
4 Оценка качества данных и процедура очистки








4.1 Общие сведения
Предобработка данных комплекс методов и алгоритмов, которые применяются в аналитическом приложении целью подготовить данные к решению конкретной задачи и приведения их в соответствие с требованиями, определенных спецификой задачи и способами ее решения.
Очистка данных определяет:
- противоречивость – информация, несоответствующая законам и т.д.
- аномальные значения – значения, которые сильно выбиваются из общего ряда;
- пропуски – незаполненные поля;
- несоответствие форматов;
- ошибки ввода или опечатки;
- дублирование.
Графически необходимость проведения очистки данных приведена на рисунке 4.1.
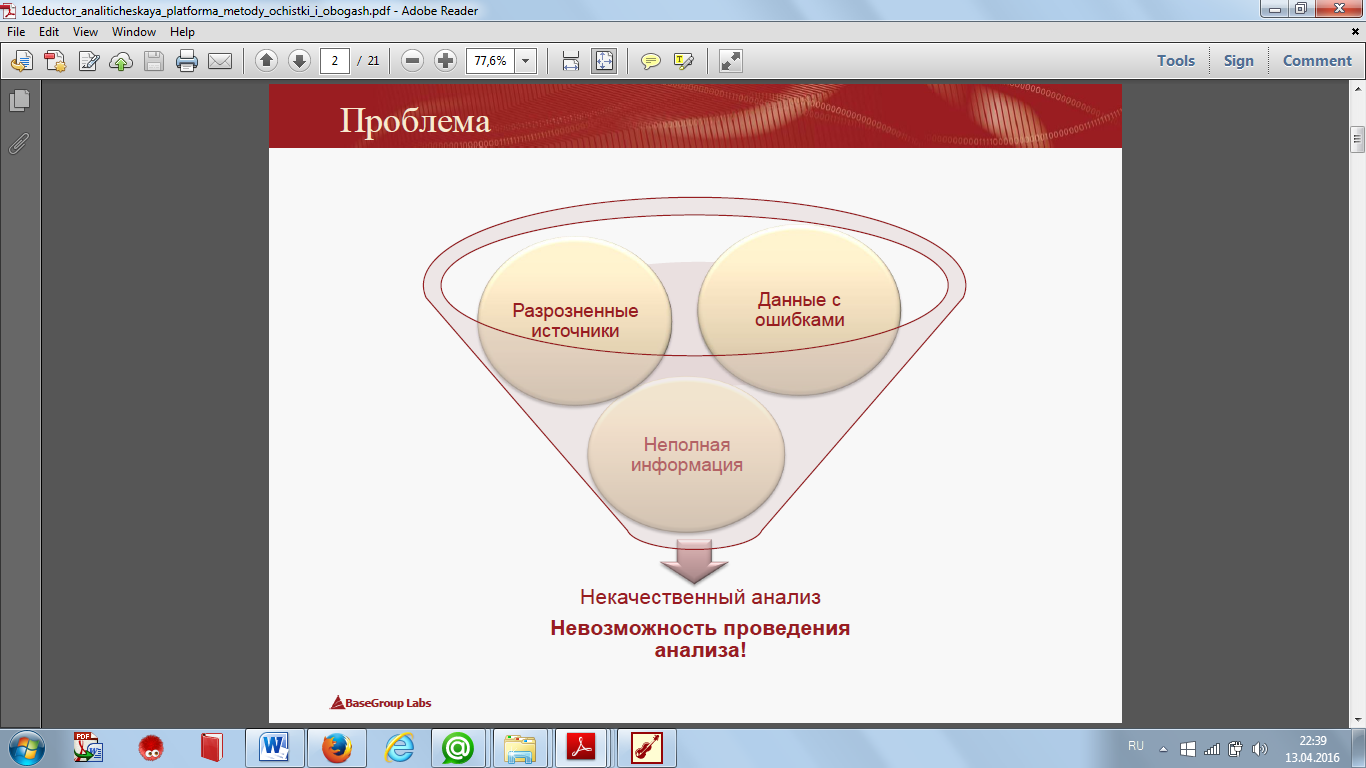
Рисунок 4.1 – Графическое представление необходимости проведения очистки данных
Этапы очистки данных включают:
- анализ данных;
- определение порядка и правил преобразования;
- подтверждение;
- преобразование;
- противоток очищенных данных.
Результаты очистки данных представлены на рисунке 4.2.

