 : к момену выставления фронта ,мастер выставляет команду WRITE и адрес ADDRESS ,по которому осуществляется обращение .
Такт 3 : в промежутке между татктом 2 и татктом 3 3slave определяет , что обращение осуществлено к нему и выставлен знак DEVSEV и TRDY.
Такт 3 : активное устр-во выставляет данные на ШД и выставляет сигнал Byte Enables, который подтверждает каждый из передоваемых байтов (читакт первую порцию данных адресованное устр-ву D1).
Такт 4: Slave не готов к обмену и выставляет сигнал TRDY и активное устр-во данные ен передаёт .
Такт 5 : Мастер не готов и выставляет сигнал об этом и Slave не принимает данные. Т5 –Т6 : оба устр-ва готовы к обмену и мастер выставляет порцию данных и Byte Enables Т7: цикл завершается: выыставляетоднавременно пару сигналов в IRDY =1 и FRAME=1 – цикл завешон.
Арбитраж: скрытый в PCI : освмещённый реальный арбитраж с работой др. устр-в . У каждого устр-ва сигналы REQ , GNT свои.
Активное устр-во выдаёт сигнал REQ на арбитр по своей линии . Арбитр определяет какое устр- во имеет наиболее высокий приоритет и по линии выдаёт сигнал GNT этому устр-ву.Активное устр-во выставляет сигнал FRAME ,что устр-во захвачено и осуществляет обмен.
Особенности :
1) Групповая пересылка
2) Встроенная поддержка кэширования
Неудобства – существование мостов и необходимость реализовать сопрягающее устройство .
9. Микропроцессоры и микроконтроллеры
Как известно, процессор является основным вычислительным блоком компьютера, в наибольшей степени определяющим его мощь. Процессор является устройством, исполняющим программу - последовательность команд (инструкций), задуманную программистом и оформленную в виде модуля программного кода. Чтобы понять, что делает процессор, рассмотрим его в окружении системных компонентов IBM PC-совместимого компьютера. Этой компьютерной архитектурой, естественно, не ограничивается сфера применения процессоров. Всем известный IBM PC-совместимый компьютер представляет собой реализацию так называемой фон-неймановской архитектуры вычислительных машин. Эта архитектура была представлена Джоном фон-Нейманом еще в 1945 году и имеет следующие основные признаки. Машина состоит из блока управления, арифметико-логического устройства (АЛУ), памяти и устройств ввода/вывода. В ней реализуется концепция хранимой программы: программы и данные хранятся в одной и той же памяти. Выполняемые действия определяются блоком управления и АЛУ, которые вместе являются основой центрального процессора. Центральный процессор выбирает и исполняет команды из памяти последовательно, адрес очередной команды задается "счетчиком адреса" в блоке управления. Этот принцип исполнения называется последовательной передачей управления. Данные, с которыми работает программа, могут включать переменные - именованные области памяти, в которых сохраняются значения с целью дальнейшего использования в программе. Фон-неймановская архитектура - не единственный вариант построения ЭВМ, есть и другие, которые не соответствуют указанным принципам (например, потоковые машины). Однако подавляющее большинство современных компьютеров основано именно на этих принципах, включая и сложные многопроцессорные комплексы, которые можно рассматривать как объединение фон-неймановских машин. Конечно же, за более чем полувековую историю ЭВМ классическая архитектура прошла длинный путь развития. В общем смысле под архитектурой процессора понимается его программная модель, то есть программно-видимые свойства. Под микроархитектурой понимается внутренняя реализация этой программной модели. Для одной и той же архитектуры разными фирмами и в разных поколениях применяются существенно различные микроархитектурные реализации, при этом, естественно, стремятся к максимальному повышению производительности (скорости исполнения