
1 Компьютерные словари и системы компьютерного перевода








Отчет по практическому занятию
Тема: Сканирование «бумажного» и распознавание электронного текстового документа. Возможности систем распознавания текстов
Дата:
Цель: освоить процессы сканрирования доументов и перевода из формата к формату.
Выполнил: ФИО
Группа: 13, 14.
Специальность: ИС и П
Преподаватель: Жиров Д.С.
Теоретическая часть
1 Компьютерные словари и системы компьютерного перевода
Словари широко используются для перевода текстов с одного языка на другой. Первые словари были созданы около 5 тысяч лет назад в Шумере. Это были глиняные таблички, разделённые на две части: в первой записывалось слово на шумерском языке, во второй — аналогичное по значению слово на другом языке, иногда с краткими пояснениями.
Современные словари строятся по этому же принципу. Сегодня существуют тысячи словарей для перевода между сотнями языков (русско-немецкий, англо-испанский и т.д.), причём каждый из них может содержать десятки тысяч слов. В печатном варианте словарь – это толстая книга объёмом в сотни страниц, где поиск необходимого слова — очень трудоёмкий процесс.
Компьютерные словари могут содержать переводы на разные языки сотен тысяч слов и словосочетаний, а также дают пользователю возможность дополнительные возможности:
– многоязычность: существуют компьютерные словари, которые дают пользователю возможность выбрать языки и направление перевода (например, русско-французский, немецко-русский и т. д.);
– наличие специализированных словарей по различным областям знаний (юриспруденция, информационные технологии, медицина и др.);
– наличие «быстрого набора»: в процессе набора слова появляется список похожих слов;
– доступ к наиболее часто используемым словам с помощью закладок;
– возможность ввода словосочетаний;
– мультимедийность: наличие возможности прослушивания слов в исполнении дикторов, носителей языка;
– онлайн-доступ компьютерные словари в Интернете обеспечивают выбор тематического словаря и направления перевода.
В условиях глобализации использование традиционной технологии перевода вручную тормозит развитие контактов между людьми, находящимися в разных странах и говорящими на разных языках.
Современные системы компьютерного перевода дают возможность переводить многостраничные документы с высокой скоростью (одна страница в секунду) и способны переводить web-страницы в режиме реального времени.
Системы компьютерного перевода производят перевод текстов на основе формального «знания» языка: его синтаксиса (правил построения предложений), законов словообразования и использовании словарей. Программа-переводчик вначале делает анализ текста на одном языке, а после конструирует данный текст на другом языке.
Онлайновые компьютерные переводчики позволяют:
– выбор тематического словаря;
– выбор направления перевода;
– перевода любого текста, набранного в окне перевода или скопированного из буфера обмена;
– перевода целых web-страниц, включая гиперссылки и с сохранением исходного форматирования;
– перевод электронных писем.
Современное программное обеспечение даёт возможность перевода технической документации, деловой переписки и других специализированных текстов с допустимым качеством. Но, разумеется, полностью на такие системы полагаться нельзя. Они могут допускать семантические (смысловые) и стилистические ошибки, а также мало применимы для перевода художественных произведений, поскольку неспособны корректно переводить аллегории, гиперболы, метафоры и другие элементы художественного стиля.
2. Системы оптического распознавания символов
Оптическое распознавание символов[1] – это технология, которая позволяет преобразовывать различные типы документов – отсканированные документы, PDF-файлы или фото с цифровой камеры – в редактируемые форматы с возможностью поиска.
Если имеется документ в бумажном формате (статья в журнале, брошюра или договор в формате PDF, присланный партнёром по e-mail), то для получения возможности редактирования такого документа, его недостаточно просто отсканировать.
Сканированием легко можно получить изображение страницы текста в графическом файле. Но для того, чтобы получить документ в формате текстового файла, надо провести распознавание текста: преобразовать элементы графического изображения в последовательности текстовых символов.
Для этого потребуется программа для распознавания символов, которая сможет выделить в изображении буквы, составить их в слова, а затем объединить слова в предложения, что в дальнейшем позволит работать с содержимым исходного документа.
Текст, преобразованный из графической в символьную (текстовую) форму, можно далее обрабатывать любыми текстовыми редакторами. Системы оптического распознавания символов экспортируют результаты распознавания в популярные офисные приложения (Microsoft Office, OpenOffice и др.), причём распознанный текст можно сохранить в различных текстовых форматах: DOCX, DOC, ODT, RTF, TXT, HTML и др.
