
Организация системы шин L, S, X и M в компьютере РС/АТ








Электронный курс лекций по дисциплине
Компьютерная и микропроцессорная техника в электроприводе
по направлению подготовки 140400.62 Электроэнергетика и электротехника
Оглавление
Лекция № 1. Общая структура МПС
Лекция № 2. Принципы устройства современных МПС
Лекция № 3. Передача информации в МПС
Лекция № 4. Методы ввода/вывода и их классификация
Лекция № 5. Подсистема прерываний МПС
Лекция № 6 Подсистема прямого доступа в память МПС
Лекция № 7. Подсистема памяти МПС
Лекция № 8. PCI – шина данных
Лекция № 9. Микропроцессоры и микроконтроллеры
Лекция № 10. Цифровая обработка сигналов DSP (digital signal processor)
1. Общая структура МПС
Микропроцессор - центральная часть любой микропроцессорной системы (МПС) - включает в себя АЛУ и ЦУУ, реализующее командный цикл. МП может функционировать только в составе МПС, включающей в себя, кроме МП, память, устройства ввода/вывода, вспомогательные схемы (тактовый генератор, контроллеры прерываний и ПДП, шинные формирователи, регистры-защелки и др.).
В любой МПС можно выделить следующие основные части (подсистемы) :
· процессорный модуль;
· память;
· внешние устройства (внешние ЗУ + устройства ввода/вывода);
· подсистему прерываний;
· подсистему прямого доступа в память.
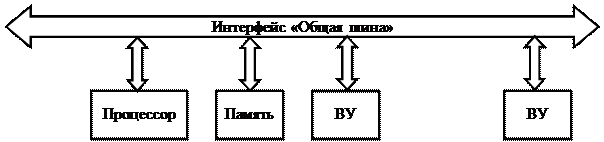 |
Связь между процессором и другими устройствами МПС может осуществляться по принципам радиальных связей, общей шины или комбинированным способом. В однопроцессорных МПС, особенно 8- и 16-разрядных, наибольшее распространение получил принцип связи "Общая шина", при котором все устройства подключаются к интерфейсу одинаковым образом (Рис.1.1).
Рис.1.1. Структура МПС с интерфейсом "Общая шина"
Все сигналы интерфейса делятся на три основные группы - данных, адреса и управления. Многочисленные разновидности интерфейсов "Общая шина" обеспечивают передачу по раздельным или мультиплексированным линиям (шинам). Например, интерфейс Microbus, с которым работают большинство 8-разрядных МПС на базе i8080, передает адрес и данные по раздельным шинам, но некоторые управляющие сигналы передаются по шине данных. Интерфейс Q-bus, используемый в микро-ЭВМ фирмы DEC (отечественный аналог - микропроцессоры серии К1801) имеет мультиплексированную шину адреса/данных, по которой эта информация передается с разделением во времени. Естественно, что при наличии мультиплексированной шины в состав линий управления необходимо включать специальный сигнал, идентифицирующий тип информации на шине.
Обмен информацией по интерфейсу производится между двумя устройствами, одно из которых является активным, а другое - пассивным. Активное устройство формирует адреса пассивных устройств и управляющие сигналы. Активным устройством выступает, как правило, процессор, а пассивным - всегда память и некоторые ВУ. Однако, иногда быстродействующие ВУ могут выступать в качестве задатчика (активного устройства) на интерфейсе, управляя обменом с памятью (т.н. режим прямого доступа в память - см. раздел 8).
Концепция "Общей шины" предполагает, что обращения ко всем устройствам МПС производится в едином адресном пространстве, однако, в целях расширения числа адресуемых объектов, в некоторых системах искусственно разделяют адресные пространства памяти и ВУ, а иногда даже и памяти программ и памяти данных.
Как известно, процессор является основным вычислительным блоком компьютера, в наибольшей степени определяющим его мощь. Процессор является устройством, исполняющим программу - последовательность команд (инструкций), задуманную программистом и оформленную в виде модуля программного кода. Чтобы понять, что делает процессор, рассмотрим его в окружении системных компонентов IBM PC-совместимого компьютера. Этой компьютерной архитектурой, естественно, не ограничивается сфера применения процессоров.
