
Глава 8. A/B-тестирование








Тот, кто последовательно применяет #abtesting для принятия решений на основе данных, неизменно бывает удручен низким коэффициентом успешности идей.
Рон Кохави
Я усвоил тот факт, что эксперименты, данные и тестирование нужны не для доказательства моей правоты <…> Фактически, чтобы выбрать правильный ответ, мне нужна информация, полученная в результате этого тестирования.
Пи Джей Маккормик[128]
* * *
В 1998 году Грегу Линдену, одному из разработчиков Amazon на заре становления этого интернет-гиганта, пришла идея: почему бы не давать пользователям рекомендации при покупке? Супермаркеты раскладывают сладости на полках возле касс, чтобы стимулировать импульсивные покупки, и это работает. Почему бы не заглянуть в корзину пользователя на Amazon.com и не предложить ему персональную рекомендацию, которая может оказаться ему полезна? Линден создал прототип, убедился в его работоспособности и показал всем. О дальнейшем развитии событий лучше услышать из его уст:
В целом идея была воспринята положительно, но были некоторые затруднения. В частности, старший вице-президент по маркетингу выступал категорически против. Его основное возражение состояло в том, что это может отпугнуть пользователей, которые не захотят оформлять заказ, — это правда, что пользователи часто не завершают процесс покупки онлайн, — и он склонил остальных на свою сторону. На тот момент мне запретили продолжать работу в этом направлении. Мне сказали, что Amazon еще не готова к запуску подобного сервиса. На этом следовало бы остановиться.
Но не тут-то было. Я подготовил сервис для онлайнового тестирования. Я верил в силу рекомендаций, и мне хотелось измерить их влияние на продажи. Говорят, старший вице-президент был в бешенстве, когда узнал, что я готовлю эксперимент. К счастью, даже топ-менеджерам его уровня сложно препятствовать тестированию. Измерения — это всегда хорошо. Единственный весомый аргумент против, что негативный эффект от этого теста мог бы оказаться настолько сильным, что Amazon бы этого не выдержала. Вряд ли такое можно было утверждать, а потому я провел тестирование.
Результат говорил сам за себя. Этот сервис оказался не только востребованным, но разница в уровне продаж была настолько значительной, что отсутствие ее на Amazon в полном масштабе обходилось компании в кругленькую сумму упущенной выгоды. Все заторопились, но теперь уже чтобы запустить рекомендательный сервис для корзины пользователя.
Грегу очень повезло. Даже не в том, что его идея сработала (хотя, разумеется, это важно), а в том, что уже тогда компания Amazon располагала достаточной инфраструктурой для тестирования и такой корпоративной культурой, благодаря которой можно было добиться проведения этого теста. У него получилось доказать ценность своей идеи, реализовать ее на практике и повысить прибыль компании.
Во многих ситуациях, особенно новых для нас, интуиция не всегда срабатывает верно. Часто мы бываем удивлены результатом. Не верите? Тогда возьмем несколько быстрых примеров из онлайн-экспериментов. Первый пример — предложение о покупке в рекламном объявлении. С точки зрения количества переходов (индекс CTR), какое из них сработает лучше и насколько?
• Получите скидку 10 долл. с первой покупки. Заказывайте онлайн сейчас!
• Получите дополнительную скидку 10 долл. Заказывайте онлайн сейчас.
На практике второй вариант оказался эффективнее первого, его индекс CTR был в два раза выше[129]. А как насчет пары объявлений на рис. 8.1? (Кстати, вы заметили, чем они отличаются?) Какое сработает лучше и насколько?
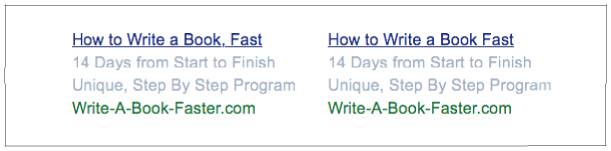
Рис. 8.1. У какого из этих вариантов индекс CTR будет выше? У грамматически правильного объявления слева индекс CTR на 8 % выше (4,4 % по сравнению с 4,12 %).
Вариант слева, грамматически верный благодаря добавлению одной-единственной запятой, был на 8 % эффективнее.
