
□ Изменить компиляторы для генерации новых IL-команд и измененного формата метаданных.








□ Изменить JIT-компилятор, чтобы он обрабатывал новые IL-команды, работающие с аргументами типа, и создавал корректный машинный код.
□ Создать новые члены отражения, чтобы разработчики могли запрашивать информацию о типах и членах, проверяя у них наличие параметров.
□ Определить новые члены, предоставляющие информацию отражения, чтобы разработчики могли создавать определения обобщенных типов и методов во время исполнения.
□ Изменить отладчик, чтобы он поддерживал обобщенные типы, члены, поля и локальные переменные.
□ Изменить функцию IntelliSense в Microsoft Visual Studio для отображения конкретных прототипов членов при использовании обобщенного типа или метода с указанием типа данных.
А теперь разберемся, как обобщения реализуются во внутренних механизмах CLR. Эта информация пригодится вам как при проектировании и создании, так и при выборе готовых обобщенных алгоритмов.
Открытые и закрытые типы
Я уже рассказывал, как CLR создает внутреннюю структуру данных для каждого типа, применяемого в приложении. Эти структуры данных называют объектами- типами (type objects). Обобщенный тип также считается типом, и для него CLR тоже создает внутренний объект-тип. Это справедливо для ссылочных типов (классов), значимых типов (структур), интерфейсов и делегатов. Тем не менее тип с обобщенными параметрами-типами называют открытым типом (open type), а в CLR запрещено конструирование экземпляров открытых типов (как и экземпляров интерфейсных типов).
При ссылке на обобщенный тип в коде можно определить набор обобщенных аргументов типа. Если всем аргументам определенного типа передаются действительные типы данных, то он становится закрытым типом (closed type). CLR разрешает создание экземпляров закрытых типов. Тем не менее в коде, ссылающемся на обобщенный тип, можно не определять все обобщенные аргументы типа. Таким образом, в CLR создается новый объект открытого типа, экземпляры которого создавать нельзя. Следующий код проясняет ситуацию:
using System;
using System.Collections.Generic;
// Частично определенный открытый тип
internal sealed class DictionaryStringKey<TValue> :
DictionarycString, TValue> {
}
public static class Program { public static void Main() {
Object о = null;
// Dictionary<j> - открытый тип с двумя параметрами типа Type t = typeof(Dictionary<j>);
// Попытка создания экземпляра этого типа (неудачная) о = Createlnstance(t);
Console.WriteLine();
// DictionaryStringKeyo - открытый тип с одним параметром типа
t = typeof (DictionaryStringKeyo);
// Попытка создания экземпляра этого типа (неудачная) о = Createlnstance(t);
Console.WriteLine();
// DictionaryStringKey<Guid> - это закрытый тип t = typeof(DictionaryStringKey<Guid>)j
// Попытка создания экземпляра этого типа (удачная) о = Createlnstance(t);
II Проверка успешности попытки
Console.WriteLine("Object type=" + o.GetType());
>
private static Object CreateInstance(Type t) {
Object о = null; try {
о = Activator.Createlnstance(t);
Console.Write("Created instance of {0}", t.ToString());
>
catch (ArgumentException e) {
Console.WriteLine(e.Message);
}
return o;
}
}
Если откомпилировать и выполнить этот код, вы увидите следующее:
Cannot create an Instance of System.Collections.Generic.
Dictionary' 2[TKey,TValue] because Type.ContainsGenericParameters is true.
Cannot create an instance of DictionaryStringKey'l[TValue] because Type.ContainsGenericParameters is true.
Created instance of DictionaryStringKey'l[System.Guid]
Object type=DictionaryStringKey'l[System.Guid]
Итак, при попытке создания экземпляра открытого типа метод Createlnstance объекта Activator выдает исключение ArgumentException. На самом деле сообщение об исключении означает, что тип все еще содержит обобщенные параметры типа.
В выводимой программой информации видно, что имена типов заканчиваются левой одиночной кавычкой ('), за которой следует число, означающее арность (arity) типа, то есть число необходимых для него параметров типа. Например, арность класса Dictionary равна 2, потому что для него требуется определить типы ТКеу и TValue. Арность класса DictionaryStringKey равна 1, так как требуется указать лишь один тип — TValue.
Необходимо отметить, что CLR размещает статические поля типа в самом объекте-типе (см. главу 4). Следовательно, каждый закрытый тип имеет свои статические поля. Иначе говоря, статические поля, определенные в объекте List<T>, не будут совместно использоваться объектами List<DateTime> и List<String>, потому что у каждого объекта закрытого типа есть свои статические поля. Если же в обобщенном типе определен статический конструктор (см. главу 8), то последний выполняется для закрытого типа лишь раз. Иногда разработчики определяют статический конструктор для обобщенного типа, чтобы аргументы типа соответствовали определенным критериям. Например, обобщенный тип, используемый только с перечислимыми типами, определяется следующим образом:
internal sealed class GenericTypeThatRequiresAnEnum<T> { static GenericTypeThatRequiresAnEnum() { if (Itypeof(T).IsEnum) {
throw new ArgumentException("T must be an enumerated type");
}
}
}
В CLR существует механизм ограничений (constraints), предлагающий более удачный инструмент определения обобщенного типа с указанием допустимых для него аргументов типа. Но об ограничениях — чуть позже. К сожалению, этот механизм не позволяет ограничить аргументы типа только перечислимыми типами, поэтому в предыдущем примере необходим статический конструктор для проверки того, что используемый тип является перечислимым.
Обобщенные типы и наследование
Обобщенный тип, как и всякий другой, может быть производным от других типов. При использовании обобщенного типа с указанием аргументов типа в CLR определяется новый объект-тип, производный от того же типа, что и обобщенный тип. Например, тип List<T> является производным от Object, поэтому типы List<String> и List<Guid> тоже будут производными от Object. Аналогично, тип DictionaryStringKey<TValue> — производный от Dictionary<String, TValue>, поэтому тип DictionanyStningKey<Guid> также производный от Dictionany<Stning, Guid>. Понимание того, что определение аргументов типа не имеет ничего общего с иерархиями наследования, позволяет разобраться, какие приведения типов допустимы, а какие нет.
Например, пусть класс Node связанного списка определяется следующим образом.
internal sealed class Node<T> { public T m_data; public Node<T> m_next;
public Node(T data) : this(data, null) {
}
public Node(T data, Node<T> next) { mdata = data; mnext = next;
}
public override String ToStringQ { return m_data.ToString() +
((m_next != null) ? mnext.ToString() : null);
}
}
Тогда код создания связного списка будет выглядеть примерно так:
private static void SameDataLlnkedLlst() {
Node<Char> head = new Node<Char>('C'); head = new Node<Char>('B', head); head = new Node<Char>('A', head);
Console.WriteLine(head. ToString()); // Выводится "ABC"
}
В приведенном классе Node поле m_next должно ссылаться на другой узел, поле m_data которого содержит тот же тип данных. Это значит, что узлы связного списка должны иметь одинаковый (или производный) тип данных. Например, нельзя использовать класс Node для создания связного списка, в котором тип данных одного элемента — Chan, другого — DateTime, а третьего — String... Вернее, можно, если использовать везде Node<Object>, но тогда мы лишаемся безопасности типов на стадии компиляции, а значимые типы будут упаковываться.
Следовательно, будет лучше начать с определения необобщенного базового класса Node, а затем определить обобщенный класс TypedNode (используя класс Node как базовый). Такое решение позволяет создать связный список с произвольным типом данных у каждого узла, пользоваться преимуществами безопасности типов и избежать упаковки значимых типов. Вот определения новых классов:
internal class Node { protected Node mnext;
public Node(Node next) { m_next = next;
>
>
internal sealed class TypedNode<T> : Node { public T m_data;
public TypedNode(T data) : this(data, null) {
>
public TypedNode(T data, Node next) : base(next) { m_data = data;
> public override String ToStringO {
return m_data.ToString() +
((mnext != null) ? m_next.ToString() : String.Empty);
}
>
Теперь можно написать код для создания связного списка с разными типами данных у разных узлов. Код будет выглядеть примерно так:
private static void DifferentDataLinkedList() {
Node head = new TypedNode<Char>(".");
head = new TypedNode<DateTime>(DateTime.NoWj head);
head = new TypedNode<String>("Today is ", head);
Console. Write Line (head. ToStringO);
>
Идентификация обобщенных типов
Синтаксис обобщенных типов часто приводит разработчиков в замешательство. В исходном коде появляется слишком много знаков «меньше» (<) и «больше» (>), и это сильно затрудняет его чтение. Для упрощения синтаксиса некоторые разработчики определяют новый необобщенный тип класса, производный от обобщенного типа и определяющий все необходимые аргументы типа. Например, пусть нужно упростить следующий код:
List<DateTime> dt = new List<DateTime>();
Некоторые разработчики сначала определят класс:
internal sealed class DateTimeList : List<DateTime> {
// Здесь никакой код добавлять не нужно!
}
Теперь код создания списка можно написать проще (без знаков < и >): DateTimeList dt = new DateTimeList();
Этот вариант удобен при использовании нового типа для параметров, локальных переменных и полей. И все же ни в коем случае нельзя явно определять новый класс лишь затем, чтобы упростить чтение исходного текста. Причина проста: пропадает тождественность и эквивалентность типов, как видно из следующего кода:
Boolean sameType = (typeof(List<DateTime>) == typeof(DateTimeList));
При выполнении этого кода sameType инициализируется значением false, потому что сравниваются два объекта разных типов. Это также значит, что методу, в прототипе которого определено, что он принимает значение типа DateTimeList, нельзя передать List<DateTime>. Тем не менее методу, который должен принимать List<DateTime>, можно передать DateTimeList, потому что тип DateTimeList является производным от List<DateTime>. Запутаться в этом очень просто.
К счастью, C# позволяет использовать упрощенный синтаксис для ссылки на обобщенный закрытый тип, не влияющий на эквивалентность типов. Для этого в начало файла с исходным текстом нужно добавить старую добрую директиву using:
using DateTimeList = System.Collections.Generic.List<System.DateTime>;
Здесь директива using просто определяет символическое имя DateTimeList. При компиляции кода компилятор заменяет все вхождения DateTimeList типом System.Collections.Generic. List<System.DateTime>. Таким образом, разработчики могут использовать упрощенный синтаксис, не меняя смысл кода и тем самым сохраняя идентификацию и тождество типов. Теперь при выполнении следующей строки кода sameType инициализируется значением true:
Boolean sameType = (typeof(List<DateTime>) == typeof(DateTimeList));
Для удобства вы можете использовать свойство локальной переменной неявного типа языка С#, для которой компилятор обозначает тип локальной переменной метода из типа вашего выражения:
using System;
using System.Collections.Generic;
internal sealed class SomeType { private static void SomeMethod () {
// Компилятор определяет, что dtl имеет тип // System.Collections.Generic.List<System.DateTime> var dtl = List<DateTime>();
}
}
Разрастание кода
При JIT-компиляции обобщенного метода CLR подставляет в IL-код метода указанные аргументы-типы, а затем создает машинный код для данного метода, работающего с конкретными типами данных. Это именно то, что нужно, и это одна из основных функций обобщений. Но в таком подходе есть один недостаток: CLR генерирует машинный код для каждого сочетания «метод + тип», что приводит к разрастанию кода (code explosion); в итоге существенно увеличивается рабочий набор приложения, снижая производительность.
К счастью, в CLR есть несколько механизмов оптимизации, призванных предотвратить разрастание кода. Во-первых, если метод вызывается для конкретного аргумента типа и позже он вызывается опять с тем же аргументом типа, CLR компилирует код для такого сочетания «метод + тип» только один раз. Поэтому, если List<DateTime> используется в двух совершенно разных сборках (загруженных в один домен приложений), CLR компилирует методы для List<DateTime> всего один раз. Это существенно сокращает степень разрастания кода.
Кроме того, CLR считает все аргументы ссылочного типа тождественными, что опять же обеспечивает совместное использование кода. Например, код, скомпилированный в CLR для методов List<String>, может применяться для методов List<Stream>, потому что String и Stream — ссылочные типы. По сути, для всех ссылочных типов используется одинаковый код. CLR выполняет эту оптимизацию, потому что все аргументы и переменные ссылочного типа — это просто указатели на объекты в куче (32-разрядное значение в 32-разрядной и 64-разрядное значение в 64-разрядной версии Windows), а все операции с указателями на объекты выполняются одинаково.
Но если аргументы типа относятся к значимому типу, среда CLR должна сгенерировать машинный код именно для этого значимого типа. Это объясняется тем, что у значимых типов может быть разный размер. И даже если два значимых типа имеют одинаковый размер (например, Int32 и UInt32 — это 32-разрядные значения), CLR все равно не может использовать дяя них единый код, потому что для обработки этих значений могут применяться разные машинные команды.
Обобщенные интерфейсы
Конечно же, основное преимущество обобщений — это способность определять обобщенные ссылочные и значимые типы. Но для CLR также исключительно важна поддержка обобщенных интерфейсов. Без них любая попытка работы со значимым типом через необобщенный интерфейс (например, IComparable) всякий раз будет приводить к необходимости упаковки и потере безопасности типов в процессе компиляции, что сильно сузило бы область применения обобщенных типов. Вот почему CLR поддерживает обобщенные интерфейсы. Ссылочный и значимый типы реализуют обобщенный интерфейс путем задания аргументов-типов, или же любой тип реализует обобщенный интерфейс, не задавая аргументы-типы. Рассмотрим несколько примеров.
Определение обобщенного интерфейса из библиотеки FCL (из пространства имен System.Collections.Generic) выглядит следующим образом:
public interface IEnumerator<T> : IDisposable, IEnumerator {
T Current { get; }
}
Следующий тип реализует данный обобщенный интерфейс и задает аргументы типа.
Обратите внимание, что объект Triangle может перечислять набор объектов Point, а свойство Current имеет тип Point:
internal sealed class Triangle : IEnumerator<Point> { private Point[] m_vertices;
// Тип свойства Current в IEnumerator<Point> - это Point public Point Current { get { ... } }
}
Теперь рассмотрим пример типа, реализующего тот же обобщенный интерфейс, но без задания аргументов-типов:
internal sealed class ArrayEnumerator<T> : IEnumerator<T> { private T[] marray;
// Тип свойства Current в IEnumerator<T> - T public T Current { get { ... } }
}
Обратите внимание: объект Array Enumerator перечисляет набор объектов Т (где Т не задано, поэтому код, использующий обобщенный тип ArrayEnumerator, может задать тип Т позже). Также отмечу, что в этом примере свойство Current имеет неопределенный тип данных Т. Подробнее обобщенные интерфейсы обсуждаются в главе 13.
Обобщенные делегаты
Поддержка обобщенных делегатов в CLR позволяет передавать методам обратного вызова любые типы объектов, обеспечивая при этом безопасность типов. Более того, благодаря обобщенным делегатам экземпляры значимого типа могут передаваться методам обратного вызова без упаковки. Как уже отмечалось в главе 17, делегат — это просто определение класса с помощью четырех методов: конструктора и методов Invoke, Beginlnvoke и Endlnvoke. При определении типа делегата с параметрами типа компилятор задает методы класса делегата, а параметры типа применяются ко всем методам, параметры и возвращаемые значения которых относятся к указанному параметру типа.
Например, обобщенный делегат определяется следующим образом:
public delegate TReturn CallMecTReturn, TKey, TValue>(
TKey key, TValue value);
Компилятор превращает его в класс, который на логическом уровне выглядит так:
public sealed class CallMecTReturn, TKey, TValue> : MulticastDelegate { public CallMe(Object object, IntPtr method); public virtual TReturn Invoke(TKey key, TValue value); public virtual IAsyncResult BeginInvoke(TKey key, TValue value,
AsyncCallback callback, Object object); public virtual TReturn Endlnvoke(IAsyncResult result);
>
ПРИМЕЧАНИЕ
Там, где это возможно, рекомендуется использовать обобщенных делегатов Action и Func из библиотеки FCL. Я описал эти типы делегатов в главе 17.
Контравариантные и ковариантные аргументы-типы в делегатах и интерфейсах
Каждый из параметров-типов обобщенного делегата должен быть помечен как ковариантный или контравариантный. Это позволяет вам осуществлять приведение типа переменной обобщенного делегата к тому же типу делегата с другим параметром-типом. Параметры-типы могут быть:
□ Инвариантными. Параметр-тип не может изменяться. Пока в этой главе приводились только инвариантные параметры-типы.
□ Контравариантными. Параметр-тип может быть преобразован от класса к классу, производному от него. В языке C# контравариантный тип обозначается ключевым словом in. Контравариантный параметр-тип может появляться только во входной позиции, например, в качестве аргументов метода.
□ Ковариантными. Аргумент-тип может быть преобразован от класса к одному из его базовых классов. В языке C# ковариантный тип обозначается ключевым словом out. Ковариантный параметр обобщенного типа может появляться только в выходной позиции, например, в качестве возвращаемого значения метода.
Предположим, что существует следующий тип делегата:
public delegate TResult Funccin T, out TResult>(T arg);
Здесь параметр-тип T помечен словом in, делающим его контравариантным, а параметр-тип TResult помечен словом out, делающим его ковариантным.
Пусть объявлена следующая переменная:
FunccObJect, ArgumentException> fnl = null;
Ее можно привести к типу Func с другими параметрами-типами:
FunccString, Exception) fn2 = fnl; // Явного приведения типа не требуется Exception е = fn2("");
Это говорит о том, что fnl ссылается на функцию, которая получает Object и возвращает ArgumentException. Переменная fn2 пытается сослаться на метод, который получает String и возвращает Exception. Так как мы можем передать String методу, которому требуется тип Object (тип String является производным от Object), а результат метода, возвращающего ArgumentException, может интерпретироваться как Exception (тип ArgumentException является производным от Exception), представленный здесь программный код откомпилируется, а на этапе компиляции будет сохранена безопасность типов.
ПРИМЕЧАНИЕ
Вариантность действует только в том случае, если компилятор сможет установить возможность преобразования ссылок между типами. Другими словами, вариантность неприменима для значимых типов из-за необходимости упаковки (boxing). Я считаю, что из-за этого ограничения вариантность существенно теряет свою полезность. Например:
void ProcessCollection(IEnumerable<ObJect> collection) { ... }
Я не смогу вызвать этот метод, передавая ссылку на объект List<DateTime> из-за невозможности ссылочного преобразования между значимым типом DateTime и объектом Object, даже если DateTime унаследован от объекта Object. Можно решить эту проблему следующим образом:
void ProcessCollection<T>(IEnumerable<T> collection) { ... }
Большое преимущество записи ProcessCollection(IEnumerable<Object> collection) заключается в том, что здесь используется только одна версия JIT-кода. Однако для ProcessCollection<T> (IEnumerable<T> collection) тоже существует только одна версия JIT-кода, совместно используемая всеми Т, являющимися ссылочными типами. Для Т, являющихся значимыми типами, будут генерироваться другие версии ЛТ-кода, но по крайней мере теперь можно вызвать метод с передачей ему коллекции значимого типа.
Вариантность также недопустима для параметра-типа, если при передаче аргумента этого типа используются ключевые слова out и ref. Например, для строки:
delegate void SomeDelegate<in T>(ref T t);
компилятор выдает следующее сообщение об ошибке (недействительная вариантность: параметр-тип Т' должен быть инвариантно действительным для 'SomeDelegate<T>.lnvoke(ref Т)'. Параметр-тип Т' контравариантен):
Invalid variance: The type parameter "T" must be invariantly valid on 'SomeDelegate<T>.Invoke(ref T)". "T‘ is contravariant
При использовании делегатов с обобщенными аргументами и возвращаемыми значениями рекомендуется всегда использовать ключевые слова in и out для обозначения контравариантности и ковариантности везде, где это возможно. Это не приводит ни к каким нежелательным последствиям, но позволит применять ваших делегатов в большем количестве сценариев.
Как и в случае с делегатами, параметры-типы интерфейсов могут быть либо контравариантными, либо ковариантными. Приведу пример интерфейса с контра- вариантным параметром обобщенного типа:
public interface IEnumeratorcout T> : IEnumerator {
Boolean MoveNextQ;
T Current { get; }
}
Контравариантность T позволяет успешно скомпилировать и выполнить следующий программный код:
// Этот метод допускает интерфейс IEnumerable любого ссылочного типа Int32 Count(IEnumerable<Ob]ect> collection) { ... }
// Этот вызов передает IEnumerable<String> в Count Int32 с = Count(new[] { "Grant" });
ВНИМАНИЕ
Иногда разработчики спрашивают, почему они должны явно указывать слово in или out в параметрах обобщенного типа. Они полагают, что компилятор может самостоятельно проверить объявление делегатов или интерфейсов и автоматически определить, являются ли параметры обобщенного типа контравариантными или ковариантными. Несмотря на то что компилятор действительно может это определять автоматически, разработчики языка C# считают, что при определении контракта следует указывать эти слова в явном виде. Представьте, что компилятор определил, что параметр обобщенного типа контравариантен, а затем в будущем в интерфейс будет добавлен член с параметром-типом в выходной позиции. В следующий раз при компиляции компилятор определит, что этот параметр-тип инвариантен, но в тех местах кода, где используется факт контравариантности параметра-типа, могут возникнуть ошибки.
По этой причине разработчики компилятора требуют точно определять параметр- тип. При попытке использования этого параметра-типа в контексте, не соответствующем объявлению, компилятор выдаст ошибку с сообщением о нарушении контракта. Если потом вы решите исправить код путем добавления in или out для параметров-типов, вам придется внести изменения в программный код, использующий старый контракт.
Обобщенные методы
При определении обобщенного ссылочного и значимого типа или интерфейса все методы, определенные в этих типах, могут использовать их параметр-тип. Параметр-тип может использоваться для параметров метода, возвращаемого значения метода или типа заданной внутри него локальной переменной. Но CLR также позволяет методу иметь собственные параметры-типы, которые могут применяться для параметров, возвращаемых значений или локальных переменных. Вот немного искусственный пример типа, в котором определяются параметр-тип и метод с собственным параметром-типом:
internal sealed class GenericType<T> { private T mvalue;
public GenericType(T value) { m_value = value; }
public TOutput Converter<TOutput>() {
TOutput result = (TOutput) Convert.ChangeType(revalue, typeof(TOutput));
продолжение &
return result;
}
}
Здесь в классе GenericType определяется свой параметр-тип (Т), а в методе Converter — свой (TOutput). Благодаря этому можно создать класс GenericType, работающий с любым типом. Метод Converter преобразует объект, на который ссылается поле m_value, в другие типы в зависимости от аргумента типа, переданного ему при его вызове. Возможность определения независимых параметров-типов и параметров метода дает небывалую гибкость.
Удачный пример обобщенного метода — метод Swap:
private static void Swap<T>(ref T ol, ref T o2) {
T temp = ol;
1 = o2;
2 = temp;
}
Теперь вызывать Swap из кода можно следующим образом:
private static void CallingSwapQ {
Int32 nl = 1, n2 = 2;
Console.WriteLine("nl={0}, n2={l}", nl, n2);
Swap<Int32>(ref nl, ref n2);
Console.WriteLine("nl={0}, n2={l}“, nl, n2);
String si = "Aidan", s2 = "Grant";
Console.WriteLine("sl={0}, s2={l}", si, s2);
Swap<String>(ref si, ref s2);
Console.WriteLine("sl={0}, s2={l}“, si, s2);
>
Использование обобщенных типов с методами, получающими параметры out и ref, особенно интересно тем, что переменные, передаваемые в качестве аргумента out/ref, должны быть того же типа, что и параметр метода, чтобы избежать возможного нарушения безопасности типов. Эта особенность параметров out/ref обсуждается в главе 9. В сущности, именно поэтому методы Exchange и CompareExchange класса Interlocked поддерживают обобщенную перегрузку1:
public static class Interlocked {
public static T Exchange<T>(ref T locationl, T value) where T: class; public static T CompareExchange<T>(
ref T locationl, T value, T comparand) where T: class;
}
Обобщенные методы и выведение типов
Синтаксис обобщений в C# со всеми его знаками «меньше» и «больше» приводит в замешательство многих разработчиков. С целью упростить создание, чтение и ра-
 Ключевое слово where описано в разделе «Верификация и ограничения» этой главы.
Ключевое слово where описано в разделе «Верификация и ограничения» этой главы.
боту с кодом компилятор C# предлагает логическое выведение типов (type inference) при вызове обобщенных методов. Это значит, что компилятор пытается определить (или логически вывести) тип, который будет автоматически использоваться при вызове обобщенного метода. Логический вывод типов продемонстрирован в следующем фрагменте кода:
private static void CallingSwapUsingInference() {
Int32 nl = 1, n2 = 2;
Swap(ref nl, ref n2); // Вызывает Swap<Int32>
String si = "Aidan";
Object s2 = "Grant";
Swap(ref si, ref s2); // Ошибка, невозможно вывести тип
>
Обратите внимание, что в этом коде при вызове Swap аргументы типа не задаются с помощью знаков < и >. В первом вызове Swap компилятор C# сумел установить, что переменные nl и п2 относятся к типу Int32, поэтому он вызвал Swap, используя аргумент-тип Int32.
При выполнении логического выведения типа в C# используется тип данных переменной, а не фактический тип объекта, на который ссылается эта переменная. Поэтому во втором вызове Swap компилятор C# «видит», что si имеет тип String, a s2 — Object (хотя s2 ссылается на String). Поскольку у переменных si и s2 разный тип данных, компилятор не может с точностью вывести тип для аргумента типа метода Swap и выдает ошибку (ошибка CS0411: аргументы типа для метода Program.Swap<T>(ref Т, ref Т) не могут быть выведены. Попробуйте явно задать аргументы типа):
error CS0411: The type arguments for method "Program.Swap<T>(ref T, ref T)" cannot be inferred from the usage. Try specifying the type arguments explicitly
Тип может определять несколько методов таким образом, что один из них будет принимать конкретный тип данных, а другой — обобщенный параметр-тип, как в этом примере:
private static void Display(String s) {
Console.WriteLine(s);
}
private static void Display<T>(T o) {
Display(o.ToString()); // Вызывает Display(String)
}
Метод Display можно вызвать несколькими способами:
Display("3eff"); // Вызывает Display(String)
Display(123); // Вызывает Display<T>(T)
Display<String>("Aidan"); // Вызывает Display<T>(T)
В первом случае компилятор может вызвать либо метод Display, принимающий String, либо обобщенный метод Display (заменяя Т типом String). Но компилятор C# всегда выбирает явное, а не обобщенное соответствие, поэтому генерирует вызов
необобщенного метода Display, получающего String. Во втором случае компилятор не может вызвать необобщенный метод Display, получающий String, поэтому он вызывает обобщенный метод Display. Кстати, очень удачно, что компилятор всегда выбирает более явное соответствие. Ведь если бы компилятор выбрал обобщенный метод Display, тот вызвал бы метод ToString, возвращающий String, что привело бы к бесконечной рекурсии.
В третьем вызове метода Display задается обобщенный аргумент типа String. Для компилятора это означает, что не нужно пытаться логически вывести аргументы типа, а нужно использовать указанные аргументы типа. В данном случае компилятор также считает, что непременно нужно вызвать обобщенный метод Display, поэтому он его и вызывает. Внутренний код обобщенного метода Display вызывает ToString для переданной ему строки, а полученная в результате строка затем передается необобщенному методу Display.
Обобщения и другие члены
В языке C# у свойств, индексаторов, событий, операторных методов, конструкторов и деструкторов не может быть параметров-типов. Однако их можно определить в обобщенном типе с тем, чтобы в их коде использовать параметры-типы этого типа.
C# не поддерживает задание собственных обобщенных параметров типа у этих членов, поскольку создатели языка C# из компании Microsoft считают, что разработчикам вряд ли потребуется задействовать эти члены в качестве обобщенных. К тому же для поддержки обобщенного использования этих членов в C# пришлось бы разработать специальный синтаксис, что довольно затратно. Например, при использовании в коде оператора + компилятор может вызвать перегруженный операторный метод. Невозможно указать в коде, где есть оператор +, какие бы то ни было аргументы типа.
Верификация и ограничения
В процессе компиляции обобщенного кода компилятор C# анализирует его, убеждаясь, что он сможет работать с любыми типами данных — существующими и теми, которые будут определены в будущем. Рассмотрим следующий метод:
private static Boolean MethodTakingAnyType<T>(T о) {
T temp = о;
Console.WriteLine(о.ToString());
Boolean b = temp.Equals(o); return b;
Здесь объявляется временная переменная (temp) типа Т, а затем выполняется несколько операций присваивания переменных и несколько вызовов методов. Представленный метод работает с любым типом Т — ссылочным, значимым, перечислимым, типом интерфейса или типом делегата, существующим типом или типом, который будет определен в будущем, потому что любой тип поддерживает присваивание и вызовы методов, определенных в Object (например, ToString и Equals). Вот еще метод:
private static T Min<T>(T ol, Т о2) { if (ol.CompareTo(o2) < 0) return ol; return o2;
>
Метод Min пытается через переменную ol вызвать метод CompareTo. Но многие типы не поддерживают метод CompareTo, поэтому компилятор C# не в состоянии скомпилировать этот код и обеспечить, чтобы после компиляции метод смог работать со всеми типами. При попытке скомпилировать приведенный код появится сообщение об ошибке (ошибка CS0117: Т не содержит определение метода CompareTo):
error CS0117: "T" does not contain a definition for 'CompareTo'
Получается, что при использовании обобщений можно лишь объявлять переменные обобщенного типа, выполнять присваивание, вызывать методы, определенные в Object, — и все! Но ведь в таком случае от обобщений пользы мало. К счастью, компиляторы и CLR поддерживают уже упоминавшийся механизм ограничений (constraints), благодаря которому обобщения снова начинают приносить практическую пользу.
Ограничение сужает перечень типов, которые можно передать в обобщенном аргументе, и расширяет возможности по работе с этими типами. Вот новый вариант метода Min, который задает ограничение (выделено полужирным шрифтом):
public static T Min<T>(T ol, T о2) where Т : 1СоирагаЫе<Т> { if (ol.CompareTo(o2) < 0) return ol; return o2;
}
Маркер where в C# сообщает компилятору, что указанный в Т тип должен реализовывать обобщенный интерфейс IComparable того жетипа (Т). Благодаря этому ограничению компилятор разрешает методу вызвать метод CompareTo, потому что последний определен в интерфейсе IComparable<T>.
Теперь, когда код ссылается на обобщенный тип или метод, компилятор должен убедиться, что в коде указан аргумент типа, удовлетворяющий этим ограничениям. Пример:
private static void CallMinQ {
Object ol = "leff", o2 = "Richter";
Object oMin = Min<Object>(ol, o2); // Ошибка CS0311
При компиляции этого кода появляется сообщение (ошибка CS0311: тип object не может использоваться в качестве параметра-типа "Г" в обобщенном типе или методе 'SomeType.Min<T>(T,T)Не существует неявного преобразования ссылки из 'Object'в 'System.IComparablecobject>'.
Error CS0311: The type 'object' cannot be used as type parameter 'T' in the generic type or method 'SomeType.Min<T>(T, T)‘. There is no implicit reference conversion from 'object' to 'System.IComparable<object>'.
Компилятор выдает эту ошибку, потому что System.Object не реализует интерфейс IComparablecOb jectx На самом деле System .Object вообще не реализует никаких интерфейсов.
Итак, вы примерно представляете, что такое ограничения и как они работают. Ограничения можно применять к параметрам типа как обобщенных типов, так и обобщенных методов (как показано в методе Min). Среда CLR не поддерживает перегрузку по именам параметров типа или по именам ограничений. Перегрузка типов и методов выполняется только по арности. Покажу это на примере:
// Можно определить следующие типы: internal sealed class АТуре {} internal sealed class AType<T> {} internal sealed class ATypecTl, T2> {} // Ошибка: конфликт с типом АТуре<Т>, у которого нет ограничений, internal sealed class АТуре<Т> where Т : IComparable<T> {}
// Ошибка: конфликт с типом АТуре<Т1, Т2> internal sealed class АТуресТЗ, Т4> {}
internal sealed class AnotherType {
// Можно определить следующие методы: private static void M() {} private static void M<T>() {} private static void M<T1, T2>() {}
// Ошибка: конфликт с типом М<Т>, у которого нет ограничений private static void M<T>() where T : IComparable<T> {}
// Ошибка: конфликт с типом М<Т1, Т2>. private static void M<T3, Т4>() {}
}
При переопределении виртуального обобщенного метода в переопределяющем методе должно быть задано то же число параметров-типов, а они, в свою очередь, наследуют ограничения, заданные для них методом базового класса. Собственно, переопределяемый метод вообще не вправе задавать ограничения для своих параметров-типов, но может переименовывать параметры-типы. Аналогично, при реализации интерфейсного метода в нем должно задаваться то же число параметров-типов, что и в интерфейсном методе, причем эти параметры-типы наследуют ограничения, заданные для них методом интерфейса. Следующий пример демонстрирует это правило с помощью виртуальных методов:
internal class Base {
public virtual void M<T1, T2>() where T1 : struct
where T2 : class {
}
}
internal sealed class Derived : Base { public override void M<T3, T4>() where T3 : EventArgs // Ошибка
where T4 : class // Ошибка
{ }
}
При компиляции этого кода появится сообщение об ошибке (ошибка CS0460: ограничения для методов интерфейсов с переопределением и явной реализацией наследуются от базового метода и поэтому не могут быть заданы явно):
Error CS0460: Constraints for override and explicit interface implementation methods are inherited from the base method, so they cannot be specified directly
Если из метода M<T3, Т4> класса Derived убрать две строки where, код успешно компилируется. Заметьте: разрешается переименовывать параметры типа (в этом примере имя Т1 изменено на ТЗ, а Т2 — на Т4), но изменять (и даже задавать) ограничения нельзя.
Теперь поговорим о различных типах ограничений, которые компилятор и CLR позволяют применять к параметрам типа. К параметру-типу могут применяться следующие ограничения: основное (primary), дополнительное (secondary) и/или ограничение конструктора (constructor constraint). Речь о них идет в следующих трех разделах.
Основные ограничения
В параметре-типе можно задать не более одного основного ограничения. Основным ограничением может быть ссылочный тип, указывающий на незапечатанный класс. Нельзя использовать для этой цели следующие ссылочные типы: System.Object, System.Array, System.Delegate, System.MulticastDelegate, System.ValueType, System.Enum и System.Void.
При задании ограничения ссылочного типа вы гарантируете компилятору, что заданный аргумент-тип будет относиться либо к типу, указанному в ограничении, либо к производному от него типу. Для примера возьмем следующий обобщенный класс:
internal sealed class PrimaryConstraintOfStream<T> where T : Stream { public void M(T stream) { stream.Close();// OK }
В этом определении класса для параметра-типа Т установлено основное ограничение Stream (из пространства имен System. 10), сообщающее компилятору, что код, использующий PrimaryConstraintOfStream, должен задавать аргумент типа Stream или производного от него типа (например, FileStream). Если параметр-тип не задает основное ограничение, автоматически задается тип System.Object. Однако если в исходном тексте явно указать System. Ob j ect, компилятор C# выдаст ошибку (ошибка CS0702: в ограничении не может использоваться специальный класс object):
error CS0702: Constraint cannot be special class 'object'
Есть два особых основных ограничения: class и struct. Ограничение class гарантирует компилятору, что указанный аргумент-тип будет иметь ссылочный тип. Этому ограничению удовлетворяют все типы-классы, типы-интерфейсы, типы- делегаты и типы-массивы, как в следующем обобщенном классе:
internal sealed class PrimaryConstraintOfClass<T> where T : class { public void M() {
T temp = null;// Допустимо, потому что тип Т должен быть ссылочным
>
>
В этом примере присваивание temp значения null допустимо, потому что известно, что Т имеет ссылочный тип, а любая переменная ссылочного типа может быть равна null. При отсутствии у Т ограничений этот код бы не скомпилировал- ся, потому что тип Т мог бы быть значимым, а переменные значимого типа нельзя
приравнять к null.
Ограничение struct гарантирует компилятору, что указанный аргумент типа
будет иметь значимый тип. Этому ограничению удовлетворяют все значимые типы, а также перечисления. Однако компилятор и CLR рассматривают любой значимый тип System.Nullable<T> как особый, и значимые типы с поддержкой null не подходят под это ограничение. Это объясняется тем, что для параметра типа Nullable<T> действует ограничение struct, а среда CLR запрещает такие рекурсивные типы, как Nullable<Nullable<T>>. Значимые типы с поддержкой null обсуждаются в главе 19.