Всем известный IBM PC-совместимый компьютер представляет собой реализацию так называемой фон-неймановской архитектуры вычислительных машин. Эта архитектура была представлена Джоном фон-Нейманом еще в 1945 году и имеет следующие основные признаки. Машина состоит из блока управления, арифметико-логического устройства (АЛУ), памяти и устройств ввода/вывода. В ней реализуется концепция хранимой программы: программы и данные хранятся в одной и той же памяти.
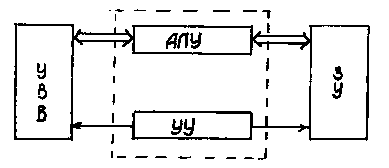
Рис. 1.1 Архитектура фон-Неймана
Если разделить память на: память программ и память данных мы получим Гарвардскую архитектуру.
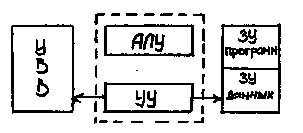
Рис. 1.2 Гарвардская архитектура
Выполняемые действия определяются блоком управления и АЛУ, которые вместе являются основой центрального процессора. Центральный процессор выбирает и исполняет команды из памяти последовательно, адрес очередной команды задается "счетчиком адреса" в блоке управления. Этот принцип исполнения называется последовательной передачей управления. Данные, с которыми работает программа, могут включать переменные - именованные области памяти, в которых сохраняются значения с целью дальнейшего использования в программе.
Фон-неймановская архитектура - не единственный вариант построения ЭВМ, есть и другие, которые не соответствуют указанным принципам (например, потоковые машины). Однако подавляющее большинство современных компьютеров основано именно на этих принципах, включая и сложные многопроцессорные комплексы, которые можно рассматривать как объединение фон-неймановских машин. Конечно же, за более чем полувековую историю ЭВМ классическая архитектура прошла длинный путь развития.
Прерывание – первое отличие современных архитектур от машин фон-Неймана. Работа прерывания заключается в том, что при поступлении сигнала прерывания процессор обязан прекратить выполнение текущей программы и немедленно начать обработку процедуры прерывания.
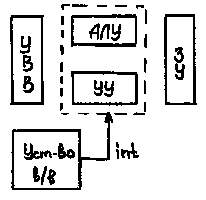
Рис. 1.3 Архитектура фон-Неймана с прерыванием
ПДП (Прямой Доступ к Памяти) – второе отличие современных архитектур от машин фон-Неймана. ПДП позволяет сократить расходы на пересылку единицы информации.
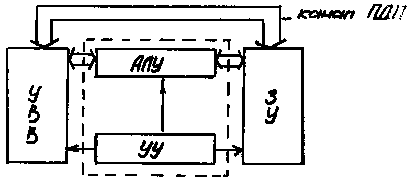
Рис. 1.4 Архитектура фон-Неймана с каналом ПДП
2. Принципы устройства современных МПС
Шинная организация IBM PC
В основу архитектуры IBM PC изначально был положен принцип открытости, который стал ее отличительной чертой. Основные конкуренты IBM в области персональных машин пришли к этому только через несколько лет после того, как указанный принцип позволил персональным компьютерам фирмы IBM практически завоевать компьютерный рынок.
Принцип открытости, строго говоря, основывается во-первых, на чрезвычайно развитой в IBM PC системе прерываний, которая позволяет “подключать” программы пользователя ко всем ресурсам системы на любом уровне, доступном пользователю, а во-вторых, на системе шин, организующей информационные потоки таким образом, чтобы не только позволить пользователю подключать к ресурсам процессора свои аппаратные средства (возможно, нестандартные), но и дать возможность самой архитектуре совершенствоваться и развиваться за счет введения дополнительных или новых компонентов без каких-либо принципиальных изменений в организации информационных потоков.
Принципы организации открытой системы прерываний будут рассмотрены ниже в отдельном разделе, а здесь остановимся на шинной организации информационных потоков, которая берет свое начало с первой модели IBM PC и эволюционирует сегодня. Как Вам известно из курса "Организации ЭВМ", шину микрокомпьютера образует группа линий передачи сигналов с адресной информацией, информацией о передаваемых данных, а также управляющих сигналов. Фактически ее можно разделить на три части: адресную шину, шину данных и шину управления.