Наконец, в заключительном примере (рис. 8.2) даны две практически идентичные версии интернет-страницы — за исключением того, что в варианте слева все поля в форме для заполнения необязательные. У этого варианта коэффициент конверсии был на 31 % выше. Более того, качество этих контактов было выше.
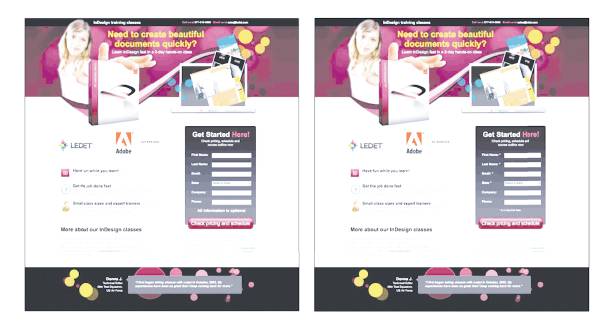
Рис. 8.2. В варианте слева все поля формы для заполнения необязательны. Коэффициент конверсии этого объявления на 31 % выше, более того, качество этих контактов тоже было выше
Источник: https://www.behave.org/test/adobe-training-company-tests-required-form-fields-vs-not-required-%E2%80%93-which-version-got-a-31-lift-in-lead-gen-form-submissions/
Во всех этих примерах было сложно прогнозировать, какой вариант окажется эффективнее, и еще сложнее было предсказать влияние на другие показатели. Именно поэтому качественно подготовленный эксперимент имеет такую ценность. Он переводит диалог из плоскости «Мне кажется…» в плоскость «Согласно данным…». Таким образом, это неоценимый компонент компании с управлением на основе данных.
Давайте рассмотрим этот аспект в перспективе. В главе 5 мы провели обзор пяти видов анализа, включая каузальный анализ, являющийся вершиной аналитической работы, по крайней мере, с точки зрения обычного бизнеса. Контролируемый эксперимент, применение научного метода или «научных методов работы с данными»[130] — прямой способ выявить эти причинно-следственные отношения.
Три примера, обсуждавшихся выше, представляли собой варианты эксперимента под названием A/B-тестирование. Сейчас я приведу краткое его описание. Какие-то подробности и детали я добавлю чуть ниже в этой главе, а сейчас опишу основную идею. При проведении A/B-тестирования вы устанавливаете контроль, например, над текущим состоянием сайта (вариант А). Половину трафика своего сайта вы направляете на эту версию. Эти посетители сайта будут относиться к группе А. Вторую половину пользователей вы направляете на другую версию сайта, имеющую небольшие отличия, например, надпись на кнопке для оформления заказа — «Приобрести», а не «Купить сейчас» (вариант В). Эти посетители сайта относятся к группе В. Вы определяете показатель, который хотите протестировать, например влияет ли надпись на кнопке на уровень средней выручки на посетителя. Вы проводите эксперимент в течение установленного времени (дней или недель), а затем осуществляете статистический анализ. Вы анализируете, отмечается ли статистически значимая разница в фокусном поведении — в данном случае в показателе выручки на посетителя — между группой А и группой В. Если разница есть, то в чем ее причина? Если эксперимент был полностью контролируемым (то есть в условиях имелось лишь одно небольшое отличие), возможны два варианта. Это могла быть случайность, что вероятно при слишком маленьком размере выборки (то есть эксперимент не соответствовал стандартам). Или же разница между вариантами А и В носит причинно-следственный характер. Согласно данным, фактор, который отличался, вызвал изменение поведения пользователей.
Поскольку объективное проведение экспериментов и их влияние на корпоративную культуру — критически важный фактор для компании с управлением на основе данных, эта глава будет посвящена A/B-тестированию. Мы охватим оба подхода: более распространенный классический частотный подход, а также более современный байесовский подход. Мы подробно разберем, как проводить тесты, на примерах того, как это делать и как этого делать не стоит. Помимо примеров, описанных ранее, я приведу еще ряд примеров, позволяющих понять, зачем нам все это нужно и какое существенное влияние это может оказать на бизнес. Итак, приступим.
Почему A/B-тестирование?