программ). Сейчас существует множество архитектур процессоров, которые делятся на две глобальные категории - RISC и CISC. RISC - Reduced (Restricted) Instruction Set Computer - процессоры (компьютеры) с сокращенной системой команд. Эти процессоры обычно имеют набор однородных регистров универсального назначения, причем их число может быть большим. Система команд отличается относительной простотой, коды инструкций имеют четкую структуру, как правило, с фиксированной длиной. В результате аппаратная реализация такой архитектуры позволяет с небольшими затратами декодировать и выполнять эти инструкции за минимальное (в пределе 1) число тактов синхронизации. Определенные преимущества дает и унификация регистров. CISC - Complete Instruction Set Computer - процессоры (компьютеры) с полным набором инструкций, к которым относится и семейство х86. Состав и назначение их регистров существенно неоднородны, широкий набор команд усложняет декодирование инструкций, на что расходуются аппаратные ресурсы. Возрастает число тактов, необходимое для выполнения инструкций. Процессоры х86 имеют самую сложную в мире систему команд. Хорошо ли это, вопрос спорный, но груз совместимости с программным обеспечением для IBM PC, имеющим уже 20-летнюю историю, не позволяет расставаться с этим "наследием тяжелого прошлого". В процессорах семейства х86, начиная с 486, применяется комбинированная архитектура - CISC-процессор имеет RISC-ядро. Различают следующие способы организации вычислительного процесса:
· один поток команд - один поток данных (Simple Instruction - Simple Data, SISD) - характерно для традиционной фон-неймановской архитектуры (иногда вместо Simple пишут Single);
· один поток команд - множественный поток данных (Simple Instruction - Multiple Data, SIMD) - технология MMX;
· множественный поток команд - один поток данных (Multiple Instruction - Simple Data, MISD);
· множественный поток команд - множественный поток данных (Multiple Instruction - Multiple Data, MIMD).
8-разрядный микропроцессор i8080
На Рис. 9.1 представлена внутренняя структура МП i8080, включающего в себя 8-разрядное АЛУ с буферным регистром и схемой десятичной коррекции, блок РОН, регистры указателя стека SP и счетчика команд PC, первичный управляющий автомат УА, буферные схемы шин адреса и данных и схему управления системой.
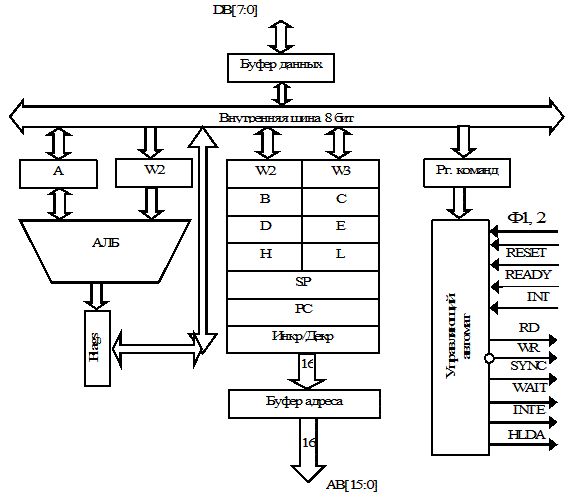
Рис. 9.1. Внутренняя структура МП i8080
Внешний интерфейс представлен 8-разрядной двунаправленной шиной данных D[7:0], 16-разрядной шиной адреса A[15:0] и группой линий управления.
Назначение входных и выходных линий МП :
D[7:0] - двунаправленная шина данных служит для приема и выдачи данных, приема команды, приема вектора прерывания, выдачи дополнительной управляющей информации (слово PSW);
A[15:0] - однонаправленная шина адреса служит для выдачи адреса памяти и устройств ввода/вывода;
Ф1,Ф2 - сигналы тактового генератора частотой 1..2,5 МГц;
RESET - сброс (начальная установка и запуск программы с адреса 0000);
READY - входной сигнал готовности памяти или ВУ к обмену (обеспечивает асинхронный режим обмена);
INT - запрос внешнего прерывания;
HOLD - захват шины (требование прямого доступа в память со стороны ВУ);
WR - запись - выходной сигнал, определяющий направление передачи информации по шине данных от процессора к памяти или ВУ;
RD - чтение - выходной сигнал, определяющий направление передачи информации по шине данных от памяти или ВУ к процессору;
SYNC - выходной сигнал, идентифицирующий наличие на шине данных дополнительной управляющей информации (PSW);
WAIT - выходной сигнал, отмечающий состояние ожидания или останова МП;
INTE - выходной сигнал, подтверждающий режим внешних прерываний;
HLDA - выходной сигнал, подтверждающий режим прямого доступа в память (подтверждение захвата).