Пример класса, в котором параметр-тип ограничивается ключевым словом struct:
internal sealed class PrimaryConstraintOfStruct<T> where T : struct { public static T FactoryQ {
// Допускается, потому что у каждого значимого типа неявно // есть открытый конструктор без параметров return new Т();
}
}
В этом примере применение к Т оператора new правомерно, потому что известно, что Т имеет значимый тип, а у всех значимых типов неявно есть открытый конструктор без параметров. Если бы тип Т был неограниченным, ограниченным ссылочным
типом или ограниченным классом, этот код не скомпилировался бы, потому что у некоторых ссылочных типов нет открытых конструкторов без параметров.
Дополнительные ограничения
Для параметра-типа могут быть заданы нуль или более дополнительных ограничений. При задании ограничения интерфейсного типа вы гарантируете компилятору, что указанный аргумент-тип будет определять тип, реализующий этот интерфейс. А так как можно задать несколько интерфейсных ограничений, в аргументе типа должен указываться тип, реализующий все интерфейсные ограничения (и все основные ограничения, если они заданы). Подробнее об интерфейсных ограничениях см. главу 13.
Другой тип дополнительных ограничений называют ограничением параметра- типа (type parameter constraint). Оно используется гораздо реже, чем интерфейсные ограничения интерфейса, и позволяет обобщенному типу или методу указать, что аргументы-типы должны быть связаны определенными отношениями. К параметру- типу может быть применено нуль и более ограничений. В следующем обобщенном методе продемонстрировано использование ограничения параметра-типа:
private static List<TBase> ConvertIList<T, TBase>(IList<T> list) where T : TBase {
List<TBase> baseList = new List<TBase>(list.Count); for (Int32 index = 0; index < list.Count; index++) { baseList.Add(list[index]);
}
return baseList;
}
В методе Convert I List определены два параметра-типа, из которых параметр Т ограничен параметром типа TBase. Это значит, что какой бы аргумент-тип ни был задан для Т, он должен быть совместим с аргументом-типом, заданным для TBase. В следующем методе показаны допустимые и недопустимые вызовы ConvertIList:
private static void CallingConvertIList() {
// Создает и инициализирует тип List<String> (реализующий IList<String>) IList<String> Is = new List<String>(); ls.Add("A String");
// Преобразует IList<String> в IList<ObJect>
IList<ObJect> lo = ConvertIListcString, Ob]ect>(ls);
// Преобразует IList<String> в IList<IComparable>
IList<IComparable> lc = ConvertIListcString, IComparable>(Is);
// Преобразует IList<String> в IList<IComparable<String>> IList<IComparable<String>> lcs =
ConvertIListcStringj IComparable<String>>(ls);
// Преобразует IList<String> в IList<String>
 |
IList<String> ls2 = ConvertIListcString, String>(ls);
// Преобразует IList<String> в IList<Exception>
IList<Exception> le = ConvertIListcString, Exception>(ls); // Ошибка
}
В первом вызове ConvertIList компилятор проверяет, чтобы тип String был совместим с Object. Поскольку тип String является производным от Object, первый вызов удовлетворяет ограничению параметра-типа. Во втором вызове ConvertIList компилятор проверяет, чтобы тип String был совместим с IComparable. Поскольку String реализует интерфейс IComparable, второй вызов соответствует ограничению параметра-типа. В третьем вызове ConvertIList компилятор проверяет, чтобы тип String был совместим с IComparable<String>. Так как String реализует интерфейс IComparable<String>, третий вызов соответствует ограничению параметра-типа. В четвертом вызове ConvertIList компилятор знает, что тип String совместим сам с собой. В пятом вызове ConvertIList компилятор проверяет, чтобы тип String был совместим с Exception. Однако так как тип String несовместим с Exception, пятый вызов не соответствует ограничению параметра типа, и компилятор возвращает ошибку (ошибка CS0311: тип string не может использоваться в качестве параметра- типа ' Т' в обобщенном типе или методе Program.ConvertIList<T,TBase>(System. Collectons.Generic .IList<T>). He существует неявного преобразования ссылки из 'string'в 'System.Exception':
error CS0311: The type 'string' cannot be used as type parameter 'T' in the generic type or method Program.ConvertIList<T,TBase>(System.Collections.Ge neric.IList<T>)'. There is no implicit reference conversion from 'string' to 'System.Exception'.
Ограничения конструктора
Для параметра-типа можно задать не более одного ограничения конструктора. Ограничение конструктора гарантирует компилятору, что указанный аргумент-тип будет иметь неабстрактный тип, имеющий открытый конструктор без параметров. Учтите, что компилятор C# считает ошибкой одновременное задание ограничения конструктора и ограничения struct, потому что это избыточно. У всех значимых типов неявно присутствует открытый конструктор без параметров. В следующем классе для параметра-типа использовано ограничение конструктора:
internal sealed class ConstructorConstraint<T> where T : new() { public static T FactoryQ {
// Допустимо, потому что у всех значимых типов неявно
// есть открытый конструктор без параметров, и потому что
// это ограничение требует, чтобы у всех указанных ссылочных типов
// также был открытый конструктор без параметров
return new Т();
}
}
В этом примере применение оператора new к Т допустимо, потому что известно, что Т — это тип с открытым конструктором без параметров. Разумеется, это справедливо для всех значимых типов, а ограничение конструктора требует, чтобы это условие выполнялось и для всех ссылочных типов, заданных в аргументе-типе.
Иногда разработчики предпочитают объявлять параметр типа через ограничение конструктора, при котором сам конструктор принимает различные параметры. На сегодняшний день CLR (и, как следствие, компилятор С#) поддерживает только конструкторы без параметров. По мнению специалистов Microsoft, в большинстве случаев этого вполне достаточно, и я с ними полностью согласен.
Другие проблемы верификации
В оставшейся части этой главы я представлю несколько конструкций, которые из-за проблем с верификацией при использовании обобщений ведут себя непредсказуемо, и покажу, как с помощью ограничений сделать их верифицируемыми.
Приведение переменной обобщенного типа
Приведение переменной обобщенного типа к другому типу допускается только в том случае, если она приводится к типу, совместимому с ограничением:
private static void CastingAGenericTypeVariablel<T>(T obj) {
Int32 x = (Int32) obj ; // Ошибка
String s = (String) obj; // Ошибка
}
Компилятор вернет ошибку для обеих строк, потому что Т может иметь любой тип и успех приведения типа не гарантирован. Чтобы этот код скомпилировался, его нужно изменить, добавив в начале приведение к Object:
private static void CastingAGenericTypeVariable2<T>(T obj) {
Int32 x = (Int32) (Object) obj ; 11 Ошибки нет
String s = (String) (Object) obj; // Ошибки нет
}
Теперь этот код скомпилируется, но во время выполнения CLR все равно может сгенерировать исключение InvalidCastException.
Для приведения к ссылочному типу также применяют оператор as языка С#. В следующем коде он используется с типом String (поскольку Int32 — значимый тип):
private static void CastingAGenericTypeVariable3<T>(T obj) {
String s = obj as String; // Ошибки нет
}
Присваивание переменной обобщенного типа значения по умолчанию
Приравнивание переменной обобщенного типа к null допустимо, только если обобщенный тип ограничен ссылочным типом: private static void SettingAGenericTypeVariableToNull<T>() {
T temp = null; // CS0403: нельзя привести null к параметру типа Т // because it could be a value type...
// (Ошибка CS0403: нельзя привести null к параметру типа T,
// поскольку Т может иметь значимый тип...)
}
Так как параметр типа Т не ограничен, он может иметь значимый тип, а приравнять переменную значимого типа к null нельзя. Если бы параметр типа Т был ограничен ссылочным типом, temp можно было бы приравнять к null, и код скомпилировался бы и работал. При создании C# в Microsoft посчитали, что разработчикам может понадобиться присвоить переменной значение по умолчанию. Для этого в компиляторе C# предусмотрено ключевое слово default:
private static void SettingAGenericTypeVariableToDefaultValue<T>() {
T temp = default(T); // Работает
}
В этом примере ключевое слово default приказывает компилятору C# и JIT- компилятору CLR создать код, приравнивающий temp к null, если Т имеет ссылочный тип, и обнуляющий все биты переменной temp, если Т имеет значимый тип.
Сравнение переменной обобщенного типа с null
Сравнение переменной обобщенного типа с null с помощью операторов == и ! = допустимо независимо от того, ограничен обобщенный тип или нет:
private static void ComparingAGenericTypeVariableWithNull<T>(T obj) { if (obj == null)
{ /* Этот код никогда не исполняется для значимого типа */ }
}
Так как тип Т не ограничен, он может быть ссылочным или значимым. Во втором случае obj нельзя приравнять null. Обычно в этом случае компилятор C# должен выдать ошибку, но этого не происходит — код успешно компилируется. При вызове этого метода с аргументом значимого типа JIT-компилятор, обнаружив, что результат выполнения инструкции if никогда не равен true, просто не сгенерирует машинный код для инструкции if и кода в фигурных скобках. Если бы я использовал оператор ! =, JIT-компилятор также не сгенерировал бы код для инструкции if (поскольку условие всегда истинно), но сгенерировал бы код в фигурных скобках после if.
Кстати, если к Т применить ограничение struct, компилятор C# выдаст ошибку, потому что код, сравнивающий значимый тип с null, не имеет смысла — результат всегда один.
Сравнение двух переменных обобщенного типа
Сравнение двух переменных одинакового обобщенного типа допустимо только в том случае, если обобщенный параметр типа имеет ссылочный тип:
private static void ComparingTwoGenericTypeVariables<T>(T ol, T o2) { if (ol == o2) { } // Ошибка
}
В этом примере у Т нет ограничений, и хотя можно сравнивать две переменные ссылочного типа, сравнивать две переменные значимого типа допустимо лишь в том случае, когда значимый тип перегружает оператор ==. Если у Т есть ограничение class, этот код скомпилируется, а оператор == вернет значение true, если переменные ссылаются на один объект и полностью тождественны. Если параметр Т ограничен ссылочным типом, перегружающим метод operator==, компилятор сгенерирует вызовы этого метода в тех местах, где он встречает оператор ==. Естественно, это относится и к оператору ! =.
При написании кода для сравнения элементарных значимых типов (Byte, Int32, Single, Decimal и т. д.) компилятор C# сгенерирует код правильно, но для непримитивных значимых типов генерировать код сравнения он не умеет. Поэтому если у параметра Т метода ComparingTwoGenericTypeVariables есть ограничение struct, компилятор выдаст ошибку. А ограничивать параметр-тип значимым типом нельзя, потому что они неявно являются запечатанными, а следовательно, не существует типов, производных от значимого типа. Если бы это было разрешено, обобщенный метод будет ограничен конкретным типом; компилятор C# не позволяет это делать, поскольку эффективнее было бы использовать необобщенный метод.
Использование переменных обобщенного типа в качестве операндов
Следует заметить, что использование операторов с операндами обобщенного типа создает немало проблем. В главе 5 я показал, как C# обрабатывает примитивные типы — Byte, Int 16, Int32, Int64, Decimal и др. В частности, я отметил, что C# умеет интерпретировать операторы, применяемые к элементарным типам (например +, * и / ). Однако эти операторы нельзя использовать с переменными обобщенного типа, потому что во время компиляции компилятор не знает их тип. Получается, что нельзя спроектировать математический алгоритм для произвольных числовых типов данных. Допустим, я попытаюсь написать следующий обобщенный метод:
private static T Sum<T>(T num) where T : struct {
T sum = default(T) ;
for (T n = default(T) ; n < num ; n++) sum += n; return sum;
}
Я сделал все возможное, чтобы он скомпилировался: определил ограничение struct для Т и использовал конструкцию default (Т), чтобы sum и п инициализировались нулем. Но при компиляции кода выдаются три сообщения об ошибках:
□ ошибка CS0019: оператор < нельзя применять к операндам типа Т и Т:
error CS0019: Operator '<' cannot be applied to operands of type 'T' and 'T'
□ ошибка CS0023: оператор ++ нельзя применять к операнду типа Т:
error CS0023: Operator '++' cannot be applied to operand of type 'T'
□ ошибка CS0019: оператор += нельзя применять к операндам типа Т и Т:
error CS0019: Operator '+=' cannot be applied to operands of type 'T' and 'T'
Это существенно ограничивает поддержку обобщений в среде CLR, и многие разработчики (особенно из научных, финансовых и математических областей) испытали глубокое разочарование. Многие пытались создать методы, призванные обойти это ограничение, прибегая к отражению (см. главу 23), примитивному типу dynamic (см. главу 5), перегрузке операторов и т. п. Однако все эти решения сильно снижают производительность или ухудшают читабельность кода. Остается надеяться, что в следующих версиях CLR и компиляторов компания Microsoft устранит этот недостаток.
Глава 13. Интерфейсы
Многие программисты знакомы с концепцией множественного наследования (multiple inheritance) — возможности определения класса, производного от двух или более базовых классов. Допустим, имеется класс ТnansmitData, предназначенный для передачи данных, и класс ReceiveData, обеспечивающий получение данных. Допустим, нужно создать класс SocketPort, который может и получать, и передавать данные. Для этого класс SocketPort должен наследовать одновременно от обоих классов: TransmitData и ReceiveData.
Некоторые языки программирования разрешают множественное наследование, позволяя создать класс SocketPort, производный от двух базовых классов. Однако CLR (а значит, и все основанные на этой среде языки программирования) множественное наследование не поддерживает. Вместе с тем CLR позволяет реализовать ограниченное множественное наследование через интерфейсы (interfaces). В этой главе рассказывается об определении и применении интерфейсов, а также приводятся основные правила, позволяющие понять, когда уместно использовать интерфейсы, а не базовые классы.
Наследование в классах и интерфейсах
В .NET Framework есть класс System.Object, в котором определено 4 открытых экземплярных метода: ToString, Equals, GetHashCode nGetType. Этот класс является корневым базовым классом для всех остальных классов, поэтому все классы наследуют эти четыре метода класса Object. Это также означает, что код, оперирующий экземпляром класса Object, в действительности может выполнять операции с экземп.чяром любого класса.
Любой производный от Object класс наследует:
□ Сигнатуры методов. Это позволяет коду считать, что он оперирует экземпляром класса Object, тогда как на самом деле он работает с экземпляром какого-либо другого класса.
□ Реализацию этих методов. Разработчик может определить класс, производный от Object, не реализуя методы класса Object вручную.
В CLR у класса может быть один и только один прямой «родитель» (который прямо или опосредованно наследует от класса Object). Базовый класс предоставляет набор сигнатур и реализации этих методов. При этом новый класс может стать базовым для другого класса, который будет определен другим разработчиком, и при этом новый производный класс унаследует все сигнатуры методов и их реализации.
CLR также позволяет определить интерфейс, который, в сущности, представляет собой средство назначения имени набору сигнатур методов. Интерфейс не содержит реализаций методов. Класс наследует интерфейс через указание имени последнего, причем этот класс должен явно содержать реализации интерфейсных методов — иначе CLR посчитает определение типа недействительным. Конечно, реализация интерфейсных методов — обычно довольно утомительное занятие, поэтому я и назвал наследование интерфейсов ограниченным механизмом реализации множественного наследования. Компилятор C# и CLR позволяют классу наследовать от нескольких интерфейсов, и, конечно же, класс при этом должен реализовать все унаследованные методы интерфейсов.
Одна из замечательных особенностей наследования классов — возможность подстановки экземпляров производного типа в любые контексты, в которых выступают экземпляры базового типа. Аналогичным образом наследование от интерфейсов позволяет подставлять экземпляры типа, реализующего интерфейс, во все контексты, где требуются экземпляры указанного интерфейсного типа. Чтобы наше обсуждение стало более конкретным, давайте посмотрим, как определяются интерфейсы.
Определение интерфейсов
Как упоминалось ранее, интерфейс представляет собой именованный набор сигнатур методов. Обратите внимание, что в интерфейсах можно также определять события, свойства — без параметров или с ними (последние в C# называют индексаторами), поскольку все это просто упрощенные средства синтаксиса, которые в конечном итоге все равно соответствуют методам. Однако в интерфейсе нельзя определять ни конструкторы, ни экземплярные поля.
Хотя CLR допускает наличие в интерфейсах статических методов, статических полей и конструкторов, а также констант, CLS-совместимый интерфейс не может иметь подобных статических членов, поскольку некоторые языки не поддерживают их определение или обращение к ним. C# не позволяет определять в интерфейсе статические члены.
В C# для определения интерфейса, назначения ему имени и набора сигнатур экземплярных методов используется ключевое слово interface. Вот определения некоторых интерфейсов из библиотеки классов Framework Class Library:
public interface IDisposable { void Dispose();
}
public interface IEnumerable {
IEnumerator GetEnumeratorQ;
} public interface IEnumerable<T> : IEnumerable {
IEnumerator<T> GetEnumerator();
>
public interface ICollection<T> : 1ЕпитегаЬ1е<Т>, IEnumerable { void Add(T item); void Clear();
Boolean Contains(T item);
void CopyTo(T[] array, Int32 arraylndex);
Boolean Remove(T item);
Int32 Count { get; } // Свойство только для чтения
Boolean IsReadOnly { get; } // Свойство только для чтения
>
С точки зрения CLR, определение интерфейса — почти то же, что и определение типа. То есть CLR определяет внутреннюю структуру данных для объекта интерфейсного типа, а для обращения к различным членам интерфейса может использовать отражение. Как и типы, интерфейс может определяться на уровне файлов или быть вложенным в другой тип. При определении интерфейсного типа можно указать требуемую область видимости и доступа (public, protected, internal и т. и.).
В соответствии с соглашением имена интерфейсных типов начинаются с прописной буквы I, что облегчает их поиск в исходном коде. CLR поддерживает обобщенные интерфейсы (как показано в некоторых предыдущих примерах) и интерфейсные методы. В этой главе я лишь слегка касаюсь некоторых возможностей обобщенных интерфейсов, детали см. в главе 12.
Определение интерфейса может «наследовать» другие интерфейсы. Однако слово «наследовать» не совсем точное, поскольку в интерфейсах наследование работает иначе, чем в классах. Я предпочитаю рассматривать наследование интерфейсов как включение контрактов других интерфейсов. Например, определение интерфейса TCollection<T> включает контракт интерфейсов TEnumerable<T> и IEnumerable. Это означает следующее:
□ любой класс, наследующий интерфейс ICollection<T>, должен реализовать все методы, определенные в интерфейсах ICollection<T>, IEnumerable<T> иIEnumerable;
□ любой код, ожидающий объект, тип которого реализует интерфейс ICollection<T>, может быть уверен в том, что тип объекта также реализует методы интерфейсов IEnumerable<T> иIEnumerable.
Наследование интерфейсов
Сейчас я покажу, как определить тип, реализующий интерфейс, создать экземпляр этого типа и использовать полученный объект для вызова интерфейсных методов. В C# это делается очень просто, внутренняя реализация чуть сложнее, но об этом — немного позже.
Интерфейс System.IComparable<T> определяется так (в MSCorl_ib.dll):
public interface IComparable<T> {
Int32 CompareTo(T other);
}
Следующий код демонстрирует, как определить тип, реализующий этот интерфейс, и код, сравнивающий два объекта Point:
using System;
// Объект Point является производным от System.Object // и реализует IComparable<T> в Point public sealed class Point : IComparable<Point> { private Int32 m_x, m_y;
public Point(Int32 x, Int32 y) { m_x = x; m_y = y;
}
// Этот метод реализует IComparable<T> в Point public Int32 CompareTo(Point other) {
return Math.Sign(Math.Sqrt(m_x * m_x + m_y * m_y)
- Math.Sqrt(other.m_x * other.m_x + other.m_y * other.m_y));
}
public override String ToStringO {
return String.Format("({0}, {1})", m_x, m_y);
}
public static class Program { public static void Main() { Point[] points = new Point[] { new Point(3, 3), new Point(l, 2),
}■>
// Вызов метода CompareTo интерфейса IComparable<T> объекта Point if (points[0].CompareTo(points[l]) > 0) {
Point tempPoint = points[0]; points[0] = points[l]; points[l] = tempPoint;
}
Console.WriteLine("Points from closest to (0, 0) to farthest:"); foreach (Point p in points)
Console.WriteLine(p);
}
Компилятор C# требует, чтобы метод, реализующий интерфейс, отмечался модификатором public. CLR требует, чтобы интерфейсные методы были виртуаль
ными. Если метод явно не определен в коде как виртуальный, компилятор сделает его таковым и, вдобавок, запечатанным. Это не позволяет производному классу переопределять интерфейсные методы. Если явно задать метод как виртуальный, компилятор сделает его таковым и оставит незапечатанным, что предоставит производному классу возможность переопределять интерфейсные методы.
Производный класс не в состоянии переопределять интерфейсные методы, объявленные запечатанными, но может повторно унаследовать тот же интерфейс и предоставить собственную реализацию его методов. При вызове интерфейсного метода объекта вызывается реализация, связанная с типом самого объекта. Следующий пример демонстрирует это:
using System;
public static class Program { public static void Main() {
Base b = new Base();
// Вызов реализации Dispose в типе b: "Dispose класса Base" b.DisposeQ;
// Вызов реализации Dispose в типе объекта b: "Dispose класса Base"
((IDisposable)b). DisposeQ;
В TO рОИ ПрИМ0р
Derived d = new Derived();
// Вызов реализации Dispose в типе d: "Dispose класса Derived" d.DisposeQ;
// Вызов реализации Dispose в типе объекта d: "Dispose класса Derived"
((IDisposable)d).Dispose();
I************************ * Третий пример *************************/ b = new DerivedQ;
// Вызов реализации Dispose в типе b: "Dispose класса Base" b.DisposeQ;
// Вызов реализации Dispose в типе объекта b: "Dispose класса Derived" ((IDisposable)b) .DisposeQ;
}
}
// Этот класс является производным от Object и реализует IDisposable internal class Base : IDisposable {
// Этот метод неявно запечатан и его нельзя переопределить public void DisposeQ {
Console.WriteLine("Base’s Dispose");
}
}
// Этот класс наследует от Base и повторно реализует IDisposable internal class Derived : Base, IDisposable {
// Этот метод не может переопределить Dispose из Base.
// Ключевое слово 'new' указывает на то, что этот метод // повторно реализует метод Dispose интерфейса IDisposable new public void Dispose() {
Console.WriteLine(nDerived's Dispose");
// ПРИМЕЧАНИЕ: следующая строка кода показывает,
// как вызвать реализацию базового класса (если нужно)
// base.DisposeQ;
>
>
Подробнее о вызовах интерфейсных методов
Тип System.String из библиотеки FCL наследует сигнатуры и реализации методов System.Object. Кроме того, тип String реализует несколько интерфейсов: IComparable, ICloneable, [[Convertible, IEnumerable, IComparable<String>, IEnumerable<Char> и IEquatable<String>. Это значит, что типу String не требуется реализовывать (или переопределять) методы, имеющиеся в его базовом типе Object. Однако тип String должен реализовывать методы, объявленные во всех интерфейсах.
CLR допускает определение полей, параметров или локальных переменных, имеющих интерфейсный тип. Используя переменную интерфейсного типа, можно вызывать методы, определенные этим интерфейсом. К тому же CLR позволяет вызывать методы, определенные в типе Object, поскольку все классы наследуют его
методы, как продемонстрировано в следующем коде:
// Переменная s ссылается на объект String String s = "leffrey";
// Используя переменную s, можно вызывать любой метод,
// определенный в String, Object, IComparable, ICloneable,
// IConvertible, IEnumerable и т. д.
// Переменная cloneable ссылается на тот же объект String ICloneable cloneable = s;
// Используя переменную cloneable, я могу вызвать любой метод,
// объявленный только в интерфейсе ICloneable (или любой метод,
// определенный в типе Object)
// Переменная comparable ссылается на тот же объект String IComparable comparable = s;
// Используя переменную comparable, я могу вызвать любой метод,
// объявленный только в интерфейсе IComparable (или любой метод,
// определенный в типе Object) // Переменная enumerable ссылается на тот же объект String
// Во время выполнения можно приводить интерфейсную переменную
// к интерфейсу другого типа; если тип объекта реализует оба интерфейса
IEnumerable enumerable = (IEnumerable) comparable;
// Используя переменную enumerable; я могу вызывать любой метод;
// объявленный только в интерфейсе IEnumerable (или любой метод;
// определенный только в типе Object)
Все переменные в этом коде ссылаются на один объект String в управляемой куче, а значит, любой метод, который я вызываю с использованием любой из этих переменных, задействует один объект String, хранящий строку "Jeffrey". Но тип переменной определяет действие, которое я могу выполнить с объектом. Переменная s имеет тип String, значит, она позволяет вызвать любой член, определенный в типе String (например, свойство Length). Переменную s можно также использовать для вызова любых методов, унаследованных от типа Object (например, GetType).
Переменная cloneable имеет тип интерфейса ICloneable, а значит, позволяет вызывать метод Clone, определенный в этом интерфейсе. Кроме того, можно вызвать любой метод, определенный в типе Object (например, GetType), поскольку CLR «знает», что все типы являются производными от Object. Однако переменная cloneable не позволяет вызывать открытые методы, определенные в любом другом интерфейсе, реализованном типом String. Аналогичным образом через переменную comparable можно вызвать CompareTo или любой метод, определенный в типе Object, но не другие методы.
ВНИМАНИЕ
Как и ссылочный тип, значимый тип может реализовать несколько (или нуль) интерфейсов. Но при приведении экземпляра значимого типа к интерфейсному типу этот экземпляр надо упаковать, потому что интерфейсная переменная является ссылкой, которая должна указывать на объект в куче, чтобы среда CLR могла проверить указатель и точно выяснить тип объекта. Затем при вызове метода интерфейса с упакованным значимым типом CLR использует указатель, чтобы найти таблицу методов типа объекта и вызвать нужный метод.
Явные и неявные реализации интерфейсных методов (что происходит за кулисами)
Когда тип загружается в CLR, для него создается и инициализируется таблица методов (см. главу 1). Она содержит по одной записи для каждого нового, представляемого только этим типом метода, а также записи для всех виртуальных методов, унаследованных типом. Унаследованные виртуальные методы включают методы, определенные в базовых типах иерархии наследования, а также все методы, определенные интерфейсными типами. Допустим, имеется простое определение типа:
internal sealed class SimpleType : IDisposable {
public void Dispose() { Console.WriteLine("Disposen); }
>
Тогда таблица методов типа содержит записи, в которых представлены:
□ все экземплярные методы, определенные в типе Object и неявно унаследованные от этого базового класса;
□ все интерфейсные методы, определенные в явно унаследованном интерфейсе IDisposable (в нашем примере в интерфейсе IDisposable определен только один метод — Dispose);
□ новый метод, Dispose, появившийся в типе SimpleType.
Чтобы упростить жизнь программиста, компилятор C# считает, что появившийся в типе SimpleType метод Dispose является реализацией метода Dispose из интерфейса IDisposable. Компилятор C# вправе сделать такое предположение, потому что метод открытый, а сигнатуры интерфейсного метода и нового метода совпадают. Значит, методы принимают и возвращают одинаковые типы. Кстати, если бы новый метод Dispose был помечен как виртуальный, компилятор C# все равно сопоставил бы этот метод с одноименным интерфейсным методом.
Сопоставляя новый метод с интерфейсным методом, компилятор C# генерирует метаданные, указывающие на то, что обе записи в таблице методов типа SimpleType должны ссылаться на одну реализацию. Чтобы вам стало понятнее, следующий код демонстрирует вызов открытого метода Dispose класса, а также вызов реализации класса для метода Dispose интерфейса IDisposable.
public sealed class Program { public static void MainQ {
SimpleType st = new SimpleTypeQ;
11 Вызов реализации открытого метода Dispose st. DisposeQ;
11 Вызов реализации метода Dispose интерфейса IDisposable IDisposable d = st; d.DisposeQ;
}
В первом вызове выполняется обращение к методу Dispose, определенному в типе SimpleType. Затем я определяю переменную d интерфейсного типа IDisposable. Я инициализирую переменную d ссылкой на объект SimpleType. Теперь при вызове d .DisposeQ выполняется обращение к методу Dispose интерфейса IDisposable. Так как C# требует, чтобы открытый метод Dispose тоже был реализацией для метода Dispose интерфейса IDisposable, будет выполнен тот же код, и в этом примере вы не заметите какой-либо разницы. На выходе получим следующее:
Dispose
Dispose
Теперь мы перепишем SimpleType, чтобы можно было увидеть разницу:
internal sealed class SimpleType : IDisposable {
public void Dispose() { Console.WriteLine("public Dispose"); }
void IDisposable.DisposeQ { Console.Writel_ine( "IDisposable Dispose"); }
>
He вызывая метод Main, мы можем просто перекомпилировать и запустить заново программу, и на выходе получим следующее:
public Dispose IDisposable Dispose
Если в C# перед именем метода указано имя интерфейса, в котором определен этот метод (в нашем примере — IDisposable. Dispose), то вы создаете явную реализацию интерфейсного метода (Explicit Interface Method Implementation, EIMI). Заметьте: при явной реализации интерфейсного метода в C# нельзя указывать уровень доступа (открытый или закрытый). Однако когда компилятор создает метаданные для метода, он назначает ему закрытый уровень доступа (private), что запрещает любому коду использовать экземпляр класса простым вызовом интерфейсного метода. Единственный способ вызвать интерфейсный метод — обратиться через переменную этого интерфейсного типа.
Обратите внимание на то, что EIMI-метод не может быть виртуальным, а значит, его нельзя переопределить. Это происходит потому, что EIMI-метод в действительности не является частью объектной модели типа; это всего лишь средство связывания интерфейса (набора вариантов поведения, или методов) с типом. Если такой подход кажется вам немного неуклюжим, значит, вы все поняли правильно. Далее в этой главе я опишу некоторые действенные причины для использования EIMI.
Обобщенные интерфейсы
Поддержка обобщенных интерфейсов в C# и CLR открывает перед разработчиками много интересных возможностей. В этом разделе рассказывается о преимуществах обобщенных интерфейсов.
Во-первых, обобщенные интерфейсы обеспечивают безопасность типов на стадии компиляции. Некоторые интерфейсы (такие, как необобщенный IComparable) определяют методы, которые принимают или возвращают параметры типа Object. При вызове в коде методов таких интерфейсов можно передать ссылку на экземпляр любого типа, однако обычно это нежелательно. Приведем пример:
private void SomeMethodl() {
Int32 x = 1, у = 2;
IComparable с = x;
// CompareTo ожидает Object,
11 но вполне допустимо передать переменную у типа Int32 с.CompareTo(у); // Выполняется упаковка
// CompareTo ожидает Object,
// при передаче "2" (тип String) компиляция выполняется нормально, // но во время выполнения генерируется исключение ArgumentException с.CompareTo("2");
}
Ясно, что желательно обеспечить более строгий контроль типов в интерфейсном методе, поэтому в FCL включен обобщенный интерфейс IComparable<T>. Вот новая версия кода, измененная с учетом использования обобщенного интерфейса:
private void SomeMethod2() {
Int32 x = 1, у = 2;
IComparable<Int32> с = x;
// CompareTo ожидает Object,
// но вполне допустимо передать переменную у типа Int32 с.CompareTo(у); // Выполняется упаковка
// CompareTo ожидает Int32,
// передача "2" (тип String) приводит к ошибке компиляции // с сообщением о невозможности привести тип String к Int32 c.CompareTo("2"); // Ошибка
}
Второе преимущество обобщенных интерфейсов заключается в том, что при работе со значимыми типами требуется меньше операций упаковки. Заметьте: в SomeMethodl необобщенный метод CompareTo интерфейса IComparable ожидает переменную типа Object; передача переменной у (значимый тип Int32) приводит к упаковке значения у. В SomeMethod2 метод CompareTo обобщенного интерфейса IComparable<T> ожидает Int32; передача у выполняется по значению, поэтому упаковка не требуется.
ПРИМЕЧАНИЕ
В FCI-Определены необобщенные и обобщенные версии интерфейсов IComparable, ICollection, IList, IDictionary и некоторых других. Если вы определяете тип и хотите реализовать любой из этих интерфейсов, обычно лучше выбирать обобщенные версии. Необобщенные версии оставлены в FCLAnq обратной совместимости с кодом, написанным до того, как в .NET Framework появилась поддержка обобщений. Необобщенные версии также предоставляют пользователям механизм работы сданными более универсальным, но и менее безопасным образом.
Некоторые обобщенные интерфейсы происходят от необобщенных версий, так что в классе приходится реализовывать как обобщенную, таки необобщенную версии. Например, обобщенный интерфейс IEnumerable<T> наследует от необобщенного интерфейса Enumerable. Так что если класс реализует IEnumerable<T>, он должен также реализовать Enumerable.
Иногда, при необходимости интеграции с другим кодом, приходится реализовывать необобщенный интерфейс просто потому, что необобщенной версии не существует. В этом случае, если любой из интерфейсных методов принимает или возвращает тип Object, теряется безопасность типов при компиляции, и значимые типы должны упаковываться. Можно в некоторой степени исправить эту ситуацию, действуя так, как описано далее в разделе «Совершенствование безопасности типов за счет явной реализации интерфейсных методов».
Третье преимущество обобщенных интерфейсов заключается в том, что класс может реализовать один интерфейс многократно, просто используя параметры различного типа. Следующий пример показывает, как это бывает удобно:
using System;
// Этот класс реализует обобщенный интерфейс IComparable<T> дваады public sealed class Number: IComparable<Int32>, IComparable<String> { private Int32 m_val = 5;
// Этот метод реализует метод CompareTo интерфейса IComparable<Int32> public Int32 CompareTo(Int32 n) { return mval.CompareTo(n);
}
// Этот метод реализует метод CompareTo интерфейса IComparable<String> public Int32 CompareTo(String s) {
return m_val.CompareTo(Int32.Parse(s));
}
}
public static class Program { public static void Main() {
Number n = new NumberQ;
// Значение n сравнивается со значением 5 типа Int32 IComparable<Int32> clnt32 = n;
Int32 result = cInt32.CompareTo(5);
// Значение n сравнивается со значением "5" типа String IComparable<String> cString = n; result = cString.CompareTo("5");
}
Параметры интерфейса обобщенного типа могут быть также помечены как контравариантые или ковариантные, что позволяет более гибко использовать интерфейсы. Подробнее о контравариантности и ковариантности рассказывается в главе 12.
Обобщения и ограничения интерфейса
В предыдущем разделе были описаны преимущества обобщенных интерфейсов. В этом разделе речь пойдет о пользе ограничения параметров-типов таких интерфейсов.
Первое преимущество состоит в том, что параметр-тип можно ограничить несколькими интерфейсами. В этом случае тип передаваемого параметра должен реализовывать все ограничения. Вот пример:
public static class SomeType { private static void Test() {
Int32 x = 5;
Guid g = new Guid();
// Компиляция этого вызова M выполняется без проблем,
// поскольку Int32 реализует и IComparable, и IConvertible М(х);
// Компиляция этого вызова М приводит к ошибке, поскольку // Guid реализует IComparable, но не реализует IConvertible M(gB
}
// Параметр Т типа М ограничивается только теми типами,
// которые реализуют оба интерфейса: IComparable И IConvertible private static Int32 M<T>(T t) where T : IComparable, IConvertible {
}
}
Замечательно! При определении параметров метода каждый тип параметра указывает, что передаваемый аргумент должен иметь заданный тип или быть производным от него. Если типом параметра является интерфейс, аргумент может относиться к любому типу класса, реализующему заданный интерфейс. Использование нескольких ограничений интерфейса позволяет методу указывать, что передаваемый аргумент должен реализовывать несколько интерфейсов.
На самом деле, ограничивая Т классом и двумя интерфейсами, мы говорим, что типом передаваемого аргумента должен быть указанный базовый класс (или производный от него), а также что он должен реализовывать оба интерфейса. Такая гибкость позволяет методу диктовать условия вызывающему коду, а при невыполнении установленных ограничений возникают ошибки компиляции.
Второе преимущество ограничений интерфейса — избавление от упаковки при передаче экземпляров значимых типов. В предыдущем фрагменте кода методу М передавался аргумент х (экземпляр типа Int32, то есть значимого типа). При передаче х в М упаковка не выполнялась. Если код методам вызовет t.CompareTo(...), то упаковка при вызове также не будет выполняться (упаковка может выполняться для аргументов, передаваемых CompareTo).