Как уже говорилось, наша интуиция может нас подвести (подробнее к этому мы еще вернемся в главе 9). Даже эксперты в определенных областях ошибаются чаще, чем им бы хотелось это признать. В своей книге A/B Testing: The Most Powerful Way To Turn Clicks Into Customers (Wiley & Sons) Дэн Сирокер, генеральный директор и создатель платформы для A/B-тестирования Optimizely, рассказывает о некоторых аспектах работы своей компании в 2008 году во время предвыборной кампании Барака Обамы. Перед ними стояла задача оптимизировать интернет-страницу для потенциальных сторонников Обамы и с ее помощью собрать базу адресов электронной почты этих людей. Изначально на странице была размещена статичная картинка с красной кнопкой с надписью «SIGN UP» («ПОДПИСАТЬСЯ»). Команда разработчиков полагала, что видеоролики с самыми убедительными выступлениями будут привлекать пользователей эффективнее статичного изображения. После того как были протестированы разные статичные картинки и разные видеоролики, стало ясно, что «любой видеоролик значительно уступает любому изображению». Оптимальное сочетание изображения и надписи на кнопке (лучшим вариантом оказался «LEARN MORE» («ПОДРОБНЕЕ») повысило уровень подписки на 40,6 %. Это соответствовало дополнительно почти 2,8 млн подписчиков, 280 тыс. волонтеров и невероятным 57 млн долл. дополнительных пожертвований. Бывает невозможно предугадать, что и как именно сработает: поведение людей непостоянно и непредсказуемо. Тем не менее результаты, подобные этим, показывают, что мы можем получить важное конкурентное преимущество и непосредственно узнать своих текущих и потенциальных клиентов.
Более того, онлайн-тестирование — относительно недорогое и простое. Не обязательно требуются новые технологии и творческие усилия, чтобы сделать новую версию надписи на кнопке «ПОДРОБНЕЕ» вместо «ПОДПИСАТЬСЯ». Кроме того, эти изменения не навсегда. Если вы что-то попробовали, но это не сработало, просто вернитесь к первоначальному варианту. В любом случае вы узнаете что-то новое о своих клиентах. Вы практически ничем не рискуете.
Предметом тестирования может стать все что угодно. В какой бы отрасли вы ни работали, всегда есть что оптимизировать и имеются уроки, которые можно извлечь. Команда, работавшая на предвыборный штаб Обамы, проводила множество самых разных тестов. Она тестировала темы сообщений в электронных рассылках, содержание рассылок, время отправления и частоту, все аспекты сайта, даже сценарии, на которые волонтеры опирались в беседе с потенциальными донорами. Как показывает этот пример, подобное тестирование может не ограничиваться только онлайн-форматом. В качестве еще одного примера можно привести маркетинговые акции по увеличению лояльности покупателей, когда компания неожиданно дарит подарки определенной категории клиентов. Эти акции следует тщательно продумывать. С их помощью можно сравнивать такие показатели, как процент возврата, «пожизненная ценность клиента», а также положительные отзывы в социальных сетях от тех, кто получил подарок, и тех, кто не получил. Во всех этих случаях к экспериментам следует относиться с таким же уровнем научной строгости и структурировать их с той же тщательностью, что и онлайн A/B-эксперименты.
Один из приятных аспектов A/B-тестирования в том, что вам не требуется предварительного причинно-следственного объяснения, почему что-то должно сработать. Нужно просто провести тест, изучить результаты и найти те факторы, которые обеспечивают позитивное влияние. Кохави отмечает, что в Amazon половина экспериментов не приносила результатов, а в Microsoft — две трети[131]. Чтобы выиграть в долгосрочной перспективе, совсем не обязательно, чтобы срабатывал каждый эксперимент. Единственное положительное изменение способно оказать огромное влияние на итоги всей деятельности.
Практические рекомендации по A/B-тестированию
После такого вступления, описавшего преимущества применения A/B-тестирования, давайте перейдем к практическим аспектам и посмотрим, как качественно его организовать.