Рисунок 4.2 – Результаты очистки данных
4.2 Оценка качества данных
Одним из этапов очистки данных, предусмотренных ПАП «DEDUCTOR» является узел «Качество данных», предназначенный для проведения профайлинга и аудита данных с целью определения степени пригодности полей набора данных для решения задач анализа по объективным критериям: пропуски, выбросы, экстремальные значения. [3]
1 Шаг - для выполнения оценки качества данных на панели «Сценарии» нажимаем 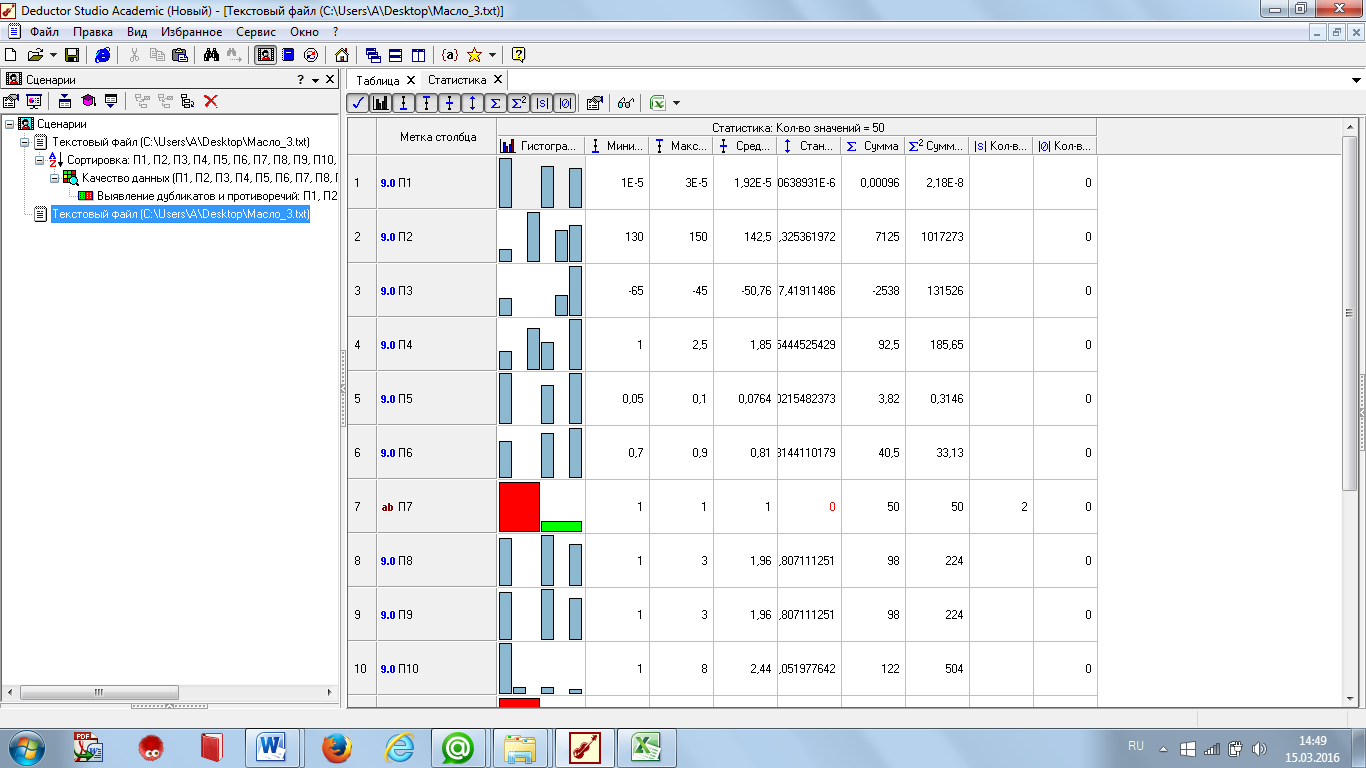 «Мастер обработки», предварительно в левой части окна выбрав необходимую для анализа базу данных. В появившемся окне выбираем обработчик «Качество данных» (рисунок 4.3).
«Мастер обработки», предварительно в левой части окна выбрав необходимую для анализа базу данных. В появившемся окне выбираем обработчик «Качество данных» (рисунок 4.3).
