
Коэффициент корреляции рангов Спирмена rs








Этот коэффициент рассчитывать проще, однако результаты получаются менее точными, чем при использовании r. Это связано с тем, что при вычислении коэффициента Спирмена используют порядок следования данных, а не их количественные характеристики и интервалы между классами.
Дело в том, что при использовании коэффициента корреляции рангов Спирмена (rs) проверяют только, будет ли ранжирование данных для какой-либо выборки таким же, как и в ряду других данных для этой выборки, попарно связанных с первыми (например, будут ли одинаково «ранжироваться» студенты при прохождении ими как психологии, так и математики, или даже при двух разных преподавателях психологии?). Если коэффициент близок к + 1, то это означает, что оба ряда практически совпадают, а если этот коэффициент близок к - 1, можно говорить о полной обратной зависимости.
Коэффициент rs вычисляют по формуле
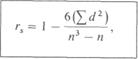
где d- разность между рангами сопряженных значений признаков (независимо от ее знака), а n-число пар.
Обычно этот непараметрический тест используется в тех случаях, когда нужно сделать какие-то выводы не столько об интервалах между данными, сколько об их рангах, а также тогда, когда кривые распределения слишком асимметричны и не позволяют использовать такие параметрические критерии, как коэффициент r (в этих случаях бывает необходимо превратить количественные данные в порядковые).
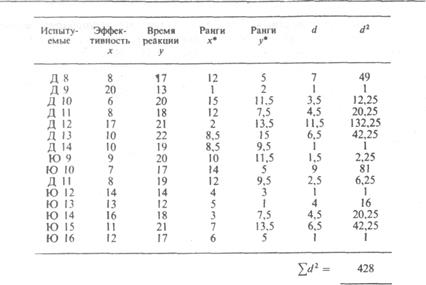
Поскольку именно так обстоит дело с распределением значений эффективности и времени реакции в экспериментальной группе после воздействия, можно повторить расчеты, которые вы уже проделали для этой группы, только теперь не для коэффициента r , а для показателя rs. Это позволит посмотреть, насколько различаются эти два показателя*.
* Следует помнить, что
1) для числа попаданий 1-й ранг соответствует самой высокой, а 15-й-самой низкой результативности, тогда как для времени реакции 1-й ранг соответствует самому короткому времени, а 15-й-самому долгому;
2) данным ex aequo придается средний ранг.
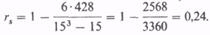
Таким образом, как и в случае коэффициента r, получен положительный, хотя и недостоверный, результат. Какой же из двух результатов правдоподобнее: r = -0,48 или rs = +0,24? Такой вопрос может встать лишь в том случае, если результаты достоверны.
Хотелось бы еще раз подчеркнуть, что сущность этих двух коэффициентов несколько различна. Отрицательный коэффициент r указывает на то, что эффективность чаще всего тем выше, чем время реакции меньше, тогда как при вычислении коэффициента rs требовалось проверить, всегда ли более быстрые испытуемые реагируют более точно, а более медленные - менее точно.
Поскольку в экспериментальной группе после воздействия был получен коэффициент r s , равный 0,24, подобная тенденция здесь, очевидно, не прослеживается. Попробуйте самостоятельно разобраться в данных для контрольной группы после воздействия, зная, что åd2 = 122,5:
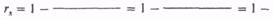 ; достоверно ли?
; достоверно ли?
Каков ваш вывод?………………………………… ……………………………………………………………
…………………………………………………………………………………………………………………….
Итак, мы рассмотрели различные параметрические и непараметрические статистические методы, используемые в психологии. Наш обзор был весьма поверхностным, и главная задача его заключалась в том, чтобы читатель понял, что статистика не так страшна, как кажется, и требует в основном здравого смысла. Напоминаем, что данные «опыта», с которыми мы здесь имели дело, - вымышленные и не могут служить основанием для каких-либо выводов. Впрочем, подобный эксперимент стоило бы действительно провести. Поскольку для этого опыта была выбрана сугубо классическая методика, такой же статистический анализ можно было бы использовать во множестве различных экспериментов. В любом случае нам кажется, что мы наметили какие-то главные направления, которые могут оказаться полезны тем, кто не знает, с чего начать статистический анализ полученных результатов.
Резюме
Существуют три главных раздела статистики: описательная статистика, индуктивная статистика и корреляционный анализ.
I . Описательная статистика
1. Задачи описательной статистики - классификация данных, построение распределения их частот, выявление центральных тенденций этого распределения и оценка разброса данных относительно средних.
2. Для классификации данных сначала располагают их в возрастающем порядке. Далее их разбивают на классы по величине, интервалы между которыми определяются в зависимости от того, что именно исследователь хочет выявить в данном распределении.
3. К наиболее часто используемым параметрам, с помощью которых можно описать распределение, относятся, с одной стороны, такие величины, как мода, медиана и средняя арифметическая, а с другой -показатели, разброса, такие как варианса (дисперсия) и стандартное отклонение.
4. Мода соответствует значению, которое встречается чаще других или находится в середине класса, обладающего наибольшей частотой.
Медиана соответствует значению центрального данного, которое может быть получено после того, как все данные будут расположены в возрастающем порядке.