ПОДГОТОВИТЕЛЬНЫЙ ЭТАП
В этом разделе мы рассмотрим ряд аспектов, на которые следует обратить внимание в ходе подготовительного этапа. Первое и самое важное — сформулировать критерии, которыми вы будете руководствоваться. Затем мы рассмотрим так называемые А/А-тесты, которые важны для проверки аппарата эксперимента. Кроме того, их можно использовать для генерирования нескольких ложноположительных результатов, чтобы наглядно продемонстрировать руководителям и коллегам статистическую значимость и важность достаточно большой выборки. Далее мы детально изучим план A/B-теста (что мы тестируем, кто участники, какой анализ будет проводиться и так далее). Наконец, мы остановимся на важнейшем аспекте и фактически первом вопросе, который задают все новички: каким должен быть размер выборки?
Критерии эффективности
Рекомендация: четко сформулируйте критерии эффективности до начала тестирования.
Важно иметь четкое понимание своей цели и имеющихся средств. Зачем мы это делаем? Особенно важно до начала тестирования определить ключевые показатели, которые иногда называют критериями общей оценки. В чем будет заключаться успешный результат? Если вы этого не сделаете, у вас может появиться соблазн собрать как можно больше данных в ходе эксперимента, а на этапе анализа начать статистически тестировать всё и ухватиться за значимые результаты. Хуже того, может появиться мысль выборочно отразить в отчетах только положительные показатели и результаты. Такой подход лишь доставит вам неприятности и не принесет долгосрочной пользы компании.
А/А-тестирование
Рекомендация по проведению A/A тестов
Если А обозначает контрольную группу, то, как вы уже могли догадаться, A/A-тестирование представляет собой сравнение двух контрольных групп, все изначальные условия для которых одинаковые. Какой в этом смысл? На самом деле есть целый ряд преимуществ.
Во-первых, вы можете применять его для тестирования и мониторинга вашей инфраструктуры и процессов распределения. Если вы зададите настройки системы для разделения трафика 50/50, но размер выборок в двух группах будет сильно отличаться, это означает, что с вашим процессом распределения что-то не так.
Во-вторых, если при сопоставимом размере двух выборок наблюдаются сильно отличающиеся показатели деятельности, это свидетельствует о проблеме с отслеживанием событий, проблеме при проведении анализа или составлении отчетности. При этом можно ожидать уровень различий при А/А-тестировании около 5 %, сделав допущение, что вы придерживаетесь стандартного статистического уровня значимости 5 %. Что действительно нужно отслеживать при многократном проведении A/A-тестов, так это наблюдаются ли у вас значительные расхождения, на порядок больше, чем стандартный уровень значимости. Если да, это может свидетельствовать о проблеме. Однако Георгий Георгиев резонно отмечает: «Даже если вам требуется всего 500 или 100 A/A-тестов, чтобы заметить статистически значимые отклонения от ожидаемых результатов, это все равно огромная потеря денег. Просто потому, что впечатления, клики, посетители — это все не бесплатно, не говоря уже о том, как вы могли бы использовать этот трафик»[132]. Нужно проводить множество A/B-тестов и постоянно внедрять инновационные решения. Однако, если у вас нет постоянного потока A/B-тестов или возник перерыв, проводите A/A-тесты.
В-третьих, результаты тестирования можно использовать для оценки вариативности тех показателей, которые вы контролируете. В некоторых вычислениях размера выборки, таких как при тестировании среднего значения (скажем, средний размер корзины или время, проведенное на сайте), это значение понадобится для вычисления размера выборки.
Наконец, в блоге Nelio A/B Testing отмечается, что применение A/A-тестов имеет, помимо прочего, и образовательную функцию[133]. Для тех компаний, где конечные пользователи или руководители никогда раньше не имели дела с A/В-тестированием и не особо подкованы в вопросах вероятности и теории статистики, это будет весьма полезно. Не стоит торопить события и сразу переходить к A/B-тестированию, полагая, что тестируемые показатели должны быть лучше контрольных, даже когда результаты впечатляют. Статистически значимый результат может быть делом случая, и самое наглядное доказательство этого — A/A-тестирование.
Планирование A/В-теста
Рекомендация: продумайте весь ход эксперимента до его начала.