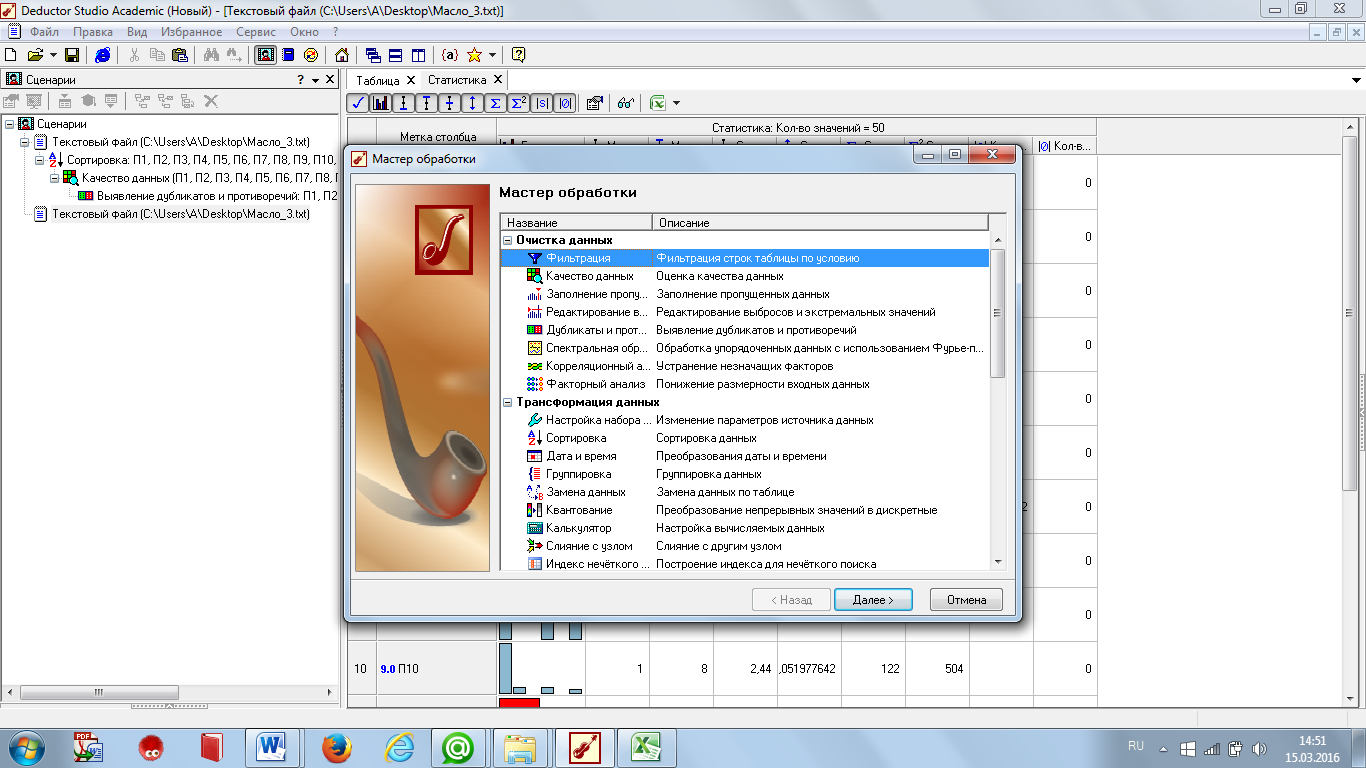
Рисунок 4.3 - Оценка качества данных (выбор обработчика)
2 Шаг –определяем параметры обработки: пропущенные данные, выбросы и экстремальные значения. Для этого в секции «Максимально допустимый процент пропусков» можем задать максимально допустимое число пропусков в процентах к общему числу записей набора данных, при превышении которого поле считается требующим предобработки с целью восстановления пропущенных значений [3], равное 0%, так как при анализе выполнения импорта было получено, что пропуски отсутствуют ( см. рисунок 3.9).
В этом же окне выбираем способ определения выбросов и экстремальных значений. Выбираем «Стандартное отклонение», для которого критерием является отклонение значения признака от среднего более, чем на заданное число стандартных отклонений. При этом данный параметр отдельно задается для выбросов и для экстремальных значений, что в дальнейшем позволяет обрабатывать эти типы аномальных значений по отдельности, используя различные методы [3]. Нужно помнить, что каждый количественный показатель имеет свои значения этих параметров, поэтому все последующие шаги будут приведены для показателя П2 (рисунок 4.4).