В то же время если М объявляется следующим образом, то для передачи х в М придется выполнять упаковку:
private static Int32 M(IComparable t) {
}
Для ограничений интерфейсов компилятор C# генерирует определенные IL- инструкции, которые вызывают интерфейсный метод для значимого типа напрямую, без упаковки. Кроме использования ограничений интерфейса нет другого способа заставить компилятор C# генерировать такие IL-инструкции; следовательно, во всех других случаях вызов интерфейсного метода для значимого типа всегда приводит к упаковке.
Реализация нескольких интерфейсов с одинаковыми сигнатурами и именами методов
Иногда нужно определить тип, реализующий несколько интерфейсов с методами, у которых совпадают имена и сигнатуры. Допустим, два интерфейса определены
следующим образом:
public interface IWindow {
Object GetMenuQ;
}
public interface IRestaurant {
Object GetMenuQ;
}
Требуется определить тип, реализующий оба этих интерфейса. В этом случае нужно реализовать члены типа путем явной реализации методов:
// Этот тип является производным от System.Object
// и реализует интерфейсы IWindow и IRestaurant
public sealed class MarioPizzeria : IWindow, IRestaurant {
// Реализация метода GetMenu интерфейса IWindow Object IWindow.GetMenu() { ... }
// Реализация метода GetMenu интерфейса IRestaurant Object IRestaurant.GetMenu() { ... }
// Метод GetMenu (необязательный),
// не имеющий отношения к интерфейсу public Object GetMenuQ { ... }
Так как этот тип должен реализовывать несколько различных методов GetMenu, нужно сообщить компилятору С#, какой из методов GetMenu реализацию для конкретного интерфейса.
Код, в котором используется объект MarioPizzeria, должен выполнять приведение типа к определенному интерфейсу для вызова нужного метода:
MarioPizzeria mp = new MarioPizzeria();
11 Эта строка вызывает открытый метод GetMenu класса MarioPizzeria mp.GetMenuQ;
// Эти строки вызывают метод IWindow.GetMenu IWindow window = mp; window. GetMenuQ;
// Эти строки вызывают метод IRestaurant.GetMenu IRestaurant restaurant = mp; restaurant.GetMenu();
Совершенствование безопасности типов за счет явной реализации интерфейсных методов
Интерфейсы очень удобны, так как они определяют стандартный механизм взаимодействия между типами. Ранее я говорил об обобщенных интерфейсах и о том, как они повышают безопасность типов при компиляции и позволяют избавиться от упаковки. К сожалению, иногда приходится реализовывать необобщенные интерфейсы, поскольку обобщенной версии попросту не существует. Если какой-либо из интерфейсных методов принимает параметры типа System. Object или возвращает значение типа System.Object, безопасность типов при компиляции нарушается и выполняется упаковка. В этом разделе я показываю, как за счет явной реализации интерфейсных методов (EIMI) можно несколько улучшить ситуацию.
Вот очень часто используемый интерфейс IComparable:
public interface IComparable {
Int32 CompareTo(Object other);
>
В этом интерфейсе определяется единственный метод, который принимает параметр типа System.Object. Если я определю собственный тип, реализующий этот интерфейс, определение типа будет выглядеть примерно так:
internal struct SomeValueType : IComparable { private Int32 m_x;
public SomeValueType(Int32 x) { m_x = x; } public Int32 CompareTo(Object other) {
return(m_x _ ((SomeValueType) other).m_x);
>
Используя SomeValueType, я могу написать следующий код:
public static void Main() {
SomeValueType v = new SomeValueType(0);
Object о = new ObjectQ;
Int32 n = v.CompareTo(v); 11 Нежелательная упаковка n = v.CompareTo(o); // Исключение InvalidCastException
>
Этот код нельзя назвать идеальным по двум причинам:
□ нежелательная упаковка — когда переменная v передается в качестве аргумента методу CompareTo, она должна упаковываться, поскольку CompareTo ожидает параметр типа Object;
□ отсутствие безопасности типов — компиляция кода выполняется без проблем, но когда метод CompareTo пытается привести other к типу SomeValueType, возникает исключение InvalidCastException.
Оба недостатка можно исправить средствами EIMI. Вот модифицированная версия типа SomeValueType, в которой имеет место явная реализация интерфейсных методов:
internal struct SomeValueType : IComparable { private Int32 m_x;
public SomeValueType(Int32 x) { m_x = x; }
public Int32 CompareTo(SomeValueType other) { return(m_x _ other.m_x);
}
// ПРИМЕЧАНИЕ: в следующей строке не используется public/private Int32 IComparable.CompareTo(Object other) { return CompareTo((SomeValueType) other);
}
}
Обратите внимание на некоторые изменения в новой версии. Во-первых, здесь два метода CompareTo. Первый больше не принимает параметр типа Object, а принимает параметр типа SomeValueType. Поскольку параметр изменился, код, выполняющий приведение other к типу SomeValueType, стал ненужным и был удален. Во-вторых, изменение первого метода CompareTo для обеспечения безопасности типов приводит к тому, что SomeValueType больше не придерживается контракта, обусловленного реализацией интерфейса IComparable. Поэтому в SomeValueType нужно реализовать метод CompareTo, удовлетворяющий контракту IComparable. Этим занимается второй метод CompareTo, который использует механизм явной реализации интерфейсных методов.
Эти два изменения обеспечили безопасность типов при компиляции и избавили от упаковки:
public static void Main() {
SomeValueType v = new SomeValueType(0);
Object о = new ObjectQj
Int32 n = v.CompareTo(v); // Без упаковки
n = v.CompareTo(o); // Ошибка компиляции
>
Однако если определить переменную интерфейсного типа, то мы потеряем безопасность типов при компиляции и опять вернемся к упаковке:
public static void Main() {
SomeValueType v = new SomeValueType(0);
IComparable c = v; // Упаковка!
Object о = new ObjectQj
Int32 n = c.CompareTo(v); // Нежелательная упаковка n = c.CompareTo(o); // Исключение InvalidCastException
>
Как уже отмечалось, при приведении экземплярного типа к интерфейсному среда CLR должна упаковывать экземпляр значимого типа. Поэтому в приведенном методе Main выполняются две упаковки.
К EIMI часто прибегают при реализации таких интерфейсов, как IConvertible, ICollection, IList и IDictionary. Это позволяет обеспечить в интерфейсных методах безопасность типов при компиляции и избавиться от упаковки значимых типов.
Опасности явной реализации интерфейсных методов
Очень важно понимать некоторые особенности EIMI, из-за которых следует избегать явной реализации интерфейсных методов везде, где это возможно. К счастью, в некоторых случаях вместо EIMI можно обойтись обобщенными интерфейсами. Но все равно остаются ситуации, когда без EIMI не обойтись (например, при реализации двух интерфейсных методов с одинаковыми именами и сигнатурами). С явной реализацией интерфейсных методов связаны некоторые серьезные проблемы (далее я расскажу о них подробнее):
□ отсутствие документации, объясняющей, как именно тип реализует EIMI-метод, а также отсутствие IntelliSense-поддержки в Microsoft Visual Studio;
□ при приведении к интерфейсному типу экземпляры значимого типа упаковываются;
□ EIMI нельзя вызвать из производного типа.
В описаниях методов типа в справочной документации .NET Framework можно найти сведения о явной реализации методов интерфейсов, но справка по конкретным типам отсутствует — доступна только общая информация об интерфейсных методах. Например, о типе Int32 говорится, что он реализует все методы интерфейса IConvertible. И это хорошо, потому что разработчик знает, что такие методы существуют; с другой стороны, эта информация может создать проблемы, потому что вызвать метод интерфейса inconvertible для Int32 напрямую нельзя. Например, следующий метод не скомпилируется.
public static void Main() {
Int32 x = 5;
Single s = x.ToSingle(null); // Попытка вызвать метод
11 интерфейса IConvertible
>
При компиляции этого метода компилятор C# вернет следующую ошибку (ошибка CS0117: int не содержит определения для ToSingle):
error CS0117: 'int' does not contain a definition for 'ToSingle'
Это сообщение об ошибке лишь запутывает разработчика; в нем утверждается, что в типе Int32 метод ToSingle не определен, хотя на самом деле это неправда.
Чтобы вызвать метод ToSingle типа Int32, сначала следует привести его к типу IConvertible:
public static void Main() {
Int32 x = 5;
Single s = ((IConvertible) x).ToSingle(null);
}
Требование приведения типа далеко не очевидно, многие разработчики не могут самостоятельно до этого додуматься. Но на этом проблемы не заканчиваются — при приведении значимого типа Int32 к интерфейсному типу IConvertible значимый тип упаковывается, что приводит к лишним затратам памяти и снижению производительности. Это вторая серьезная проблема.
Третья и, наверное, самая серьезная проблема с EIMI состоит в том, что явная реализация интерфейсного метода не может вызываться из производного класса. Вот пример:
internal class Base : IComparable {
// Явная реализация интерфейсного метода (EIMI)
Int32 IComparable.CompareTo(Ob]ect о) {
Console.WriteLine("Base's CompareTo"); return в;
}
}
internal sealed class Derived : Base, IComparable {
// Открытый метод, также являющийся реализацией интерфейса public Int32 CompareTo(ObJect о) {
Console.WriteLine("Derived1s CompareTo");
// Эта попытка вызвать EIMI базового класса приводит к ошибке:
// "error CS0117: 'Base' does not contain a definition for ■CompareTo1"
base.CompareTo(o);
return 0;
}
}
В методе CompareTo типа Derived я попытался вызвать base. CompareTo, но это привело к ошибке компилятора С#. Проблема заключается в том, что в классе Base нет открытого или защищенного метода CompcareTo, который он мог бы вызвать. Есть метод CompareTo, который можно вызвать только через переменную типа IComparable. Я мог бы изменить метод CompareTo класса Derived следующим образом:
// Открытый метод, который также является реализацией интерфейса public Int32 CompareTo(Object о) {
Console.WriteLine("Derived1s CompareTo");
// Эта попытка вызова EIMI базового класса приводит // к бесконечной рекурсии IComparable с = this; с.CompareTo(o);
return в;
}
В этой версии я привожу this к типу переменной с (типу IComparable), а затем использую с для вызова CompareTo. Однако открытый метод CompareTo класса Derived является реализацией метода CompareTo интерфейса IComparable класса Derived, поэтому возникает бесконечная рекурсия. Ситуацию можно исправить, объявив класс Derived без интерфейса IComparable: internal sealed class Derived : Base /*, IComparable */ { ... }
Теперь предыдущий метод CompareTo вызовет метод CompareTo класса Base. Однако не всегда можно просто удалить интерфейс из типа, поскольку производный тип должен реализовывать интерфейсный метод. Лучший способ исправить ситуацию — в дополнение к явно реализованному интерфейсному методу создать в базовом классе виртуальный метод, который будет реализовываться явно. Затем в классе Derived можно переопределить виртуальный метод. Вот как правильно определять классы Base и Derived: internal class Base : IComparable {
// Явная реализация интерфейсного метода (EIMI)
Int32 IComparable.CompareTo(Object о) {
Console.WriteLine("Base" s IComparable CompareTo11); return CompareTo(o); // Теперь здесь вызывается виртуальный метод >
// Виртуальный метод для производных классов // (этот метод может иметь любое имя) public virtual Int32 CompareTo(Object о) {
Console.WriteLine(nBase's virtual CompareTo"); return 0;
>
>
internal sealed class Derived : Base, IComparable {
// Открытый метод, который также является реализацией интерфейса public override Int32 CompareTo(Object о) {
Console.WriteLine("Derived1s CompareTo");
11 Теперь можно вызвать виртуальный метод класса Base return base.CompareTo(о);
}
Заметьте: я определил виртуальный метод как открытый, но в некоторых случаях лучше сделать его защищенным. Это вполне возможно, хотя и потребует небольших изменений.
Как видите, к явной реализации интерфейсных методов нужно прибегать с осторожностью. Когда разработчики впервые узнали о EIMI, многие посчитали это отличной новостью и стали пытаться выполнять явную реализацию интерфейсных методов везде, где только можно. Не попадайтесь на эту удочку! Явная реализация интерфейсных методов полезна в лишь некоторых случаях, но ее следует избегать везде, где можно обойтись другими средствами.
Дилемма разработчика: базовый класс или интерфейс?
Меня часто спрашивают, что лучше выбирать для проектировании типа — базовый тип или интерфейс? Ответ не всегда очевиден. Вот несколько правил, которые могут помочь вам сделать выбор.
□ Связь потомка с предком. Любой тип может наследовать только одну реализацию. Если производный тип не может ограничиваться отношением типа «является частным случаем» с базовым типом, нужно применять интерфейс, а не базовый тип. Интерфейс подразумевает отношение «поддерживает функциональность». Например, тип может преобразовывать экземпляры самого себя в другой тип (IConvertible), может создать набор экземпляров самого себя (ISenializable) и т. д. Заметьте, что значимые типы должны наследовать от типа System.ValueType и поэтому не могут наследовать от произвольного базового класса. В этом случае нужно определять интерфейс.
□ Простота использования. Разработчику проще определить новый тип, производный от базового, чем создать интерфейс. Базовый тип может предоставлять массу функций, и в производном типе потребуется внести лишь незначительные изменения, чтобы изменить его поведение. При создании интерфейса в новом типе придется реализовывать все члены.
□ Четкая реализация. Как бы хорошо ни был документирован контракт, вряд ли будет реализован абсолютно корректно. По сути, проблемы СОМ связаны именно с этим — вот почему некоторые COM-объекты нормально работают только с Microsoft Word или Microsoft Internet Explorer. Базовый тип с хорошей реализацией основных функций — прекрасная отправная точка, вам останется изменить лишь отдельные части.
□ Управление версиями. Когда вы добавляете метод к базовому типу, производный тип наследует стандартную реализацию этого метода без всяких затрат. Пользовательский исходный код даже не нужно перекомпилировать. Добавление нового члена к интерфейсу требует изменения пользовательского исходного кода и его перекомпиляции.
В FCL классы, связанные с потоками данных, построены по принципу наследования реализации. System. 10. Stream — это абстрактный базовый класс, предоставляющий множество методов, в том числе Read и Write. Другие классы (System. 10.FileStream, System.10.MemoryStreamи System.Net.Sockets.NetworkStream)
являются производными от Stream. В Microsoft выбрали такой вид отношений между этими тремя классами и St ream по той причине, что так проще реализовывать конкретные классы. Так, производные классы должны самостоятельно реализовать только операции синхронного ввода-вывода, а способность выполнять асинхронные операции наследуется от базового класса Stream.
Возможно, выбор наследования реализации для классов, работающих с потоками, не совсем очевиден: ведь базовый класс Stream на самом деле предоставляет лишь ограниченную готовую функциональность. Однако если взглянуть на классы элементов управления Windows Forms, где Button, CheckBox, ListBox и все прочие элементы управления порождаются от System. Windows. Forms. Control, легко представить объем кода, реализованного в Control; весь этот код просто наследуется классами элементов управления, позволяя им правильно функционировать.
Что касается коллекций (collections), то их специалисты Microsoft реализовали в FCL на основе интерфейсов. В пространстве имен System.Collections.Generic определено несколько интерфейсов для работы с коллекциями: IEnumerable<T>, ICollection<T>, IList<T> и IDictionary<TKey, TValuex Кроме того, Microsoft предлагает несколько конкретных классов (таких, как List<T>, DictionarycTKey, TValue>, Queue<T>, Stack<T> и пр.), которые реализуют комбинации этих интерфейсов. Такой подход объясняется тем, что реализация всех классов-коллекций существенно различается. Иначе говоря, у List<T>, DictionarycTKey, TValue> и Queue<T> найдется не так много общего кода.
И все же операции, предлагаемые всеми этими классами, вполне согласованы. Например, все они поддерживают подмножество элементов с возможностью перебора, все они позволяют добавлять и удалять элементы. Если есть ссылка на объект, тип которого реализует интерфейс IList<T>, можно написать код, способный добавлять, удалять и искать элементы, не зная конкретный тип коллекции. Это очень мощный механизм.
Наконец, нужно сказать, что на самом деле можно определить интерфейс и создать базовый класс, который реализует интерфейс. Например, в FCL определен интерфейс IComparer<T>, и любой тип может реализовать этот интерфейс. Кроме того, FCL предоставляет абстрактный базовый класс Сотрагег<Т>, который реализует этот интерфейс (абстрактно) и предлагает реализацию по умолчанию для необобщенного метода Compare интерфейса IComparer. Применение обеих возможностей дает большую гибкость, поскольку разработчики теперь могут выбрать из двух вариантов наиболее предпочтительный.
ЧАСТЬ III
Основные типы данных
Глава 14. Символы, строки и обработка текста..................... 356
Глава 15. Перечислимые типы и битовые флаги................... 403
Глава 16. Массивы................................................................... 416
Глава 17. делегаты................................................................... 434
Глава 18. настраиваемые атрибуты........................................ 464
 Глава 19. Null-совместимые значимые типы
Глава 19. Null-совместимые значимые типы
Глава 14. Символы, строки и обработка текста
Эта глава посвящена приемам обработки отдельных символов, а также целых строк в Microsoft .NET Franiework. Вначале рассматриваются структура System.Char и способы работы с символами. Потом мы перейдем к весьма полезному классу System. String, предназначенному для работы с неизменяемыми строками (такую строку можно создать, но не изменить). Затем рассказывается о динамическом построении строк с помощью класса System.Text.StringBuilder. Разобравншсь с основами работы со строками, мы обсудим вопросы форматирования объектов в строки и эффективного сохранения и передачи строк в различных кодировках. В конце главы рассказывается о классе System.Security .SecureString, который может использоваться для защиты конфиденциальных строк данных, таких как пароли и номера кредитных карт.
Символы
Символы в .NET Framework всегда представлены 16-разрядными кодами стандарта Юникод, что облегчает разработку многоязыковых приложений. Символ представляется экземпляром структуры System.Char (значимый тип). Тип System.Char довольно прост, у него лишь два открытых неизменяемых поля: константа MinValue, определенная как ' \0', и константа MaxValue, определенная как ' \uffff'.
Для экземпляра Char можно вызывать статический метод GetUnicodeCategory, который возвращает значение перечислимого типа System. Globalization . UnicodeCategory, показывающее категорию символа: управляющий символ, символ валюты, буква в нижнем или верхнем регистре, знак препинания, математический символ и т. д. (в соответствии со стандартом Юникод).
Для облегчения работы с типом Char имеется несколько статических методов, например: IsDigit, IsLetter, IsWhiteSpace, IsUpper, IsLower, IsPunctuation, Is- LetterOrDigit, IsControl, IsNumber, IsSeparator, IsSurrogate, IsLowSurrogate, IsHighSurrogate и IsSymbol. Большинство этих методов обращается к GetUnicodeCategory и возвращает true или false. В параметрах этих методов передается либо одиночный символ, либо экземпляр String и индекс символа в строке.
Кроме того, статические методы ToLowerlnvariant и ToUpperlnvariant позволяют преобразовать символ в его эквивалент в нижнем или верхнем регистре
без учета региональных стандартов. Для преобразования символа с учетом региональных стандартов (culture), относящихся к вызывающему потоку (эти сведения методы получают, запрашивая статическое свойство CurrentCulture типа System. Globalization.Culturelnfо), служат методы ToLower и Tollpper. Чтобы задать конкретный набор региональных стандартов, передайте этим методам экземпляр класса Culturelnfo. Данные о региональных стандартах необходимы методам ToLower и ToUpper, поскольку от них зависит результат операции изменения регистра буквы. Например, в турецком языке символ U+0069 (латинская строчная буква i) при переводе в верхний регистр становится символом U+0130 (латинская прописная буква I с надстрочной точкой), тогда как в других языках — это символ U+0049 (латинская прописная буква I).
Помимо перечисленных статических методов, у типа Char есть также несколько собственных экземплярных методов. Метод Equals возвращает true, если два экземпляра Char представляют один и тот же 16-разрядный символ Юникода. Метод CompareTo (определенный в интерфейсах IComparable и IComparable<Char>) сравнивает два кодовых значения без учета региональных стандартов. Метод Con - vertFromUtf32 создает строку, состоящую из одного или двух символов UTF-16, для одного символа UTF-32. Метод ConvertToUtf32 создает символ UTF-32 для суррогатной пары или строки. Метод ToString возвращает строку, состоящую из одного символа, тогда как Parse и TryParse получают односимвольную строку String и возвращают соответствующую кодовую позицию UTF-16.
FlaKOHen, метод GetNumericValue возвращает числовой эквивалент символа. Это можно продемонстрировать на следующем примере:
using System;
public static class Program { public static void Main() {
Double d; // '\u0033' - это "цифра 3"
d = Char.GetNumericValue('\u0033'); // Параметр '3'
// даст тот же результат
Console.WriteLine(d.ToString()); // Выводится "3"
// '\u00bc' - это "простая дробь одна четвертая ('1/4')" d = Char.GetNumericValue('\u00bc');
Console.WriteLine(d.ToString()); // Выводится "0.25"
// 'A' - это "Латинская прописная буква А" d = Char.GetNumericValue('А');
Console.WriteLine(d.ToString()); // Выводится "-1"
}
}
А теперь представлю в порядке предпочтения три способа преобразования различных числовых типов в экземпляры типа Char, и наоборот.
□ Приведение типа. Самый эффективный способ, так как компилятор генерирует IL-команды преобразования без вызовов каких-либо методов. Для преобразо-
вания типа Char в числовое значение, такое как Int32, приведение подходит лучше всего. Кроме того, в некоторых языках (например, в С#) допускается указывать, какой код должен использоваться при выполеннии преобразования: проверяемый или непроверяемый (см. главу 5).
□ Использование типа Convert. У типа System.Convert есть несколько статических методов, корректно преобразующих Char в числовой тип и обратно. Все эти методы выполняют преобразование как проверяемую операцию, чтобы в случае потери данных при преобразовании возникало исключение OverflowException.
□ Использование интерфейса IConvertible. В типе Char и во всех числовых типах библиотеки .NET Framework Class Library (FCL) реализован интерфейс IConvertible, в котором определены такие методы, как ToUIntl6 и ToChar. Этот способ наименее эффективен, так как вызов интерфейсных методов для числовых типов приводит к упаковке экземпляра: Char и все числовые типы являются значимыми типами. Методы IConvertible генерируют исключение System. InvalidCastException, если преобразование невозможно (например, преобразование типа Char в Boolean) или грозит потерей данных. Во многих типах (в том числе Char и числовых типах FCL) используются EIMI-реализации методов IConvertible (см. главу 13), а значит, перед вызовом какого-либо метода этого интерфейса нужно выполнить явное приведение экземпляра к IConvertible. Все методы IConvertible за исключением GetTypeCode принимают ссылку на объект, реализующий интерфейс IFormatProvider. Этот параметр полезен, когда по какой-либо причине при преобразовании требуется учитывать региональные стандарты. В большинстве операций преобразования в этом параметре передается null, потому что он все равно игнорируется.
Применение всех трех способов продемонстрировано в следующем примере:
using System;
public static class Program { public static void Main() {
Char c;
Int32 n;
// Преобразование "число - символ" посредством приведения типов C# с = (Char) 65;
Console.WriteLine(c); // Выводится "А" n = (Int32) с;
Console.WriteLine(n); // Выводится "65"
с = unchecked((Char) (65536 + 65));
Console.WriteLine(c); // Выводится "A" // Преобразование "число - символ" с помощью типа Convert
с = Convert.ToChar(65);
Console.WriteLine(c); // Выводится "A"
n = Convert.ToInt32(c);
Console.WriteLine(n); // Выводится "65"
// Демонстрация проверки диапазона для Convert try {
с = Convert.ToChar(70000); // Слишком много для 16 разрядов Console.WriteLine(c); // Этот вызов выполняться НЕ будет
}
catch (OvertlowException) {
Console.WrlteLlne("Can't convert 70000 to a Char.");
}
// Преобразование "число - символ" с помощью интерфейса IConvertible с = ((IConvertible) 65).ToChar(null);
Console.WriteLine(c); // Выводится "A"
n = ((IConvertible) c).ToInt32(null);
Console.WriteLine(n); // Выводится "65"
}
Тип System.String
Один из самых полезных типов, встречающихся в любом приложении — System. String, — представляет неизменяемый упорядоченный набор символов. Будучи прямым потомком Object, он является ссылочным типом, по этой причине строки всегда размещаются в куче и никогда — в стеке потока. Тип String реализует также несколько интерфейсов (IComparable/IComparable<String>, ICloneable, IConvertible, IEnumerable/IEnumerable<Char> иIEquatable<String>).
Создание строк
Во многих языках (включая С#) String относится к примитивным типам, то есть компилятор разрешает вставлять литеральные строки непосредственно в исходный код. Компилятор помещает эти литеральные строки в метаданные модуля, откуда они загружаются и используются во время выполнения.
В C# оператор new не может использоваться для создания объектов String из литеральных строк:
using System;
public static class Program { public static void Main() {
продолжение &
String s = new String("Hi there."); // Ошибка Console.WriteLine(s);
}
Вместо этого используется более простой синтаксис:
using System;
public static class Program { public static void Main() {
String s = "Hi there.";
Console.WriteLine(s);
}
}
Результат компиляции этого кода можно посмотреть с помощью утилиты ILDasm.exe:
.method public hidebysig static void Main() cil managed
{
.entrypoint
// Code size 13 (0xd)
.maxstack 1
.locals init (string V_0)
IL_0000: ldstr "Hi there."
IL_0005: stloc.0 IL0006: ldloc.0
IL0007: call void [mscorlib]System.Console::WriteLine(string)
IL_000c: ret
} // end of method Program::Main
За создание нового экземпляра объекта отвечает IL-команда newobj. Однако здесь этой команды нет. Вместо нее вы видите специальную IL-команду ldstr (загрузка строки), которая создает объект String на основе литеральной строки, полученной из метаданных. Отсюда следует, что объекты String в CLR создаются по специальной схеме.
Используя небезопасный код, можно создать объект String с помощью Char* и SByte*. Для этого следует применить оператор new и вызвать один из конструкторов типа String, получающих параметры Char* и SByte*. Эти конструкторы создают объект String и заполняют его строкой, состоящей из указанного массива экземпляров Char или байтов со знаком. У других конструкторов нет параметров- указателей, их можно вызвать из любого языка, создающего управляемый код.
В C# имеется специальный синтаксис для включения литеральных строк в исходный код. Для вставки специальных символов, таких как конец строки, возврат каретки, забой, в C# используются управляющие последовательности, знакомые разработчикам на C/C++:
// String содержит символы конца строки и перевода каретки String s = "Hi\r\nthere.";
ВНИМАНИЕ
Задавать в коде последовательность символов конца строки и перевода каретки напрямую, как это сделано в представленном примере, не рекомендуется. У типа System.Environment определено неизменяемое свойство NewLine, которое при выполнении приложения в Windows возвращает строку, состоящую из этих символов. Однако свойство NewLine зависит от платформы и возвращает ту строку, которая обеспечивает создание разрыва строк на конкретной платформе. Скажем, при переносе CLI в UNIX свойство NewLine должно возвращать строку, состоящую только из символа «\п». Чтобы приведенный код работал на любой платформе, перепишите его следующим образом:
String s = "Hi" + Environment.NewLine + "there.";
Чтобы объединить несколько строк в одну строку, используйте оператор + языка С#:
// Конкатенация трех литеральных строк образует одну литеральную строку String s = "Hi" + " " + "there.";
Поскольку все строки в этом коде литеральные, компилятор выполняет их конкатенацию на этапе компиляции, в результате в метаданных модуля оказывается лишь строка "Hi there.". Конкатенация нелитеральных строк с помощью оператора + происходит на этапе выполнения. Для конкатенации нескольких строк на этапе выполнения оператор + применять нежелательно, так как он создает в куче несколько строковых объектов. Вместо него рекомендуется использовать тип System.Text. StringBuilder (о нем рассказано далее).
И наконец, в C# есть особый вариант объявления строки, в которой все символы между кавычками трактуются как часть строки. Эти специальные объявления — буквальные строки (verbatim strings) — обычно используют при задании пути к файлу или каталогу и при работе с регулярными выражениями. Следующий пример показывает, как объявить одну и ту же строку с использованием признака буквальных строк (@) и без него:
// Задание пути к приложению
String file = "C:\\Windows\\System32\\Notepad.exe";
// Задание пути к приложению с помощью буквальной строки String file = @"С:\Windows\System32\Notepad.exe";
Оба фрагмента кода дают одинаковый результат. Однако символ @ перед строкой во втором случае сообщает компилятору, что перед ним буквальная строка и он должен рассматривать символ обратной косой черты (\) буквально, а не как префикс управляющей последовательности, благодаря чему путь в коде выглядит более привычно.
Теперь, познакомившись с формированием строк, рассмотрим операции, выполняемые над объектами типа String.
Неизменяемые строки
Самое важное, что нужно помнить об объекте String — то, что он неизменяем; то есть созданную однажды строку нельзя сделать длиннее или короче, в ней нельзя изменить ни одного символа. Неизменность строк дает определенные преимущества. Для начала можно выполнять операции над строками, не изменяя их:
if (s.ToUpperlnvariant().Substring(10, 21).EndsWith("EXE")) {
}
Здесь ToUpperlnvariant возвращает новую строку; символы в строке s не изменяются. Substring обрабатывает строку, возвращенную ToUpperlnvariant, и тоже возвращает новую строку, которая затем передается методу EndsWith. В программном коде приложения нет ссылок на две временные строки, созданные ToUpperlnvariant и Substring, поэтому занятая ими память освободится при очередной уборке мусора. Если выполняется много операций со строками, в куче создается много объектов String — это заставляет чаще прибегать к помощи уборщика мусора, что отрицательно сказывается на производительности приложения.
Благодаря неизменности строк отпадает проблема синхронизации потоков при работе со строками. Кроме того, в CLR несколько ссылок String могут указывать на один, а не на несколько разных строковых объектов, если строки идентичны. А значит, можно сократить количество строк в системе и уменьшить расход памяти — это именно то, что непосредственно относится к интернированию строк (string interning), о котором речь пойдет дальше.
По соображениям производительности тип String тесно интегрирован с CLR. В частности, CLR «знает» точное расположение полей в этом типе и обращается к ним напрямую. За повышение производительности и прямой доступ приходится платить небольшую цену: класс St ring является запечатанным. Иначе, имея возможность описать собственный тип, производный от String, можно было бы добавлять свои поля, противоречащие структуре String и нарушающие работу CLR. Кроме того, ваши действия могли бы нарушить предположения CLR об объекте String, которые вытекают из его неизменности.
Сравнение строк
Сравнение — пожалуй, наиболее часто выполняемая со строками операция. Есть две причины, по которым приходится сравнивать строки. Мы сравниваем две строки для выяснения, равны ли они, и для сортировки (прежде всего, для представления их пользователю программы).
Для проверки равенства строк и для их сравнения при сортировке я настоятельно рекомендую использовать один из перечисленных далее методов, реализованных в классе String:
Boolean Equals(String value, StringComparison comparisonType)
static Boolean Equals(String a, String b, StringComparison comparisonType)
static Int32 Compare(String strA, String strB,
StringComparison comparisonType) static Int32 Compare(string strA, string strB,
Boolean ignoreCase, Culturelnfo culture)
static Int32 Compare(String strA, String strB,
Culturelnfo culture, CompareOptions options)
static Int32 Compare(String strA, Int32 indexA, String strB, Int32 indexB,
Int32 length, StringComparison comparisonType) static Int32 Compare(String strA, Int32 indexA, String strB, Int32 indexB,
Int32 length, Culturelnfo culture, CompareOptions options) static Int32 Compare(String strA, Int32 indexA, String strB, Int32 indexB,
Int32 length, Boolean ignoreCase, Culturelnfo culture)
Boolean StartsWith(String value, StringComparison comparisonType)
Boolean StartsWith(String value,
Boolean ignoreCase, Culturelnfo culture)
Boolean EndsWith(String value, StringComparison comparisonType)
Boolean EndsWith(String value, Boolean ignoreCase, Culturelnfo culture)
При сортировке всегда нужно учитывать регистр символов. Дело в том, что две строки, отличающиеся лишь регистром символов, будут считаться одинаковыми и поэтому при каждой сортировке они могут упорядочиваться в произвольном порядке, что может приводить пользователя в замешательство.
В аргументе comparisonType (он есть в большинстве перечисленных методов) передается одно из значений, определенных в перечислимом типе StringComparison, который определен следующим образом:
public enum StringComparison {
CurrentCulture = 0,
CurrentCulturelgnoreCase = 1,
InvariantCulture = 2,
InvariantCulturelgnoreCase = 3,
Ordinal = 4,
OrdinallgnoreCase = 5
}
Аргумент options является одним из значений, определенных перечислимым типом CompareOptions:
[Flags]
public enum CompareOptions {
None = 0,
IgnoreCase = 1,
IgnoreNonSpace = 2,
IgnoreSymbols = 4,
IgnoreKanaType = 8,
IgnoreWidth = 0x00000010,
Ordinal = 0x40000000,
OrdinallgnoreCase = 0x10000000,
StringSort = 0x20000000
>
Методы, работающие с аргументом CompareOptions, также поддерживают явную передачу информации о языке и региональных стандартах. Если установлен флаг Ordinal KJiHOrdinallgnoreCase, тогда методы Compare игнорируют определенный язык и региональные стандарты.
Во многих программах строки используются для решения внутренних задач: представления имен путей и файлов, URL-адресов, параметров и разделов реестра, переменных окружения, отражения, XML-тегов, XML-атрибутов и т. п. Часто такие строки вообще не выводятся, а используются только внутри программы. Для сравнения внутренних строк следует всегда использовать флаг StringComparison. Ordinal или StringComparison.OrdinallgnoreCase. Это самый быстрый способ сравнения, так как он игнорирует лингвистические особенности и региональные стандарты.
С другой стороны, если требуется корректно сравнить строки с точки зрения лингвистических особенностей (обычно перед выводом их на экран для пользователя), следует использовать флаг StringComparison.CurrentCulture или StringComparison.CurrentCulturelgnoreCase.
ВНИМАНИЕ
Обычно следует избегать использования флагов StringComparison.InvariantCulture и StringComparison.InvariantCulturelgnoreCase. Хотя эти значения и позволяют выполнить лингвистически корректное сравнение, применение их для сравнения строк в программе занимает больше времени, чем с флагом StringComparison.Ordinal или StringComparison.OrdinallgnoreCase. Кроме того, игнорирование региональных стандартов — совсем неудачный выбор для сортировки строк, которые планируется показывать пользователю.
ВНИМАНИЕ
Если вы хотите изменить регистр символов строки перед выполнением простого сравнения, следует использовать предоставляемый String метод Tollpperlnvariant или ToLowerlnvariant. При нормализации строк настоятельно рекомендуется использовать метод Tollpperlnvariant, а не ToLowerlnvariant из-за того, что в Microsoft сравнение строк в верхнем регистре оптимизировано. На самом деле, в FCL перед не зависящим от регистра сравнением строки нормализуют путем приведения их к верхнему регистру.
Иногда для лингвистически корректного сравнения строк используют региональные стандарты, отличные от региональных стандартов вызывающего потока. В таком случае можно задействовать перегруженные версии показанных ранее методов StartsWith, EndsWith и Compare — все они принимают аргументы Boolean и Culturelnfo.
А теперь поговорим о лингвистически корректных сравнениях. Для представления пары «язык-страна» (как описано в спецификации RFC 1766) в .NET Framework используется тип System.Globalization.Culturelnfo. В частности, en-US означает американскую (США) версию английского языка, en-AU — австралийскую версию английского языка, a de-DE германскую версию немецкого языка. В CLR у каждого потока есть два свойства, относящиеся к этой паре и ссылающиеся на объект Culturelnfo.
□ CurrentUICulture служит для получения ресурсов, видимых конечному пользователю. Это свойство наиболее полезно для графического интерфейса пользователя или приложений Web Forms, так как оно обозначает язык, который следует выбрать для вывода элементов пользовательского интерфейса, таких как надписи и кнопки. По умолчанию при создании потока это свойство потока задается Win32-функцией GetUserDefaultUILanguage на основании объекта Culturelnfo, который указывает на язык текущей версии Windows. При использовании МШ-версии (Multilingual User Interface) Windows это свойство можно задать с помощью утилиты Regional and Language Options (Язык и региональные стандарты) панели управления.
