
Если исходный текст документа многоязычный, то можно указать несколько языков одновременно, однако следует принять во внимание, что увеличение числа включенных языков замедляет процесс распознавания.








Помимо языка оригинала, модуль распознавания учитывает и тип печати, который по умолчанию определяется автоматически, но при необходимости может быть установлен и вручную.
При распознавании текстов, напечатанных на матричном принтере в черновом режиме или на пишущей машинке, можно добиться более высокого качества распознавания, установив правильный тип печати. Выделяются два специфических типа печати: матричный принтер и пишущая машинка (Сервис/Опции/Тип печати). Символы, напечатанные на матричном принтере, состоят из отдельных точек, иногда хорошо различимых даже на глаз, а
213
символы пишущей машинки, как правило, имеют одинаковую ширину (моноширинные). Именно эти две особенности должен учитывать FineReader при распознавании. На обычных типографских шрифтах тип печати должен быть установлен в Auto.
9.9. ПРОВЕРКА ПРАВОПИСАНИЯ И СОХРАНЕНИЕ РЕЗУЛЬТАТОВ РАБОТЫ
Модуль распознавания анализирует не только отдельные символы, но и целые слова, используя при этом встроенный словарь. Кроме того, этот модуль особым образом помечает «неуверенно распознанные» символы.
Работа со словами, неизвестными системе, и с неуверенно распознанными символами осуществляется в модуле проверки правописания. Он вызывается кнопкой Проверить правописание. На рис. 9.5 вы видите спеллер FineReader за работой. Он предлагает варианты, один из которых надо выбрать и нажать кнопку Заменить. Можно поправить ошибку прямо в окне спеллера, а можно оставить слово, как оно есть, если это правильное, но не известное спеллеру слово, и тогда воспользуемся кнопкой Пропустить.
Весь распознанный текст виден в окне текста главного окна программы. Оно представляет собой несложный текстовый редактор, позволяющий свободно изменять и гарнитуру шрифта, и его начертание. К тому же в этом окне цветом будут отмечены неуверенно распознанные символы.

Рис. 9.5. Диалогоиос окно проверки ирапописания
214
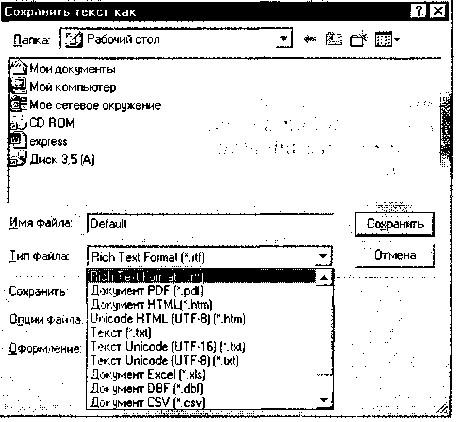
Рис. 9.6. Выбор формата сохранения изображения
После окончания проверки правописания следует определить, в каком формате сохранять полученные результаты (кнопка Сохранить), например RTF, DOC, PDF, HTML, DBF, XLS (рис. 9.6).
Как видно из приведенного списка, FineReader позволяет передавать результаты распознавания практически во все широко используемые приложения, такие как MS Word, MS Excel, а также использовать автоматический ввод для публикации в Web и для заполнения баз данных. Такая универсальность подчас оказывается просто незаменимой.
9.10. А ЕСЛИ ВЫ ПОЛЬЗУЕТЕСЬ ДРУГОЙ OCR-СИСТЕМОЙ?
У каждой модели сканера своя программа, в ней свои настройки, свои возможности. Но есть и кое-что общее.
Практически все программы делают быстрое предварительное сканирование (Preview), после которого вы можете:
• выделить мышью область сканирования. Если не производитьвыделение, тогда сканируется все рабочее поле сканера или же предыдущая ручная установка этой области;
• выбрать режим сканирования: цветной файл с различным ко-личеством цветов, черно-белый, в оттенках серого и другие режимы;
• выставить параметры яркости, контраста или выбрать авто-матическое определение этих параметров;
• запустить основное сканирование (Scan). '
215
Было бы неплохо научиться подбирать параметры изображения для оригиналов плохого качества в зависимости от вида дефектов исходного текста, ведь одно дело, когда текст напечатан бледной лентой печатной машинки, и совсем другое, когда шрифт слишком темный с жирными заплывшими буквами. И уж совсем иначе выглядят настройки для сканирования газетного листа на плохой бумаге с мелким шрифтом.
Подбор настроек сканера уменьшает количество неверно распознанных букв до вполне приемлемого качества сканирования и распознавания — есть надежда, что ошибки будут не в каждом слове, а хотя бы через строчку.
Это интересно