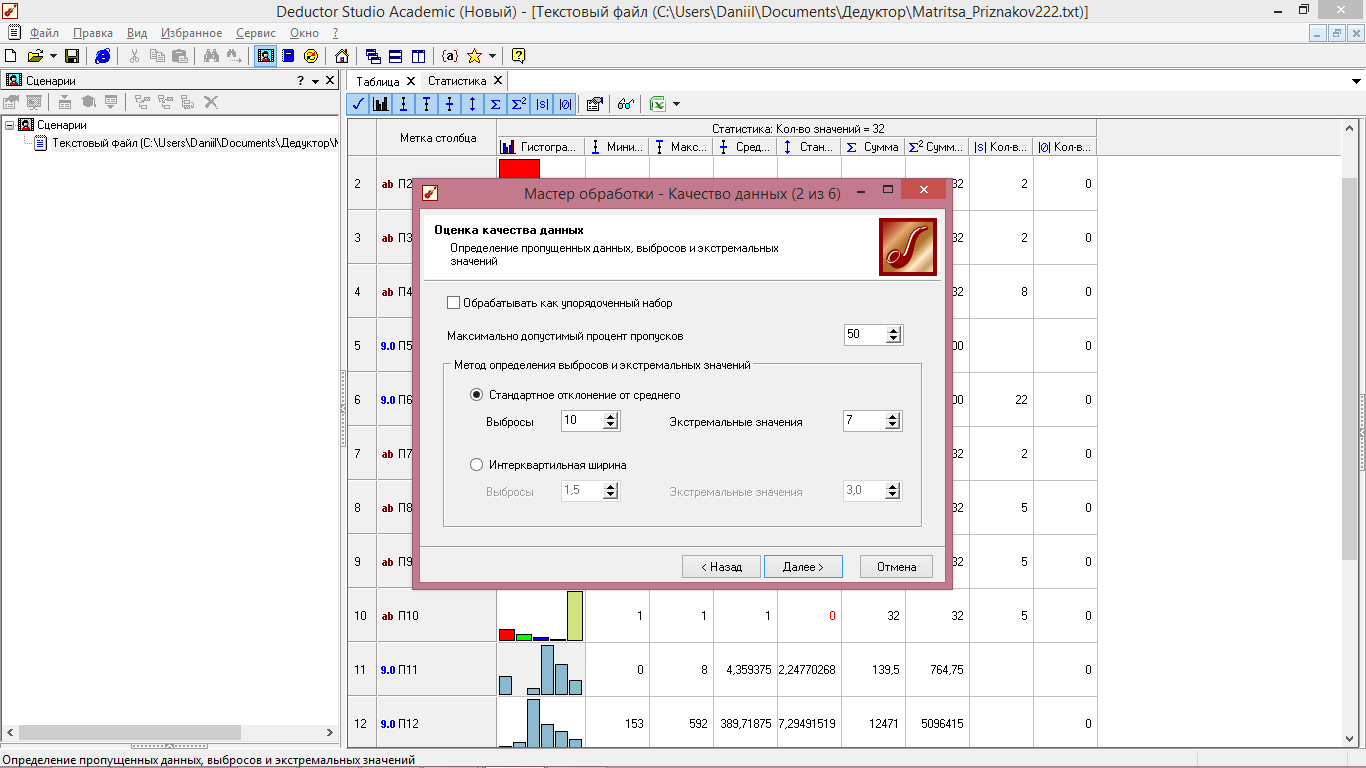
Рисунок 4.4 - Оценка качества данных
(определение пропущенных данных, выбросов и экстремальных значений)
3 Шаг - задаем используемые столбцы. Так как мы хотим определить качество показателя П2, поэтому в графе «Назначение» для столбца П2 ставим значение «Используемый», для остальных – «Неиспользуемый», нажимаем «Далее» (рисунок 4.5).
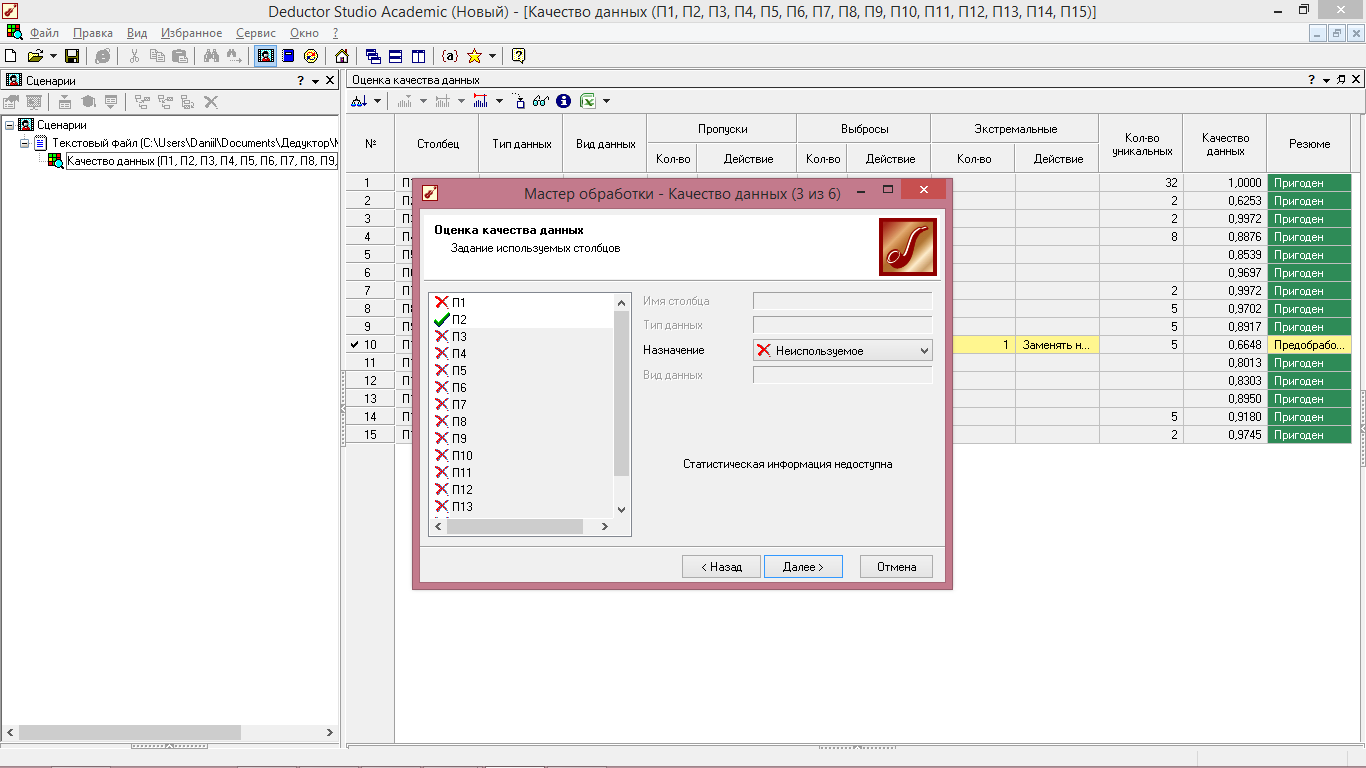
Рисунок 4.5 - Оценка качества данных (задание используемых столбцов)
4 Шаг - нажимаем «Пуск» и ждем, пока в графе «Название процесса» не отобразится «Успешное завершение», а в графе «Процент выполнения текущего процесса» - 100%, после чего нажимаем «Далее» (рисунок 4.6).