ВНИМАНИЕ
В типе String определено несколько вариантов перегрузки методов Equals, StartsWith, EndsWith и Compare помимо тех, что приведены ранее. Microsoft рекомендует избегать других версий (не представленных в этой книге). Кроме того, нежелательно использовать и другие имеющиеся в String методы сравнения — CompareTo (необходимый для интерфейса IComparable), CompareOrdinal и операторы == и !=. Причина в том, что вызывающий код не определяет явно, как должно выполняться сравнение строк, а на основании метода нельзя узнать, какой способ сравнения выбран по умолчанию. Например, по умолчанию метод CompareTo выполняет сравнение с учетом региональных стандартов, a Equals —без учета. Если вы явно указываете, как должно выполняться сравнение строк, ваш код будет проще читать и сопровождать.
□ CurrentCulture используется во всех случаях, в которых не используется свойство Cur rentUICulture, в том числе для форматирования чисел и дат, приведения и сравнения строк. При форматировании требуются обе части объекта Culturelnfo — информация о языке и стране. По умолчанию при создании потока это свойство потока задается Win32^yHKnHeit GetUserDefaultLCID на основании объекта Culturelnfo. Его можно задать на вкладке Regional Options (Региональные параметры) утилиты Regional and Language Options (Язык и региональные стандарты) панели управления.
Значения по умолчанию для этих двух свойств потоков, используемые при создании потока, можно переопределить — для этого следует задать статические свойства DefaultThreadCurrentCulture и DefaultThreadCurrentUICulture объекта Culturelnfo.
Во многих приложениях свойствам CurrentUICulture и CurrentCulture задается один объект Culturelnfo, то есть в них содержится одинаковая информация о языке и стране. Однако она может различаться. Например, в приложении, работающем в США, все элементы интерфейса могут представляться на испанском языке, а валюта и формат дата — в соответствии с принятыми в США стандартами. Для этого свойству CurrentUICulture потока задается объект Culturelnfo, инициализированный с языком es (испанский), а свойству CurrentCulture — объект Culturelnfo, инициализированный парой en-US.
Внутренняя реализация объекта Culturelnfo ссылается на объект System. Globalization. Comparelnfo, инкапсулирующий принятые в данных региональных стандартах таблицы сортировки в соответствии с правилами Юникода. Использование региональных стандартов при сортировке строк демонстрирует пример:
using System;
using System.Globalization;
public static class Program { public static void Main() {
String si = "Strasse";
String s2 = "StraBe";
Boolean eq;
// CompareOrdinal возвращает ненулевое значение
eq = String.Compare(sl, s2, StringComparison.Ordinal) == 0;
Console.WriteLine("Ordinal comparison: '{0}' {2} '{1}'", si, s2, eq ? n==" : ”!=");
// Сортировка строк для немецкого языка (de) в Германии (DE)
Culturelnfo ci = new CultureInfo("de-DE“);
// Compare возвращает нуль
eq = String.Compare(sl, s2, true, ci) == 0;
Console.WriteLine("Cultural comparison: '{0}' {2} '{1}'", si, s2, eq ? "==" ; "!=");
}
}
В результате компоновки и выполнения кода получим следующее:
Ordinal comparison: 'Strasse' != 'StraBe'
Cultural comparison: 'Strasse' == 'StraBe'
ПРИМЕЧАНИЕ
Если метод Compare не выполняет простое сравнение, то он производит расширение символов (character expansions), то есть разбивает сложные символы на несколько символов, игнорируя региональные стандарты. В предыдущем случае немецкий символ В всегда расширяется до ss. Аналогично лигатурный символ JE всегда расширяется до АЕ. Поэтому в приведенном примере вызов Compare будет всегда возвращать 0 независимо от выбранных региональных стандартов.
В некоторых редких случаях требуется более тонкий контроль при сравнении строк для проверки на равенство и для сортировки. Например, это может потребоваться при сравнении строк с японскими иероглифами. Для этого используется свойство Comparelnfo объекта Culturelnfo. Как отмечалось ранее, объект Comparelnfo инкапсулирует таблицы сравнения символов для различных региональных стандартов, причем для каждого регионального стандарта существует только один объект Comparelnfo.
При вызове метода Compare класса String используются указанные вызывающим потоком региональные стандарты. Если региональные стандарты не указаны, используются значения свойства CurrentCulture вызывающего потока. Код, реализующий метод Compare, получает ссылку на объект Comparelnfo соответствующего регионального стандарта и вызывает метод Compare объекта Comparelnfo, передавая соответствующие параметры (например, признак игнорирования регистра символов). Естественно, если требуется дополнительный контроль, вы должны самостоятельно вызывать метод Compare конкретного объекта Comparelnfo.
Метод Compare класса Comparelnfo принимает в качестве параметра значение перечислимого типа CompareOptions. Битовые флаги можно объединять посредством оператора «или» для большего контроля над сравнением строк. За полным описанием флагов обращайтесь к документации .NET Framework.
Следующий пример демонстрирует значение региональных стандартов при сортировке строк и различные варианты сравнения строк:
using System; using System.Text; using System.Windows.Forms; using System.Globalization; using System.Threading;
public sealed class Program { public static void Main() {
String output = String.Empty;
String[] symbol = new String[] { };
Int32 x;
Culturelnfo ci;
// Следующий код демонстрирует, насколько отличается результат // сравнения строк для различных региональных стандартов String si = "cote";
String s2 = "cote";
// Сортировка строк для французского языка (Франция) ci = new CultureInfo("fr-FR"); х = Math.Sign(ci.Comparelnfo.Compare(sl, s2)); output += String.Format("{0} Compare: {1} {3} {2}“, ci.Namej slj s2j symbol[x + 1]); output += Environment.NewLine;
// Сортировка строк для японского языка (Япония) ci = new CultureInfo("ja-3P"); х = Math.Sign(ci.Comparelnfo.Compare(sl, s2));
продолжение
output += String.Format("{0} Compare: {1} {3} {2}", ci.Name, si, s2, symbol[x + 1]); output += Environment.NewLine;
// Сортировка строк по региональным стандартам потока ci = Thread.CurrentThread.CurrentCulture; х = Math.Sign(ci.Comparelnfo.Compare(sl, s2)); output += String.Format("{0} Compare: {1} {3} {2}", ci.Name, si, s2, symbol[x + 1]);
output += Environment.NewLine + Environment.NewLine;
// Следующий код демонстрирует использование дополнительных возможностей // метода Comparelnfo.Compare при работе с двумя строками // на японском языке
// Эти строки представляют слово "shinkansen" (название // высокоскоростного поезда) в разных вариантах письма:
// хирагане и катакане
si = " "; // (n\u3057\u3093\u304b\u3093\u305b\u3093") s2 = " "; // (n\u30b7\u30f3\u30ab\u30f3\u30bb\u30f3")
// Результат сравнения по умолчанию ci = new CultureInfo("ja-3P"); х = Math.Sign(String.Compare(sl, s2, true, ci)); output += String.Format("Simple {0} Compare: {1} {3} {2}", ci.Name, si, s2, symbol[x + 1]); output += Environment.NewLine;
// Результат сравнения, который игнорирует тип каны Comparelnfo comparelnfo = Comparelnfo.GetCompareInfo("ja-3P"); x = Math.Sign(compareInfo.Compare(sl, s2,
CompareOptions.IgnoreKanaType)); output += String.Format("Advanced {0} Compare: {1} {3} {2}", ci.Name, si, s2, symbol[x + 1]);
MessageBox.Show(output, "Comparing Strings For Sorting");
ПРИМЕЧАНИЕ
Подобные файлы с исходным кодом нельзя сохранить в кодировке ANSI, поскольку иначе японские символы будут потеряны. Для того чтобы сохранить этот файл при помощи Microsoft Visual Studio, откройте диалоговое окно Save File As, раскройте список форматов сохранения и выберите вариант Save With Encoding. Я выбрал Юникод (UTF-8 with signature) — Codepage 65001. Компилятор C# успешно разбирает файлы программного кода, использующие эту кодовую страницу.
После построения и выполнения кода получим результат, показанный на .14.1.
|
Рис. 14.1. Результат сортировки строк |
11омимо Compare, класс Comparelnfo предлагает методы IndexOf, IsLastlndexOf, IsPrefix и IsSuffix. Благодаря имеющейся у каждого из этих методов перегруженной версии, которой в качестве параметра передается значение перечислимого типа CompareOptions, вы получаете дополнительные возможности по сравнению с методами Compare, IndexOf, LastlndexOf, StartsWith и EndsWith класса String. Кроме того, следует иметь в виду, что в FCL есть класс System. StringComparer, который также можно использовать для сравнения строк. Он оказывается кстати в тех случаях, когда необходимо многократно выполнять однотипные сравнения множества строк.
Интернирование строк
Как я уже отмечал, сравнение строк используется во многих приложениях, однако эта операция может ощутимо сказаться на производительности. При порядковом сравнении (ordinal comparison) СLR быстро проверяет, равно ли количество символов в стр< жах. При отрицательном результате строки точно не равны, но если длина одинакова, приходится сравнивать их символ за символом. 11 р и сравнении с учетом региональных стандартов среде CLR тоже приходится посимвольно сравнить строки, потому что две строки разной длины могут оказаться равными.
К тому же хранение в памяти нескольких экземпляров одной строки приводит к непроизводительным затратам памяти - ведь строки неизменяемы. Эффективного использования памяти можно добиться, если держать в ней одну строку, на которую будут указывать соответствующие ссылки.
Если в приложении строки сравниваются часто методом порядкового сравнения с учетом регистра или если в приложении ожидается появление множества одинаковых строковых объектов, то для повышения производительности надо применить поддерживаемый CLR механизм интернирования строк (string interning). При инициализации CLR создает внутреннюю хеш-таблицу, в которой ключами являются строки, а значениями — ссылки на строковые объекты в управляемой куче. Вначале таблица, разумеется, пуста. В классе String есть два метода, предоставляющие доступ к внутренней хеш-таблице:
public static String Intern(String str); public static String Islnterned(String str);
Первый из них, Intern, ищет String во внутренней хеш-таблице. Если строка обнаруживается, возвращается ссылка на соответствующий объект String. Иначе создается копия строки, она добавляется во внутреннюю хеш-таблицу, и возвращается ссылка на копию. Если приложение больше не удерживает ссылку на исходный объект String, уборщик мусора вправе освободить память, занимаемую этой строкой. Обратите внимание, что уборщик мусора не вправе освободить строки, на которые ссылается внутренняя хеш-таблица, поскольку в ней самой есть ссылки на эти String. Объекты String, на которые ссылается внутренняя хеш-таблица, нельзя освободить, пока не выгружен соответствующий домен приложения или не закрыт поток.
Как и Intern, метод Islnterned получает параметр String и ищет его во внутренней хеш-таблице. Если поиск удачен, Islnterned возвращает ссылку на интернированную строку. В противном случае; он возвращает null, а саму строку не вставляет в хеш-таблицу.
По умолчанию при загрузке сборки CLR интернирует все литеральные строки, описанные в метаданных сборки. Выяснилось, что это отрицательно сказывается на производительности из-за необходимости дополнительного поиска в хеш-таблицах, поэтому Microsoft теперь позволяет отключить эту «функцию». Если сборка отмечена атрибутом System.Runtime.CompilerServices.CompilationRelaxations Attribute, определяющим значение флага System.Runtime.CompilerServices. CompilationRelaxations. NoStringlnterning, то в соответствии со спецификацией ЕСМА среда CLR может отказаться от интернирования строк, определенных в метаданных сборки. Обратите внимание, что в целях повышения производительности работы приложения компилятор C# всегда при компиляции сборки определяет этот атрибут/флаг.
Даже если в сборке определен этот атрибут/флаг, CLR может предпочесть интернировать строки, но на это не стоит рассчитывать. Никогда не стоит писать код, рассчитанный на интернирование строк, если только вы сами в своем коде явно не вызываете метод Intern типа String. Следующий код демонстрирует
интернирование строк:
String si = "Hello";
String s2 = "Hello";
Console.WriteLine(ObJect.ReferenceEquals(sl, s2)); // Должно быть 'False'
si = String.Intern(sl); s2 = String.Intern(s2);
Console.WriteLine(Object.ReferenceEquals(sl, s2)); // 'True'
При первом вызове метода ReferenceEquals переменная si ссылается на объект-строку "Hello" в куче, a s2 — на другую объект-строку "Hello". Поскольку ссылки разные, выводится значение False. Однако если выполнить этот код в CLR версии 4.5, будет выведено значение True. Дело в том, что эта версия CLR игнорирует атрибут/флаг, созданный компилятором С#, и интернирует литеральную строку "Hello" при загрузке сборки в домен приложений. Это означает, что si и s2 ссылаются на одну строку в куче. Однако, как уже отмечалось, никогда не стоит писать код с расчетом на такое поведение, потому что в последующих версиях этот атрибут/флаг может приниматься во внимание, и строка "Hello" интернироваться не будет. В действительности, CLR версии 4.5 учитывает этот атрибут/флаг, но только если код сборки создан с помощью утилиты NGen.exe.
Перед вторым вызовом метода ReferenceEquals строка "Hello" явно интернируется, в результате si ссылается на интернированную строку "Hello". Затем при повторном вызове Intern переменной s2 присваивается ссылка на ту же самую строку "Hello", на которую ссылается si. Теперь при втором вызове ReferenceEquals мы гарантировано получаем результат True независимо от того, была ли сборка скомпилирована с этим атрибутом/флагом.
Теперь на примере посмотрим, как использовать интернирование строки для повышения производительности и снижения нагрузки на память. Показанный далее метод NumTimesWordAppearsEquals принимает два аргумента: слово и массив строк, в котором каждый элемент массива ссылается на одно слово. Метод определяет, сколько раз указанное слово содержится в списке слов, и возвращает число:
private static Int32 NumTimesWordAppearsEquals(String word, String[] wordlist) {
Int32 count = 0;
for (Int32 wordnum = 0; wordnum < wordlist.Length; wordnum++) { if (word.Equals(wordlist[wordnum], StringComparison.Ordinal)) count++;
}
return count;
}
Как видите, этот метод вызывает метод Equals типа String, который сравнивает отдельные символы строк и проверяет, все ли символы совпадают. Это сравнение может выполняться медленно. Кроме того, массив wordlist может иметь много элементов, которые ссылаются на многие объекты String, содержащие тот же набор символов. Это означает, что в куче может существовать множество идентичных строк, которые не должны уничтожаться в процессе уборки мусора.
А теперь посмотрим на версию этого метода, которая написана с интернированием строк:
private static Int32 NumTimesWordAppearsIntern(String word, String[] wordlist) {
// В этом методе предполагается, что все элементы в wordlist // ссылаются на интернированные строки word = String.Intern(word);
Int32 count = 0;
for (Int32 wordnum = 0; wordnum < wordlist.Length; wordnum++) { if (Object.ReferenceEquals(word, wordlist[wordnum])) count++;
}
return count;
}
Этот метод интернирует слово и предполагает, что wordlist содержит ссылки на интернированные строки. Во-первых, в этой версии экономится память, если слово повторяется в списке слов, потому что теперь wordlist содержит многочисленные ссылки на единственный объект String в куче. Во-вторых, эта версия работает быстрее, потому что для выяснения, есть ли указанное слово в массиве, достаточно простого сравнения указателей.
Хотя метод NumTimesWordAppearsIntern работает быстрее, чем NumTimes- WordAppearsEquals, общая производительность приложения может оказаться ниже, чем при использовании метода NumTimesWordAppearsIntern из-за времени, которое требуется на интернирование всех строк по мере добавления их в массив wordlist (соответствующий код не показан). Преимущества метода NumTimesWordAppearsIntern ускорение работы и снижение потребления памяти — будут заметны, если приложению нужно множество раз вызывать метод, передавая один и тот же массив wordlist. Этим обсуждением я хотел донести до вас, что интернирование строк полезно, но использовать его нужно с осторожностью. Собственно, именно по этой причине компилятор C# указывает, что не следует разрешать интернирование строк.
Создание пулов строк
При обработке исходного кода компилятор должен каждую литеральную строку поместить в метаданные управляемого модуля. Если одна строка встречается в исходном коде много раз, размещение всех таких строк в метаданных приведет к увеличению размера результирующего файла.
Чтобы не допустить роста объема кода, многие компиляторы (в том числе С#) хранят литеральную строку в метаданных модуля только в одном экземпляре. Все упоминания этой строки в исходном коде компилятор заменяет ссылками на ее экземпляр в метаданных. Благодаря этому заметно уменьшается размер модуля. Способ не нов — в компиляторах Microsoft C/C++ этот механизм реализован уже давно и называется созданием пула строк (string pooling). Это еще одно средство, позволяющее ускорить обработку строк. Полагаю, вам будет полезно знать о нем.
Работа с символами и текстовыми элементами в строке
Сравнение строк полезно при сортировке и поиске одинаковых строк, однако иногда требуется проверять отдельные символы в пределах строки. С подобными задачами призваны справляться несколько методов и свойств типа String, в числе которых Length, Chars (индексатор в С#), GetEnumerator, ToCharArray, Contains, IndexOf, LastlndexOf, IndexOfAny и LastlndexOfAny.
На самом деле System.Char представляет одно 16-разрядное кодовое значение в кодировке Юникод, которое необязательно соответствует абстрактному Юникод- символу. Так, некоторые абстрактные Unicode-символы являются комбинацией двух кодовых значений. Например, сочетание символов U+0625 (арабская буква
«алеф» с подстрочной «хамза») и U+0650 (арабская «казра») образует один арабский символ, или текстовый элемент.
Кроме того, представление некоторых текстовых элементов требует не одного, а двух 16-разрядных кодовых значений. Первое называют старшим (high surrogate), а второе — младшим заменителем (low surrogate). Значения старшего находятся в диапазоне от U+D800 до U+DBFF, младшего — от U+DC00 до U+DFFF. Такой способ кодировки позволяет представить в Unicode более миллиона различных символов.
Символы-заменители востребованы в основном в странах Восточной Азии и гораздо меньше в США и Европе. Для корректной работы с текстовыми элементами предназначен тип System.Globalization.Stringlnfo. Самый простой способ воспользоваться этим типом — создать его экземпляр, передав его конструктору строку. Чтобы затем узнать, сколько текстовых элементов содержит строка, достаточно прочитать свойство LengthlnTextElements объекта Stringlnfo. Позже можно вызвать метод SubstringByTextElements объекта Stringlnfo, чтобы извлечь один или несколько последовательных текстовых элементов.
Кроме того, в классе Stringlnfo есть статический метод GetTextElementEnumerator, возвращающий объект System. Globalization. TextElementEnumerator, который, в свою очередь, позволяет просмотреть в строке все абстрактные символы Юникода. Наконец, можно воспользоваться статическим методом ParseCombiningCharacters типа Stringlnfo, чтобы получить массив значений типа Int32, по длине которого можно судить о количестве текстовых элементов в строке. Каждый элемент массива содержит индекс первого кодового значения соответствующего текстового элемента.
Очередной пример демонстрирует различные способы использования класса Stringlnfo для управления текстовыми элементами строки:
using System; using System.Text; using System.Globalization; using System.Windows.Forms;
public sealed class Program { public static void Main() {
// Следующая строка содержит комбинированные символы String s = "a\u0304\u0308bc\u0327";
SubstringByTextElements(s);
EnumTextElements(s);
EnumTextElementlndexes(s);
}
private static void SubstringByTextElements(String s) {
String output = String.Empty;
Stringlnfo si = new Stringlnfo(s);
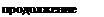 for (Int32 element = 0; element < si.LengthlnTextElements; element++) { output += String.Format(
for (Int32 element = 0; element < si.LengthlnTextElements; element++) { output += String.Format(
"Text element {0} is '{1}'{2}",
element, si.SubstringByTextElements(element, 1),
Environment.NewLine);
}
MessageBox.Show(output, "Result of SubstringByTextElements");
}
private static void EnumTextElements(String s) {
String output = String.Empty;
TextElementEnumerator charEnum =
StringInfo.GetTextElementEnumerator(s); while (charEnum.MoveNext()) { output += String.Format(
"Character at index {0} is '{1}'{2}", charEnum.ElementIndex, charEnum.GetTextElement(), Environment.NewLine);
}
MessageBox.Show(output, "Result of GetTextElementEnumerator");
}
private static void EnumTextElementIndexes(String s) {
String output = String.Empty;
Int32[] textElemIndex = StringInfo.ParseCombiningCharacters(s); for (Int32 i = 0; i < textElemIndex.Length; i++) { output += String.Format(
"Character {0} starts at index {1}{2}", i, textElemIndex[i], Environment.NewLine);
}
MessageBox.Show(output, "Result of ParseCombiningCharacters");
}
}
 |
После компоновки и последующего запуска этого кода на экране появятся информационные окна (рис. 14.2-14.4).
Прочие операции со строками
В табл. 14.1 представлены методы типа String, предназначенные для полного или частичного копирования строк.
| Таблица 14.1. Методы копирования строк
|
|
|
Помимо этих методов, у типа String есть много статических и экземплярных методов для различных операций со строками: Insert, Remove, PadLeft, Replace, Split, loin, ToLower, ToUpper, Trim, Concat, Format и пр. Еще раз повторю, что все эти методы возвращают новые строковые объекты; создать строку можно, но изменить ее нельзя (при условии использования безопасного кода).
Эффективное создание строк
Тип String представляет собой неизменяемую строку, а для динамических операций со строками и символами при создании объектов String в FCL имеется тип System. Text.StringBuilder. Его можно рассматривать как некий общедоступный конструктор для String. В общем случае нужно создавать методы, у которых в качестве параметров выступают объекты String, а не StringBuilder, хотя можно написать метод, возвращающий строку, создаваемую динамически внутри метода.
У объекта StringBuilder предусмотрено поле со ссылкой на массив структур Char. Используя члены StringBuilder, можно эффективно манипулировать этим массивом, сокращая строку и изменяя символы строки. При увеличении строки, представляющей ранее выделенный массив символов, StringBuilder автоматически выделит память для нового, большего по размеру массива, скопирует символы и приступит к работе с новым массивом. А прежний массив попадет в сферу действия уборщика мусора.
Сформировав свою строку с помощью объекта StringBuilder, «преобразуйте» массив символов StringBuilder в объект String, вызвав метод ToString типа StringBuilder. Этот метод просто возвращает ссылку на поле-строку, управляемую объектом StringBuilder. Поскольку массив символов здесь не копируется, метод выполняется очень быстро. Объект String, возвращаемый методом ToString, не может быть изменен. Поэтому, если вы вызовете метод, который попытается изменить строковое поле, управляемое объектом StringBuilder, методы этого объекта, зная, что для него был вызван метод ToString, создадут новый массив символов, манипуляции с которым не повлияют на строку, возвращенную предыдущим вызовом ToString.
Создание объекта StringBuilder
В отличие от класса String, класс StringBuilder в CLR не представляет собой ничего особенного. Кроме того, большинство языков (включая С#) не считают StringBuilder примитивным типом. Объект StringBuilder создается так же, как любой объект непримитивного типа:
StringBuilder sb = new StringBuilder();
У типа StringBuilder несколько конструкторов. Задача каждого из них — выделять память и инициализировать три внутренних поля, управляемых любым объектом StringBuilder.
□ Максимальная емкость (maximum capacity) — поле типа Int32, которое задает максимальное число символов, размещаемых в строке. По умолчанию оно равно Int32.MaxValue (около двух миллиардов). Это значение обычно не изменяется, хотя можно задать и меньшее значение, ограничивающее размер создаваемой строки. Для уже созданного объекта StringBuilder это поле изменить нельзя.
□ Емкость (capacity) — поле типа Int32, показывающее размер массива символов StringBuilder. По умолчанию оно равно 16. Если известно, сколько символов предполагается разместить в StringBuilder, укажите это число при создании объекта StringBuilder. При добавлении символов StringBuilder определяет, не выходит ли новый размер массива за установленный предел. Если да, то StringBuilder автоматически удваивает емкость, и исходя из этого значения, выделяет память под новый массив, а затем копирует символы из исходного массива в новый. Исходный массив в дальнейшем утилизируется сборщиком мусора. Динамическое увеличение массива снижает производительность, поэтому его следует избегать, задавая подходящую емкость в начале работы с объектом.
□ Массив символов (character array) — массив структур Char, содержащий набор символов «строки». Число символов всегда меньше (или равно) емкости и максимальной емкости. Количество символов в строке можно получить через свойство Length типа StringBuilder. Значение Length всегда меньше или равно емкости StringBuilder. При создании StringBuilder можно инициализировать массив символов, передавая ему String как параметр. Если строка не задана, массив первоначально не содержит символов и свойство Length возвращает 0.
Члены типа StringBuilder
Тип StringBuilder в отличие от String представляет изменяемую строку. Это значит, что многие члены StringBuilder изменяют содержимое в массиве символов, не создавая новых объектов, размещаемых в управляемой куче. StringBuilder выделяет память для новых объектов только в двух случаях:
□ при динамическом построении строки, размер которой превышает установленную емкость;
□ при вызове метода ToString типа StringBuilder.
В табл. 14.2 представлены методы класса StringBuilder.
| Таблица 14.2. Члены класса StringBuilder
|
|
|
| Таблица 14.2 (продолжение)
|
|
|
Отмечу одно важное обстоятельство: большинство методов StringBuilder возвращают ссылку на тот же объект StringBuilder. Это позволяет выстроить в цепочку сразу несколько операций:
StringBuilder sb = new StringBuilder();
String s = sb.AppendFormat("{0} {1}", "Jeffrey", "Richter").
Replace(' ', '-')•Remove(4, 3).ToString();
Console.WriteLine(s); // "3eff-Richter"
У класса StringBuilder нет некоторых аналогов для методов класса String. Например, у класса String есть методы То Lowe г, ToUpper, EndsWith, PadLeft, Trim
и т. д., отсутствующие у класса StringBuilder. В то же время у класса StringBuilder есть расширенный метод Replace, выполняющий замену символов и строк лишь в части строки (а не во всей строке). Из-за отсутствия полного соответствия между методами иногда приходится прибегать к преобразованиям между String и StringBuilder. Например, сформировать строку, сделать все буквы прописными, а затем вставить в нее другую строку позволяет следующий код:
// Создаем StringBuilder для операций со строками StringBuilder sb = new StringBuilder();
// Выполняем ряд действий со строками, используя StringBuilder sb.AppendFormat("{0} {1}" "Jeffrey", "Richter").Replace(" ", "-");
// Преобразуем StringBuilder в String,
// чтобы сделать все символы прописными String s = sb. ToString(). ToUpperQ;
П Очищаем StringBuilder (выделяется память под новый массив Char) sb.Length = в;
II Загружаем строку с прописными String в StringBuilder // и выполняем остальные операции sb.Append(s).Insert(8, "Marc-");
// Преобразуем StringBuilder обратно в String s = sb.ToString();
// Выводим String на экран для пользователя Console.WriteLine(s); // "JEFFREY-Marc-RICHTER"
Этот код неудобен и неэффективен — и все из-за того, что StringBuilder не поддерживает все операции, которые может выполнить String. Надеюсь, в будущем Microsoft улучшит класс StringBuilder, дополнив его необходимыми методами для работы со строками.
Получение строкового представления объекта
Часто нужно получить строковое представление объекта, например, для отображения числового типа (такого, как Byte, Int32, Single и т. д.) и объекта DateTime.
Поскольку .NET Framework является объектно-ориентированной платформой, то каждый тип должен сам предоставить код, преобразующий «значение» экземпляра в некий строковый эквивалент. Выбирая способы решения этой задачи, разработчики FCL придумали паттерн программирования, предназначенный для повсеместного использования. Рассмотрим этот паттерн.
Для получения представления любого объекта в виде строки надо вызвать метод ToStning. Поскольку этот открытый виртуальный метод без параметров определен в классе System.Object, его можно вызывать для экземпляра любого типа. Семантически ToStning возвращает строку, которая представляет текущее значение объекта в формате, учитывающем текущие региональные стандарты вызвавшего потока. Строковое представление числа, к примеру, должно правильно отображать разделитель дробной части, разделитель групп разрядов и тому подобные параметры, устанавливаемые региональными стандартами вызывающего потока.
Реализация ToStning в типе System.Object просто возвращает полное имя типа объекта. В этом значении мало пользы, хотя для многих типов такое решение по умолчанию может оказаться единственно разумным. Например, как иначе представить в виде строки такие объекты, как FileStneam или Hashtable?
Типы, которые хотят представить текущее значение объекта в более содержательном виде, должны переопределить метод ToStning. Все базовые типы, встроенные в FCF (Byte, Int32, UInt64, Double и т. д.), имеют переопределенный метод ToStning, реализация которого возвращает строку с учетом региональных стандартов. В отладчике Visual Studio при наведении указателя мыши на соответствующую переменную появляется всплывающая подсказка. Текст этой подсказки формируется путем вызова метода ToStning этого объекта. Таким образом, при определении класса вы должны всегда переопределять метод ToStning, чтобы иметь качественную поддержку при отладке программного кода.
Форматы и региональные стандарты
У метода ToStning без параметров есть два недостатка. Во-первых, вызывающая программа не управляет форматированием строки, как, например, в случае, когда приложению нужно представить число в денежном или десятичном формате, в процентном или шестнадцатеричном виде. Во-вторых, вызывающая программа не может выбрать формат, учитывающий конкретные региональные стандарты. Второй недостаток создает проблемы скорее для серверных приложений, нежели для кода на стороне клиента. Изредка приложению требуется форматировать строку с учетом региональных стандартов, отличных от таковых у вызывающего потока. Для управления форматированием строки нужна версия метода ToStning, позволяющая задавать специальное форматирование и сведения о региональных стандартах.
Тип может предложить вызывающей программе выбор форматирования и региональных стандартов, если он реализует интерфейс System. IFonmattable:
public interface IFormattable {
String ToString(String format, IFormatProvider formatProvider);
}
В FCL у всех базовых типов (Byte, SByte, Intl6/UIntl6, Int32/UInt32, Int64/ UInt64, Single, Double, Decimal и DateTime) есть реализации этого интерфейса. Кроме того, есть такие реализации и у некоторых других типов, например GUID. К тому же каждый перечислимый тип автоматически реализует интерфейс IFormattable, позволяющий получит!) строковое выражение для числового значения, содержащегося в экземпляре перечислимого типа.
Метод ToString интерфейса IFormattable получает два параметра. Первый, format, — это строка, сообщающая методу способ форматирования объекта. Второй, formatProvider, — это экземпляр типа, который реализует интерфейс System. IFormatProvider. Этот тип предоставляет методу ToString информацию о региональных стандартах. Как — скоро узнаете.
Тип, реализующий метод ToString интерфейса IFormattable, определяет допустимые варианты форматирования. Если переданная строка форматирования неприемлема, тип должен генерировать исключение System. FormatException.
Многие типы FCL поддерживают несколько форматов. 11апример, тип DateTime поддерживает следующие форматы: "d" — даты в кратком формате, "D" — даты в полном формате, "g" — даты в общем формате, "М" — формат «месяц/день», "s" — сортируемые даты, "Т" —время, "и" — уннверсальноевремявстандарте18О8601, "U" — универсальное время в полном формате, "Y" — формат «год/месяц» и т. д. Все перечислимые типы поддерживают строки: "G" — общий формат, "F" — формат флагов, "D" — десятичный формат и "X" — шестнадцатеричный формат. Подробнее о форматировании перечислимых типов см. главу 15.
Кроме того, все встроенные числовые типы поддерживают следующие строки: "С" — формат валют, "D" — десятичный формат, "Е" — научный (экспоненциальный) формат, "F" — формат чисел с фиксированной точкой, "G" общий формат, "N"— формат чисел, "Р" — формат процентов, "R" — обратимый (round-trip) формат и "X" — шестнадцатеричный формат. Числовые типы поддерживают также шаблоны форматирования для случаев, когда обычных строк форматирования недостаточно. Шаблоны форматирования содержат специальные символы, позволяющие методу ToString данного типа отобразить нужное количество цифр, место разделителя дробной части, количество знаков в дробной части и т. д. Полную информацию о строках форматирования см. в разделе .NET Framework SDK, посвященном форматированию строк.
Если вместо строки форматирования передается null, это равносильно вызову метода ToString с параметром "G". Иначе говоря, объекты форматируют себя сами, применяя по умолчанию «общий формат». Разрабатывая реализацию типа, выберите формат, который, по вашему мнению, будет использоваться чаще всего; это и будет «общий формат». Кстати, вызов метода ToString без параметров означает представление объекта в общем формате.
Закончив со строками форматирования, перейдем к региональным стандартам. По умолчанию форматирование выполняется с учетом региональных стандартов, связанных с вызывающим потоком. Это свойственно методу ToString без параметров и методу ToString интерфейса IFormattable со значением null в качестве formatProvider.
Региональные стандарты влияют на форматирование чисел (включая денежные суммы, целые числа, числа с плавающей точкой и проценты), дат и времени. Метод ToStning для типа Guid, представляющего код GUID, возвращает строку, отображающую только значение GUID. Региональные стандарты вряд ли нужно учитывать при создании такой строки, так как она используется только самой программой.
При форматировании числа метод ToString «анализирует» параметр formatProvider. Если это null, метод ToString определяет региональные стандарты, связанные с вызывающим потоком, считывая свойство System. Threading. Thread. CurrentThread. CurrentCulture. Оно возвращает экземпляр типа System. Globalization.Culturelnfo.
Получив объект, ToString считывает его свойства NumberFormat для форматирования числа или DateTimeFormat для форматирования даты. Эти свойства возвращают экземпляры System.Globalization.NumberFormatlnfо и System. Globalization. DateT imeFormatlnf о соответственно. Тип NumberFormatlnf о описывает группу свойств, таких как CurrencyDecimalSeparator, CurrencySymbol, NegativeSign, NumberGroupSeparator и PercentSymbol. Аналогично, у типа Date- TimeFormatlnfo описаны такие свойства, как Calendar, DateSeparator, DayNames, LongDatePattern, ShortTimePattern и TimeSeparator. Метод ToString считывает эти свойства при создании и форматировании строки.
При вызове метода ToString интерфейса IFormattable вместо null можно передать ссылку на объект, тип которого реализует интерфейс IFormatProvider:
public interface IFormatProvider {
Object GetFormat(Type formatType);
}
Основная идея применения интерфейса IFormatProvider такова: реализация этого интерфейса означает, что экземпляр типа «знает», как обеспечить учет региональных стандартов при форматировании, а региональные стандарты, связанные с вызывающим потоком, игнорируются.
Тип System.Globalization.Culturelnfo — один из немногих определенных в FCL типов, в которых реализован интерфейс IFormatProvider. Если нужно форматировать строку, скажем, для Вьетнама, следует создать объект Culturelnfo и передать его ToString как параметр formatProvider. Вот как формируют строковое представление числа Decimal во вьетнамском формате денежной величины:
Decimal price = 123.54М;
String s = price.ToString("C", new CultureInfo("vi-VN"));
MessageBox.Show(s);
Если собрать и запустить этот код, появится информационное окно (рис. 14.5). Метод ToString типа Decimal, исходя из того, что аргумент formatProvider отличен от null, вызывает метод GetFormat объекта:
NumberFormatlnfo nfi = (NumberFormatlnfo)
formatProvider.GetFormat(typeof(NumberFormatInfo));
|
|
Рис. 14.5. Числовое значение во вьетнамском формате денежной величины
Так ToString запрашивает у объекта (Culturelnfo) данные о надлежащем форматировании чисел. Числовым типам (вроде Decimal) достаточно получить лишь сведения о форматировании чисел. Однако другие типы (вроде DateTime) могут вызывать GetFormat иначе:
DateTimeFormatlnfo dtfi = (DateTimeFormatlnfo)
formatProvider.GetFormat(typeof(DateTimeFormat Info));
Раз параметр GetFormat может идентифицировать любой тип. метод достаточно гибок, чтобы запрашивать любую форматную информацию. Сейчас типы .NET Framework с помощью GetFormat запрашивают информацию только о числах и дате/времени; в будущем появится возможность запрашивать другие сведения.