Уровни этих сигналов в каждый момент времени определяют состояние всей вычислительной системы в этот момент. Далее мы привяжем обсуждение этих принципов функционирования к конкретной архитектуре ЭВМ, совместимых с IBM PC AT-286 и 386. На рис.2.1 изображено ядро гипотетической вычислительной системы, включающей, например, синхрогенератор i82284, микропроцессор i80286 и математический сопроцессор i80287, а также шинный контроллер i82288.
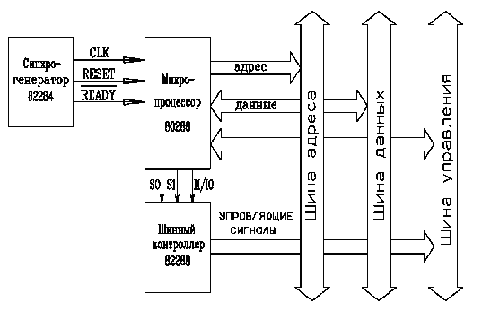
Рис 2.1. Шины компьютера.
Кроме того, показаны три шины: адреса, данных и управляющих сигналов. Синхрогенератор генерирует тактовый сигнал CLK для синхронизации внутреннего функционирования процессора и других микросхем. Сигнал RESET производит сброс процессора в начальное состояние. Сигнал READY, также формируется с помощью синхрогенератора, предназначен для удлинения циклов шины при работе с медленными периферийными устройствами. На адресную шину, состоящую из 24 линий, микропроцессор i80286 выставляет адрес байта или слова, которые будут пересылаться по шине данных в процессор или из него. Кроме того, шина адреса используется микропроцессором для указания адресов (номеров) периферийных портов, с которыми производится обмен данными.
Шина данных состоит из 16 линий, по которым возможна передача как отдельных байтов, так и двухбайтовых слов. При пересылке байтов возможна передача отдельно как по старшим 8 линиям, так и по младшим. Шина данных двунаправленна, т.к. передача байтов и слов может производиться как в микропроцессор, так и из него. Шина управления формируется сигналами, во-первых, поступающими непосредственно от микропроцессора, во-вторых, сигналами, сформированными системным контроллером, и, в-третьих, сигналами, идущими к микропроцессору от других микросхем и периферийных адаптеров. Микропроцессор использует системный контроллер для формирования управляющих сигналов, определяющих правила переноса данных по шине. Он выставляет три сигнала S0, S1, M/IO (выводы 5, 4 и 65), которые определяют тип цикла шины (подтверждение прерывания, чтение порта ввода/вывода, запись в порт ввода/вывода, останов, чтение памяти, запись в память). На основании значений этих сигналов системный контроллер формирует управляющие сигналы, определяющие последовательность процессов данного типа цикла шины.
Для того чтобы понять динамику работы шины, разберем, каким образом процессор осуществляет чтение слова из оперативной памяти. Это происходит в течение четырех тактов CLK (тактовых импульсов на входе 31 микропроцессора), или двух внутренних состояний процессора (т.е. каждое состояние процессора длится 2 такта синхросигнала CLK). Во время первого состояния, обозначаемого как Ts, процессор выставляет на адресную шину значение адреса, по которому будет читаться слово. Кроме того, он формирует на шине совместно с шинным контроллером соответствующие значения управляющих сигналов. Эти сигналы и адрес обрабатываются схемой управления памятью, в результате чего, начиная с середины второго состояния процессора Ts (т.е. в начале четвертого такта CLK) на шине данных появляется значение содержимого соответствующего слова из оперативной памяти. И, наконец, процессор считывает значение этого слова с шины данных. На этом перенос (копирование) значения слова из памяти в процессор заканчивается.
Организация системы шин L, S, X и M в компьютере РС/АТ
Следует отметить, что описанная выше система из одной, разбитой на три секции, шины, использовалась лишь в древних ЭВМ класса IBM PC XT. Имея название “Общая шина”, она и впрямь пронизывала весь компьютер, позволяя соединить в каждый момент времени процессор с одним из приборов памяти либо одним из контроллеров периферийных устройств. На самом деле в нашем компьютере имеется не одна, а несколько шин (см.рис.2.2). Основных шин четыре, и обозначаются они как L-шина, S-шина, М-шина и X-шина. Нами только что рассматривалась L-шина (или локальная шина), линии адреса и данных которой связаны непосредственно с микропроцессором. Можно ввести понятие удаленности шины от процессора, считая, что чем больше буферов отделяют шину, тем она более удалена от процессора. Тогда L-шина может считаться ближайшей к процессору.