Процесс распознавания
Сначала программа распознавания проводит постраничный анализ изображений, из которых состоит документ: определяет структуру страниц, выделяет текстовые блоки, таблицы. Кроме того, в современных документах зачастую содержатся различные элементы дизайна: фоновые изображения, колонтитулы, иллюстрации и т.п. Поэтому системе важно с самого начала определить, как устроен исходный документ: есть ли в нём разделы и подразделы, оглавление, нумерация страниц, ссылки и сноски, таблицы и графики и т.д.
После этого в текстовых блоках выделяются отдельные строки, которые делятся на слова, а слова – на символы.
В зависимости от качества документа используется два метода распознавания.
При типографском качестве исходного документа (приемлемый размер шрифта, без плохо напечатанных символов или исправлений), то задача распознавания решается растровый метод:
1. растровое изображение страницы разделяется на изображения отдельных символов,
2. каждое из них последовательно накладывается на шаблоны символов, имеющихся в памяти программы,
3. выбирается шаблон с наименьшим количеством точек, не совпадающих с точками входного изображения.
При низком качестве исходного документа (например, факс или машинописный текст) используется структурный метод: распознавание символов по наличию в них определённых структурных элементов (отрезков, дуг, колец и точек). Каждый символ описывается набором параметров, которые определяют взаимное расположение его элементов. При распознавании в искажённом символьном изображении выделяются характерные детали и сравниваются со структурными шаблонами символов. В итоге будет выбран тот символ, для которого комбинация всех структурных элементов и их взаимное расположение (наличие пересечения линий, углы между ними, размеры дуг) более всего соответствуют распознаваемому символу.
Наиболее распространённые OCR-системы используют как растровый, так и структурный методы распознавания. При этом данные программы являются «самообучающимися»: для каждого конкретного документа они создают свой набор шаблонов символов. Поэтому скорость и качество распознавания многостраничных документов неизменно возрастают.
Системы оптического распознавания форм
При заполнении налоговых деклараций, проведении ЕГЭ и ОГЭ и т.п. используются различные бланки с полями, в которые печатными буквами от руки вводятся данные. Такие рукопечатные тексты распознаются с помощью систем оптического распознавания форм.
Сложность этого процесса состоит в необходимости «узнать» символы, написанные от руки, несмотря на возможные их отклонения, присущие почерку конкретного человека. Кроме этого, система должна понять, к какому полю относится распознаваемый текст: где указано имя плательщика, где – фамилия, а где – номер его банковского счёта и т.п.
Эта технология оптимизирует ввод тысяч бюллетеней и бланков и значительно экономит время их обработки.
Оптическое распознавание документов
Интеллектуальные системы оптического распознавания обеспечивают быстрое и точное преобразование в электронный вид печатных документов, цифровых фотографий документов и файлов в формате PDF. При распознавании полностью сохраняется оформление документа: иллюстрации, картинки, списки, таблицы и т. д. Полученные результаты можно редактировать в текстовых процессорах, сохранять в различных форматах, отправлять по e-mail и публиковать в Интернете.
Анализ и обработка документа целиком, а не постранично, позволяют распознать отдельные элементы его структуры (стили, шрифты, колонтитулы, сноски, гиперссылки, подписи к картинкам, таблицам и диаграммам и пр.). Таким образом, система оптического распознавания точно распознаёт и максимально полно сохраняет исходное оформление любого документа.
Оптическое распознавание изображений
OCR-системы взаимодействуют со всеми моделями сканеров. Однако для целей распознавания сейчас нет необходимости оснащать компьютер сканером. Современное программное обеспечение даёт возможность распознавать фотографии документов, сделанные цифровой камерой. Во многих случаях использование фотоаппарата или камеры смартфона намного удобнее (и быстрее) сканера для получения изображения.
Системы оптического распознавания символов работают с разнообразными форматами графических файлов: BMP, JPEG, TIFF, PNG и других.
Также данные программы обеспечивают предварительную обработку изображения для повышения качества распознавания и упрощения дальнейшей работы с документом. Современные OCR-системы могут:
– очистить изображение от «мусора»,
– устранить перекосы и искажения строк,
– инвертировать изображение,
– повернуть или зеркально отразить его,
– обрезать края или стереть часть изображения.