При планировании теста следует обратить внимание на многие аспекты. Тем компаниям, которые намерены внедрить у себя культуру A/В-тестирования, я рекомендовал бы заранее продумать приведенный ниже спектр вопросов. После того как вы запустите тестирование, обсуждать критерии эффективности будет поздно. Вряд ли вы захотите, чтобы кто-то подтасовывал результаты во время анализа. Этап обсуждения и всех согласований должен предшествовать этапу самого тестирования.
Цель
• В чем цель этого теста?
Зоны ответственности
• Кто представитель от бизнеса?
• Кто отвечает за реализацию тестов?
• Кто осуществляет бизнес-аналитику?
Планирование эксперимента
• Какие показатели вы планируете тестировать, а какие будут являться контрольными?
• Кто составит вашу тестовую и контрольную группы (то есть люди)?
• Каковы ваша нулевая и альтернативная гипотезы?[134]
• Какие показатели вы планируете отслеживать?
• Когда будут обсуждаться результаты и формироваться обратная связь?
• Когда начнется тестирование?
• Требуется ли время для «разогрева»? В таком случае, с какого момента пойдет отсчет эксперимента для аналитических целей?
• Сколько продлится тест?
• Как определили размер выборки?
Процесс анализа
• Кто будет проводить анализ? (В идеале должно быть разделение между теми, кто планирует эксперимент, и теми, кто оценивает результаты.)
• Какой вид анализа будет проводиться?
• Когда начнется процесс анализа?
• Когда он завершится?
• Какое программное обеспечение будет использоваться для его проведения?
Результаты
• Как будут распространяться результаты анализа?
• Как будет приниматься окончательное решение?
Список кажется довольно длинным, но по мере того как вы будете проводить все больше и больше тестов, некоторые из вопросов и ответов перейдут в разряд стандартных. Например, ответы могут быть: «При проведении анализа мы всегда используем R» или «Проведение статистического анализа входит в обязанности Сары». Этот набор вопросов станет постепенно внедряться в корпоративную культуру, процесс будет становиться все более автоматическим, пока наконец он не станет естественным и привычным.
По получившемуся у меня описанию процедура проведения эксперимента и процесс анализа — очень четкие, почти клинические и доведенные до автоматизма: тест А против теста В, какой тест выигрывает, тот и внедряется на практике. Если бы так и было, то это был бы полный процесс управления на основе данных. Но реальный мир гораздо сложнее. В игру вступают другие факторы. Во-первых, результаты не всегда четко определены. Возможна двусмысленность. Не исключено, что показатель в тестовой группе был немного завышенным на протяжении всего теста, но незначительно. Или некоторые факторы компенсировали друг друга (например, объем продаж и уровень конверсии). Или, возможно, в процессе анализа вы обнаружили фактор, способный повлиять на объективность результатов. Все это может негативно сказаться на их анализе и интерпретации. Подобная двусмысленность вполне реальна. Во-вторых, отдельный эксперимент не обязательно отражает ту долгосрочную стратегию, которой следует компания. Пи Джей Маккормик приводит пример подобной ситуации на Amazon[135]. Он описывает A/B-тест, в котором в качестве контрольного элемента выступало крошечное изображение покупаемого продукта, настолько маленькое, что его было невозможно рассмотреть. В качестве тестируемого элемента было более крупное изображение продукта. Казалось бы, результат теста очевиден. Но не все так просто: маленькое изображение, по которому даже не было понятно, на что кликает пользователь, победило! Тем не менее в компании приняли решение перейти на размер изображения крупнее. Почему?
«Мы запустили более крупные изображения, потому что так пользователи видят, что они покупают. Это более положительный опыт. Кроме того, это совпадает с тем, к чему мы стремимся в долгосрочной перспективе, и с нашим видением. Данные не мыслят в долгосрочной перспективе за вас. Они не принимают решения. Они лишь дают информацию — пищу для размышлений. Но если вы принимаете решения автоматически, не задумываясь о том, что означают эти данные, и не соотнося их с вашим долгосрочным видением относительно вашего продукта или пользователей, то, скорее всего, ваши решения будут ошибочными»[136].
(Процесс принятия решений будет темой следующей главы.)
Размер выборки
Рекомендация: используйте калькулятор размера выборки.