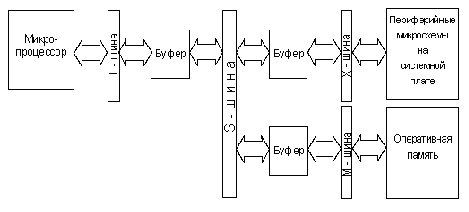
Рис 2.2. Шинная организация IBM PC AT
Основной шиной, связывающей компьютер в единое целое, является S-шина, или системная шина, к которой, кроме того, подключаются адаптеры периферийных устройств, не входящих в состав системного ядра. Именно она выведена на 8 специальных разъемов-слотов. Эти слоты хорошо видны на системной плате компьютера: в них установлены платы периферийных адаптеров (дисплея, флоппи-диска, винчестера, мыши и т.д.).
При переходе с шины L на шину S сигналы процессора должны претерпеть определенную трансформацию. В частности, максимальная нагрузочная способность линий микропроцессора не превышает одного TTL входа, так как максимальный выходной ток этих линий не должен превышать 1мА. Поэтому между линиями L - шины и S - шины должны располагаться буферные элементы, повышающие мощность выводов как минимум в сто раз. Кроме того, шина данных микропроцессора, как мы увидим в дальнейшем, не всегда должны соединяться с остальными частями ЭВМ. При выполнении так называемого внепроцессорного обмена микропроцессор вообще должен быть отключен от остальных схем компьютера.
Защелкивание (этот распространенный в среде инженеров - электронщиков термин обозначает сохранение информации в регистре) кода адреса необходимо по следующей причине. К тому моменту, когда на шинах данных появляется информация, подлежащая перемещению в микропроцессор или из него, должен уже быть подготовлен тракт передачи этой информации от источника к приемнику, проходящий через систему шин и образованный целым набором буферных усилителей и шинных формирователей. Как известно, переключение выводов микросхем из высокоимпедансного состояния в рабочее, а также переключение направления передачи информации требует определенного времени. Кроме того, время затрачивается на дешифрацию элементов, участвующих в данном обмене. Следовательно, адресная информация должна быть выставлена на шину заблаговременно - еще в конце машинного цикла, предшествующего циклу рассматриваемого обмена, и сохраняться в регистре. Кроме того, для максимально возможного увеличения скорости обмена адресная информация, необходимая для дешифрации периферийных микросхем, вообще фиксируется и участвует в подготовке обмена начиная примерно с середины предыдущего цикла. Этот вариант адреса, образующийся на линиях LA(17) - LA(23), и соответствующий адресу обмена в следующем цикле, меняется уже тогда, когда на остальных линиях адреса системной шины еще присутствует информация, соответствующая адресу обмена в текущем цикле.
Эволюция шинной архитектуры
Когда микропроцессор с рассмотренной шинной архитектурой выполняет, например, команду чтения из памяти, воздействие (адрес и сигналы управления) с локальной L шины попадает на системную S шину, а только затем на шину памяти M. После этого данные, считанные из памяти, опять-таки попадают на системную шину, а с нее - на локальную. Очевидно, что каждый перенос информации через тот или иной буферный элемент сопровождается определенной задержкой. И пусть одна задержка невелика (не более 10 наносекунд), но суммарно их набирается довольно много, что и определяет ту довольно низкую тактовую частоту, на которой работали первые IBM PC - 12, или даже 8 Мгц.
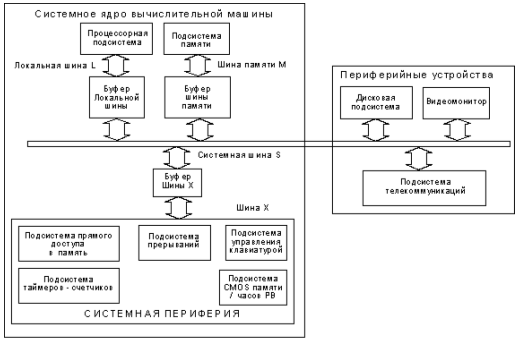
Рис 2.3 Классическая архитектура IBM PC AT 286
Для устранения таких потерь в более поздних моделях IBM PC AT 286 основная оперативная память выделяется в особую подсистему и доступ к ней осуществляется не через системную шину, а параллельно с доступом к системной шине. Как правило, это связано с наличием интегрированного контроллера шины данных. Суммарная задержка передачи данных в этом случае сокращается примерно до 20 нс, а тактовая частота повышается до 25 МГц.