Рисунок 4.6 - Оценка качества данных (запуск процесса)
5 Шаг - выбираем способ отображения данных: для этого ставим галочки напротив «Таблица характеристик полей», нажимаем «Далее» (рисунок 4.7).
Рисунок 4.7 - Оценка качества данных (выбор способа отображения данных)
6 Шаг - заполняем графы «Имя» и «Метка», нажимаем «Готово»
(рисунок 4.8).
Рисунок 18 - Оценка качества данных (завершение процесса)
7 Шаг – результаты профайлинга и аудита данных, сделанные узлом «Качество данных» представляются в виде таблицы, в заголовке которой указываются свойства набора данных и другие параметры оценки качества (рисунок 19).
В графе «Пропуски» отображается количество имеющихся пропусков и действие, которое требуется выполнить при восстановлении пропусков.
В графе «Выбросы» представлено количество обнаруженных выбросов и действие, которое требуется выполнить при их обработке.
В графе «Экстремальные» указывается количество обнаруженных экстремальных значений и действие, которое требуется выполнить при их обработке.
Графа «Количество уникальных» содержит количество уникальных значений в данных.
В графе «Качество данных» указывается индекс качества данных.
Поле «Резюме» содержит заключение о том, являются ли данные пригодными для последующего анализа. Пригодным считается поле, которое не содержит пропусков, экстремальных значений и выбросов, непригодным – поле, индекс качества которого равен 0. Все остальные поля считаются требующими предобработки. [3]
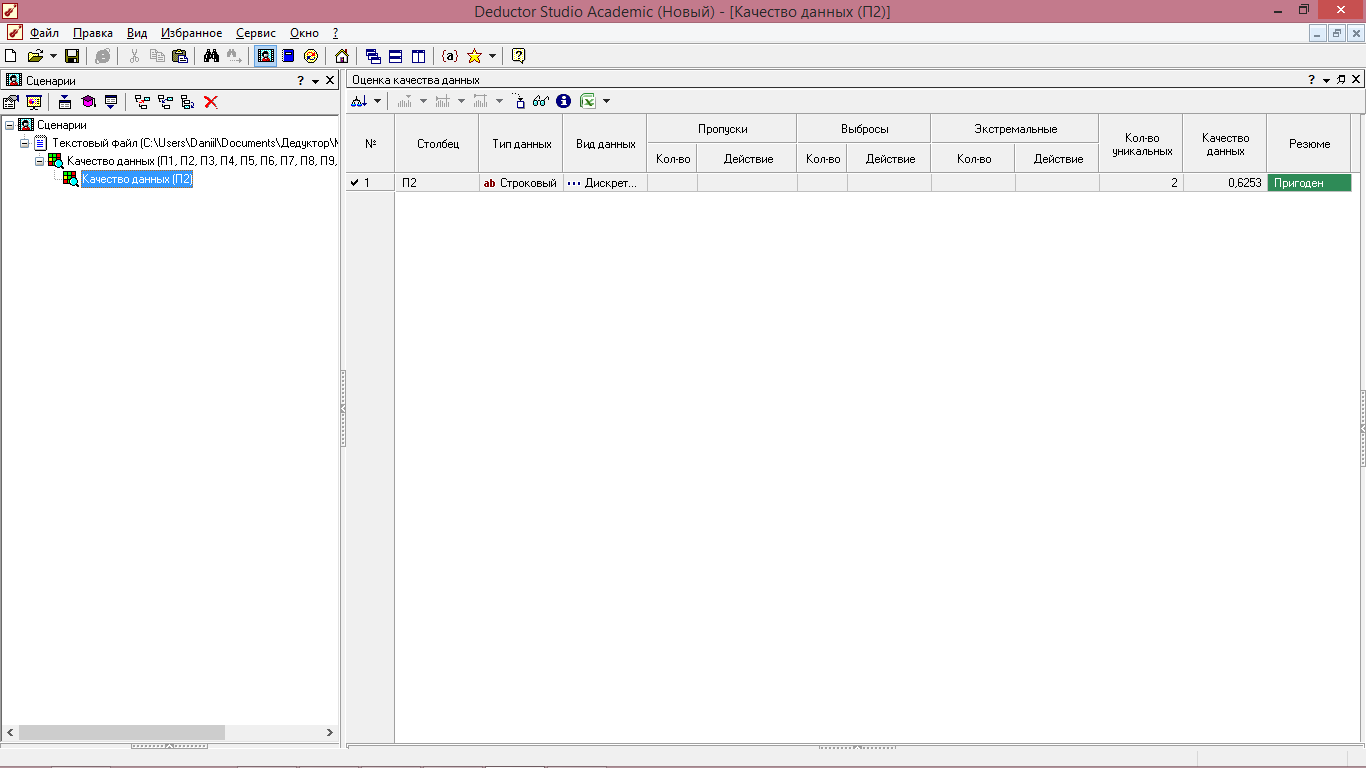
Рисунок 4.9 - Оценка качества данных
(определение качества данных и их пригодности к анализу)
Исходя из рисунка 4.9, делаем вывод, что данные показателя П2 (температура вспышки) не имеют пропусков, выбросов и экстремальных значений, индекс качества данных достаточно высок, следовательно, данные являются пригодными для анализа.
8 Шаг - аналогичным образом проводим оценку качества данных всех количественных показателей.
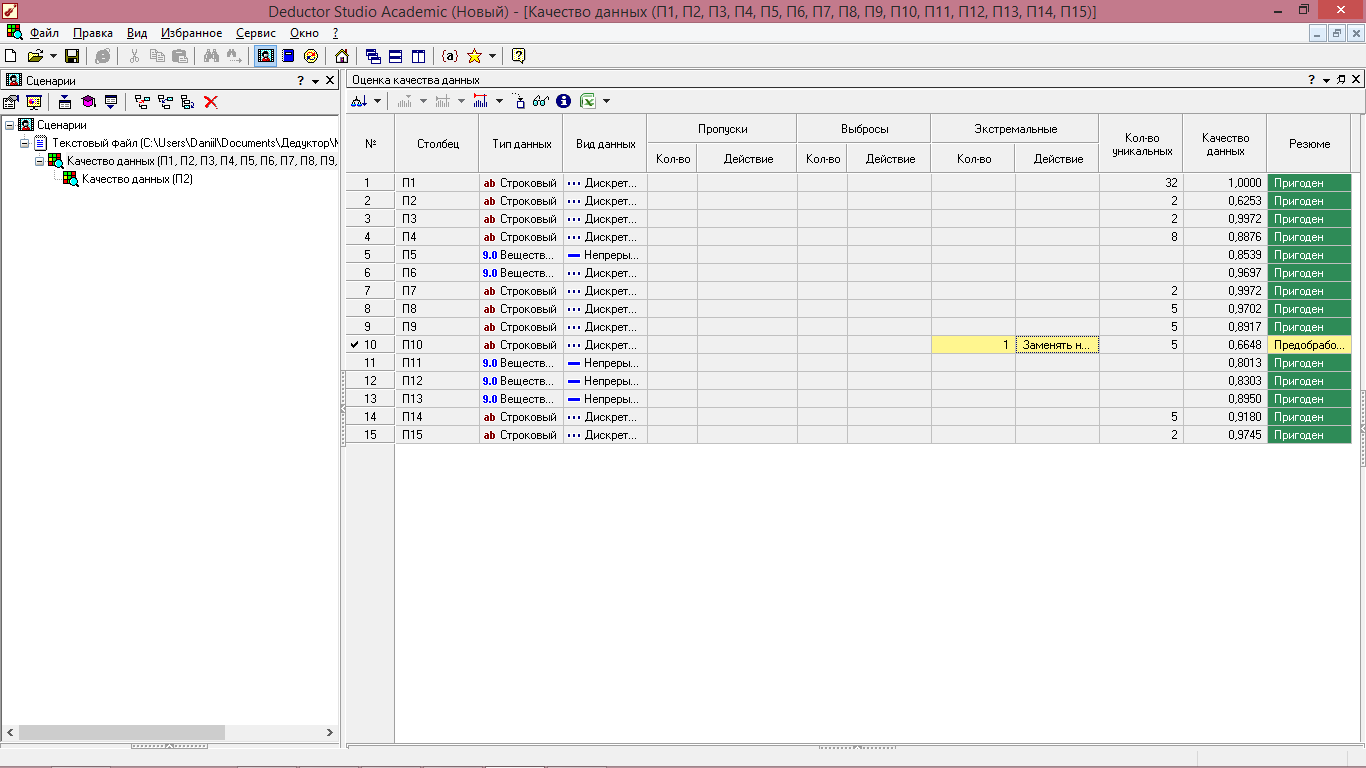
Рисунок 19 - Оценка качества данных
После проведения оценки качества данных для других количественных показателей получаем, что почти все параметры, кроме П10(Максимальный диаметр сверления (бетон - бур)) являются пригодными для анализа.