Кстати, чтобы получить строку для объекта, который не отформатирован в соответствии с определенными региональными стандартами, вызовите статическое свойство InvariantCulture класса System. Globalization .Culturelnfo и передайте возвращенный объект как параметр formatProvider методу ToString:
Decimal price = 123.54И-
String s = price.ToString("C", Culturelnfo.InvariantCulture)•
MessageBox.Show)s)•
После компоновки и запуска этого кода появится информационное окно (рис, 14.6). ()братите внимание на первый символ в выходной строке: н. ()н представляет междунарс>дное обозначение денежного знака (U+00A4).
|
Рис. 14.6. Числовое значение в формате, представляющем абстрактную денежную единицу |

Обычно нет необходимости выводить строку в формате инвариантных региональных стандартов. В типовом случае нужно просто сохранить строку в файле, отложив ее разбор на будущее.
В FCL интерфейс IFormatProvider реализуется только тремя типами: уже упоминавшимся типом Culturelnfo, а также типами NumberFormatlnfo и DateTimeFormatlnfo. Когда GetFormat вызывается для объекта NumberFormatlnfo, метод проверяет, является ли запрашиваемый тип NumberFormatlnfo. Если да, возвращается this, нет — null. Аналогичным образом вызов GetFormat для объекта DateTimeFormatlnfo возвращает this, если запрашиваемый тип DateTimeFormatlnfo, и null — если нет. Реализация этого интерфейса для этих двух типов упрощает программирование. Чаще всего при получении строкового представления объекта вызывающая программа задает только формат, довольствуясь региональными стандартами, связанными с вызывающим потоком. Поэтому обычно мы вызываем ToString, передавая строку форматирования и null как параметр formatProvider. Для упрощения работы с ToString во многие типы включены перегруженные версии метода ToString. Например, тип Decimal предоставляет четыре перегруженных метода ToString:
// Эта версия вызывает ToString(null, null)
// Смысл: общий формат, региональные стандарты потока public override String ToStringO;
// В этой версии выполняется полная реализация ToString // Здесь реализован метод ToString интерфейса IFormattable // Смысл: и формат, и региональные стандарты задаются вызывающей программой public String ToString(String format, IFormatProvider formatProvider);
// Эта версия просто вызывает ToString(format, null)
// Смысл: формат, заданный вызывающей программой,
// и региональные стандарты потока public String ToString(String format);
// Эта версия просто вызывает ToString(null, formatProvider)
// Здесь реализуется метод ToString интерфейса IConvertible // Смысл: общий формат и региональные стандарты,
// заданные вызывающей программой
public String ToString(IFormatProvider formatProvider);
Форматирование нескольких объектов в одну строку
До сих пор речь шла о том, как конкретный тип форматирует свои объекты. Однако иногда требуется сформировать строку из множества отформатированных объектов. В следующем примере в строку включаются дата, имя человека и его возраст:
String s = String.Format("On {0}, {1} is {2} years old.", new DateTime(2012, 4, 22, 14, 35, 5), "Aidan", 9);
Console.WriteLine(s);
Если собрать и запустить этот код в потоке с региональным стандартом en-US, на выходе получится строка:
On 4/22/2012 2:35:05 PM, Aldan is 9 years old.
Статический метод Format типа String получает строку форматирования, в которой подставляемые параметры обозначены своими номерами в фигурных скобках. В этом примере строка форматирования указывает методу Format подставить вместо {0} первый после строки форматирования параметр (текущие дату и время), вместо {1} — следующий параметр (Aidan) и вместо {2} — третий, последний параметр (9).
Внутри метода Format для каждого объекта вызывается метод ToString, получающий его строковое представление. Все возвращенные строки затем объединяются, а полученный результат возвращается методом. Все было бы замечательно, однако нужно иметь в виду, что ко всем объектам применяется общий формат и региональные стандарты вызывающего потока.
Чтобы расширить стандартное форматирование объекта, нужно добавить внутрь фигурных скобок строку форматирования. В частности, следующий код отличается от предыдущего только наличием строк форматирования для подставляемых параметров 0 и 2:
String s = String.Format("On {0:D}, {1} is {2:E} years old.",
new DateTime(2012, 4, 22, 14, 35, 5), "Aidan", 9);
Console.Write Line(s);
Если собрать и запустить этот код в потоке с региональным стандартом en-US,
на выходе вы увидите строку:
On Sunday, April 22, 2012, Aidan is 9.000000E+000 years old.
Разбирая строку форматирования, метод Format «видит», что для подставляемого параметра 0 нужно вызывать описанный в его интерфейсе IFormattable метод ToString, которому передаются в качестве параметров D и null. Аналогично, Format вызывает метод ToString для интерфейса IFormattable параметра 2, передавая ему Е и null. Если у типа нет реализации интерфейса IFormattable, то Format вызывает его метод ToString без параметров, а в результирующую строку добавляется формат по умолчанию.
У класса String есть несколько перегруженных версий статического метода Format. В одну из них передается объект, реализующий интерфейс IFormatProvider, в этом случае при форматировании всех подставляемых параметров можно применять региональные стандарты, задаваемые вызывающей программой. Очевидно, Format вызывает метод ToString для каждого объекта, передавая ему полученный объектIFormatProvider.
Если вместо String для формирования строки применяется StringBuilder, можно вызывать метод AppendFormat класса StringBuilder. Этот метод работает так же, как Format класса String, за исключением того, что результат форматирования добавляется к массиву символов StringBuilder. Точно так же в AppendFormat передается строка форматирования и имеется версия, которой передается IFormatProvider.
У типа System. Console тоже есть методы Write и WniteLine, которым передаются строка форматирования и замещаемые параметры. Однако у Console нет перегруженных методов Write и WriteLine, позволяющих передавать IFormatProvider. Если при форматировании строки нужно применить определенные региональные стандарты, вызовите метод Format класса String, передав ему нужный объект IFormatProvider, а затем подставьте результирующую строку в метод Write или WriteLine класса Console. Это не намного усложнит задачу, поскольку, как я уже отмечал, код на стороне клиента редко при форматировании применяет региональные стандарты, отличные от тех, что связаны с вызывающим потоком.
Создание собственного средства форматирования
Уже на этом этапе понятно, что платформа .NET Framework обладает весьма гибкими средствами форматирования. Но это не все — вы можете написать метод, который будет вызываться в AppendFormat типа StringBuilder независимо от того, для какого объекта выполняется форматирование. Иначе говоря, для каждого объекта вместо метода ToString метод AppendFormat вызовет вашу функцию, которая будет форматировать один или несколько объектов так, как вам нужно. Следующее описание относится также к методу Format типа String.
Попробую пояснить работу этого механизма на примере. Допустим, вам нужен форматированный HTML-текст, который пользователь будет просматривать в браузере, причем все значения Int32 должны выводиться полужирным шрифтом. Для этого всякий раз, когда значение типа Int32 форматируется в String, нужно обрамлять строку тегами полужирного шрифта: <В> и </В>. Следующий фрагмент показывает, как легко это делается:
using System; using System.Text; using System.Threading;
public static class Program { public static void Main() {
StringBuilder sb = new StringBuilderQ;
sb.AppendFormat(new BoldInt32s(), "{0} {1} "3eff", 123,
DateTime.Now);
Console.WriteLine(sb);
}
}
internal sealed class BoldInt32s : IFormatProvider, ICustomFormatter { public Object GetFormat(Type formatType) {
if (formatType == typeof(ICustomFormatter)) return this; return Thread.CurrentThread.CurrentCulture.GetFormat(formatType);
} public String Format(String format, Object arg, IFormatProvider
formatProvider) {
String s;
IFormattable formattable = arg as IFormattable;
if (formattable == null) s = arg.ToString();
else s = formattable.ToString(format, formatProvider);
if (arg.GetTypeQ == typeof(Int32)) return "<B>" + s + "</B>"; return s;
}
После компиляции и запуска кода в потоке с региональным стандартом en-US появится строка (дата может отличаться):
Jeff <В>123</В> September 1
Метод Main конструирует пустой объект StringBuilder, к которому затем добавляется форматированная строка. При вызове Append Format в качестве первого параметра подставляется экземпляр класса BoldInt32s. В нем, помимо рассмотренного ранее интерфейса IFormatProvider, реализован также интерфейс ICustomFormatter:
public interface ICustomFormatter {
String Format(String format. Object arg,
IFormatProvider formatProvider);
}
Метод Format этого интерфейса вызывается всякий раз, когда методу Append- Format класса StringBuilder нужно получить строку для объекта. Внутри этого метода у нас появляется возможность гибкого управления процессом форматирования строки. Заглянем внутрь метода Append Format, чтобы узнать поподробнее, как он работает. Следующий псевдокод демонстрирует работу метода AppendFormat:
public StringBuilder AppendFormat(IFormatProvider formatProvider,
String format, params ObJect[] args) {
// Если параметр IFormatProvider передан, выясним,
// предоставляет ли он объект ICustomFormatter ICustomFormatter cf = null;
if (formatProvider != null)
cf = (ICustomFormatter)
formatProvider.GetFormat(typeof(ICustomFormatter));
// Продолжаем добавлять литеральные символы (не показанные // в этом псевдокоде) и замещаемые параметры в массив символов // объекта StringBuilder.
Boolean MoreReplaceableArgumentsToAppend = true; while (MoreReplaceableArgumentsToAppend) {
продолжение
// argFormat ссылается на замещаемую строку форматирования,
// полученную из параметра format String argFormat = /* ... */;
// argObj ссылается на соответствующий элемент // параметра-массива args Object argObj = /* ... */;
II argStr будет указывать на отформатированную строку,
// которая добавляется к результирующей строке String argStr = null;
// Если есть специальный объект форматирования,
// используем его для форматирования аргумента if (cf != null)
argStr = cf.Format(argFormat, argObj, formatProvider);
// Если специального объекта форматирования нет или он не выполнял // форматирование аргумента, попробуем еще что-нибудь if (argStr == null) {
// Выясняем, поддерживает ли тип аргумента // дополнительное форматирование
IFormattable formattable = argObj as IFormattable; if (formattable != null) {
// Да; передаем методу интерфейса для этого типа
// строку форматирования и класс-поставщик
argStr = formattable.ToString(argFormat, formatProvider);
} else {
// Нет; используем общий формат с учетом // региональных стандартов потока if (argObj != null) argStr = argObj.ToStringQ; else argStr = String.Empty;
}
}
// Добавляем символы из argStr в массив символов (поле - член класса)
/* ... */
// Проверяем, есть ли еще параметры, нуждающиеся в форматировании MoreReplaceableArgumentsToAppend = /* ... */;
}
return this;
}
Когда Main обращается к методу AppendFormat, тот вызывает метод GetFormat моего поставщика формата, передавая ему тип ICustomFonmatten. Метод GetFormat, описанный в моем типе BoldInt32s, «видит», что запрашивается ICustomFormatter, и возвращает ссылку на собственный объект, потому что он реализует этот интерфейс. Если из GetFormat запрашивается какой-то другой тип, я вызываю метод GetFormat для объекта Culturelnfo, связанного с вызывающим потоком.
При необходимости форматировать замещаемый параметр AppendFormat вызывается метод Format класса ICustomFormatter. В моем примере вызывается
метод Format, описанный моим типом BoldInt32s. В своем методе Format я проверяю, поддерживает ли форматируемый объект расширенное форматирование посредством интерфейса IFormattable. Если нет, то для форматирования объекта я вызываю простой метод ToString без параметров (унаследованный от Object); если да — вызываю расширенный метод ToString, передавая ему строку форматирования и поставщика формата.
Теперь, имея форматированную строку, я проверяю, имеет ли объект тип Int32, и если да, заключаю строку в HTML-теги <В> и </В>, после чего возвращаю полученную строку. Если тип объекта отличается от Int32, просто возвращаю форматированную строку без дополнительной обработки.
Получение объекта посредством разбора строки
В предыдущем разделе я рассказал о получении представления определенного объекта в виде строки. Здесь мы пойдем в обратном направлении: рассмотрим, как получить представление конкретной строки в виде объекта. Получать объект из строки требуется не часто, однако иногда это может оказаться полезным. В компании Microsoft осознали важность формализации механизма, посредством которого строки можно разобрать на объекты.
Любой тип, способный разобрать строку, имеет открытый, статический метод Parse. Он получает St ring, а на выходе возвращает экземпляр данного типа; в каком- то смысле Parse ведет себя как фабрика. В FCL метод Parse поддерживается всеми числовыми типами, а также типами DateTime, TimeSpan и некоторыми другими (например, типами данных SQL).
Посмотрим, как получить из строки целочисленный тип. Все числовые типы (Byte, SByte, Intl6/UIntl6,Int32/UInt32,Int64/UInt64, Single, Double, Decimal и Biglnteger) имеют минимум один метод Parse. Вот как выглядит метод Parse для типа Int32 (для других числовых типов методы Parse выглядят аналогично).
public static Int32 Parse(String s, NumberStyles style, IFormatProvider
provider);
Взглянув на прототип, вы сразу поймете суть работы этого метода. Параметр s типа String идентифицирует строковое представление числа, которое необходимо разобрать для получения объекта Int32. Параметр style типа System. Globalization .NumberStyles — это набор двоичных флагов для идентификации символов, которые метод Parse должен найти в строке. А параметр provider типа IFormatProvider идентифицирует объект, используя который метод Parse может получить информацию о региональных стандартах, о чем речь шла ранее.
Так, в следующем фрагменте при обращении к Parse генерируется исключение System. FormatException, так как в начале разбираемой строки находится пробел:
Int32 х = Int32.Parse(" 123", NumberStyles.None, null);
Чтобы «пропустить» пробел, надо вызвать Parse с другим параметром style:
Int32 х = Int32.Parse(" 123", NumberStyles.AllowLeadingWhite, null);
Подробнее о флагах и стандартных комбинациях, определенных в типе NumberStyles, см. документацию на .NET Framework SDK.
Вот пример синтаксического разбора строки шестнадцатеричного числа:
Int32 х = Int32.Parse("lA", NumberStyles.HexNumber, null);
Console.WrlteLlne(x); // Отображает "26".
Этому методу Parse передаются три параметра. Для удобства у многих типов есть перегруженные версии Parse с меньшим числом параметров. Например, у типа Int32 четыре перегруженные версии метода Parse:
// Передает NumberStyles.Integer в качестве параметра стиля // и информации о региональных стандартах потока public static Int32 Parse(String s);
// Передает информацию о региональных стандартах потока public static Int32 Parse(String s, NumberStyles style);
// Передает NumberStyles.Integer в качестве параметра стиля public static Int32 Parse(String s, IFormatProvider provider)
// Тот метод, о котором я уже рассказал в этом разделе public static int Parse(String s, NumberStyles style,
IFormatProvider provider);
У типа DateTime также есть метод Parse:
public static DateTime Parse(String s,
IFormatProvider provider, DateTimeStyles styles);
Этот метод действует подобно методу Parse для числовых типов за исключением того, что методу Parse типа DateTime передается набор двоичных флагов, описанных в перечислимом типе System.Globalization.DateTimeStyles, а не в типе NumberStyles. Подробнее о флагах и стандартных комбинациях, определенных в типе DateTimeStyles, см. документацию на .NET Framework SDK.
Для удобства тип DateTime содержит три перегруженных метода Parse:
// Передается информация о региональных стандартах потока,
//а также DateTimeStyles.None в качестве стиля public static DateTime Parse(String s);
// DateTimeStyles.None передается в качестве стиля
public static DateTime Parse(String s, IFormatProvider provider);
// Этот метод рассмотрен мной в этом разделе public static DateTime Parse(String s,
IFormatProvider provider, DateTimeStyles styles);
Даты и время плохо поддаются синтаксическому разбору. Многие разработчики столкнулись с тем, что метод Parse типа DateTime ухитряется получить дату и время из строки, в которой нет ни того, ни другого. Поэтому в тип DateTime введен метод ParseExact, который анализирует строку согласно некоему шаблону, показывающему, как должна выглядеть строка, содержащая дату или время, и как выполнять ее разбор. О шаблонах форматирования см. раздел, посвященный DateTimeFormatlnfo, в документации на .NET Framework SDK.
ПРИМЕЧАНИЕ
Некоторые разработчики сообщили в Microsoft о следующем факте: если при многократном вызове Parse этот метод генерирует исключения (из-за неверных данных, вводимых пользователями), это отрицательно сказывается на производительности приложения. Для таких требующих высокой производительности случаев в Microsoft создали методы TryParse для всех числовых типов данных, для DateTime, TimeSpan и даже для IPAddress. Вот как выглядит один из двух перегруженных методов TryParse типа Int32:
public static Boolean TryParse(String s, NumberStyles style,
IFormatProvider provider, out Int32 result);
Как видите, метод возвращает true или false, информируя, удастся ли разобрать строку в объект Int32. Если метод возвращает true, переменная, переданная по ссылке в результирующем параметре, будет содержать полученное в результате разбора числовое значение. Паттерн ТгуХхх обсуждается в главе 20.
Кодировки: преобразования между символами и байтами
\\6п32-программистам часто приходится писать код, преобразующий символы и строки из Unicode в Multi-Byte Character Set (MBCS). Поскольку я тоже этим занимался, могу авторитетно утверждать, что дело это очень нудное и чреватое ошибками. В CLR все символы представлены 16-разрядными кодами Юникода, а строки состоят только из 16-разрядных символов Юникода. Это намного упрощает работу с символами и строками в период выполнения.
Однако порой текст требуется записать в файл или передать его по сети. Когда текст состоит главным образом из символов английского языка, запись и передача 16-разрядных значений становится неэффективной, поскольку половина байтов содержит нули. Поэтому разумнее сначала закодировать (encode) 16-разрядные символы в более компактный массив байтов, чтобы потом декодировать (decode) его в массив 16-разрядных значений.
Кодирование текста помогает также управляемым приложениям работать со строками, созданными в системах, не поддерживающих Юникод. Так, чтобы создать текстовый файл, предназначенный для японской версии Windows 95, нужно сохранить текст в Юникоде, используя код Shift-JIS (кодовая страница 932). Аналогично с помощью кода Shift-JIS можно прочитать в CLR текстовый файл, созданный в японской версии Windows 95.
Кодирование обычно выполняется перед отправкой строки в файл или сетевой поток с помощью типов System. 10. BinaryWriter и System. 10. StreamWriter. Декодирование обычно выполняется при чтении из файла или сетевого потока с помощью типов System. 10. BinaryReader и System. 10. St reamReader. Если кодировка явно не указана, все эти типы по умолчанию используют код UTF-8 (UTF означает Unicode Transformation Format). В этом разделе операции чтения и записи строк в потоки рассмотрены более подробно.
К счастью, в FCF есть типы, упрощающие операции кодирования и декодирования. К наиболее часто используемым кодировкам относят UTF-f 6 и UTF-8.
□ UTF-f 6 кодирует каждый 16-разрядный символ в 2 байта. При этом символы остаются, как были, и сжатия данных не происходит — скорость процесса отличная. Часто код UTF-f 6 называют еще Юникод-кодировкой (Unicode encoding). Заметьте также, что, используя UTF-f 6, можно выполнить преобразование из прямого порядка байтов (big endian) в обратный (little endian), и наоборот.
□ UTF-8 кодирует некоторые символы одним байтом, другие — двумя байтами, третьи — тремя, а некоторые — четырьмя. Символы со значениями ниже 0x0080, которые в основном используются в англоязычных странах, сжимаются в один байт. Символы между 0x0080 и 0x07FF, хорошо подходящие для европейских и среднеазиатских языков, преобразуются в 2 байта. Символы, начиная с 0x0800 и выше, предназначенные для языков Восточной Азии, преобразуются в 3 байта. И наконец, пары символов-заместителей (surrogate character pairs) записываются в 4 байта. UTF-8 — весьма популярная система кодирования, однако она уступает UTF-16, если нужно кодировать много символов со значениями от 0x0800 и выше.
Хотя для большинства случаев подходят кодировки UTF-16 и UTF-8, FCL поддерживает и менее популярные кодировки.
□ UTF-32 кодирует все символы в 4 байта. Эта кодировка используется для создания простого алгоритма прохода символов, в котором не требуется разбираться с символами, состоящими из переменного числа байтов. В частности, UTF-32 упрощает работу с символами-заместителями, так как каждый символ состоит ровно из 4 байт. Ясно, что UTF-32 неэффективна с точки зрения экономии памяти, поэтому она редко используется для сохранения или передачи строк в файл или по сети, а обычно применяется внутри программ. Стоит также заметить, что UTF-32 можно задействовать для преобразования прямого порядка следования байтов в обратный, и наоборот.
□ UTF-7 обычно используется в старых системах, где под символ отводится 7 разрядов. Этой кодировки следует избегать, поскольку обычно она приводит не
к сжатию, а к раздуванию данных. Комитет Unicode Consortium настоятельно рекомендует отказаться от применения UTF-7.
□ ASCII кодирует 16-разрядные символы в ASCII-символы; то есть любой 16- разрядный символ со значением меньше 0x0080 переводится в одиночный байт. Символы со значением больше 0x007F не поддаются этому преобразованию, и значение символа теряется. Для строк, состоящих из символов в ASCII-диапазоне (от 0x00 до 0x7F), эта кодировка сжимает данные наполовину, причем очень быстро (поскольку старший байт просто отбрасывается). Данный код не годится для символов вне ASCII-диапазона, так как теряются значения символов.
Наконец, FCL позволяет кодировать 16-разрядные символы в произвольную кодовую страницу. Как и в случае с ASCII, это преобразование может привести к потере значений символов, не отображаемых в заданной кодовой странице. Используйте кодировки UTF-16 и UTF-8 во всех случаях, когда не имеете дело со старыми файлами и приложениями, в которых применена какая-либо иная кодировка.
Чтобы выполнить кодирование или декодирование набора символов, сначала надо получить экземпляр класса, производного от System.Text.Encoding. Абстрактный базовый класс Encoding имеет несколько статических свойств, каждое из которых возвращает экземпляр класса, производного от Encoding.
Пример кодирования и декодирования символов с использованием кодировки UTF-8:
using System; using System.Text;
public static class Program { public static void Main() {
// Кодируемая строка String s = "Hi there.";
// Получаем объект, производный от Encoding, который "умеет" выполнять // кодирование и декодирование с использованием UTF-8 Encoding encodingUTF8 = Encoding.UTF8;
// Выполняем кодирование строки в массив байтов Byte[] encodedBytes = encodingUTF8.GetBytes(s);
// Показываем значение закодированных байтов Console.WriteLine("Encoded bytes: " +
BitConverter.ToString(encodedBytes));
// Выполняем декодирование массива байтов обратно в строку String decodedString = encodingUTF8.GetString(encodedBytes);
// Показываем декодированную строку
Console.WriteLine("Decoded string: " + decodedString);
}
Вот результат выполнения этой программы:
Encoded bytes: 48-69-20-74-68-65-72-65-2Е Decoded string: Hi there.
Помимо UTF8, у класса Encoding есть и другие статические свойства: Unicode, BigEndianUnicode, UTF32, UTF7, ASCII и Default. Последнее возвращает объект, который выполняет кодирование и декодирование с учетом кодовой страницы пользователя, заданной с помощью утилиты Regional and Language Options (Язык и региональные стандарты) панели управления (см. описание Win32-функции GetACP). Однако свойство Default применять не рекомендуется, потому что поведение приложения будет зависеть от настройки машины, то есть при изменении кодовой таблицы, предлагаемой по умолчанию, или выполнении приложения на другой машине приложение поведет себя иначе.
Наряду с перечисленными свойствами, у Encoding есть статический метод GetEncoding, позволяющий указать кодовую страницу (в виде числа или строки). Метод GetEncoding возвращает объект, выполняющий кодирование/декодирование, используя заданную кодовую страницу. Например, можно вызвать GetEncoding с параметром "Shift-DIS" или 932.
При первом запросе объекта кодирования свойство класса Encoding (или его метод GetEncoding) создает и возвращает объект для требуемой кодировки. При последующих запросах такого же объекта будет возвращаться уже имеющийся объект; то есть при очередном запросе новый объект не создается. Благодаря этому сокращается число объектов и снижается нагрузка на кучу.
Кроме статических свойств и метода GetEncoding класса Encoding, для создания экземпляра класса кодирования можно задействовать классы System.Text. UnicodeEncoding, System.Text.UTF8Encoding, System.Text.UTF32Encoding,System. Text .UTF7Encoding или System.Text .ASCIIEncoding. Только помните, что в этих случаях в управляемой куче появятся новые объекты, что неминуемо отрицательно скажется на производительности.
У классов UnicodeEncoding,UTF8Encoding, UTF32Encoding и UTF7Encoding есть несколько конструкторов, дающих дополнительные возможность в плане управления процессом кодирования и маркерами последовательности байтов (Byte Order Mark, BOM). Первые три класса также имеют конструкторы, которые позволяют заставить класс генерировать исключение при декодировании некорректной последовательности байтов; эти конструкторы нужно использовать для обеспечения безопасности приложения и защиты от приема некорректных входных данных.
Возможно, при работе с BinaryWriter или StreamWriter вам придется явно создавать экземпляры этих классов. У класса ASCIIEncoding лишь один конструктор, и поэтому возможности управления кодированием здесь невелики. Получать объект ASCIIEncoding (точнее, ссылку на него) всегда следует путем запроса свойства ASCII класса Encoding. Никогда не создавайте самостоятельно экземпляр класса ASCIIEncoding — при этом создаются дополнительные объекты в куче, что отрицательно сказывается на производительности.
Вызвав для объекта, производного от Encoding, метод GetBytes, можно преобразовать массив символов в массив байтов. (У этого метода есть несколько перегруженных версий.) Для обратного преобразования вызовите метод GetChars или более удобный GetString. (Эти методы также имеют несколько перегруженных версий.) Работа методов GetBytes и GetString продемонстрирована в приведенном ранее примере.
У всех типов, производных от Encoding, есть метод GetByteCount, который, не выполняя реального кодирования, подсчитывает количество байтов, необходимых для кодирования данного набора символов. Он может пригодиться для выделения памяти под массив байтов. Имеется также аналогичный метод GetCharCount, который возвращает число подлежащих декодированию символов, не выполняя реального декодирования. Эти методы полезны, когда требуется сэкономить память и многократно использовать массив.
Методы GetByteCount и GetCharCount работают не так быстро, поскольку для получения точного результата они должны анализировать массив символов/байтов. Если скорость важнее точности, вызывайте GetMaxByteCount или GetMaxCharCount — оба метода принимают целое число, в котором задается число символов или байтов соответственно, и возвращают максимально возможный размер массива.
Каждый объект, производный от Encoding, имеет набор открытых неизменяемых свойств, дающих более подробную информацию о кодировании. Подробнее см. описание этих свойств в документации на .NET Framework SDK.
Чтобы продемонстрировать свойства и их назначение, я написал программу, в которой эти свойства вызываются для разных вариантов кодирования:
using System; using System.Text;
public static class Program { public static void Main() {
foreach (Encodinglnfo ei in Encoding.GetEncodings()) {
Encoding e = ei.GetEncodingQ;
Console.WriteLine("{l}{0}" +
M\tCodePage={2}, WindowsCodePage={3}{0}“ +
M\tWebName={4}, HeaderName={5}, BodyName={6}{0}“ +
M\tIsBrowserDisplay={7}, IsBrowserSave={8}{0}“ +
M\tIsMailNewsDisplay={9}, IsMailNewsSave={10}{0}“,
Environment.NewLine,
e.EncodingName, e.CodePage, e.WindowsCodePage, e.WebName, e.HeaderName, e.BodyName, e.IsBrowserDisplay, e.IsBrowserSave, e.IsMailNewsDisplay, e.IsMailNewsSave);
}
}
}
Вот результат работы этой программы (текст сокращен для экономии бумаги):
IBM EBCDIC (US-Canada)
CodePage=37, WindowsCodePage=1252 WebName=IBM037, HeaderName=IBM037, BodyName=IBM037 IsBrowserDisplay=Falsej IsBrowsenSave=False IsMailNewsDisplay=Falsej IsMailNewsSave=False
OEM United States
CodePage=437, WindowsCodePage=1252 WebName=IBM437j HeaderName=IBM437j BodyName=IBM437 IsBrowserDisplay=Falsej IsBrowserSave=False IsMailNewsDisplay=Falsej IsMailNewsSave=False
IBM EBCDIC (International)
CodePage=500j WindowsCodePage=1252 WebName=IBM500j HeaderName=IBM500j BodyName=IBM500 IsBrowserDisplay=Falsej IsBrowserSave=False IsMailNewsDisplay=Falsej IsMailNewsSave=False
Arabic (ASMO 708)
CodePage=708, WindowsCodePage=1256
WebName=ASMO-708, HeaderName=ASMO-708j BodyName=ASMO-708 IsBrowserDisplay=True, IsBrowserSave=True IsMailNewsDisplay=False, IsMailNewsSave=False
Unicode
CodePage=1200, WindowsCodePage=1200 WebName=utf-16, HeaderName=utf-16, BodyName=utf-16 IsBrowserDisplay=False, IsBrowserSave=True IsMailNewsDisplay=False, IsMailNewsSave=False
Unicode (Big-Endian)
CodePage=1201, WindowsCodePage=1200
WebName=unicodeFFFE, HeaderName=unicodeFFFEJ BodyName=unicodeFFFE IsBrowserDisplay=False, IsBrowserSave=False IsMailNewsDisplay=False, IsMailNewsSave=False
Western European (DOS)
CodePage=850, WindowsCodePage=1252 WebName=ibm850, HeaderName=ibm850, BodyName=ibm850 IsBrowserDisplay=False, IsBrowserSave=False IsMailNewsDisplay=False, IsMailNewsSave=False
Unicode (UTF-8)
CodePage=65001, WindowsCodePage=1200 WebName=utf-8, HeaderName=utf-8, BodyName=utf-8 IsBrowserDisplay=True, IsBrowserSave=True IsMailNewsDisplay=True, IsMailNewsSave=True
Обзор наиболее популярных методов классов, производных от Encoding, завершает табл. 14.3.
| Таблица 14.3. Методы классов, производных от Encoding
|
|
|
Кодирование и декодирование потоков символов и байтов
Представьте, что вы читаете закодированную в UTF-16 строку с помощью объекта System.Net.Sockets.NetworkStream. Весьма вероятно, что байты из потока поступают группами разного размера, например сначала придут 5 байт, а затем 7. В UTF-1 б каждый символ состоит из двух байт. Поэтому в результате вызова метода GetString класса Encoding с передачей первого массива из 5 байт будет возвращена строка, содержащая только два символа. При следующем вызове GetString из потока поступят следующие 7 байт, и GetString вернет строку, содержащую три символа, причем все неверные!
Причина искажения данных состоит в том, что ни один из производных от Encoding классов не отслеживает состояние потока между двумя вызовами своих методов. Если вы выполняете кодирование или декодирование символов и байтов, поступающих порциями, то вам придется приложить дополнительные усилия для отслеживания состояния между вызовами, чтобы избежать потери данных.
Чтобы выполнить декодирование порции данных, следует получить ссылку на производный от Encoding объект (как описано в предыдущем разделе) и вызвать его метод GetDecoder. Этот метод возвращает ссылку на вновь созданный объект типа, производного от класса System. Text. Decoder. Класс Decoder, подобно классу Encoding, является абстрактным базовым классом. В документации .NET Framework SDK вы не найдете классов, которые представляют собой конкретные реализации класса Decoder, хотя FCL определяет группу производных от Decoder классов. Все эти классы являются внутренними для FCL, однако метод GetDecoder может создать экземпляры этих классов и вернуть их коду вашего приложения.
У всех производных от Decoder классов существует два метода: GetChars и GetCharCount. Естественно, они служат для декодирования массивов байтов и работают аналогично рассмотренным ранее методам GetChars и GetCharCount класса Encoding. Когда вы вызываете один из них, он декодирует массив байтов, насколько это возможно. Если в массиве не хватает байтов для формирования символа, то оставшиеся байты сохраняются внутри объекта декодирования. При следующем вызове одного из этих методов объект декодирования берет оставшиеся байты и складывает их с вновь полученным массивом байтов — благодаря этому декодирование данных, поступающих порциями, выполняется корректно. Объекты Decoder весьма удобны для чтения байтов из потока.
Тип, производный от Encoding, может служить для кодирования/декодирования без отслеживания состояния. Однако тип, производный от Decoder, можно использовать только для декодирования. Чтобы выполнить кодирование строки порциями, вместо метода GetDecoder класса Encoding применяется метод GetEncoder. Он возвращает вновь созданный объект, производный от абстрактного базового класса System.Text.Encoder. И опять, в документации на .NET Framework SDK нет описания классов, представляющих собой конкретную реализацию класса Encoder, хотя в FCL определена группа производных от Encoder классов. Подобно классам, производным от Decoder, они являются внутренними для FCL, однако метод GetEncoder может создавать экземпляры этих классов и возвращать их коду приложения.
Все классы, производные от Encoder, имеют два метода: GetBytes и GetByteCount. При каждом вызове объект, производный от Encoder, отслеживает оставшуюся необработанной информацию, так что данные могут кодироваться по фрагментам.
Кодирование и декодирование строк в кодировке Base-64
В настоящее время кодировки UTF-16 и UTF-8 весьма популярны. Также весьма часто применяется кодирование последовательностей байтов в строки в кодировке base-64. В FCL есть методы для кодирования и декодирования в кодировке base-64. Было бы логично предположить, что для этой цели используется тип, производный от Encoding, но по какой-то причине кодирование и декодирование base-64 выполняется с помощью статических методов, предоставляемых типом System.Convert.
Чтобы декодировать строку в кодировке base-64 в массив байтов, вызовите статический метод FromBase64String или FromBase64CharArray класса Convert. Для декодирования массива байтов в строку base-64 служит статический метод ToBase64String или ToBase64CharArray класса Convert. Пример использования этих методов:
using System;
public static class Program { public static void Main() {
// Получаем набор из 10 байт, сгенерированных случайным образом Byte[] bytes = new Byte[10]; new Random().NextBytes(bytes);
// Отображаем байты
Console.WriteLine(BitConverter.ToString(bytes));
// Декодируем байты в строку в кодировке base-64 и выводим эту строку String s = Convert.ToBase64String(bytes);
Console.WriteLine(s);
// Кодируем строку в кодировке base-64 обратно в байты и выводим их bytes = Convert.FromBase64String(s);
Console.WriteLine(BitConverter.ToString(bytes));
}
}
После компиляции этого кода и запуска выполняемого модуля получим следующие строки (ваш результат может отличаться от моего, поскольку байты получены случайным образом):
3B-B9-27-40-59-35-86-54-5F-F1
07knQFklhlRf8Q==
3B-B9-27-40-59-35-86-54-5F-F1
Защищенные строки
Часто объекты String применяют для хранения конфиденциальных данных, таких как пароли или информация кредитной карты. К сожалению, объекты String хранят массив символов в памяти, и если разрешить выполнение небезопасного или неуправляемого кода, он может просмотреть адресное пространство кода, найти строку с конфиденциальной информацией и использовать ее в своих неблаговидных целях. Даже если объект String существует недолго и становится добычей уборщика мусора, CLR может не сразу задействовать ранее занятую этим объектом память (особенно если речь идет об объектах String предыдущих версий), оставляя символы объекта в памяти, где они могут стать добычей злоумышленника. Кроме того, поскольку строки являются неизменяемыми, при манипуляции ими старые версии «висят» в памяти, в результате разные версии строки остаются в различных областях памяти.
В некоторых государственных учреждениях действуют строгие требования безопасности, гарантирующие определенный уровень защиты. Для решения таких задач специалисты Microsoft добавили в FCL безопасный строковый класс System. Security. SecureString. При создании объекта SecureString его код выделяет блок неуправляемой памяти, которая содержит массив символов. Уборщику мусора об этой неуправляемой памяти ничего не известно.
Символы строки шифруются для защиты конфиденциальной информации от любого потенциально опасного или неуправляемого кода. Для дописывания в конец строки, вставки, удаления или замены отдельных символов в защищенной строке служат соответственно методы AppendChar, InsertAt, RemoveAt и SetAt. При вызове любого из этих методов код метода расшифровывает символы, выполняет операцию и затем обратно шифрует строку. Это означает, что символы находятся в незашифрованном состоянии в течение очень короткого периода времени. Это также означает, что символы строки модифицируются в том же месте, где хранятся, но скорость операций все равно конечна, так что прибегать к ним желательно пореже.
