
Относительные или абсолютные показатели








Очень важное решение — относительные или абсолютные показатели следует применять. Этот выбор определяет разработку показателей, которые при одном сценарии показывают очень разные картины.
Представьте, что в какой-то компании ведется классификация клиентов и 25 % от общего количества относятся к категории VIP (например, они приобрели продукцию компании на сумму больше 1 тыс. долл.). Через полгода у этой компании только 17 % VIP-клиентов. Черт, что случилось? Они что, ушли? Как все исправить?
Предположим, что в этот период усилия компании были сосредоточены на привлечении новых клиентов. Тогда, вероятно, общее количество клиентов увеличилось (показано оранжевым на рис. 6.2), а количество VIP-клиентов могло остаться тем же, при этом их пропорция уменьшилась. Фактически вполне возможно даже, что количество VIP-клиентов тоже увеличилось, но при этом пропорция стала ниже.
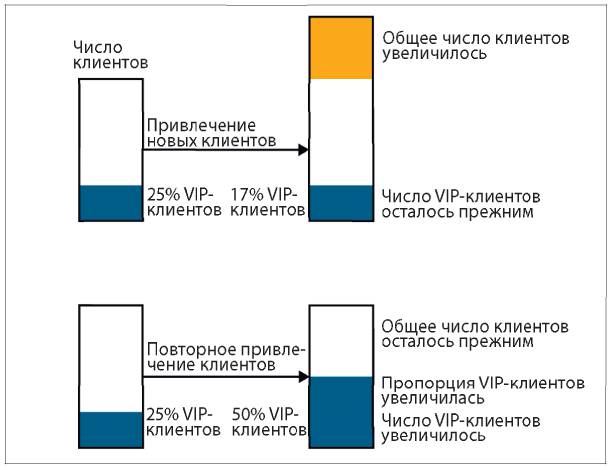
Рис. 6.2. У компании 25 % VIP-клиентов. В верхнем сценарии компания сосредоточила усилия на привлечении новых клиентов (показано оранжевым). Это привело к увеличению общего количества клиентов, количество VIP-клиентов осталось прежним, но пропорция уменьшилась. В нижнем сценарии компания сосредоточила усилия на работе с текущими клиентами. Пропорция и количество VIP-клиентов стали выше, но общего увеличения клиентской базы не произошло
И наоборот, предположим, что через полгода мы наблюдаем значительное увеличение количества VIP-клиентов и их пропорции. Это может отражать здоровый рост клиентской базы, но, с другой стороны, роста клиентской базы может и не быть, если усилия компании были сосредоточены исключительно на возвращении покупателей и увеличении количества повторных покупок (рис. 6.2, внизу). (Для многих компаний второй сценарий с увеличением количества повторных покупок более предпочтителен по сравнению с увеличением клиентской базы, так как стоимость привлечения новых клиентов, как правило, слишком высока.)
Как видите, выбор между применением абсолютных (количество VIP-клиентов) или относительных (их пропорция) показателей может привести к очень разным интерпретациям.
Вывод: тщательно взвесьте, что вы хотите узнать, и выберите абсолютный или относительный показатель, который будет адекватно отображать нужные вам изменения.
РОБАСТНОСТЬ
Определяйте статистически робастные[93] показатели, то есть те, что относительно нечувствительны к отдельным резко отличающимся значениям.
Рассмотрим следующий пример из San Francisco Chronicle:
Средняя заработная плата специалистов технического профиля в центральной части полуострова Сан-Франциско (округ Сан-Матео) в прошлом году составила 291 497 долл. Возможное объяснение отклонения: глава компании Facebook Марк Цукерберг получил всего один доллар в качестве зарплаты, но заработал 3,3 млрд долл. на опционах на покупку акций в 2013 году. Если вычесть 3,3 млрд долл. из общей суммы, то среднее значение получится примерно 210 тыс. долл.[94]
Использовать среднее значение в данном случае не следует, учитывая высокую степень позитивной асимметрии в данных по заработной плате. Среднее значение получается существенно завышенным (более чем на 35 %) из-за одной резко отличающейся переменной. В данном случае гораздо рациональнее выбрать показатель медианы, так как он более устойчив к резко отличающимся значениям и лучше отражает средние данные.
Стоит отметить, что в некоторых случаях могут понадобиться показатели, которые особенно чувствительны к пограничным значениям. Пиковая нагрузка на веб-сайт должна охватывать редкие максимальные значения, которые должны быть включены в диапазон. Оценить или визуализировать робастность можно с помощью повторной выборки. Возьмите набор данных и вычислите показатель. Повторите расчеты несколько раз, заменяя набор данных; получив ряд значений показателя, составьте их распределение. Насколько это распределение отличается от того, что вы ожидали или хотели бы увидеть?
Вывод: примените разведочный анализ (например, постройте гистограмму или диаграмму рассеяния), чтобы лучше понять данные, и на его основании выберите робастные показатели.
ПРЯМАЯ СВЯЗЬ
Постарайтесь выбирать показатели, которые непосредственно измеряют интересующий вас процесс. К сожалению, не все можно измерить и оценить количественно, поэтому иногда приходится довольствоваться косвенными или приближенными показателями.
Кэти О’Нейл привела наглядный пример, как результаты тестов учеников приблизительно отражают качество обучения[95]. Чем больше расстояние между самим процессом и приближенным показателем, тем менее достоверным и полезным будет его значение. В результате вы можете начать оптимизировать приближенный показатель, что может оказаться совсем не тем, что вы действительно хотите оптимизировать.
Сьюзан Веббер рассказала о тестировании вкусов кока-колы и о выпуске на рынок нью-кок в 1980 году[96]. Компания провела маркетинговые исследования, которые показали в высшей степени положительные результаты, даже по сравнению с традиционной кока-колой. Однако когда новый продукт вывели на рынок, его продажи провалились. Почему?
Покупатели сочли напиток слишком сладким. Дело в том, что при тестировании вкуса в ходе маркетинговых исследований участники фокус-группы пробовали напиток маленькими глотками, в результате чего степень его сладости не так раздражала. Если бы они пробовали напиток «как в жизни» (сделали бы большой глоток жарким днем), то оптимизировали бы свое восприятие в соответствии с действительностью.
Вывод: везде, где возможно, оснащайте свои процессы и системы контрольно-измерительными средствами и старайтесь максимально избегать приближенных показателей. Не всегда стоит идти по пути наименьшего сопротивления и использовать данные, оказавшиеся под рукой. Сконцентрируйтесь на данных, которые вам следовало бы собрать и использовать, если они в большей степени отвечают вашим потребностям.