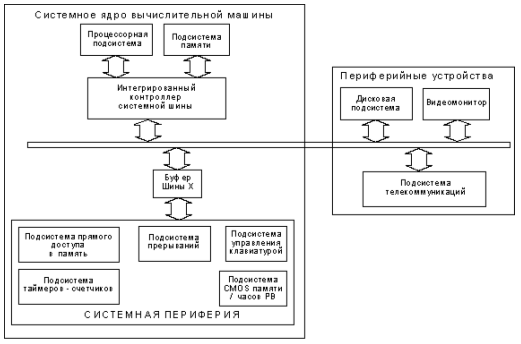
Рис 2.4 Архитектура IBM PC AT 286 поздних моделей
Дальнейшее совершенствование систем в этом направлении привело к тому, что переход от шины данных LD локальной шины к шине MD шины памяти упростился до предела. Функцию контроллера шины данных в этом случае выполняет обычный шинный формирователь. На первый взгляд, в нем нет необходимости и можно было бы просто объединить шины LD и MD. Но по соображениям согласования электрических сигналов этого нельзя делать.
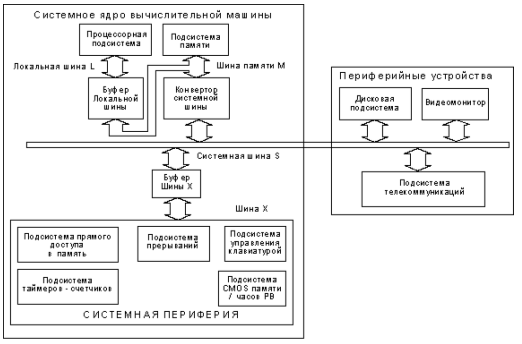
Рис 2.5 Архитектура IBM PC AT 386 с конвертором системной шины
Дальнейшие возможности повышения производительности процессора связаны с поисками решений в области архитектуры РС АТ. Введение кэш- памяти позволило ослабить требования по времени доступа к основной оперативной памяти (кэш-память - это статическая память с малым временем доступа, которая не “видна” для программного обеспечения. Объем ее колеблется от 128Кбайт до 1 Мбайт). При этом на локальной шине, кроме микропроцессора и сопроцессора, появляется контроллер управления кэш- памятью. При объеме памяти 128 Кбайт вероятность того, что необходимая микропроцессору информация окажется в кэш-памяти, состовляет 95-98%. Эффективность кэш-памяти становится значительной на частотах выше 20 Мгц, так как в этом случае потери производительности из-за задержек доступа к оперативной памяти очень чувствительны.
Последующие архитектурные изменения связаны с переходом от процессоров, имеющих 32 разрядные шины данных (i80386 и i80486), к процессорам, имеющим 64 разрядные шины, а именно к процессорам Pentium, Pentium Pro и Pentium II.
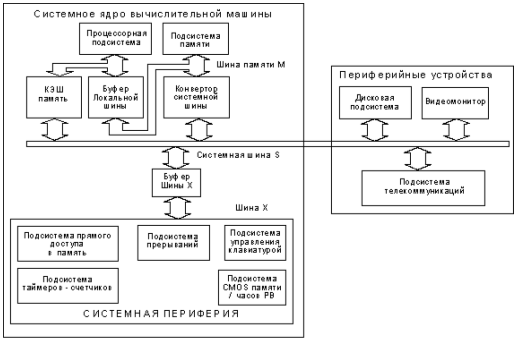
Рис 2.6 Архитектура IBM PC AT с кеш-памятью
3. Передача информации в МПС
При организации последовательного обмена ключевыми могут считаться две проблемы:
1) синхронизацию битов передатчика и приемника;
2) фиксацию начала сеанса передачи.
В МПС существует три способа передачи информации:
· асинхронный;
· синхронный;
· смешанный.
Асинхронный способ характеризуется тем, что сигналы передаются с произвольными промежутками времени.
Синхронный способ характеризуется тем, что сигналы передаются строго периодично во времени.
Смешанный способ характеризуется тем, что байты передаются асинхронно, а биты внутри байтов синхронно.