Класс SecureString реализует интерфейс IDisposable, служащий для надежного уничтожения конфиденциальной информации, хранимой в строке. Когда приложению больше не нужно хранить конфиденциальную строковую информацию, достаточно вызвать метод Dispose типа SecureString или использовать экземпляр SecureString в конструкции using. Внутренняя реализация Dispose обнуляет содержимое буфера памяти, чтобы предотвратить доступ постороннего кода, и только после этого буфер освобождается. Объект SecureString содержит внутренний объект класса, производного от Saf eBuff ег, в котором хранится сама строка. Класс SafeBuffer наследует от класса CriticalFinalizerObject (см. главу 21), что гарантирует вызов метода Finalize попавшего в распоряжение уборщика мусора объекта SecureString, обнуление строки и последующее освобождение буфера. В отличие от объекта String, при уничтожении объекта SecureString символы зашифрованной строки в памяти не остаются.
Теперь, когда вы знаете, как создавать и изменять объект SecureString, можно поговорить о его использовании. К сожалению, в последней версии FCL поддержка класса SecureString ограничена — вернее, методов, принимающих параметр SecureString, очень немного. В версии 4 инфраструктуры .NET Framework передать SecureString в качестве пароля можно:
□ при работе с криптографическим провайдером (Cryptographic Service Provider, CSP) см. класс System.Security.Cryptography.CspParameters;
□ при создании, импорте или экспорте сертификата в формате Х.509 см. классы System.Security.Cryptography.X509Certificates.X509Certificate и System. Security.Cryptography.X509Certificates.X509Certificate2;
□ при запуске нового процесса под определенной учетной записью пользователя см. классы System.Diagnostics.Process и System.Diagnostics.ProcessStartInfо;
□ при организации нового сеанса записи журнала событий см. класс System. Diagnostics.Eventing.Reader.EventLogSession;
□ при использовании элемента управления System.Windows. Controls. PasswordBox см. класс свойства SecurePassword.
Наконец, вы можете создавать собственные методы, принимающие в качестве аргумента объект SecureString. В методе надо задействовать объект SecureString для создания буфера неуправляемой памяти, хранящего расшифрованные символы, до использования этого буфера в методе. Чтобы сократить до минимума временное «окно» доступа к конфиденциальным данным, ваш код должен обращаться к расшифрованной строке минимально возможное время. После использования строки следует как можно скорее обнулить буфер и освободить его. Никогда не размещайте содержимое SecureString в типе String — в этом случае незашифрованная строка находится в куче и не обнуляется, пока память не будет задействована повторно после уборки мусора. Класс SecureString не переопределяет метод ToString специально — это нужно для предотвращения раскрытия конфиденциальных данных (что может произойти при преобразовании их в String).
Следующий пример демонстрирует инициализацию и использование SecureString (при компиляции нужно указать параметр /unsafe компилятора С#):
using System;
using System.Security;
using System.Runtime.InteropServices;
public static class Program { public static void Main() {
using (SecureString ss = new SecureString()) {
Console.Write("Please enter password: "); while (true) {
ConsoleKeylnfo cki = Console.ReadKey(true); if (cki.Key == ConsoleKey.Enter) break;
// Присоединить символы пароля в конец SecureString ss.AppendChar(cki.KeyChar);
Console.Write("*");
}
Console.Write Line();
// Пароль введен, отобразим его для демонстрационных целей DisplaySecureString(ss);
}
// После 'using' SecureString обрабатывается методом Disposed,
// поэтому никаких конфиденциальных данных в памяти нет
}
// Этот метод небезопасен, потому что обращается к неуправляемой памяти private unsafe static void DisplaySecureString(SecureString ss) {
Char* pc = null; try {
| |
// Дешифрование SecureString в буфер неуправляемой памяти
pc = (Char*) Marshal.SecureStringToCoTaskMemUnicode(ss);
// Доступ к буферу неуправляемой памяти,
// который хранит дешифрованную версию SecureString for (Int32 index = 0; pc[index] != 0; index++) Console.Write(pc[index]);
}
finally {
// Обеспечиваем обнуление и освобождение буфера неуправляемой памяти, // который хранит расшифрованные символы SecureString if (pc != null)
Marshal.ZeroFreeCoTaskMemUnicode((IntPtr) pc);
}
}
}
Класс System.Runtime.InteropServices.Marshal предоставляет 5 методов, которые служат для расшифровки символов SecureString в буфер неуправляемой памяти. Все методы, за исключением аргумента SecureString, статические и возвращают IntPtr. У каждого метода есть связанный метод, который нужно обязательно вызывать для обнуления и освобождения внутреннего буфера. В табл. 14.4 приведены методы класса System.Runtime.InteropServices.Marshal, используемые для расшифровки SecureString в буфер неуправляемой памяти, а также связанные методы для обнуления и освобождения буфера.
| Таблица 14.4. Методы класса Marshal для работы с защищенными строками
|
|
|
Глава 15. Перечислимые типы и битовые флаги
Перечислимые типы и битовые флаги поддерживаются в Windows долгие годы, поэтому я уверен, что многие из вас уже знакомы с их применением. Но по- настоящему объектно-ориентированными перечислимые типы и битовые флаги становятся в общеязыковой исполняющей среде (CLR) и библиотеке классов .NET Framework (FCL). Здесь у них появляются интересные возможности, которые, полагаю, многим разработчикам пока неизвестны. Меня приятно удивило, насколько благодаря этим новшествам, о которых, собственно, и идет разговор в этой главе, можно облегчить разработку приложений.
Перечислимые типы
Перечислимым (enumerated type) называют тип, в котором описан набор пар, состоящих из символьных имен и значений. Далее приведен тип Color, определяющий совокупность идентификаторов, каждый из которых обозначает определенный цвет:
internal enum Color {
White, // Присваивается значение 0 Red, // Присваивается значение 1 Green, // Присваивается значение 2 Blue, // Присваивается значение 3 Orange // Присваивается значение 4
}
Конечно, в программе можно вместо White написать 0, вместо Green — 1 и т. д. Однако перечислимый тип все-таки лучше жестко заданных в исходном коде числовых значений по крайней мере по двум причинам.
□ Программу, где используются перечислимые типы, проще написать и понять, а у разработчиков возникает меньше проблем с ее сопровождением. Символьное имя перечислимого типа проходит через весь код, и занимаясь то одной, то другой частью программы, программист не обязан помнить значение каждого «зашитого» в коде значения (что White равен 0, а 0 означает White). Если же числовое значение символа почему-либо изменилось, то нужно только перекомпилировать исходный код, не изменяя в нем ни буквы. Кроме того, работая с инструментами документирования и другими утилитами, такими как отладчик, программист видит осмысленные символьные имена, а не цифры.
□ Перечислимые типы подвергаются строгой проверке типов. Например, компилятор сообщит об ошибке, если в качестве значения я попытаюсь передать методу тип Colon.Orange (оранжевый цвет), когда метод ожидает перечислимый тип Fruit (фрукт).
В CLR перечислимые типы — это не просто идентификаторы, с которыми имеет дело компилятор. Перечислимые типы играют важную роль в системе типов, на них возлагается решение очень серьезных задач, просто немыслимых для перечислимых типов в других средах (например, в неуправляемом языке C++).
Каждый перечислимый тип напрямую наследует от типа System. Enum, производного от System. ValueType, атот, в свою очередь, — от System.Object. Из этого следует, что перечислимые типы относятся к значимым типам (см. главу 5) и могут выступать как в неупакованной, так и в упакованной формах. Однако в отличие от других значимых типов, у перечислимого типа не может быть методов, свойств и событий. Впрочем, как вы увидите в конце данной главы, наличие метода у перечислимого типа можно имитировать при помощи механизма методов расширения (extension methods).
При компиляции перечислимого типа компилятор C# превращает каждый идентификатор в константное поле типа. Например, предыдущее перечисление Color компилятор видит примерно так:
internal struct Color : System.Enum {
// Далее перечислены открытые константы,
// определяющие символьные имена и значения public const Color White = (Color) 0; public const Color Red = (Color) 1; public const Color Green = (Color) 2; public const Color Blue = (Color) 3; public const Color Orange = (Color) 4;
// Далее находится открытое поле экземпляра со значением переменной Color // Код с прямой ссылкой на этот экземпляр невозможен public Int32 value___________ ;
>
Однако компилятор C# не будет обрабатывать такой код, потому что он не разрешает определять типы, производные от специального типа System. Enum. Это псевдоопределение всего лишь демонстрирует внутреннюю суть происходящего. В общем-то, перечислимый тип — это обычная структура, внутри которой описан набор константных полей и одно экземплярное поле. Константные поля попадают в метаданные сборки, откуда их можно извлечь с помощью механизма отражения. Это означает, что в период выполнения можно получить все идентификаторы и их значения, связанные перечислимым типом, а также преобразовать строковый идентификатор в эквивалентное ему числовое значение. Эти операции предоставлены базовым типом System. Enum, который предлагает статические и экземплярные методы, выполняющие специальные операции над экземплярами перечислимых типов, избавляя вас от необходимости использовать отражение. Мы поговорим о них подробно чуть позже.
ВНИМАНИЕ
Описанные перечислимым типом символы являются константами. Встречая в коде символическое имя перечислимого типа, компилятор заменяет его числовым значением. В результате определяющая перечислимый тип сборка может оказаться ненужной во время выполнения. Но если в коде присутствует ссылка не на определенные перечислимым типом символические имена, а на сам тип, присутствие сборки на стадии выполнения будет обязательным. То есть возникает проблема версий, связанная с тем, что символы перечислимого типа являются константами, а не значениями, предназначенными только для чтения. Эта тема подробно освещена в главе 7.
К примеру, для типа System. Enum существует статический метод GetUnderlyingType, а для типа System.Туре — экземплярный метод GetEnumUnderlyingType:
public static Type GetUnderlyingType(Type enumType); // Определен
// в типе System.Enum
public Type GetEnumUnderlyingType(); // Определен в типе System.Type
Оба этих метода возвращают базовый тип, используемый для хранения значения перечислимого типа. В основе любого перечисления лежит один из основных типов, например byte, sbyte, short, ushort, int (именно он используется в C# по умолчанию), uint, long и ulong. Все эти примитивные типы C# имеют аналоги в FCL. Однако компилятор C# пропустит только примитивный тип; задание базового класса FCL (например, Int32) приведет к сообщению об ошибке (ошибка CS1008: ожидается тип byte, sbyte, short, ushort, int, uint, long или ulong):
error CS1008: Type byte, sbyte, short, ushort, int, uint, long, or ulong expected
Вот как должно выглядеть на C# объявление перечисления, в основе которого лежит тип byte (System. Byte):
internal enum Color : byte {
White,
Red,
Green,
Blue,
Orange
}
Если перечисление Color определено подобным образом, метод GetUnderlyingType вернет следующий результат:
// Эта строка выводит "System.Byte"
Console.Write Line(Enum.GetUnderlyingType(typeof(Color)));
Компилятор C# считает перечислимые типы примитивными, поэтому для операций с их экземплярами применяются уже знакомые нам операторы (==, ! =,
<, >, <=, >=, +, Л, &, |, ++ и —). Все они применяются к полю value_ экземпляра
перечисления, а компилятор C# допускает приведение экземпляров одного перечислимого типа к другому. Также поддерживается явное и неявное приведение к числовому типу.
Имеющийся экземпляр перечислимого типа можно связать со строковым представлением — для этого следует вызвать ToString, унаследованный от System. Enum:
Color с = Color.Blue;
Console.WriteLine(c); // "Blue" (Общий формат)
Console.WriteLine(c.ToStringO); // "Blue" (Общий формат)
Console.WriteLine(c.ToString("G")); // "Blue" (Общий формат)
Console.WriteLine(c.ToString("D")); // "3" (Десятичный формат)
Console.WriteLine(c.ToString("X")); // "03n (Шестнадцатеричный формат)
ПРИМЕЧАНИЕ
При работе с шестнадцатеричным форматом метод ToString всегда возвращает прописные буквы. Количество возвращенных цифр зависит от типа, лежащего в основе перечисления. Для типов byte/sbyte — это две цифры, для типов short/ ushort — четыре, для типов int/uint — восемь, а для типов long/ulong — снова две. При необходимости добавляются ведущие нули.
Помимо метода ToString тип System. Enum предлагает статический метод Format, служащий для форматирования значения перечислимого типа:
public static String Format(Type enumType, Object value, String format);
В общем случае метод ToString требует меньшего объема кода и проще в вызове. С другой стороны, методу Format можно передать числовое значение в качестве параметра value, даже если у вас отсутствует экземпляр перечисления. Например, этот код выведет строку "Blue":
//В результате выводится строка "Blue"
Console.WriteLine(Enum.Format(typeof(Color), 3, "G"));
ПРИМЕЧАНИЕ
Можно объявить перечисление, различные идентификаторы которого имеют одинаковое числовое значение. В процессе преобразования числового значения в символ посредством общего форматирования методы типа вернут один из символов, правда, неизвестно какой. Если соответствия не обнаруживается, возвращается строка с числовым значением.
Статический метод GetValues типа System. Enum и метод GetEnumValues экземпляра System .Туре создают массив, элементами которого становятся символьные имена перечисления. И каждый элемент содержит соответствующее числовое значение:
public static Array GetValues(Type enumType); // Определен в System.Enum public Array GetEnumValuesQ; // Определен в System. Type
Этот метод вместе с методом ToString позволяет вывести все идентификаторы и числовые значения перечисления:
Color[] colors = (Color[]) Enum.GetValues(typeof(Color));
Console.WriteLine("Number of symbols defined: " + colors.Length);
Console. Write Line ("Value\tSymbol\n------- \t------ ");
foreach (Color c in colors) {
// Выводим каждый идентификатор в десятичном и общем форматах Console.WriteLine("{0,5:D}\t{0:G}", с);
}
Результат выполнения этого кода выглядит так:
Number of symbols defined: 5 Value Symbol
0 White
1 Red
2 Green
3 Blue
4 Orange
Лично мне методы GetValues и GetEnumVal не нравятся, потому что они возвращают объект Array, который приходится преобразовывать к соответствующему типу массива. Я всегда определяю собственный метод:
public static TEnum[] GetEnumValues<TEnum>() where TEnum : struct { return (TEnum[])Enum.GetValues(typeof(TEnum));
}
Обобщенный метод GetEnumValues улучшает безопасность типов на стадии компиляции и упрощает первую строку кода в предыдущем примере до следующего вида:
Color[] colors = GetEnumValues<Color>( );
Мы рассмотрели некоторые интересные операции, применимые к перечислимым типам. Полагаю, что показывать символьные имена элементов пользовательского интерфейса (раскрывающихся списков, полей со списком и т. п.) чаще всего вы будете с помощью метода ToString с использованием общего формата (если выводимые строки не требуют локализации, которая не поддерживается перечислимыми типами). Помимо метода GetValues, типы System. Enum и System.Туре предоставляют еще два метода для получения символических имен перечислимых типов:
// Возвращает строковое представление числового значения
public static String GetName(Type enumType, Object value); // Определен
// в System.Enum
public String GetEnumName(Object value); // Определен в System.Type // Возвращает массив строк: по одной на каждое
продолжение &
// символьное имя из перечисления
public static String[] GetNames(Type enumType); // Определен в System.Enum public String[] GetEnumNames(); // Определен в System.Type
Мы рассмотрели несколько методов, позволяющих найти символическое имя (или идентификатор) перечислимого типа. Однако нужен еще и метод определения значения, соответствующего идентификатору, например, вводимому пользователем в текстовое поле. Преобразование идентификатора в экземпляр перечислимого типа легко реализуется статическими методами Parse и TryParse типа Enum:
public static Object Parse(Type enumType, String value);
public static Object Parse(Type enumType, String value, Boolean ignoreCase); public static Boolean TryParse<TEnum>(String value, out TEnum result) where TEnum: struct; public static Boolean TryParse<TEnum>(String value,
Boolean ignoreCase, out TEnum result) where TEnum : struct;
Пример использования данных методов:
// Так как Orange определен как 4, 'с' присваивается значение 4 Color с = (Color) Enum.Parse(typeof(Color), "orange", true);
// Так как Brown не определен, генерируется исключение ArgumentException с = (Color) Enum.Parse(typeof(Color), "Brown", false);
// Создается экземпляр перечисления Color со значением 1 Enum.TryParse<Color>("l", false, out c);
// Создается экземпляр перечисления Color со значение 23 Enum.TryParse<Color>("23", false, out c);
Наконец, рассмотрим статический метод IsDef ined типа Enum и метод IsEnum- Defined типа Type:
public static Boolean IsDefined(Type enumType, Obj'ect value); // Определен
// в System.Enum
public Boolean IsEnumDefined(Obj'ect value); // Определен в System.Type
С их помощью определяется допустимость числового значения для данного перечисления:
// Выводит "True", так как в перечислении Color
// идентификатор Red определен как 1
Console.WriteLine(Enum.IsDefined(typeof(Color), 1));
// Выводит "True", так как в перечислении Color // идентификатор White определен как 0
Console.WriteLine(Enum.IsDefined(typeof(Color), "White"));
// Выводит "False", так как выполняется проверка с учетом регистра Console.WriteLine(Enum.IsDefined(typeof(Color), "white"));
// Выводит "False", так как в перечислении Color
// отсутствует идентификатор со значением 10
Console.WriteLine(Enum.IsDefined(typeof(Color), (Byte)10));
Метод IsDef ined часто используется для проверки параметров. Например:
public void SetColor(Color с) {
if (!Enum.IsDefined(typeof(Color), c)) {
throw(new ArgumentOutOfRangeException("c"j с, "Invalid Color value."));
}
// Задать цвет, как White, Red, Green, Blue или Orange
}
Без подобной проверки не обойтись, потому что пользователь вполне может вызвать метод SetColon вот таким способом:
SetColor((Color) 547);
Так как соответствие числу 547 в перечислении отсутствует, метод SetColor генерирует исключение ArgumentOutOf RangeException с информацией о том, какой параметр недопустим и почему.
ВНИМАНИЕ
При всем удобстве метода IsDefined применять его следует с осторожностью. Во- первых, он всегда выполняет поиск с учетом регистра, во-вторых, работает крайне медленно, так как в нем используется отражение. Самостоятельно написав код проверки возможных значений, вы повысите производительность своего приложения. Кроме того, метод работает только для перечислимых типов, определенных в той сборке, из которой он вызывается. Например, пусть перечисление Color определено в одной сборке, а метод SetColor — в другой. При вызове методом SetColor метода IsDefined все будет работать, если цвет имеет значение White, Red, Green, Blue или Orange. Однако если в будущем мы добавим в перечисление Color цвет Purple, метод SetColor начнет использовать неизвестное ему значение, а результат его работы станет непредсказуемым.
Напоследок упомянем набор статических методов ToOb ject типа System. Enum, преобразующих экземпляры типа Byte, SByte, Intl6, UIntl6, Int32, UInt32, Int64 или UInt64 в экземпляры перечислимого типа.
Перечислимые типы всегда применяют в сочетании с другим типом. Обычно их используют в качестве параметров методов или возвращаемых типов, свойств или полей. Часто возникает вопрос, где лучше определять перечислимый тип: внутри или на уровне того типа, которому он требуется. В FCL вы увидите, что обычно перечислимый тип определяется на уровне класса, которым он используется. Это делается просто для того, чтобы сократить объем набираемого разработчиком кода. Поэтому при отсутствии возможных конфликтов имен лучше определять перечислимые типы на одном уровне с основным классом.
Битовые флаги
Программисты часто работают с наборами битовых флагов. Метод GetAttributes типа System. 10. File возвращает экземпляр типа FileAttnibutes. Тип FileAttni- butes является экземпляром перечислимого типа, основанного на типе Int32, где каждый разряд соответствует какому-то атрибуту файла. В FCL тип FileAttnibutes описан следующим образом:
[Flags, Serializable] public enum FileAttributes {
Readonly = 0x0001,
Hidden = 0x0002,
System = 0x0004,
Directory = 0x0010,
Archive = 0x0020,
Device = 0x0040,
Normal = 0x0080,
Temporary = 0x0100,
SparseFile = 0x0200,
ReparsePoint = 0x0400,
Compressed = 0x0800,
Offline = 0x1000,
NotContentlndexed = 0x2000,
Encrypted = 0x4000
}
Следующий фрагмент проверяет, является ли файл скрытым:
String file = Assembly.GetEntryAssembly().Location;
FileAttributes attributes = File.GetAttributes(file);
Console.WriteLine("Is {0} hidden? {1}", file, (
attributes & FileAttributes.Hidden) != 0);
ПРИМЕЧАНИЕ
В классе Enum имеется метод HasFlag, определяемый следующим образом:
public Boolean HasFlag(Enum flag);
С его помощью можно переписать вызов метода ConsoleWriteLine:
Console.WriteLine("Is {0} hidden? {1}", file, attributes.HasFlag(FileAttributes.Hidden));
Однако я не рекомендую использовать метод HasFlag. Дело в том, что он принимает параметры типа Enum, азначит, передаваемые ему значения должны быть упакованы, что требует дополнительных затрат памяти.
А этот пример демонстрирует, как изменить файлу атрибуты «только для чтения» и «скрытый»:
File.SetAttributes(file, FileAttributes.Readonly | FileAttributes.Hidden);
Из описания типа FileAttributes видно, что, как правило, при создании набора комбинируемых друг с другом битовых флагов используют перечислимые типы. Однако несмотря на внешнюю схожесть, перечислимые типы семантически отличаются от битовых флагов. Если в первом случае мы имеем отдельные числовые
значения, то во втором приходится иметь дело с набором флагов, одни из которых установлены, а другие нет.
Определяя перечислимый тип, предназначенный для идентификации битовых флагов, каждому идентификатору следует явно присвоить числовое значение. Обычно в соответствующем идентификатору значении установлен лишь один бит. Также часто приходится видеть идентификатор None, значение которого определено как 0. Еще можно определить идентификаторы, представляющие часто используемые комбинации (см. приведенный далее символ ReadWrite). Настоятельно рекомендуется применять к перечислимому типу специализированный атрибут типа System. FlagsAttribute:
[Flags] // Компилятор C# допускает значение "Flags" или "FlagsAttribute"
Internal enum Actions {
None = 0 Read = 0x0001,
Write = 0x0002,
ReadWrite = Actions.Read | Actions.Write,
Delete = 0x0004,
Query = 0x0008,
Sync = 0x0010
}
Для работы с перечислимым типом Actions можно использовать все методы, описанные в предыдущем разделе. Хотя иногда возникает необходимость изменить поведение ряда функций. К примеру, рассмотрим код:
Actions actions = Actions.Read | Actions.Delete; // 0x0005 Console.WriteLine(actions.ToString()); // "Read, Delete"
Метод ToStning пытается преобразовать числовое значение в его символьный эквивалент. Но у числового значения 0x0005 нет символьного эквивалента. Однако обнаружив у типа Actions атрибут [Flags], метод ToString рассматривает числовое значение уже как набор битовых флагов. Так как биты 0x0001 и 0x0005 установлены, метод ToString формирует строку "Read, Delete". Если в описании типа Actions убрать атрибут [Flags], метод вернет строку "5".
В предыдущем разделе мы рассмотрели метод ToString и привели три способа форматирования выходной строки: "G" (общий), "D" (десятичный) и "X" (шестнадцатеричный). Форматируя экземпляр перечислимого типа с использованием общего формата, метод сначала определяет наличие атрибута [Flags]. Если атрибут не указан, отыскивается и возвращается идентификатор, соответствующий данному числовому значению. Обнаружив же данный атрибут, ToString действует по следующему алгоритму:
1. Получает набор числовых значений, определенных в перечислении, и сортирует их в нисходящем порядке.
2. Для каждого значения выполняется операция конъюнкции (AND) с экземпляром перечисления. В случае равенства результата числовому значению связанная
с ним строка добавляется в итоговую строку, соответствующие же биты считаются учтенными и сбрасываются. Операция повторяется до завершения проверки всех числовых значений или до сброса все битов экземпляров перечисления.
3. Если после проверки всех числовых значений экземпляр перечисления все еще не равен нулю, это означает наличие несброшенных битов, которым не сопоставлены идентификаторы. В этом случае; метод возвращает исходное число экземпляра перечисления в виде строки.
4. Если исходное значение экземпляра перечисления не равно нулю, метод возвращает набор символов, разделенных запятой.
5. Если исходным значением экземпляра перечисления был ноль, а в перечислимом типе есть идентификатор с таким значением, метод возвращает этот идентификатор.
6. Если алгоритм доходит до данного шага, возвращается 0.
Чтобы получить правильную результирующую строку, тип Actions можно определить и без атрибута [Flags], Для этого достаточно указать формат "F":
// [Flags] // Теперь это просто комментарий internal enum Actions {
None = 0 Read = 0x0001,
Write = 0x0002,
ReadWrite = Actions.Read | Actions.Write,
Delete = 0x0004,
Query = 0x0008,
Sync = 0x0010
}
Actions actions = Actions.Read | Actions.Delete; // 0x0005 Console.WriteLine(actions.ToString("F")); // "Read, Delete"
Если числовое значение содержит бит, которому не соответствует какой-либо идентификатор, в возвращаемой строке окажется только десятичное число, равное исходному значению, и ни одного идентификатора.
Заметьте: идентификаторы, которые вы определяете в перечислимом типе, не обязаны быть степенью двойки. Например, в типе Actions можно описать идентификатор с именем АН, имеющий значение 0X001F. Результатом форматирования экземпляра типа Actions со значением 0X001F станет строка "АН". Других идентификаторов в строке не будет.
Пока мы говорили лишь о преобразовании числовых значений в строку флагов. Однако вы можете также получить числовое значение строки, содержащей разделенные запятой идентификаторы, воспользовавшись статическим методом Parse типа Enum или методом ТryParse. Рассмотрим это на примере:
// Так как Query определяется как 8, 'а' получает начальное значение 8 Actions а = (Actions) Enum.Parse(typeof(Actions), "Query", true);
Console. Write Line (а. ToStringQ); // "Query"
// Так как у нас определены и Query, и Read, 'а' получает
// начальное значение 9
Enum.TryParse<Actions>("Query, Read", false, out a);
Console. WriteLine(a. ToStringQ); // "Read, Query"
// Создаем экземпляр перечисления Actions enum со значением 28
a = (Actions) Enum.Parse(typeof(Actions), "28", false);
Console.WriteLine(a.ToString()); // "Delete, Query, Sync"
При вызове методов Parse и TryParse выполняются следующие действия:
1. Удаляются все пробелы в начале и конце строки.
2. Если первым символом в строке является цифра, знак «плюс» (+) или знак «минус» (-), строка считается числом и возвращается экземпляр перечисления, числовое значение которого совпадает с числом, полученным в результате преобразования строки.
3. Переданная строка разбивается на разделенные запятыми лексемы, и у каждой лексемы удаляются все пробелы в начале и конце.
4. Выполняется поиск каждой строки лексемы среди идентификаторов перечисления. Если символ найти не удается, метод Parse генерирует исключение System. ArgumentException, а метод TryParse возвращает значение false. При обнаружении символа его числовое значение путем дизъюнкции (OR) присоединяется к результирующему значению, и метод переходит к анализу следующего символа.
5. После обнаружения и проверки всех лексем результат возвращается программе. Никогда не следует применять метод IsDefined с перечислимыми типами битовых флагов. Это не будет работать по двум причинам:
□ Переданную ему строку метод не разбивает на отдельные лексемы, а ищет целиком, вместе с запятыми. Однако в перечислении не может присутствовать идентификатор, содержащий запятые, а значит, результат поиска всегда будет нулевым.
□ После передачи ему числового значения метод ищет всего один символ перечислимого типа, значение которого совпадает с переданным числом. Для битовых флагов вероятность получения положительного результата при таком сравнении ничтожно мала, и обычно метод возвращает значение false.
Добавление методов к перечислимым типам
В начале главы уже упоминалось, что определить метод как часть перечислимого типа невозможно. Это ограничение удручало меня в течение многих лет, так как то и дело возникали ситуации, когда требовалось снабдить перечислимые типы методами. К счастью, теперь его можно обойти при помощи относительно нового для C# механизма методов расширения (extension method), который подробно рассматривается в главе 8.
Для добавления методов к перечислимому типу FileAttributes нужно определить статический класс с методами расширения. Делается это следующим образом:
internal static class FileAttributesExtensionMethods { public static Boolean IsSet(
this FileAttributes flags, FileAttributes flagToTest) { if (flagToTest == 0)
throw new ArgumentOutOfRangeException(
"flagToTest", "Value must not be 0"); return (flags & flagToTest) == flagToTest;
}
public static Boolean IsClear(
this FileAttributes flags, FileAttributes flagToTest) { if (flagToTest == 0)
throw new ArgumentOutOfRangeException(
"flagToTest", "Value must not be 0"); return !IsSet(flags, flagToTest);
}
public static Boolean AnyFlagsSet(
this FileAttributes flags, FileAttributes testFlags) { return ((flags & testFlags) != 0);
}
public static FileAttributes Set(
this FileAttributes flags, FileAttributes setFlags) { return flags | setFlags;
}
public static FileAttributes Clear(
this FileAttributes flags, FileAttributes clearFlags) { return flags & ~clearFlags;
}
public static void ForEach(this FileAttributes flags,
Action<FileAttributes> processFlag) {
if (processFlag == null) throw new ArgumentNullException("processFlag"); for (UInt32 bit = 1; bit != 0; bit <<= 1) {
UInt32 temp = ((UInt32)flags) & bit;
if (temp != 0) processFlag((FileAttributes)temp);
}
}
}
Следующий фрагмент демонстрирует вызов одного из таких методов. Как легко заметить, он выглядит так, как выглядел бы вызов методов перечислимого типа:
FileAttributes fa = FileAttributes.System; fa = fa.Set(FileAttributes.Readonly); fa = fa.Clear(FileAttributes.System); fa.ForEach(f => Console.WriteLine(f));
Глава 16. Массивы
Массив представляет собой механизм, позволяющий рассматривать набор элементов как единую коллекцию. Общеязыковая исполняющая среда Microsoft .NET (CLR) поддерживает одномерные (single-dimension), многомерные (multidimension) и нерегулярные (jagged) массивы. Базовым для всех массивов является абстрактный класс System.Array, производный от System.Object. Значит, массивы всегда относятся к ссылочному типу и размещаются в управляемой куче, а переменная в приложении содержит не элементы массива, а ссылку на массив. Рассмотрим пример:
Int32[] mylntegers; // Объявление ссылки на массив
mylntegers = new Int32[100]; // Создание массива типа Int32 из 100 элементов
В первой строке объявляется переменная mylntegers, которая будет ссылаться на одномерный массив элементов типа Int32. Вначале ей присваивается значение null, так как память под массив пока не выделена. Во второй строке выделяется память под 100 значений типа Int32; и всем им присваивается начальное значение 0. Поскольку массивы относятся к ссылочным типам, блок памяти для хранения 100 неупакованных экземпляров типа Int32 выделяется в управляемой куче. Вообще говоря, помимо элементов массива в этом блоке размещается указатель на объект- тип, индекс блока синхронизации, а также некоторые дополнительные члены. Адрес этого блока памяти заносится в переменную mylntegers.
Можно также создать массивы с элементами ссылочного типа:
Control[] myControls; // Объявление ссылки на массив
myControls = new Control[50]; // Создание массива из 50 ссылок
// на переменную Control
Переменная myControls из первой строки может указывать на одномерный массив ссылок на элементы Control. Вначале ей присваивается значение null, ведь память под массив пока не выделена. Во второй строке выделяется память под 50 ссылок на Control, и все они инициализируются значением null. Поскольку Control относится к ссылочным типам, массив формируется путем создания ссылок, а не каких-либо реальных объектов. Возвращенный адрес блока памяти заносится в переменную myControls.
На рис, 16.1 показано, как выглядят массивы значимого и ссылочного типов
в управляемой куче.
На этом рисунке показан массив Controls после выполнения следующих инструкций:
myControls[l] = new ButtonQ; myControls[2] = new TextBoxQ;
myControls[3] = myControls[2]; 11 Два элемента ссылаются на один объект
 |  | |||||||||
 | ||||||||||
 |  | |||||||||
 | ||||||||||
Рис. 16.1. Массивы значимого и ссылочного типов в управляемой куче
Согласно общеязыковой спецификации (CLS), нумерация элементов в массиве должна начинаться с нуля. Только в этом случае методы, написанные на С#, смогут передать ссылку на созданный массив коду, написанному на другом языке, скажем, на Microsoft Visual Basic .NET. Кроме того, поскольку массивы с начальным нулевым индексом получили очень большое распространение, специалисты Microsoft постарались оптимизировать их работу. Тем не менее иные варианты индексации массивов в CLR допускаются, хотя их использование не рекомендуется. В случаях когда производительность и межъязыковая совместимость программ не имеют большого значения, можно использовать массивы, начальный индекс которых отличен от 0. Мы подробно рассмотрим их чуть позже.
На рисунке видно, что в массиве присутствует некая дополнительная информация. Это сведения о размерности массива, нижних границах всех его измерений (почти всегда 0) и количестве элементов в каждом измерении. Здесь же указывается тип элементов массива. Методы для получения этих данных будут рассмотрены далее в этой главе.
Пока что нам известен только процесс создания одномерных массивов. По возможности нужно ограничиваться одномерными массивами с нулевым начальным индексом, которые называют иногда SZ-массивами, или векторами. Векторы обеспечивают наилучшую производительность, поскольку для операций с ними используются команды промежуточного языка (Intermediate Language, IL), например newarr, ldelem, ldelema, ldlen и stelem. Впрочем, если у вас есть такое желание, можно применять и многомерные массивы. Вот как они создаются:
// Создание двухмерного массива типа Doubles Double[,] myDoubles = new Double[10, 20];
продолжение
// Создание трехмерного массива ссылок на строки Stringf,,] myStrings = new String[5, 3, 10];
CLR поддерживает также нерегулярные (jagged) массивы — то есть «массивы массивов». Производительность одномерных нерегулярных массивов с нулевым начальным индексом такая же, как у обычных векторов. Однако обращение к элементу нерегулярного массива означает обращение к двум или больше массивам одновременно. Вот пример массива многоугольников, где каждый многоугольник состоит из массива экземпляров типа Point:
// Создание одномерного массива из массивов типа Point Point[][] myPolygons = new Point[3][];
// myPolygons[0] ссылается на массив из 10 экземпляров типа Point myPolygons[0] = new Point[10];
// myPolygons[l] ссылается на массив из 20 экземпляров типа Point myPolygons[l] = new Point[20];
// myPolygons[2] ссылается на массив из 30 экземпляров типа Point myPolygons[2] = new Point[30];
// вывод точек первого многоугольника
for (Int32 х = 0; х < myPolygons[0].Length; x++)
Console.WriteLine(myPolygons[0][x]);
ПРИМЕЧАНИЕ
CLR проверяет корректность индексов. To есть если у вас имеется массив, состоящий из 100 элементов с индексами от 0 до 99, попытка обратиться кего элементу по индексу-5 или 100 породит исключение System.Index.OutOfRange. Доступ к памяти за пределами массива нарушает безопасность типов и создает брешь в защите, недопустимую для верифицированного CLR-кода. Проверка индекса обычно не влияет на производительность, так как компилятор выполняет ее всего один раз перед началом цикла, а не на каждой итерации. Впрочем, если вы считаете, что проверка индексов критична для скорости выполнения вашей программы, используйте для доступа к массиву небезопасный код. Эта процедура рассмотрена в разделе «Производительность доступа к массиву» данной главы.
Инициализация элементов массива
В предыдущем разделе рассмотрена процедура создания элементов массива и присвоения им начальных значений. Синтаксис C# позволяет совместить эти операции:
String[] names = new String[] { "Aidan", "Grant" };
Набор разделенных запятой символов в фигурных скобках называется инициализатором массива (array initializer). Сложность каждого символа может быть
произвольной, а в случае многомерного массива инициализатор может оказаться вложенным. В показанном примере фигурируют всего два простых выражения типа String.