4.3 Выявление дубликатов и противоречий
Так как при оценке качества данных было выявлено, что у показателей отсутствуют выбросы, пропуски и экстремальные значения, поэтому не требуется выбирать обработчики «заполнение пропусков» и «редактирование выбросов». Однако, необходимо проверить данные на выявление возможных дубликатов и противоречий.
1 Шаг - для выявления дубликатов и противоречий необходимо на панели «Сценарии» нажимаем «Мастер обработки», предварительно в левой части окна выбрав необходимую для анализа базу данных. В появившемся окне выбираем соответствующий обработчик.
2 Шаг - в открывшемся окне для каждого показателя в графе «Назначение» выбираем «Входное» и нажимаем «Далее» (рисунок 4.10).
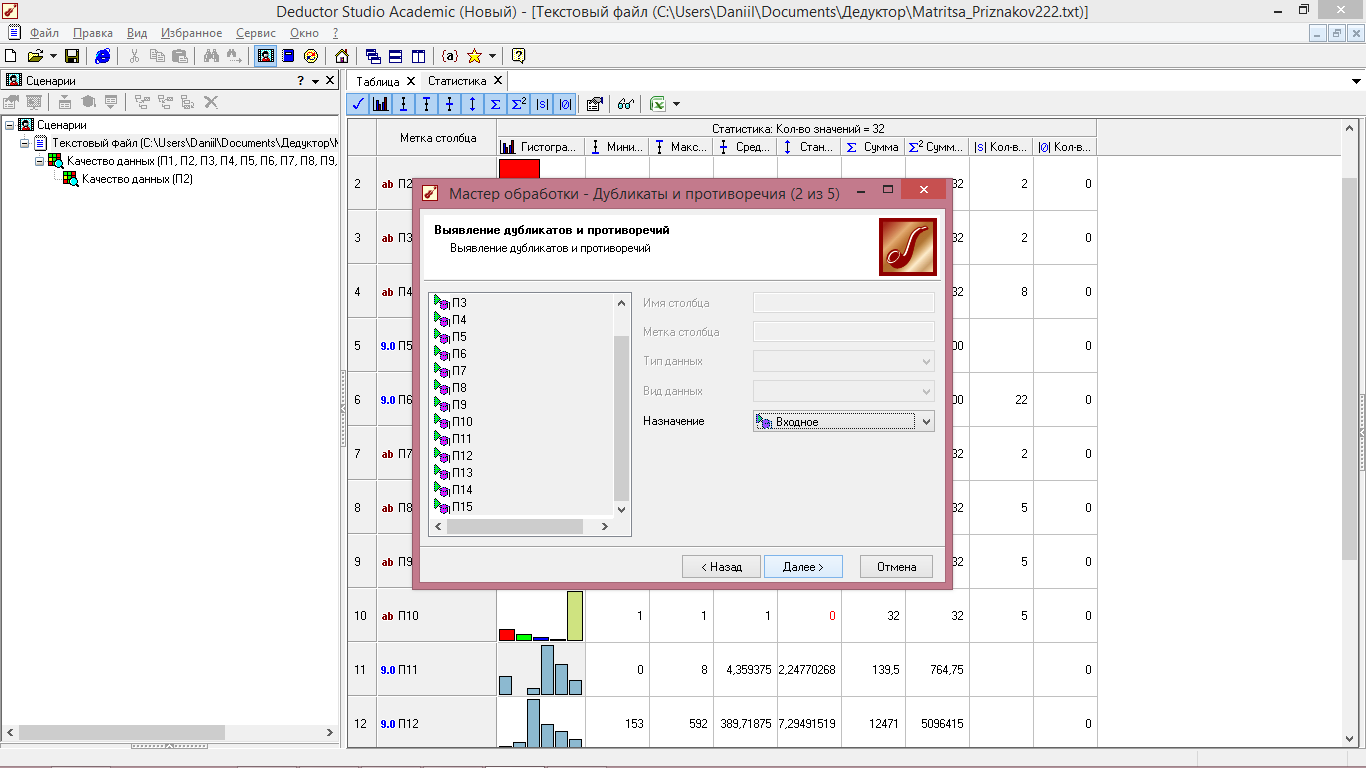
Рисунок 4.10 - Выявление дубликатов и противоречий
(назначение входных и выходных параметров)
3 Шаг - нажимаем «Пуск» и ждем, пока в графе «Название процесса» не отобразится «Успешное завершение», а в графе «Процент выполнения текущего процесса» - 100%, после чего нажимаем «Далее» (рисунок 4.11). 