Вопрос, который мне чаще всего задают относительно A/B-тестирования: «Как долго нужно проводить тестирование?» Обычно я отвечаю: «Я не знаю, нужно подсчитать с помощью калькулятора размера выборки».

Этот раздел более технический по сравнению с остальными, а потому те, кого статистика приводит в ужас, могут просто его пропустить. Основной вывод в том, что вам необходимо рассчитать минимальный размер выборки с помощью простого статистического онлайн-инструмента и придерживаться этого размера. Нельзя досрочно прекратить тестирование и рассчитывать на значимые результаты.
Причина, по которой непросто дать ответ на этот вопрос, заключается в том, что существует множество факторов, которые мы пытаемся оптимизировать.
Предположим, мы проводим стандартный A/B-тест. Есть четыре возможных сценария. Между сравниваемыми показателями не наблюдается различия, тогда:
1) мы приходим к верному заключению, что различия нет;
2) мы приходим к ошибочному заключению, что различия нет; это ложноположительный результат.
Или между сравниваемыми показателями наблюдается различие, тогда:
3) мы приходим к ошибочному заключению, что различия нет; это ложноотрицательный результат;
4) мы приходим к верному заключению, что различие есть.
Вышесказанное можно суммировать следующим образом.

Наша цель — попытаться оптимизировать вероятность верного заключения (1 или 4) и минимизировать вероятность сделать ложноположительное (2) или ложноотрицательное (3) заключение.
Для этого в нашем распоряжении два рычага, которыми мы можем воспользоваться.
Первый — более очевидный размер выборки. Если бы вы проводили опросы избирателей на президентских выборах, то были бы более уверены в своем прогнозе, если бы опросили 500 тыс. проголосовавших, а не 5 тыс. Это верно и относительно A/B-тестирования. Более значительная выборка повышает вашу статистическую мощность (статистический термин) при определении статистически достоверного различия, если это различие действительно существует. Возвращаясь к нашему примеру с четырьмя возможностями, если различие есть, то более крупная выборка снижает вероятность ложноотрицательного заключения (то есть более вероятно сделать вывод 4, чем 3). Обычно используется мощность 0,8. Это означает, что при существовании различия мы сможем определить его с вероятностью 80 %. Запомните это, мы вернемся к этому чуть позже.
Второй рычаг в нашем распоряжении — это статистический уровень значимости, обычно составляющий 5 %[137]. (Для масштабной выборки хороший подход — выбрать p ≤ 10–4.) Это означает приемлемую вероятность сделать ложноположительное заключение, если на самом деле различия между сравниваемыми показателями нет. Предположим, у нас есть обычная монета. Мы подбросили ее десять раз, и десять раз выпал орел. Кажется, сюда закралась погрешность в пользу орла. Но самая обычная монета все же могла бы упасть орлом вверх десять раз подряд, но только один раз из 1024 раз, или примерно 0,1 % от всех случаев. Если мы предположим, что монета с погрешностью, то рискуем ошибиться в 0,1 % случаев. Это кажется приемлемым риском. Далее, предположим, мы решаем, что если мы увидим восемь, девять или десять орлов или, наоборот, ноль, один или два орла, то сделаем вывод, что монета с погрешностью. При этом есть вероятность ошибиться уже в 11 % случаев. Это кажется слишком рискованным. Суть в том, чтобы сбалансировать убедительность доказательства, что тестируемое качество действительно оказывает влияние, против вероятности, что мы наблюдаем лишь случайный эффект (а фактического различия нет).
Итак, вооружившись критерием статистической мощности = 0,8 и уровнем статистической значимости = 5 %, переходим к калькулятору размера выборки (рис. 8.3). Вводим два этих значения (см. нижнюю часть рисунка), но кроме этого нужно предоставить дополнительную информацию. Этот тип калькулятора (оптимизированный для определения конверсии, то есть контроля перехода на сайт) запрашивает базовый показатель коэффициента конверсии. Это значит текущий коэффициент в вашей контрольной группе. Он также запрашивает значение минимального заметного эффекта. Это означает, что при существовании значительного различия, например 7 %, вы сможете определить его сразу же и обойтись при этом небольшим размером выборки. Если требуется определить менее значительное различие, например 1 %, потребуется выборка более крупного размера, чтобы убедиться, что различие действительно существует и оно не случайно. При коэффициенте конверсии 10 % и различии 1 % вам потребуется выборка из 28 616 человек: 14 313 составят контрольную группу и столько же — тестовую.