Если в методе объявляется локальная переменная для работы с инициализированным массивом, для упрощения кода можно воспользоваться переменной неявного типа var:
// Использование локальной переменной неявного типа: var names = new String[] { "Aidan", "Grant" };
В результате компилятор делает вывод о том, что локальная переменная names относится к типу String [ ], так как именно к этому типу принадлежит выражение, расположенное справа от оператора присваивания (=). Используя неявную типизацию массивов С#, вы поручаете компилятору определить тип элементов массива. Обратите внимание на отсутствие спецификации типа между операторами new и [ ] в следующем фрагменте кода:
// Задание типа массива с помощью локальной переменной неявного типа: var names = new[] { "Aidan", "Grant", null
Компилятор определяет тип выражений, используемых для инициализации элементов массива, и по результатам выбирает базовый класс, который лучше всего описывает все элементы. В показанном примере компилятор обнаруживает два элемента типа String и значение null. Но так как последнее может быть неявно преобразовано в любой ссылочный тип, выбор делается в пользу создания и инициализации массива ссылок типа String.
Еще пример:
// Ошибочное задание типа массива с помощью локальной
// переменной неявного типа
var names = new[] { "Aldan", "Grant", 123 };
На такой код компилятор реагирует сообщением (ошибка CS0826: подходящего типа для неявно заданного массива не обнаружено):
error CS0826: No best type found for implicitly-typed array
Дело в том, что общим базовым типом для двух строк и значения типа Int32 является тип Object. Для компилятора это означает необходимость создать массив ссылок типа Ob j ect, а затем упаковать значение типа Int32 и заставить последний элемент массива ссылаться на результат упаковки, имеющий значение 123. Разработчики сочли, что задача упаковки элементов массива приводит к слишком высоким затратам, чтобы компилятор мог выполнять ее неявно, поэтому в такой ситуации просто выводится сообщение об ошибке.
В качестве синтаксического бонуса можно указать возможность вот такой инициализации массива:
String[] names = { "Aidan", "Grant" };
Обратите внимание, что справа от оператора присваивания располагаются только начальные значения элементов массива. 11 и оператора new, ни типа, ни квадратных
скобок там нет. Этот синтаксис удобен, но к сожалению, в этом случае компилятор не разрешает использовать локальные переменные неявного типа:
// Ошибочное использование локальной переменной var names = { "Aidan", "Grant" };
Попытка компиляции такой строчки приведет к появлению двух сообщений:
error CS0820: Cannot initialize an implicitly-typed local variable with an array initializer
error CS0622: Can only use array initializer expressions to assign array types.
Try using a new expression instead
Первое говорит о том, что локальной переменной неявного типа невозможно присвоить начальное значение при помощи инициализатора массива, а второе информирует, что данный инициализатор применяется только для назначения типов массивам и рекомендует вам воспользоваться оператором new. В принципе, компилятор вполне способен выполнить все эти действия самостоятельно, но разработчики решили, что это — слишком сложная задача. Ведь пришлось бы определять тип массива, создавать его при помощи оператора new, присваивать элементам начальные значения, а кроме того, определять тип локальной переменной.
Напоследок хотелось бы рассмотреть процедуру неявного задания типа массива в случае анонимных типов и локальных переменных неявного типа. (Об анонимных типах см. главу 10.)
Рассмотрим следующий код:
// Применение переменных и массивов неявно заданного типа,
// а также анонимного типа:
var kids = new[] {new { Name=“Aidan" }, new { Name="Grant" }};
// Пример применения (с другой локальной переменной неявно заданного типа): foreach (var kid in kids)
Console.WriteLine(kid.Name);
В этом примере для присваивания начальных значений элементам массива используются два выражения, каждое из которых представляет собой анонимный тип (ведь после оператора new ни в одном из случаен не фигурирует имя типа). Благодаря идентичной структуре этих выражений (поле Name типа String) компилятор относит оба объекта к одному типу. Теперь мы можем воспользоваться возможностью неявного задания типа массива (когда между оператором new и квадратными скобками отсутствует имя типа). В результате компилятор самостоятельно определит тип, сконструирует массив и инициализирует его элементы как ссылки на два экземпляра одного и того же анонимного типа. В итоге ссылка на этот объект присваивается локальной переменной kids, тип которой определит компилятор.
Затем только что созданный и инициализированный массив используется в цикле foreach, в котором фигурирует и переменная kid неявного типа. Вот результат выполнения такого кода:
Aidan
Grant
Приведение типов в массивах
В CLR для массивов с элементами ссылочного типа допустимо приведение. В рамках решения этой задачи оба типа массивов должны иметь одинаковую размерность; кроме того, должно иметь место неявное или явное преобразование из типа элементов исходного массива в целевой тип. CLR не поддерживает преобразование массивов с элементами значимых типов в другие типы. Впрочем, данное ограничение можно обойти при помощи метода Array. Сору, который создает новый массив и заполняет его элементами. Вот пример приведения типа в массиве:
// Создание двухмерного массива FileStream FileStream[,] fs2dim = new FileStream[5, 10];
// Неявное приведение к массиву типа Object Object[,] o2dim = fs2dim;
// Невозможно приведение двухмерного массива к одномерному
// Ошибка компиляции CS0030: невозможно преобразовать тип 'object[*,*]"
// в 'System.10.Stream[]1 Stream[] sldim = (Stream[]) o2dim;
// Явное приведение к двухмерному массиву Stream Stream[,] s2dim = (Stream[,]) o2dim;
// Явное приведение к двухмерному массиву String // Компилируется, но во время выполнения // возникает исключение InvalidCastException String[,] st2dim = (String[,]) o2dim;
// Создание одномерного массива Int32 (значимый тип)
Int32[] ildim = new Int32[5];
// Невозможно приведение массива значимого типа // Ошибка компиляции CS0030: невозможно преобразовать // тип "Int[]" в 'object[]'
Object[] oldim = (Object[j) ildim;
// Создание нового массива и приведение элементов к нужному типу // при помощи метода Array.Сору
// Создаем массив ссылок на упакованные элементы типа Int32 Object[] obldim = new Object[ildim.Length];
Array.Copy(ildim, obldim, ildim.Length);
Метод Array .Copy не просто копирует элементы одного массива в другой. Он действует как функция memmove языка С, но при этом правильно обрабатывает перекрывающиеся области памяти. Он также способен при необходимости преобразовывать элементы массива в процессе их копирования. Метод Сору выполняет следующие действия:
□ Упаковка элементов значимого типа в элементы ссылочного типа, например копирование Int32[ ] в Object[].
□ Распаковка элементов ссылочного типа в элементы значимого типа, например копирование Object [] Blnt32[],
□ Расширение (widening) примитивных значимых типов, например копирование Int32[]в Double[].
□ Понижающее приведение в случаях, когда совместимость массивов невозможно определить по их типам. Сюда относится, к примеру, приведение массива типа Object [ ] в массив типа IFormattable[ ]. Если все объекты в массиве Object [ ] реализуют интерфейс IFormattable[ ], приведение пройдет успешно.
Вот еще один пример применения метода Сору:
// Определение значимого типа, реализующего интерфейс internal struct MyValueType : IComparable { public Int32 CompareTo(Object obj) {
}
}
public static class Program { public static void Main() {
// Создание массива из 100 элементов значимого типа MyValueType[] src = new MyValueType[100];
// Создание массива ссылок IComparable IComparable[] dest = new IComparable[src.Length];
// Присваивание элементам массива IComparable ссылок на упакованные // версии элементов исходного массива Array.Copy(src, dest, src.Length);
}
Нетрудно догадаться, что FCL достаточно часто использует достоинства метода Array.Сору.
Бывают ситуации, когда полезно изменить тип массива, то есть выполнить его ковариацию (array covariance). Однако следует помнить, что эта операция сказывается на производительности. Допустим, вы написали такой код:
Stringf] sa = new String[100];
Objectf] oa = sa; // oa ссылается на массив элементов типа String оа[5] = "left"; // CLR проверяет принадлежность оа к типу String;
// Проверка проходит успешно
оа[3] = 5; // CLR проверяет принадлежность оа к типу Int32;
// Генерируется исключение ArrayTypeMismatchException
В этом коде переменная оа, тип которой определен как Object [ ], ссылается на массив типа String[ ]. Затем вы пытаетесь присвоить одному из элементов этого массива значение 5, относящееся к типу Int32, производному от типа Object. Естественно, CLR проверяет корректность такого присваивания, то есть в про
цессе выполнения контролирует наличие в массиве элементов типа Int32. В данном случае такие элементы отсутствуют, что и становится причиной исключения ArrayTypeMismatchException.
ПРИМЕЧАНИЕ
Для простого копирования части элементов из одного массива в другой имеет смысл использовать метод BlockCopy класса System.Buffer, который работает быстрее метода Array. Сору. К сожалению, этот метод поддерживает только примитивные типы и не имеет такихже широких возможностей приведения, как Array. Сору. Параметры типа Int32 выражаются путем смещения байтов внутри массива, а не при помощи индексов. То есть метод BlockCopy подходит для поразрядного копирования совместимых данных из массива одного типа в другой. К примеру, таким способом можно скопировать массив типа Byte[], содержащий символы Юникода, в массив типа Char[]. Этот метод частично компенсирует отсутствие возможности считать массив просто блоком памяти произвольного типа.
Для надежного копирования набора элементов из одного массива в другой используйте метод ConstrainedCopy класса System.Array. Он гарантирует, что в случае неудачного копирования будет выдано исключение, но данные в целевом массиве останутся неповрежденными. Это позволяет использовать метод ConstrainedCopy в области ограниченного выполнения (Constrained Execution Region, CER). Гарантии, которые он дает, обусловлены требованием, чтобы тип элементов исходного массива совпадал с типом элементов целевого или был производным от него. Кроме того, метод не поддерживает упаковку, распаковку или нисходящее приведение.
Базовый класс System.Array
Рассмотрим объявление переменной массива:
FileStreamf] fsArrayj
Объявление переменной массива подобным образом приводит к автоматическому созданию типа FileStream[] для домена приложений. Тип FileStream[] является производным от System.Array и соответственно наследует оттуда все методы и свойства. Для их вызова служит переменная f sArray. Это упрощает работу с массивами, ведь в классе System.Array есть множество полезных методов и свойств, в том числе Clone, СоруТо, GetLength, GetLongLength, GetLowerBound, GetUpperBound, Length и Rank.
Класс System.Array содержит также статические методы для работы с массивами, в том числе AsReadOnly, BinarySearch, Clear, ConstrainedCopy, ConvertAll, Copy,Exists,Find, FindAll, Findlndex, FindLast, FindLastlndex,ForEach, IndexOf, LastlndexOf, Resize, Reverse, Sort и TrueForAll. В качестве параметра они принимают ссылку на массив. У каждого из этих методов существует множество перегруженных версий. Более того, для многих из них имеются обобщенные перегруженные версии, обеспечивающие контроль типов во время компиляции и высокую производительность. Я настоятельно рекомендую самостоятельно почитать о них в документации на SDK.
Реализация интерфейсов lEnumerable, ■Collection и I List
Многие методы работают с коллекциями, поскольку они объявлены с такими параметрами, как интерфейсы lEnumerable, ICollection и IList. Им можно передавать и массивы, так как эти три необобщенных интерфейса реализованы в классе System.Array. Данная реализация обусловлена тем, что эти интерфейсы интерпретируют любой элемент как экземпляр System.Object. Однако хотелось бы также, чтобы класс System .Array реализовывал обобщенные эквиваленты этих интерфейсов, обеспечивая лучший контроль типов во время компиляции и повышенную производительность.
Команда разработчиков CLR решила, что не стоит осуществлять реализацию интерфейсов IEnumerable<T>, ICollection<T> и IList<T> классом System.Array, так как в этом случае возникают проблемы с многомерными массивами, а также с массивами, в которых нумерация не начинается с нуля. Ведь определение этих интерфейсов в указанном классе означает необходимость поддержки массивов всех типов. Вместо этого разработчики пошли на хитрость: при создании одномерного массива с начинающейся с нуля индексацией CLR автоматически реализует интерфейсы IEnumerable<T>, ICollection<T> и IList<T> (здесь Т — тип элементов массива), а также три интерфейса для всех базовых типов массива при условии, что эти типы являются ссылочными. Ситуацию иллюстрирует следующая иерархия.
Object
Array (необобщенные lEnumerable, ICollection, IList)
Object[] (lEnumerable, ICollection, IList of Object)
String[] (lEnumerable, ICollection, IList of String)
Stream[] (lEnumerable, ICollection, IList of Stream)
FileStream[] (lEnumerable, ICollection, IList of FileStream)
. (другие массивы ссылочных типов)
Пример:
FileStream[] fsArray;
В этом случае при создании типа FileStream[ ] CLR автоматически реализует в нем интерфейсы IEnumerable<FileStream>, ICollection<FileStream> и IList<FileStream>. Более того, тип FileStream[] будет реализовывать интерфейсы базовых классов IEnumerable<Stream>, IEnumerable<Object>, ICollection<Stream>, ICollection<Object>, IList<Stream> и IList<Object>.
Так как все эти интерфейсы реализуются средой CLR автоматически, переменная f sArray может применяться во всех случаях использования этих интерфейсов. Например, ее можно передавать в методы с такими прототипами:
void Ml(IList<FileStream> fsList) { ... } void M2(ICollection<Stream> sCollection) { ... } void M3(IEnumerable<0bJect> oEnumerable) { ... }
Обратите внимание, что если массив содержит элементы значимого типа, класс, которому он принадлежит, не будет реализовывать интерфейсы базовых классов элемента. Например:
DateTime[] dtArray; // Массив элементов значимого типа
В данном случае тип DateTime[ ] будет реализовывать только интерфейсы IEnumerable<DateTime>, ICollection<DateTime> иIList<DateTime>; версии этих интерфейсов, общие для классов System. ValueType или System.Object, реализованы не будут. А это значит, что переменную dtArray нельзя передать показанному ранее методу М3 в качестве аргумента. Ведь массивы значимых и ссылочных типов располагаются в памяти по-разному (об этом рассказывалось в начале данной главы).
Передача и возврат массивов
Передавая массив в метод в качестве аргумента, вы на самом деле передаете ссылку на него. А значит, метод может модифицировать элементы массива. Этого можно избежать, передав в качестве аргумента копию массива. Имейте в виду, что метод Аггау.Сору выполняет поверхностное (shallow) копирование, и если элементы массива относятся к ссылочному типу, в новом массиве окажутся ссылки на существующие объекты.
Аналогично, отдельные методы возвращают ссылку на массив. Если метод создает и инициализирует массив, возвращение такой ссылки не вызывает проблем; если же вы хотите, чтобы метод возвращал ссылку на внутренний массив, ассоциированный с полем, то сначала решите, вправе ли вызывающая программа иметь доступ к этому массиву. Как правило, делать этого не стоит. Поэтому лучше пусть метод создаст массив, вызовет метод Аггау.Сору, а затем вернет ссылку на новый массив. Еще раз напомню, что данный метод выполняет поверхностное копирование исходного массива.
Результатом вызова метода, возвращающего ссылку на массив, не содержащий элементов, является либо значение null, либо ссылка на массив с нулевым числом элементов. В такой ситуации Microsoft настоятельно рекомендует второй вариант, поскольку подобная реализация упрощает код. К примеру, данный код выполняется правильно даже при отсутствии элементов, подлежащих обработке:
// Пример простого для понимания кода
Appointment[] appointments = GetAppointmentsForTodayO;
продолжение
for (Int32 а = 0; а < appointments.Length; а++) {
>
Следующий фрагмент кода также корректно выполняется при отсутствии элементов, но он уже сложнее:
// Пример более сложного кода
Appointment[] appointments = GetAppointmentsForTodayQ; if (appointments != null) {
for (Int32 a = 0, a < appointments.Length; a++) {
// Выполняем действия с элементом appointments[a]
}
>
Если вы пишете свои методы так, чтобы они вместо null возвращали массивы с нулевым числом элементов, пользователям будет проще работать с ними. То же относится к полям. Если у вашего типа есть поле, являющееся ссылкой на массив, то в него следует помещать ссылку на массив, даже если в массиве нет ни одного
элемента.
Массивы с ненулевой нижней границей
Как уже упоминалось, массивы с ненулевой нижней границей вполне допустимы. Создавать их можно при помощи статического метода Createlnstance типа Array. Существует несколько перегруженных версий этого метода, позволяющих задать тип элементов, размерность, нижнюю границу массива, а также количество элементов в каждом измерении. Метод выделяет память, записывает заданные параметры в служебную область выделенного блока и возвращает ссылку на массив. При наличии двух и более измерений ссылку, возвращенную методом Createlnstance, можно привести к типу переменной ElementType [ ] (здесь ElementType — имя типа), чтобы упростить доступ к элементам массива. Для доступа к элементам одномерных массивов пользуйтесь методами GetValue и SetValue класса Array.
Рассмотрим процесс динамического создания двухмерного массива значений типа System.Decimal. Первое измерение составят годы с 2005 по 2009 включительно, а второе — кварталы с 1 по 4 включительно. Все элементы обрабатываются в цикле. Прописав в коде границы массива в явном виде, мы получили бы выигрыш в производительности, но вместо этого воспользуемся методами Get Lower Bound и GetUpperBound класса System.Array:
using System;
public static class DynamicArrays { public static void Main() {
// Требуется двухмерный массив [2005..2009][1..4]
Int32[] lowerBounds = { 2005, 1 };

Int32[] lengths = { 5, 4 };
Decimal[,] quarterlyRevenue = (Decimal[,])
Array.CreateInstance(typeof(Decimal), lengths, lowerBounds);
Console.WriteLine("{0,4} {1,9} {2,9} {3,9} {4,9}",
"Year", "Ql", "Q2", "Q3", "Q4");
Int32 firstYear = quarterlyRevenue.GetLowerBound(0);
Int32 lastYear = quarterlyRevenue.GetllpperBound(0);
Int32 flrstQuarter = quarterlyRevenue.GetLowerBound(1);
Int32 lastQuarter = quarterlyRevenue.GetUpperBound(l);
for (Int32 year = firstYear; year <= lastYear; year++) {
Console.Write(year + " "); for (Int32 quarter = flrstQuarter; quarter <= lastQuarter; quarter++) {
Console.Write("{0,9:C} ", quarterlyRevenue[year, quarter]);
}
Console. WriteLineQ;
}
}
}
После компиляции и выполнения этого кода получаем:
| Year | Ql | Q2 | Q3 | Q4 |
| 2005 | $0.00 | $0.00 | $0.00 | $0.00 |
| 2006 | $0.00 | $0.00 | $0.00 | $0.00 |
| 2007 | $0.00 | $0.00 | $0.00 | $0.00 |
| 2008 | $0.00 | $0.00 | $0.00 | $0.00 |
| 2009 | $0.00 | $0.00 | $0.00 | $0.00 |
|
|
Внутренняя реализация массивов
В CLR поддерживаются массивы двух типов:
□ Одномерные массивы с нулевым начальным индексом. Иногда их называют SZ-массивами (от английского single-dimensional, zero-based), или векторами.
□ Одномерные и многомерные массивы с неизвестным начальным индексом.
Рассмотрим их на примере следующего кода (результат его выполнения приводится в комментариях):
using System;
public sealed class Program { public static void Maln() {
Array a;
// Создание одномерного массива с нулевым // начальным индексом и без элементов а = new String[0];
Console.WriteLine(a.GetType()); // "System.String[]"
// Создание одномерного массива с нулевым // начальным индексом и без элементов а = Array.CreateInstance(typeof(String), new Int32[] { 0 }, new Int32[] { 0 });
Console.WriteLine(a.GetType()); // "System.String[]"
// Создание одномерного массива с начальным индексом 1 и без элементов а = Array.CreateInstance(typeof(String), new Int32[] { 0 }, new Int32[] { 1 });
Console.WriteLine(a.GetType())j // "System.String[*]“ <-- ВНИМАНИЕ!
Console.WrlteLine();
// Создание двухмерного массива с нулевым // начальным индексом и без элементов а = new String[0, 0];
Console.WrlteLine(a.GetType()); // "System.String[,]"
// Создание двухмерного массива с нулевым // начальным индексом и без элементов а = Array.CreateInstance(typeof(String), new Int32[] { 0, 0 }, new Int32[] { 0, 0 });
Console.WriteLine(a.GetType()); // "System.String[,]"
// Создание двухмерного массива с начальным индексом 1 и без элементов а = Array.CreateInstance(typeof(String)^
new Int32[] { 0, 0 }, new Int32[] { 1, 1 });
Console.WrlteLlne(a.GetType())j // "System.String[,]"
}
Рядом с каждой инструкцией Console.WriteLine в виде комментария показан результат действия. Для одномерных массивов с нулевой нижней границей это System.String[], если же индексация начинается с единицы, выводится уже System.String[*]. Знак * свидетельствует о том, что CLR знает о ненулевой нижней границе. Так как в C# объявить переменную типа String[ *] невозможно, синтаксис этого языка запрещает обращение к одномерным массивам с ненулевой нижней границей. Впрочем, обойти это ограничение можно с помощью методов GetValue и SetValue класса Array, но дополнительные затраты на вызов метода снижают эффективность работы программы.
Для многомерных массивов, независимо от нижней границы, отображается один и тот же тип: System .String[, ]. Во время выполнения CLR рассматривает их как массивы с ненулевой нижней границей. Логично было бы предположить, что имя типа будет представлено как System.String[*,*], но в CLR для многомерных массивов не используется знак *. Ведь иначе он выводился бы во всех случаях, создавая путаницу.
Доступ к элементам одномерного массива с нулевой нижней границей осуществляется немного быстрее, чем доступ к элементам многомерных массивов или массивов с ненулевой нижней границей. Есть несколько причин такому поведению. Во-первых, специальные команды для работы с одномерными массивами с нулевой нижней границей (newarr, ldelem, ldelema, ldlen и stelem) позволяют JIT-компилятору генерировать оптимизированный код. При этом предполагается, что первый индекс равен нулю, то есть при доступе к элементам отсутствует необходимость вычислять смещение. Кроме того, в общем случае компилятор умеет выносить код проверки границ за пределы цикла. К примеру, рассмотрим следующий код:
using System;
public static class Program { public static void Main() {
Int32[] a = new Int32[5];
for(Int32 index = 0; index < a.Length; index++) {
// Какие-то действия с элементом а[index]
>
>
}
Обратите внимание на вызов свойства Length в проверочном выражении цикла for. Фактически при этом вызывается метод, но JIT-компилятор «знает», что Length является свойством класса Array, поэтому создает код, в котором метод вызывается всего один раз, а полученный результат сохраняется в промежуточной переменной. Именно ее значение проверяется на каждой итерации цикла. В результате такой код работает очень быстро. Некоторые разработчики недооценивают возможности JIT-компилятора и пишут «умный код», пытаясь помочь его работе. Однако такие попытки практически всегда приводят к снижению производительности, а также делают готовую программу непонятной и неудобной для редактирования. Поэтому пусть свойство Length вызывается автоматически.
Кроме того, JIT-компилятор «знает», что цикл обращается к элементам массива с нулевой нижней границей, указывая Length -1. Поэтому он в процессе выполнения генерирует код, проверяющий, все ли элементы находятся в границах массива. А именно, проверяется условие:
(0 >= a.GetLowerBound(0)) && ((Length - 1) <= a.GetUpperBound(0))
Проверка осуществляется до начала цикла. В случае положительного результата компилятор не создает в теле цикла кода, проверяющего, не вышел ли индекс элемента за границы диапазона. Именно за счет этого обеспечивается высокая производительность доступа к массиву.
К сожалению, обращение к элементам многомерного массива или массива с ненулевой нижней границей происходит намного медленней. Ведь в этих случаях код проверки индекса не выносится за пределы цикла и проверка осуществляется на каждой итерации. Кроме того, компилятор добавляет код, вычитающий из текущего индекса нижнюю границу массива. Это также замедляет работу программы даже в случае многомерных массивов с нулевой нижней границей. Если вы серьезно озабочены проблемой производительности, имеет смысл использовать нерегулярные массивы (массивы массивов).
Кроме того, в C# и CLR возможен доступ к элементам массива при помощи небезопасного (неверифицируемого) кода. В этом случае; процедура проверки индексов массива просто отключается. Данная техника применима только к массивам типа SByte, Byte, Intl6, UIntl6, Int32, UInt32, Int64, UInt64, Char, Single, Double, Decimal, Boolean, а также к массивам перечислимого типа или структуры значимого типа с полями одного из вышеуказанных типов.
Эту мощную возможность следует использовать крайне осторожно, так как она дает прямой доступ к памяти. При этом выход за границы массива не сопровождается появлением исключения; вместо этого происходит повреждение памяти, нарушение безопасности типов и, скорее всего, в системы безопасности программы появляется дефект. Поэтому сборке, содержащей небезопасный код, следует обеспечить полное доверие или же предоставить разрешение Security Permission, включив свойство Skip Verification.
Следующий код демонстрирует три варианта доступа к двухмерному массиву, включая безопасный доступ, доступ через нерегулярный массив и небезопасный доступ:
using System;
using System.Diagnostics;
public static class Program {
private const Int32 c_numElements = 10000;
public static void Main() {
// Объявление двухмерного массива
Int32[,] a2Dim = new Int32[c_numElements, cnumElements];
// Объявление нерегулярного двухмерного массива (вектор векторов)
Int32[][] alagged = new Int32[c_numElements][]; for (Int32 x = 0; x < c_numElements; x++) a3agged[x] = new Int32[c_numElements];
// 1: Обращение к элементам стандартным, безопасным способом Safe2DimArrayAccess(a2Dim);
// 2: Обращение к элементам с использованием нерегулярного массива Safe3aggedArrayAccess(a3agged);
// 3: Обращение к элементам небезопасным методом Unsafe2DimArrayAccess(a2Dim);
} private static Int32 Safe2DimArrayAccess(Int32[,] a) {
Int32 sum = 0;
for (Int32 х = 0; х < cnumElements; х++) {
for (Int32 у = 0; у < cnumElements; у++) {
sum += а[х, у];
>
}
return sum;
>
private static Int32 Safe3aggedArrayAccess(Int32[][ ] a) {
Int32 sum = 0;
for (Int32 x = 0; x < cnumElements; x++) {
for (Int32 у = 0; у < c_numElements; y++) {
sum += a[x][y];
>
}
return sum;
}
private static unsafe Int32 Unsafe2DimArrayAccess(Int32[,] a) { Int32 sum = 0; fixed (Int32* pi = a) {
for (Int32 x = 0; x < c_numElements; x++) {
Int32 baseOfDim = x * c_numElements; for (Int32 у = 0; у < cnumElements; y++) { sum += pi[baseOfDim + y];
}
}
}
return sum;
}
}
Метод Unsafe2DimArrayAccess имеет модификатор unsafe, который необходим для инструкции fixed языка С#. При вызове компилятора следует установить переключатель /unsafe или флажок Allow Unsafe Code на вкладке Build окна свойств проекта в программе Microsoft Visual Studio.
Существуют ситуации, в которых «небезопасный» доступ оказывается оптимальным, но у него есть три серьезных недостатка:
□ код обращения к элементам массива менее читабелен и более сложен в написании из-за присутствия инструкции fixed и вычисления адресов памяти;
□ ошибка в расчетах может привести к перезаписи памяти, не принадлежащей массиву, в результате возможны разрушение памяти, нарушение безопасности типов и потенциальные бреши в системе безопасности;
□ из-за высокой вероятности проблем CLR запрещает работу небезопасного кода в средах с пониженным уровнем безопасности (таких, как Microsoft Silverlight).
Небезопасный доступ к массивам и массивы фиксированного размера
Небезопасный доступ к массиву является крайне мощным средством, так как именно такой доступ дает возможность работать:
□ с элементами управляемого массива, расположенными в куче (как показано в предыдущем разделе);
□ с элементами массива, расположенными в неуправляемой куче (пример SecureString из главы 14 демонстрирует небезопасный метод доступа к массиву, возвращаемому методом SecureStringToCoTaskMemUnicode класса System. Runtime.InteropServices.Marshal);
□ с элементами массива, расположенными в стеке потока.
Если производительность для вас критична, управляемый массив можно вместо кучи разместить в стеке потока. Для этого вам потребуется инструкция stackalloc языка C# (ее принцип действия напоминает функцию alloca языка С). Она позволяет создавать одномерные массивы элементов значимого типа с нулевой нижней границей. При этом значимый тип не должен содержать никаких полей ссылочного типа. По сути, вы выделяете блок памяти, с которым можно работать при помощи небезопасных указателей, поэтому адрес этого буфера нельзя передавать большинству FCL-методов. Выделенная в стеке память (массив) автоматически освобождается после завершения метода. Именно за счет этого и достигается выигрыш в производительности. При этом для компилятора C# должен быть задан параметр /unsafe.
Метод StackallocDemo демонстрирует пример использования инструкции stackalloc:
using System;
public static class Program { public static void Main() {
StackallocDemo();
InlineArrayDemoQ;
}
private static void StackallocDemo() { unsafe {
const Int32 width = 20;
Char* pc = stackalloc Char[width]; // В стеке выделяется
// память под массив
String s = "Jeffrey Richter"; // 15 символов
for (Int32 index = 0; index < width; index++) { pc[width - index - 1] =
(index < s.Length) ? s[index] :
}
// Следующая инструкция выводит на экран "............ rethciR yerffeJ"
Console.WriteLine(new String(pc, 0, width));
}
private static void InlineArrayDemoQ { unsafe {
CharArray ca; // Память под массив выделяется в стеке Int32 widthlnBytes = sizeof(CharArray);
Int32 width = widthlnBytes / 2;
String s = "Jeffrey Richter"; // 15 символов
for (Int32 index = 0; index < width; index++) { ca.Characters[width - index - 1] =
(index < s.Length) ? s[index] :
}
// Следующая инструкция выводит на экран "............ rethciR yerffeJ
Console.WriteLine(new String(ca.Characters, 0, width));
}
}
internal unsafe struct CharArray {
// Этот массив встраивается в структуру public fixed Char Characters[20];
Так как массивы относятся к ссылочным типам, поле массива, определенное в структуре, содержит указатель или ссылку на этот массив; при этом сам он располагается вне памяти структуры. Впрочем, существует возможность встроить массив непосредственно в структуру. Вы это видели в показанном коде на примере структуры CharArray. При этом должны соблюдаться следующие условия:
□ тип должен быть структурой (значимым типом), встраивать массивы в класс (ссылочный тип) нельзя;
□ поле или структура, в которой оно определено, должно быть помечено модификатором unsafe;
□ поле массива должен быть помечено модификатором fixed;
□ массив должен быть одномерным и с нулевой нижней границей;
□ элементы массива могут принадлежать только к типам: Boolean, Char, SByte, Byte, Int32, UInt32, Int64, UInt64, Single и Double.
Встроенные массивы обычно применяются в сценариях, работающих с небезопасным кодом, в котором неуправляемая структура данных также содержит встроенный массив. Впрочем, никто не запрещает использовать их и в других случаях, например, как показано ранее в методе InlineArrayDemo, который по-своему решает ту же задачу, что и метод StackallocDemo.
Глава 17. Делегаты
В этой главе рассказывается о чрезвычайно полезном механизме, который используется уже много лет и называется функциями обратного вызова. В Microsoft .NET Framework этот механизм поддерживается при помощи делегатов (delegates). В отличие от других платформ, например неуправляемого языка C++, делегаты обладают более широкой функциональностью. Например, они обеспечивают безопасность типов при выполнении обратного вызова (способствуя решению одной из важнейших задач CLR). Кроме того, они обеспечивают возможность последовательного вызова нескольких методов, а также вызова как статических, так и экземплярных методов.
Знакомство с делегатами
Функция qsort исполняющей среды С получает указатель на функцию обратного вызова для сортировки элементов массивов. В Windows механизм обратного вызова используется оконными процедурами, процедурами перехвата, асинхронным вызовом процедур и др. В .NET Framework методы обратного вызова также имеют многочисленные применения. К примеру, можно зарегистрировать такой метод для получения различных уведомлений: о необработанных исключениях, изменении состояния окон, выборе пунктов меню, изменениях файловой системы и завершении асинхронных операций.
В неуправляемом языке C/C++ адрес функции — не более чем адрес в памяти, не несущий дополнительной информации. В нем не содержится информация ни о количестве ожидаемых функцией параметров, ни об их типе, ни о типе возвращаемого функцией значения, ни о правилах вызова. Другими словами, функции обратного вызова C/C++ не обеспечивают безопасность типов (хотя их и отличает высокая скорость выполнения).
В .NET Framework функции обратного вызова играют не менее важную роль, чем при неуправляемом программировании для Windows. Однако данная платформа предоставляет в распоряжение разработчика делегатов — механизм, безопасный по отношению к типам. Рассмотрим пример объявления, создания и использования делегатов:
using System;
using System.Windows.Forms; using System.10;
// Объявление делегата; экземпляр ссылается на метод
// с параметром типа Int32, возвращающий значение void internal delegate void Feedback(Int32 value);
public sealed class Program { public static void Main() {
StaticDelegateDemo();
InstanceDelegateDemo();
ChainDelegateDemol(new ProgramQ);
ChainDelegateDemo2(new ProgramQ);
>
private static void StaticDelegateDemo() {
Console.WriteLine("-------- Static Delegate Demo ---------- ");
Counter(lj 3j null);
Counter(lj 3, new Feedback(Program.FeedbackToConsole));
Counter(lj 3, new Feedback(FeedbackToMsgBox)); // Префикс "Program."
// не обязателен
Console.WriteLine();
}
private static void InstanceDelegateDemo() {
Console.WriteLine("-------- Instance Delegate Demo -------- ");
Program p = new Program();
Counter(l, 3, new Feedback(p.FeedbackToFile));
Console.WriteLine();
}
private static void ChainDelegateDemol(Program p) {
Console.WriteLine("-------- Chain Delegate Demo 1 --------- ");
Feedback fbl = new Feedback(FeedbackToConsole);
Feedback fb2 = new Feedback(FeedbackToMsgBox);
Feedback fb3 = new Feedback(p.FeedbackToFile);
Feedback fbChain = null;
fbChain = (Feedback) Delegate.Combine(fbChain, fbl); fbChain = (Feedback) Delegate.Combine(fbChain, fb2); fbChain = (Feedback) Delegate.Combine(fbChain, fb3);
Counter(l, 2, fbChain);
Console.WriteLine(); fbChain = (Feedback)
Delegate.Remove(fbChain, new Feedback(FeedbackToMsgBox));
Counter(l, 2, fbChain);
}
private static void ChainDelegateDemo2(Program p) {
Console.WriteLine("-------- Chain Delegate Demo 2 --------- ");
Feedback fbl = new Feedback(FeedbackToConsole);
Feedback fb2 = new Feedback(FeedbackToMsgBox);
Feedback fb3 = new Feedback(p.FeedbackToFile);
Feedback fbChain = null;
продолжение
fbChain += fbl; fbChain += fb2; fbChain += fb3;
Counter(l, 2, fbChain);
Console.WriteLine();
fbChain -= new Feedback(FeedbackToMsgBox);
Counter(l, 2, fbChain);
}
private static void Counter(Int32 from, Int32 to, Feedback fb) { for (Int32 val = from; val <= to; val++) {
// Если указаны методы обратного вызова, вызываем их if (fb != null) fb(val);
}
}
private static void FeedbackToConsole(Int32 value) {
Console.WriteLine("Item=" + value);
}
private static void FeedbackToMsgBox(Int32 value) {
MessageBox.Show("Item=" + value);
}
private void FeedbackToFile(Int32 value) {
using (StreamWriter sw = new StreamWriter("Status", true)) { sw.WriteLine("Item=" + value);
}
}
Рассмотрим этот код более подробно. Прежде всего следует обратить внимание на объявление внутреннего делегата Feedback. Он задает сигнатуру метода обратного вызова. Данный делегат определяет метод, принимающий один параметр типа Int32 и возвращающий значение void. Он напоминает ключевое слово typedef из C/C++, которое предоставляет адрес функции.
Класс Program определяет закрытый статический метод Counter. Он перебирает целые числа в диапазоне, заданном аргументами from и to. Также он принимает параметр f Ь, который является ссылкой на делегат Feedback. Метод Counter перебирает числа в цикле и для каждого из них при условии, что переменная f b не равна null, выполняет метод обратного вызова (определенный переменной fb). При этом методу обратного вызова передается значение обрабатываемого элемента и его номер. Реализация данного метода может обрабатывать элементы так, как считает нужным.
Обратный вызов статических методов
Теперь, когда мы разобрали принцип работы метода Counter, рассмотрим процедуру использования делегатов для вызова статических методов. Для примера возьмем метод StaticDelegateDemo из представленного в предыдущем разделе кода.
Метод StaticDelegateDemo вызывает метод Counter, передавая в третьем параметре f b значение null. В результате при обработке элементов не задействуется метод обратного вызова.