Рисунок 4.11 - Выявление дубликатов и противоречий (запуск процесса)
4 Шаг - в следующем окне выбираем способ отображения данных: для этого ставим галочки напротив «Отображает в виде таблицы информацию о дубликатах и противоречиях», нажимаем «Далее» (рисунок 4.12). При завершении назначаем имя и метку, нажимаем «Готово».
Рисунок 4.12 - Выявление дубликатов и противоречий (выбор способа отображения данных)
В отрывшемся окне (рисунок 4.13) видим, что в результирующий набор добавлены два поля логического типа «Противоречие» и «Дубликат», где для каждой записи исходных полей указывается признак дубликата или противоречия.
Если бы записи содержали противоречие, то в поле «Противоречие» для нее было установлен флажок «True» (истина). Аналогично и для поля «Дубликат».
Кроме того, в набор были включены два столбца целого типа «Группа противоречий» и «Группа дубликатов», содержащие номер группы для противоречивых и дублирующихся записей соответственно. Для записей, не содержащих противоречий и дубликатов, эти поля отображаются пустыми. [3]
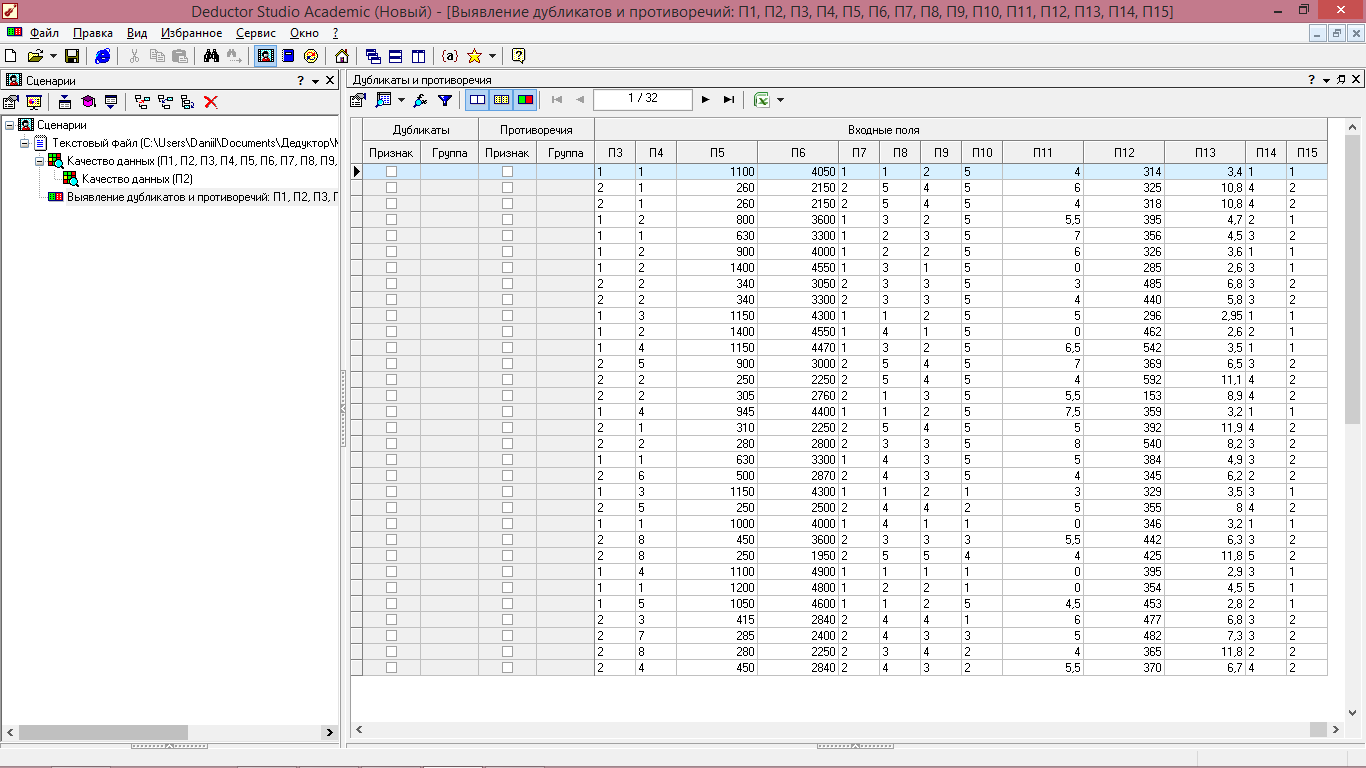
Рисунок 4.13 - Выявление дубликатов и противоречий
Так как добавленные ячейки остались пустыми, следовательно, данные не содержат дубликатов и противоречий.