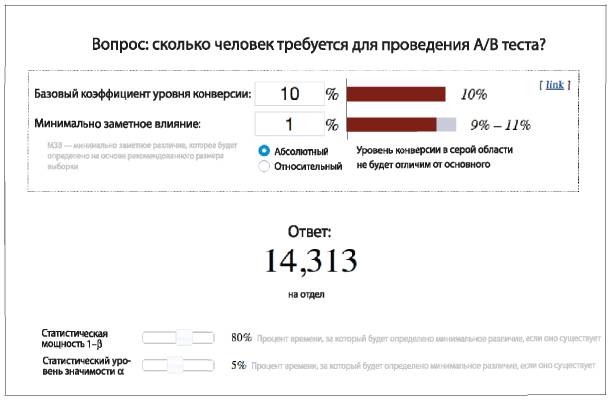
Рис. 8.3. Калькулятор размера выборки для определения конверсии
Источник: http://www.evanmiller.org/ab-testing/sample-size.html
Есть разные калькуляторы размера выборки, подходящие для разных ситуаций. Например, для сравнения средних значений, скажем, среднего размера корзины в контрольной группе и тестовой группе, калькулятор размера выборки будет похожим, но требования по вводимой информации станут слегка отличаться, например базовым показателем вариативности[138].
Оценить, сколько дней нужно на проведение эксперимента, можно путем деления среднего дневного трафика на общий размер выборки.
Обратите внимание, что это минимальный размер выборки. Предположим, исходя из размера выборки и уровня посещаемости вашего сайта, вам рекомендуется проводить тестирование в течение четырех дней. Если в эти дни уровень посещаемости сайта был ниже обычного среднего показателя, следует продолжить эксперимент, пока вы не достигнете минимального размера выборки. Если вы не продлите эксперимент или слишком рано его завершите, результаты будут необъективными. В итоге у вас повысится вероятность получить ложноотрицательное заключение: вы не сможете определить различие, которое существует. Более того, если наблюдается положительный результат, повышается вероятность того, что он не отражает действительность (см. Most Winning A/B Test Results Are Illusory[139]). Это чрезвычайно важный эффект. Вы видите положительное влияние, празднуете свою победу, запускаете тестируемую характеристику в массовое производство, а затем не наблюдаете никакого роста. Итог — напрасно потраченные время и силы, а кроме того, утрата доверия.
Итак, мы определили размер выборки и продолжительность тестирования. Или не совсем? Если вы проводите тестирование в течение четырех дней с понедельника по четверг, получите ли вы те же самые демографические и поведенческие характеристики пользователей, которые получили бы, проводи вы тестирование с пятницы по понедельник? В большинстве случаев они будут различаться. Это «эффект дня недели» в действии: пользователи, посещающие сайт в выходные, и их поведение отличаются от тех, что посещают сайт в другие дни. Таким образом, если согласно калькулятору размера выборки тестирование рекомендуется проводить в течение четырех дней, лучше продлите его еще на три дня, чтобы охватить неделю полностью. Если рекомендуемая продолжительность тестирования — 25 дней, проводите его в течение четырех недель.
Как видите, определение размера выборки — важный аспект. Если вы захотите обойтись выборкой меньшего размера, чем необходимо, то, скорее всего, получите ложные результаты: они будут указывать на наличие положительного эффекта, но не смогут генерировать дополнительную прибыль. Или, наоборот, вам не удастся определить наличие эффекта от тестируемой характеристики и вы столкнетесь с упущенной выгодой. Очевидно, оба этих варианта развития ситуации нежелательны. Наконец, расчеты размера выборки иногда бывают сложными, и для качественной оценки без калькулятора не обойтись. Воспользуйтесь имеющимися у вас инструментами.
ПРОВЕДЕНИЕ ТЕСТИРОВАНИЯ
После того как вы определили тестируемую характеристику и настроили на сайте инструменты для сбора необходимых данных, переходим к следующим вопросам: кто будет участвовать в тестировании, когда оно начнется и когда завершится?