
4. Повторять шаги с 1 до 3 до тех пор, пока сеть не будет обучена в достаточной степени.








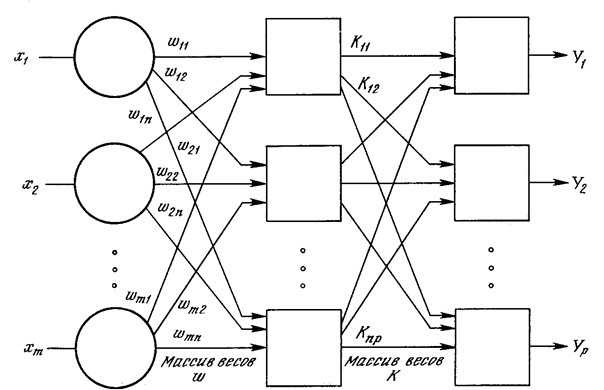
Рис. 5.1. Двухслойная сеть без обратных связей
Этот процесс стремится минимизировать целевую функцию, но может попасть, как в ловушку, в неудачное решение. На рис. 5.2 показано, как это может иметь место в системе с единственным весом. Допустим, что первоначально вес взят равным значению в точке А. Если случайные шаги по весу малы, то любые отклонения от точки А увеличивают целевую функцию и будут отвергнуты. Лучшее значение веса, принимаемое в точке В, никогда не будет найдено, и система будет поймана в ловушку локальным минимумом, вместо глобального минимума в точке В. Если же случайные коррекции веса очень велики, то как точка А, так и точка В будут часто посещаться, но то же самое будет иметь место и для каждой другой точки. Вес будет меняться так резко, что он никогда не установится в желаемом минимуме.
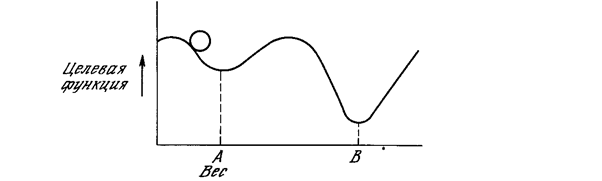
Рис.5.2. Проблема локальных минимумов.
Полезная стратегия для избежания подобных проблем состоит в больших начальных шагах и постепенном уменьшении размера среднего случайного шага. Это позволяет сети вырываться из локальных минимумов и в то же время гарантирует окончательную стабилизацию сети.
Ловушки локальных минимумов досаждают всем алгоритмам обучения, основанным на поиске минимума, включая персептрон и сети обратного распространения, и представляют серьезную и широко распространенную трудность, которой часто не замечают. Стохастические методы позволяют решить эту проблему. Стратегия коррекции весов, вынуждающая веса принимать значение глобального оптимума в точке В, возможна.
В качестве объясняющей аналогии предположим, что на рис. 5.2 изображен шарик на поверхности в коробке. Если коробку сильно потрясти в горизонтальном направлении, то шарик будет быстро перекатываться от одного края к другому. Нигде не задерживаясь, в каждый момент шарик будет с равной вероятностью находиться в любой точке поверхности.
Если постепенно уменьшать силу встряхивания, то будет достигнуто условие, при котором шарик будет на короткое время «застревать» в точке В. При еще более слабом встряхивании шарик будет на короткое время останавливаться как в точке А, так и в точке В. При непрерывном уменьшении силы встряхивания будет достигнута критическая точка, когда сила встряхивания достаточна для перемещения шарика из точки А в точку В, но недостаточна для того, чтобы шарик мог вскарабкаться из В в А. Таким образом, окончательно шарик остановится в точке глобального минимума, когда амплитуда встряхивания уменьшится до нуля.
Искусственные нейронные сети могут обучаться по существу тем же самым образом посредством случайной коррекции весов. Вначале делаются большие случайные коррекции с сохранением только тех изменений весов, которые уменьшают целевую функцию. Затем средний размер шага постепенно уменьшается, и глобальный минимум в конце концов достигается.
Это сильно напоминает отжиг металла, поэтому для ее описания часто используют термин «имитация отжига». В металле, нагретом до температуры, превышающей его точку плавления, атомы находятся в сильном беспорядочном движении. Как и во всех физических системах, атомы стремятся к состоянию минимума энергии (единому кристаллу в данном случае), но при высоких температурах энергия атомных движений препятствует этому. В процессе постепенного охлаждения металла возникают все более низкоэнергетические состояния, пока в конце концов не будет достигнуто наинизшее из возможных состояний, глобальный минимум. В процессе отжига распределение энергетических уровней описывается следующим соотношением:
P(e) = exp(–e/kT) (5.1)
где Р(е) – вероятность того, что система находится в состоянии с энергией е; k – постоянная Больцмана; Т – температура по шкале Кельвина.
При высоких температурах Р(е) приближается к единице для всех энергетических состояний. Таким образом, высокоэнергетическое состояние почти столь же вероятно, как и низкоэнергетическое. По мере уменьшения температуры вероятность высокоэнергетических состояний уменьшается по сравнению с низкоэнергетическими. При приближении температуры к нулю становится весьма маловероятным, чтобы система находилась в высокоэнергетическом состоянии.