3. Системы распознавания рукописного текста
С появлением первых карманных компьютеров в 1990 году стали разрабатываться системы распознавания рукописного текста. Такие программы преобразуют текст, написанный на экране карманного компьютера специальной устройством – стилусом, в текстовый компьютерный документ.
Практическая часть
Задание 1. С помощью нескольких онлайновых компьютерных переводчиков перевести с русского языка на английский и итальянский языки какое-либо одно слово, например, «образование».
1. Запустить любой браузер и открыть в Интернете компьютерный переводчик Google
2. В левом текстовое поле ввести слово «образование». Направление перевода программа обычно определяет автоматически (в нашем случае с русского языка на английский).
3. В правом текстовом окне появится основной вариант перевода «education», под окном будут даны другие варианты (в данном случае – «formation»; «forming», «generation» и др. (рис. 1).
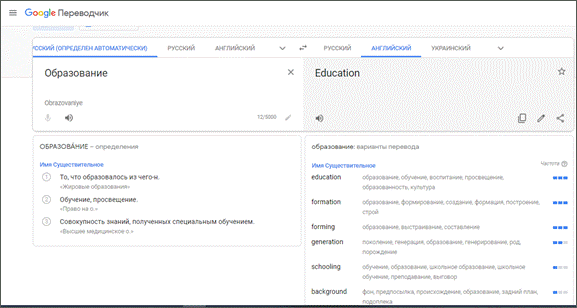
Рисунок 1 – Перевод с русского языка на английский
3. Сменить в правом текстовом окне язык с английского на итальянский, нажав соответствующую кнопку и выбрав из списка нужный язык (рис. 2).


Рисунок 1 – Кнопка выбора языка
4. В правом текстовом окне появится перевод исходного слова на итальянский язык (рис. 3).
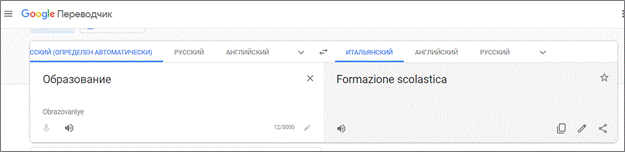
Рисунок 3 – Перевод с русского языка на итальянский
Те же действия провести с помощью онлайн-переводчиков Яндекс и Promt.
Задание 2. В Интернете с помощью нескольких онлайновых компьютерных переводчиков перевести с английского языка на русский язык целое предложение, например, «The teacher ’ s computer is placed on the table in the corner of the classroom».
1. Запустить любой браузер и открыть в Интернете компьютерный переводчик Google
2. В левом текстовое поле ввести предложение The teacher’s computer is placed on the table in the corner of the classroom.
Обычно онлайн-переводчик автоматически определяет язык, на котором написано предложение, и предполагает язык, на который необходимо осуществить перевод (в нашем случае – с английского на русский).
В правом текстовом поле появится перевод введённого предложения (рис.4).
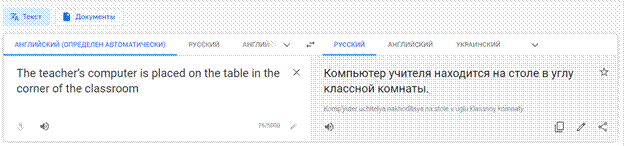
Рисунок 4 – Перевод с помощью онлайн-переводчика Google Переводчик
Если направление перевода (с какого языка на какой производится перевод) автоматически определилось некорректно, то выбираем языки вручную (рис. 5).


Рисунок 5 – Выбор языка перевода
Если есть необходимость, в переводчике можно прослушать, как звучит исходное или переведённое предложение (рис. 6).



Рисунок 6 – Кнопки прослушивания звучания
Те же действия провести с помощью онлайн-переводчиков Яндекс и Promt.
Задание 3. Отсканировать с помощью телефона и преобразовать в электронный текстовый документ, ваш конспект.
Сканирование бумажного и распознавание текстового документа с использованием ABBYY FineReader
1. Отсканировать конспект.
2. Запустить программу распознавания текста ABBYY FineReader.
3. Преобразовать графическое изображение в pdf и doc
Контрольные вопросы
1. Какими преимуществами обладают компьютерные словари по сравнению с традиционными бумажными словарями?
2. Какие документы целесообразно переводить с помощью систем компьютерного перевода?
3. В чём состоят различия в технологиях распознавания документов типографского качества и с низким качеством печати?
[1] англ. Optical Character Recognition – OCR