Больцмановское обучение
Этот стохастический метод непосредственно применим к обучению искусственных нейронных сетей:
1. Определить переменную Т, представляющую искусственную температуру. Придать Т большое начальное значение.
2. Предъявить сети множество входов и вычислить выходы и целевую функцию.
3. Дать случайное изменение весу и пересчитать выход сети и изменение целевой функции в соответствии со сделанным изменением веса.
4. Если целевая функция уменьшилась (улучшилась), то сохранить изменение веса.
Если изменение веса приводит к увеличению целевой функции, то вероятность сохранения этого изменения вычисляется с помощью распределения Больцмана:
P(c) = exp(–c/kT) (5.2)
где Р(с) – вероятность изменения с в целевой функции; k – константа, аналогичная константе Больцмана, выбираемая в зависимости от задачи; Т – искусственная температура.
Выбирается случайное число r из равномерного распределения от нуля до единицы. Если Р(с) больше, чем r, то изменение сохраняется, в противном случае величина веса возвращается к предыдущему значению.
Это позволяет системе делать случайный шаг в направлении, портящем целевую функцию, позволяя ей тем самым вырываться из локальных минимумов, где любой малый шаг увеличивает целевую функцию.
Для завершения больцмановского обучения повторяют шаги 3 и 4 для каждого из весов сети, постепенно уменьшая температуру Т, пока не будет достигнуто допустимо низкое значение целевой функции. В этот момент предъявляется другой входной вектор и процесс обучения повторяется. Сеть обучается на всех векторах обучающего множества, с возможным повторением, пока целевая функция не станет допустимой для всех них.
Величина случайного изменения веса на шаге 3 может определяться различными способами. Например, подобно тепловой системе весовое изменение w может выбираться в соответствии с гауссовским распределением:
P(w) = exp(–w2/T2) (5.2)
где P(w) – вероятность изменения веса на величину w, Т – искусственная температура.
Такой выбор изменения веса приводит к системе, аналогичной [З].
Так как нужна величина изменения веса Δw, а не вероятность изменения веса, имеющего величину w, то метод Монте-Карло может быть использован следующим образом:
1. Найти кумулятивную вероятность, соответствующую P(w). Это есть интеграл от P(w) в пределах от 0 до w. Так как в данном случае P(w) не может быть проинтегрирована аналитически, она должна интегрироваться численно, а результат необходимо затабулировать.
2. Выбрать случайное число из равномерного распределения на интервале (0,1). Используя эту величину в качестве значения P(w}, найти в таблице соответствующее значение для величины изменения веса.
Свойства машины Больцмана широко изучались. В работе [1] показано, что скорость уменьшения температуры должна быть обратно пропорциональна логарифму времени, чтобы была достигнута сходимость к глобальному минимуму. Скорость охлаждения в такой системе выражается следующим образом:
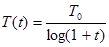 (5.4)
(5.4)
где T(t) – искусственная температура как функция времени; Т0 – начальная искусственная температура; t – искусственное время.
Этот разочаровывающий результат предсказывает очень медленную скорость охлаждения (и данные вычисления). Этот вывод подтвердился экспериментально. Машины Больцмана часто требуют для обучения очень большого ресурса времени.
Обучение Коши
В работе [6] развит метод быстрого обучения подобных систем. В этом методе при вычислении величины шага распределение Больцмана заменяется на распределение Коши. Распределение Коши имеет, как показано на рис. 5.3, более длинные «хвосты», увеличивая тем самым вероятность больших шагов. В действительности распределение Коши имеет бесконечную (неопределенную) дисперсию. С помощью такого простого изменения максимальная скорость уменьшения температуры становится обратно пропорциональной линейной величине, а не логарифму, как для алгоритма обучения Больцмана. Это резко уменьшает время обучения. Эта связь может быть выражена следующим образом:
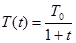 (5.5)
(5.5)
Распределение Коши имеет вид
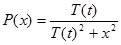 (5.6)
(5.6)
где Р(х) есть вероятность шага величины х.
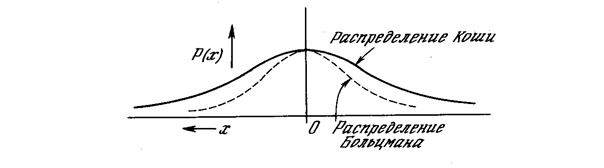
Рис. 5.3. Распределение Коши и распределение Больцмана
В уравнении (5.6) Р(х) может быть проинтегрирована стандартными методами. Решая относительно х, получаем
xc = r T(t) tg(P(x)), (5.7)
где r – коэффициент скорости обучения; хc – изменение веса.
Теперь применение метода Монте Карло становится очень простым. Для нахождения х в этом случае выбирается случайное число из равномерного распределения на открытом интервале (–p/2, p/2) (необходимо ограничить функцию тангенса). Оно подставляется в формулу (5.7) в качестве Р(х), и с помощью текущей температуры вычисляется величина шага.