При втором вызове метода Counter методом StaticDelegateDemo третьему параметру передается только что созданный делегат Feedback. Этот делегат служит оболочкой для другого метода, позволяя выполнить обратный вызов последнего косвенно, через оболочку. В рассматриваемом примере имя статического метода Program. FeedbackToConsole передается конструктору Feedback, указывая, что именно для него требуется создать оболочку. Возвращенная оператором new ссылка передается третьему параметру метода Counter, который в процессе выполнения будет вызывать статический метод FeedbackToConsole. Последний же просто выводит на консоль строку с названием обрабатываемого элемента.
ПРИМЕЧАНИЕ
Метод FeedbackToConsole определен в типе Program как закрытый, но при этом может быть вызван методом Counter. Так как оба метода определены в пределах одного типа, проблем с безопасностью не возникает. Но даже если бы метод Counter был определен в другом типе, это не сказалось бы на работе коде. Другими словами, если код одного типа вызывает посредством делегата закрытый член другого типа, проблем с безопасностью или уровнем доступа не возникает, если делегат создан в коде, имеющем нужный уровень доступа.
Третий вызов метода Counter внутри метода StaticDelegateDemo отличается от второго тем, что делегат Feedback является оболочкой для статического метода Program.FeedbackToMsgBox. Именно метод FeedbackToMsgBox создает строку, указывающую на обрабатываемый элемент, которая затем выводится в окне в виде сообщения.
В этом примере ничто не нарушает безопасность типов. К примеру, при создании делегата Feedback компилятор убеждается в том, что сигнатуры методов FeedbackToConsole и FeedbackToMsgBox типа Program совместимы с сигнатурой делегата. Это означает, что оба метода будут принимать один и тот же аргумент (типа Int32) и возвращать значение одного и того же типа (void). Однако попробуем определить метод FeedbackToConsole вот так: private static Boolean FeedbackToConsole(String value) {
}
В этом случае компилятор выдаст сообщение об ошибке (сигнатура метода FeedbackToConsole не соответствует типу делегата):
error CS0123: No overload for 'FeedbackToConsole' matches delegate 'Feedback'
Как С#, так и CLR поддерживают ковариантность и контравариантность ссылочных типов при привязке метода к делегату. Ковариантность (covariance) означает, что метод может возвратить тип, производный от типа, возвращаемого делегатом. Контравариантность (contra-variance) означает, что метод может принимать параметр, который является базовым для типа параметра делегата. Например:
delegate Object MyCallback(FileStream s);
Определив делегат таким образом, можно получить экземпляр этого делегата, связанный с методом, прототип которого выглядит примерно так:
String SomeMethod(Stream s);
Здесь тип значения, возвращаемого методом SomeMethod (тип String), является производным от типа, возвращаемого делегатом (Object); такая ковариантность разрешена. Тип параметра метода SomeMethod (тип Stream) является базовым классом для типа параметра делегата (FileStream); такая контравариантность тоже разрешена.
Обратите внимание, что ковариантность и контравариантность поддерживаются только для ссылочных типов, но не для значимых типов или значения void. К примеру, связать следующий метод с делегатом MyCallback невозможно:
Int32 SomeOtherMethod(Stream s);
Несмотря на то что тип значения, возвращаемого методом SomeOtherMethod (то есть Int32), является производным от типа значения, возвращаемого методом MyCallback (то есть Object), такая форма ковариантности невозможна, потому что Int32 — это значимый тип. Значимые типы и void не могут использоваться кова- риантно и контравариантно, потому что их структура памяти меняется, в то время как для ссылочных типов структурой памяти в любом случае остается указатель. К счастью, при попытке выполнить запрещенные действия компилятор возвращает сообщение об ошибке.
Обратный вызов экземплярных методов
Мы рассмотрели процедуру вызова при помощи делегатов статических методов, но они позволяют вызывать также экземплярные методы заданного объекта. Рассмотрим механизм этого вызова на примере метода InstanceDelegateDemo из показанного ранее кода.
Обратите внимание, что объект р типа Program создается внутри метода InstanceDelegateDemo. При этом у него отсутствуют экземплярные поля и свойства, поскольку он сконструирован с демонстрационными целями. Когда при вызове метода Counter создается делегат Feedback, его конструктору передается объект р. FeedbackToFile. В результате делегат превращается в оболочку для ссылки на метод FeedbackToFile, который является не статическим, а экземплярным методом. Когда метод Counter обращается к методу обратного вызова, который задан аргументом fb, вызывается экземплярный метод FeedbackToFile, а адрес только что созданного объекта р передается этому методу в качестве неявного аргумента this.
Метод FeedbackToFile отличается от методов FeedbackToConsole и FeedbackTo- MsgBox тем, что открывает файл и дописывает в его конец строку (созданный им файл Status находится в папке AppBase приложения).
Как видите, делегаты могут служить оболочкой как для статических, так и для экземплярных методов. В последнем случае делегат должен знать, какой экземпляр объекта будет обрабатывать вызываемый им метод. Создавая оболочку для экземплярного метода, вы предоставляете коду внутри объекта доступ к различным членам экземпляра объекта. Это означает наличие у объекта состояния, которое может использоваться во время выполнения метода обратного вызова.
Тонкости использования делегатов
На первый взгляд работать с делегатами легко. Они определяются при помощи ключевого слова C# delegate, оператор new создает экземпляры делегатов, а для обратного вызова служит уже знакомый синтаксис. В последнем случае вместо имени метода указывается ссылающаяся на делегат переменная.
На самом деле все обстоит несколько сложнее, чем демонстрируют приведенные примеры. Пользователи просто не осознают всей сложности процесса благодаря работе компиляторов и CLR. Однако в этом разделе рассматриваются все тонкости реализации делегатов, так как это поможет нам понять принцип их работы и научиться применять их эффективно и рационально. Также будут рассмотрены некоторые дополнительные возможности делегатов.
Внимательно посмотрите на следующую строку:
internal delegate void Feedback(Int32 value);
Она заставляет компилятор создать полное определение класса, которое выглядит примерно так:
internal class Feedback : System.MulticastDelegate {
// Конструктор
public Feedback(Object object, IntPtr method);
// Метод, прототип которого задан в исходном тексте public virtual void Invoke(Int32 value);
// Методы, обеспечивающие асинхронный обратный вызов public virtual IAsyncResult BeginInvoke(Int32 value,
AsyncCallback callback. Object object); public virtual void EndInvoke(IAsyncResult result);
>
Класс, определенный компилятором, содержит четыре метода: конструктор, а также методы Invoke, Beginlnvoke и Endlnvoke. В этой главы мы в основном будем рассматривать конструктор и метод Invoke. Методы Beginlnvoke и Endlnvoke относятся к модели асинхронного программирования .NET Framework, которая сейчас считается устаревшей. Она была заменена асинхронными операциями, которые рассматриваются в главе 27.

Исследовав итоговую сборку при помощи утилиты ILDasm.exe, можно убедиться, что компилятор действительно автоматически сгенерировал этот класс (рис 17.1).
| {? t.<n ПОДУЛ | |
| tilt Yitw Urfp |
| Ы V 4-Л |
| fr ГЧ Д N 3 F F 5 Т Б Ш [7^"ПТ я Й N .dftK (fwat* ej® -спя «--fifed |
В этом примере компилятор определил класс Feedback, производный от типа System.MulticastDelegate из библиотеки классов Framework Class Library (все типы делегатов являются потомками MulticastDelegate).
ВНИМАНИЕ
Класс System.MulticastDelegate является производным от класса System.Delegate, который, в свою очередь, наследует от класса System.Object. Два класса делегатов появились исторически, в то время как в FCL предполагался только один. Вам следует помнить об обоих классах, так как даже если выбрать в качестве базового класс MulticastDelegate, все равно иногда приходится работать с делегатами, использующими методы класса Delegate. Скажем, именно этому классу принадлежат статические методы Combine и Remove (о том, зачем они нужны, мы поговорим чуть позже). Сигнатуры этих методов указывают, что они принимают параметры класса Delegate. Так как тип вашего делегата является производным от класса MulticastDelegate, для которого базовым является класс Delegate, методам можно передавать экземпляры типа делегата.
Это закрытый класс, так как делегат объявляется в исходном коде с модификатором internal. Если объявить его с модификатором public, сгенерированный компилятором класс Feedback будет открытым. Следует помнить, что делегаты можно определять как внутри класса (вложенные в другой класс), так и в глобаль
ной области видимости. По сути, так как делегаты являются классами, их можно определить в любом месте, где может быть определен класс.
Любые типы делегатов — это потомки класса MulticastDelegate, от которого они наследуют все поля, свойства и методы. Три самых важных поля описаны в табл. 17.1.
| Таблица 17.1. Важнейшие закрытые поля класса MulticastDelegate
|
|
|
Обратите внимание, что конструктор всех делегатов принимает два параметра: ссылку на объект и целое число, ссылающееся на метод обратного вызова. Нов тексте исходного кода туда передаются такие значения, как Program. FeedbackToConsole или р. FeedbackToFile. Вероятно, весь ваш опыт программирования подсказывает, что этот код компилироваться не будет!
Однако компилятор знает о том, что создается делегат, и, проанализировав код, определяет объект и метод, на которые мы ссылаемся. Ссылка на объект передается в параметре object конструктора. Специальное значение IntPtr (получаемое из маркеров метаданных MethodDef или MemberRef), идентифицирующее метод, передается в параметре method. В случае статических методов параметр object передает значение null. Внутри конструктора значения этих двух аргументов сохранятся в закрытых полях _target и _methodPtr соответственно. Кроме того, конструктор присваивает значение null полю _invocationList. О назначении этого поля мы подробно поговорим в разделе, посвященном цепочкам делегатов.
Таким образом, любой делегат — это всего лишь обертка для метода и обрабатываемого этим методом объекта. Поэтому в следующих строчках кода переменные fbStatic и fblnstance ссылаются на два разных объекта Feedback, инициализированных, как показано на рис. 17.2:
Feedback fbStatic = new Feedback(Program.FeedbackToConsole);
Feedback fblnstance = new Feedback(new Program().FeedbackToFile);
|
Рис. 17.2. Верхняя переменная ссылается на делегата статического метода, нижняя — на делегата экземплярного метода |
Теперь, когда вы познакомились с процессом создания делегатов и их внутренней структурой, поговорим о методах обратного вызова. Рассмотрим еще раз код метода Counter:
private static void Counter(Int32 from, Int32 to. Feedback fb) { for (Int32 val = from; val <= to; val++) {
// Если указаны методы обратного вызова, вызываем их if (fb != null) fb(val);
}
}
Обратите внимание на строку под комментарием. Инструкция if сначала проверяет, не содержит ли переменная f b значения null. Если проверка пройдена, обращаемся к методу обратного вызова. Такая проверка необходима потому, что fb — это всего лишь переменная, ссылающаяся на делегат Feedback; она может иметь, в том числе, значение null. Может показаться, что происходит вызов функции f Ь, которой передается один параметр (val). Но у нас нет функции с таким именем. И компилятор генерирует код вызова метода Invoke делегата, так как он знает, что переменная f b ссылается на объект делегата. Другими словами, при обнаружении строки
fb(val);
компилятор генерирует такой же код, как и для строки:
fb.Invoke(val);
Воспользовавшись утилитой ILDasm.exe для исследования кода метода Counter, можно убедиться, что компилятор генерирует код, вызывающий метод Invoke. Далее показан IL-код метода Counter. Команда в строке IL_0009 является вызовом метода Invoke объекта Feedback.
.method private hidebysig static void Counter(int32 from,
int32 'to',
class Feedback fb) cil managed
{
// Code size 23 (0x17)
.maxstack 2
.locals init (int32 V_0)
ldarg.0 stloc.0 br.s IL0012 ldarg.2
 brfalse.s IL_000e ldarg.2 ldloc.0
brfalse.s IL_000e ldarg.2 ldloc.0
callvlrt Instance void Feedback::Invoke(lnt32)
ldloc.0
ldc.14.1
add
stloc.0 ldloc.0 ldarg.1 ble.s IL0004 ret
} // end of method Program::Counter
В принципе метод Counter можно изменить, включив в него явный вызов Invoke:
private static void Counter(Int32 from, Int32 to, Feedback fb) { for (Int32 val = from; val <= to; val++) {
// Если указаны методы обратного вызова, вызываем их if (fb != null) fb.Invoke(val);
}
}
Надеюсь, вы помните, что компилятор определяет метод Invoke при определении класса Feedback. Вызывая этот метод, он использует закрытые поля _target и _methodPtr для вызова желаемого метода на заданном объекте. Обратите внимание, что сигнатура метода Invoke совпадает с сигнатурой делегата, ведь и делегат Feedback, и метод Invoke принимают один параметр типа Int32 и возвращают значение void.
Обратный вызов нескольких методов (цепочки делегатов)
Делегаты полезны сами по себе, но еще более полезными их делает механизм цепочек. Цепочкой (chaining) называется коллекция делегатов, дающая возможность вызывать все методы, представленные этими делегатами. Чтобы понять, как работает цепочка, вернитесь к коду в начале этой главы и найдите там метод ChainDelegateDemol. В этом методе после инструкции Console .WriteLine создаются три делегата, на которые ссылаются переменные f Ы, f Ь2 и f ЬЗ соответственно (рис. 17.3).
|
Рис. 17.3. Начальное состояние делегатов, на которые ссылаются переменные fb1, fb2 и fb3 |
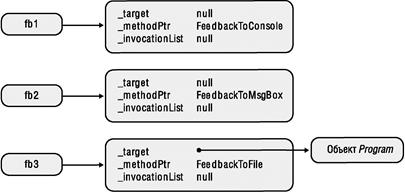
Ссылочная переменная на делегат Feedback, которая называется fbChain, должна ссылаться на цепочку, или набор делегатов, служащих оболочками для методов обратного вызова. Инициализация переменной fbChain значением null указывает на отсутствие методов обратного вызова. Открытый статический метод Combine класса Delegate добавляет в цепочку делегатов:
fbChain = (Feedback) Delegate.Combine(fbChain, fbl);
При выполнении этой строки метод Combine видит, что мы пытаемся объединить значение null с переменной fbl. В итоге он возвращает значение в переменную fbl, а затем заставляет переменную fbChain сослаться на делегата, на которого уже ссылается переменная fbl. Эта схема демонстрируется на рис. 17.4.
|
Рис. 17.4. Состояние делегатов после добавления в цепочку нового члена |
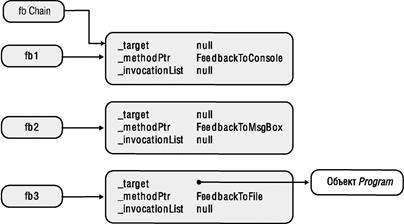
Чтобы добавить в цепочку еще одного делегата, снова воспользуемся методом Combine:
fbChain = (Feedback) Delegate.Combine(fbChain, fb2);
Метод Combine видит, что переменная fbChain уже ссылается на делегата, поэтому он создает нового делегата, который присваивает своим закрытым полям _target и _methodPtr некоторые значения. В данном случае они не важны, но важно, что поле _invocationList инициализируется ссылкой на массив делегатов. Первому элементу массива (с индексом 0) присваивается ссылка на делегат, служащий оболочкой метода FeedbackToConsole (именно на этот делегат ссылается переменная fbChain). Второму элементу массива (с индексом 1) присваивается ссылка на делегат, служащий оболочкой метода FeedbackToMsgBox (на этот делегат ссылается переменная f Ь2). Напоследок переменной fbChain присваивается ссылка на вновь созданный делегат (рис. 17.5).
|
Рис. 17.5. Делегаты после вставки в цепочку второго члена |
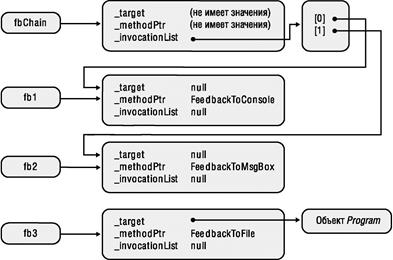
Для добавления в цепочку третьего делегата снова вызывается метод Combine: fbChain = (Feedback) Delegate.Combine(fbChain, fb3);
И снова, видя, что переменная fbChain уже ссылается на делегата, метод создает очередного делегата, как показано на рис. 17.6. Как и в предыдущих случаях, новый делегат присваивает начальные значения своим закрытым полям _tanget ii_methodPtr, в то время как поле _invoc at ion List инициализируется ссылкой на массив делегатов. Первому и второму элементам массива (с индексами 0 и 1) присваиваются ссылки на те же делегаты, на которые ссылался предыдущий делега т. Третий элемент массива (с индексом 2) становится ссылкой на делегата, служащего оболочкой метода FeedbackToFile (именно на этого делегата ссылается переменная f ЬЗ). Наконец, переменной fbChain присваивается ссылка на вновь созданного делегата. При этом ранее созданный делегат и массив, на который ссылается его поле _invocationList, теперь подлежат обработке механизмом уборки мусора.
|
Рис. 17.6. Окончательный вид цепочки делегатов |
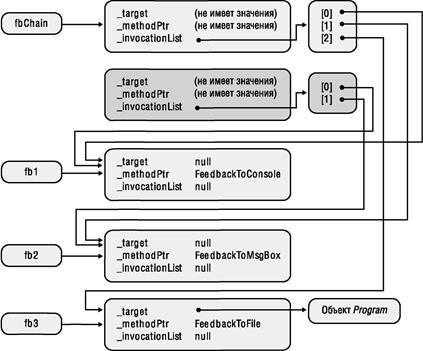
После выполнения кода, создающего цепочку, переменная fbChain передается методу Counter:
Counter(l, 2, fbChain);
Метод Counter содержит код неявного вызова метода Invoke для делегата Feedback. Впрочем, об этом мы уже говорили. Когда метод Invoke вызывается для делегата, ссылающегося на переменную fbChain, этот делегат обнаруживает, что значение поля _invocationList отлично от null. Это приводит к выполнению цикла, перебирающего все элементы массива, вызывая для них метод, оболочкой которого служит указанный делегат. В нашем примере методы вызываются в следующей последовательности: FeedbackToConsole, FeedbackToMsgBox и, наконец, FeedbackToFile.
Реализация метода Invoke класса Feedback выглядит примерно так (в псевдокоде):
public void Invoke(Int32 value) {
Delegate[] delegateSet = _invocationList as Delegate[]; if (delegateSet != null) {
// Этот массив указывает на делегаты, которые следует вызвать foreach (Feedback d in delegateSet) d(value); // Вызов каждого делегата } else {
// Этот делегат определяет используемый метод обратного вызова.
// Этот метод вызывается для указанного объекта.
_methodPtr.Invoke(_target, value);
// Строка выше - имитация реального кода.
// То, что происходит в действительности, не выражается средствами С#.
}
Для удаления делегатов из цепочки применяется статический метод Remove объекта Delegate. Эта процедура демонстрируется в конце кода метода Chain- DelegateDemol:
fbChain = (Feedback) Delegate.Remove(
fbChain, new Feedback(FeedbackToMsgBox));
Метод Remove сканирует массив делегатов (с конца и до члена с нулевым индексом), управляемый делегатом, на который ссылается первый параметр (в нашем примере это fbChain). Он ищет делегат, поля _target и jnethodPtr которого совпадают с соответствующими полями второго аргумента (в нашем примере это новый делегат Feedback). При обнаружении совпадения, если в массиве осталось более одного элемента, создается новый делегат — создается массив _invocationList, который инициализируется ссылкой на все элементы исходного массива за исключением удаляемого, — после чего возвращается ссылка на нового делегата. При удалении последнего элемента цепочки метод Remove возвращает значение null. Следует помнить, что метод Remove за один раз удаляет лишь одного делегата, а не все элементы с указанными значениями полей _target и _methodPtr.
Ранее мы также рассматривали делегат Feedback, возвращающий значение типа void. Однако этот делегат можно было определить и так:
public delegate Int32 Feedback(Int32 value);
В этом случае псевдокод метода Invoke выглядел бы следующим образом:
public Int32 Invoke(Int32 value) {
Int32 result;
Delegate[] delegateSet = invocationList as Delegate[]; if (delegateSet != null) {
// Массив указывает на делегаты, которые нужно вызвать foreach (Feedback d in delegateSet) result = d(value); // Вызов делегата } else {
// Этот делегат определяет используемый метод обратного вызова.
// Этот метод вызывается для указанного объекта, result = _methodPtr.Invoke(_target, value);
// Строка выше - имитация реального кода.
// То, что происходит в действительности, не выражается средствами С#.
}
return result;
}
По мере вызова отдельных делегатов возвращаемое значение сохраняется в переменной result. После завершения цикла в этой переменной оказывается только результат вызова последнего делегата (предыдущие возвращаемые значения отбрасываются); именно это значение возвращается коду, вызвавшему метод Invoke.
Поддержка цепочек делегатов в C#
Чтобы упростить задачу разработчиков, компилятор C# автоматически предоставляет перегруженные версии операторов += и -= для экземпляров делегатов. Эти операторы вызывают методы Delegate. Combine и Delegate. Remove соответственно. Они упрощают построение цепочек делегатов. В результате компиляции методов ChainDelegateDemol и ChainDelegateDemo2 (см. пример в начале главы) получается идентичный IL-code. Единственная разница в том, что благодаря операторам += и - = исходный код метода ChainDelegateDemo2 получается проще.
Для доказательства идентичности сгенерируйте IL-код обоих методов и изучите его при помощи утилиты ILDasm.exe. Вы убедитесь, что компилятор C# действительно заменяет все операторы += и -= вызовами статических методов Combine и Remove типа Delegate соответственно.
Дополнительные средства управления цепочками делегатов
Итак, вы научились создавать цепочки делегатов и вызывать все их компоненты. Последняя возможность реализуется благодаря наличию в методе Invoke кода, просматривающего все элементы массива делегатов. И хотя этого простого алгоритма хватает для большинства сценариев, у него есть ряд ограничений. К примеру, сохраняется только последнее из значений, возвращаемых методами обратного вызова. Получить все остальные значения нельзя. И это не единственное ограничение. Скажем, в ситуации, когда один из делегатов в цепочке становится причиной исключения или блокируется на очень долгое время, выполнение цепочки останавливается. Понятно, что данный алгоритм не отличается надежностью.
В качестве альтернативы можно воспользоваться экземплярным методом GetlnvocationList класса MulticastDelegate. Этот метод позволяет в явном виде вызвать любой из делегатов в цепочке:
public abstract class MulticastDelegate : Delegate {
// Создает массив, каждый элемент которого ссылается // на делегата в цепочке
public sealed override Delegate[] GetlnvocationListQ;
}
Метод GetlnvocationList работает с объектами классов, производных от MulticastDelegate. Он возвращает массив ссылок, каждая из которых указывает на какой-то делегат в цепочке. По сути, этот метод создает массив и инициализирует его элементы ссылками на соответствующие делегаты; в конце возвращается ссылка на этот массив. Если поле _invocation List содержит null, возвращаемый массив будет содержать всего один элемент, ссылающийся на единственного делегата в цепочке — экземпляр самого делегата.
Написать алгоритм, в явном виде вызывающий каждый элемент массива, несложно:
using System;
using System.Reflection;
using System.Text;
// Определение компонента Light internal sealed class Light {
// Метод возвращает состояние объекта Light public String SwitchPosition() { return "The light is off";
}
}
// Определение компонента Fan internal sealed class Fan {
// Метод возвращает состояние объекта Fan public String SpeedQ {
throw new InvalidOperationException("The fan broke due to overheating");
}
}
// Определение компонента Speaker internal sealed class Speaker {
// Метод возвращает состояние объекта Speaker public String Volume() {
return "The volume is loud";
}
}
public sealed class Program {
// Определение делегатов, позволяющих запрашивать состояние компонентов private delegate String GetStatus();
public static void Main() {
// Объявление пустой цепочки делегатов GetStatus getStatus = null;
// Создание трех компонентов и добавление в цепочку // методов проверки их состояния
getStatus += new GetStatus(new Light().SwitchPosition); getStatus += new GetStatus(new Fan().Speed);
getStatus += new GetStatus(new SpeakerQ .Volume);
// Сводный отчет о состоянии трех компонентов Console.WriteLine(GetComponentStatusReport(getStatus));
}
// Метод запрашивает состояние компонентов и возвращает информацию private static String GetComponentStatusReport(GetStatus status) {
// Если цепочка пуста, ничего делать не нужно if (status == null) return null;
// Построение отчета о состоянии StringBuilder report = new StringBuilderQ;
II Создание массива из делегатов цепочки
Delegate[] arrayOfDelegates = status.GetlnvocationListQ;
// Циклическая обработка делегатов массива foreach (GetStatus getStatus in arrayOfDelegates) {
try {
// Получение строки состояния компонента и добавление ее в отчет report.AppendFormat("{0}{1}{1}“, getStatus(), Environment.NewLine)
}
catch (InvalidOperationException e) {
// В отчете генерируется запись об ошибке для этого компонента Object component = getStatus.Target; report.AppendFormat(
"Failed to get status from {1}{2}{0} Error: {3}{0}{0}“, Environment.NewLine,
((component == null) ? "" : component.GetTypeQ + "."), getStatus.Method.Name, e.Message);
}
}
// Возвращение сводного отчета вызывающему коду return report.ToString();
}
Результат выполнения этого кода выглядит так:
The light is off
Failed to get status from Fan.Speed
Error: The fan broke due to overheating
The volume is loud
Обобщенные делегаты
Много лет назад, когда среда .NET Framework только начинала разрабатываться, в Microsoft ввели понятие делегатов. По мере добавления в FCL классов появлялись и новые типы делегатов. Со временем их накопилось изрядное количество. Только в библиотеке MSCorLib.dll их около 50. Вот некоторые из них:
public delegate void TryCode(Ob]ect userData); public delegate void WaitCallback(Ob]ect state); public delegate void TimerCallback(Ob]ect state); public delegate void ContextCallback(Ob]ect state); public delegate void SendOrPostCallback(Ob]ect state); public delegate void ParameterizedThreadStart(Object ob])j
Вы не заметили определенное сходство в отобранных мной делегатах? На самом деле они одинаковы: переменная любого из этих делегатов должна ссылаться на метод, получающий Object и возвращающий void. Соответственно весь этот набор делегатов не нужен — вполне можно обойтись одним.
Так как современная версия .NET Framework поддерживает обобщения, нам на самом деле нужно всего лишь несколько обобщенных делегатов (определенных в пространстве имен System), представляющих методы, которые могут принимать до 16 аргументов:
public delegate void Action(); // Этот делегат не обобщенный
public delegate void Action<T>(T obj);
public delegate void ActiorKTl, T2>(T1 argl, T2 arg2);
public delegate void ActiorKTl, T2, T3>(T1 argl, T2 arg2, T3 arg3);
public delegate void ActiorKTl, T16>(T1 argl, T16 argl6);
В .NET Framework имеются 17 делегатов Action, от не имеющих аргументов вообще до имеющих 16 аргументов. Чтобы вызвать метод с большим количеством аргументов, придется определить собственного делегата, но это уже маловероятно.
Кроме делегатов Action в .NET Framework имеется 17 делегатов Func, которые позволяют методу обратного вызова вернуть значение:
public delegate TResult Func<TResult>();
public delegate TResult Func<T, TResult>(T arg);
public delegate TResult FunccTl, T2, TResult>(Tl argl, T2 arg2);
public delegate TResult FunccTl, T2, T3, TResult>(Tl argl, T2 arg2, T3 arg3);
public delegate TResult FunccTl,..., T16, TResult>(Tl argl, ..., T16 argl6);
Вместо определения собственных типов делегатов рекомендуется по мере возможности использовать обобщенных делегатов; ведь это уменьшает количество типов в системе и упрощает код. Однако, если нужно передать аргумент по ссылке, используя ключевые слова ref или out, может потребоваться определение собственного делегата:
delegate void Bar(ref Int32 z);
Аналогично нужно действовать в ситуациях, когда требуется передать делегату переменное число параметров при помощи ключевого слова params, если вы хотите задать значения по умолчанию для аргументов делегата или если потребуется установить ограничение для аргумента-типа.
При работе с делегатами, использующими обобщенные аргументы и возвращающими значения, не следует забывать про ковариантность и контравариантность, так как это расширяет область применения делегатов. Дополнительная информация по этой теме приведена в главе 12.
Упрощенный синтаксис работы с делегатами
Многие программисты не любят делегатов из-за сложного синтаксиса. К примеру, рассмотрим строку:
buttonl.Click += new EventHandler(buttonl_Click);
Здесь buttonl_Click — метод, который выглядит примерно так:
void buttonl_Click(Ob]ect sender, EventArgs e) {
// Действия после щелчка на кнопке...
}
Первая строка кода как бы регистрирует адрес метода buttonl_Click в кнопке, чтобы при щелчке на ней вызывался метод. Программистам обычно кажется неразумным создавать делегат EventHandler всего лишь для того, чтобы указать на адрес метода buttonl_Click. Однако данный делегат нужен среде CLR, так как он служит оберткой, гарантирующей безопасность типов при вызове метода. Обертка также поддерживает вызов экземплярных методов и создание цепочек. Тем не менее программисты не хотят вникать во все эти детали и предпочли бы записать код следующим образом:
buttonl.Click += buttonl_Click;
К счастью, компилятор C# поддерживает упрощенный синтаксис при работе с делегатами. Однако перед тем как перейти к рассмотрению соответствующих возможностей, следует заметить, что это — не более чем упрощенные пути создания IL- кода, необходимого CLR для нормальной работы с делегатами. Кроме того, следует учитывать, что описание упрощенного синтаксиса работы с делегатами относится исключительно к С#; другими компиляторами он может и не поддерживаться.
Упрощение 1: не создаем объект делегата
Как вы уже видели, C# позволяет указывать имя метода обратного вызова без создания делегата, служащего для него оберткой. Вот еще один пример: internal sealed class AClass {
public static void Callbackl/\lithoutNewingADelegateObject() {
ThreadPool.QueueUserWorkItem(SomeAsyncTaskj 5);
}
private static void SomeAsyncTask(Object o) {
Console.WriteLine(o);
}
}
Статический метод QueueUserWorkltem класса ThreadPool ожидает ссылку на делегата WaitCallback, который, в свою очередь, ссылается на метод SomeAsyncTask. Так как компилятор в состоянии догадаться, что именно имеется в виду, можно опустить строки, относящиеся к созданию делегата WaitCallback, чтобы упростить чтение и понимание кода. В процессе компиляции IL-код, генерирующий нового делегата WaitCallback, создается автоматически, а запись является всего лишь упрощенной формой синтаксиса.
Упрощение 2: не определяем метод обратного вызова
В приведенном фрагменте кода метод обратного вызова SomeAsyncTask передается методу QueueUserWorkltem класса ThreadPool. C# позволяет подставить реализацию метода обратного вызова непосредственно в код, а не в отдельный метод. Скажем, наш код можно записать так:
internal sealed class AClass {
public static void CallbackWithoutNewingADelegateObject() {
ThreadPool.QueueUserWorkItem( obj => Console.WriteLine(obj ), 5);
}
}
Обратите внимание, что первый «аргумент» метода QueueUserWorkltem (он выделен полужирным шрифтом) представляет собой фрагмент кода! Формально в C# он называется лямбда-выражением (lambda expression) и распознается по наличию оператора =>. Лямбда-выражения используются в тех местах, где компилятор ожидает присутствия делегата. Обнаружив лямбда-выражение, компилятор автоматически определяет в классе новый закрытый метод (в нашем примере — AClass). Этот метод называется анонимной функцией (anonymous function), так как вы обычно не знаете его имени, которое автоматически создается компилятором. Впрочем, никто не мешает исследовать полученный код при помощи утилиты ILDasm.exe. Именно она помогла узнать после компиляции написанного фрагмента кода, что методу было присвоено имя <CallbackWithoutNewingADelegateObject
>b_ 0, а также, что метод принимает всего один аргумент типа Object, возвращая
значение типа void.
Компилятор выбирает для метода имя, начинающееся с символа <, потому что в C# идентификаторы не могут содержать этот символ. Такой подход гарантирует, что программист не сможет случайно выбрать для какого-нибудь из своих методов имя, совпадающее с автоматически созданным компилятором. При этом, если в C# идентификаторы не могут содержать символа <, в CLR это разрешено. Несмотря на возможность обращения к методу через механизм отражения путем передачи его имени в виде строки, следует помнить, что компилятор может по-разному генерировать это имя при каждом следующем проходе.
Утилита ILDasm.exe позволяет также заметить, что компилятор C# применяет к методу атрибут System. Runtime.CompilerServices. CompilerGeneratedAttribute. Это дает инструментам и утилитам возможность понять, что метод создан автоматически, а не написан программистом. В этот сгенерированный компилятором метод и помещается код, находящийся справа от оператора = >.
ПРИМЕЧАНИЕ
При написании лямбда-выражений невозможно применить к сгенерированному компилятором методу пользовательские атрибуты или модификаторы (например, unsafe). Впрочем, обычно это не является проблемой, так как созданные компилятором анонимные методы всегда закрыты. Каждый такой метод является статическим или нестатическим в зависимости от того, будет ли он иметь доступ к каким-либо экземплярным членам. Соответственно, применять кэтим методам модификаторы public, protected, internal, virtual, sealed, override или abstract просто не требуется.
Написанный код компилятор C# переписывает примерно таким образом (комментарии вставлены мною):
internal sealed class AClass {
// Это закрытое поле создано для кэширования делегата // Преимущество: CallbackWithoutNewingADelegateObject не будет // создавать новый объект при каадом вызове
// Недостатки: кэшированные объекты недоступны для сборщика мусора [CompilerGeпегated]
private static WaitCallback <>9_______ CachedAnonymousMethodDelegatel;
public static void CallbackWithoutNewingADelegateObject() {
if (<>9__ CachedAnonymousMethodDelegatel == null) {
// При первом вызове делегат создается и кэшируется
<>9__ CachedAnonymousMethodDelegatel =
new WaitCallback(<CallbackWithoutNewingADelegateObject>b___________ в);
}
ThreadPool.QueuellserWorkItem(<>9______ CachedAnonymousMethodDelegatel, 5);
}
[CompilerGenerated]
private static void <CallbackWithoutNewingADelegateObject>b___________ 0(
Object obj) {
Console.WriteLine(obj);
}
}
Лямбда-выражение должно соответствовать сигнатуре делегата WaitCallback: возвращать void и принимать параметр типа Object. Впрочем, я указал имя пара
метра, просто поместив переменную obj слева от оператора =>. Расположенный справа от этого оператора метод Console.WriteLine действительно возвращает void. Если бы расположенное справа выражение не возвращало void, сгенерированный компилятором код просто проигнорировал бы возвращенное значение, ведь в противном случае не удалось бы соблюсти требования делегата WaitCallback.
Также следует отметить, что анонимная функция помечается как private; в итоге доступ к методу остается только у кода, определенного внутри этого же типа (хотя отражение позволит узнать о существовании метода). Обратите внимание, что анонимный метод определен как статический. Это связано с отсутствием у кода доступа к каким-либо членам экземпляра (ведь метод CallbackWithoutNewingADe legateObject сам по себе статический). Впрочем, код может обращаться к любым определенным в классе статическим полям или методам. Например:
internal sealed class AClass {
private static String smname; // Статическое поле
public static void CallbackWithoutNewingADelegateObject() { ThreadPool.QueuellserWorkItem(
// Код обратного вызова может обращаться к статическим членам obj =>Console.WriteLine(sm_name+ " + obj),
5);
}
}
Не будь метод CallbackWithoutNewingADelegateObject статическим, код анонимного метода мог бы содержать ссылки на члены экземпляра. Но даже при отсутствии таких ссылок компилятор все равно генерирует статический анонимный метод, так как он эффективнее экземплярного метода, потому что ему не нужен дополнительный параметр this. Если же в коде анонимного метода наличествуют ссылки на члены экземпляра, компилятор создает нестатический анонимный метод:
internal sealed class AClass {
private String m_name; // Поле экземпляра
// Метод экземпляра
public void CallbackWithoutNewingADelegateObject() {
ThreadPool.QueueUserWorkItem(
// Код обратного вызова может ссылаться на члены экземпляра obj => Console.WriteLine(m_name+ " + obj),
5);
>
}
Имена аргументов, которые следует передать лямбда-выражению, указываются слева от оператора =>. При этом следует придерживаться правил, которые мы рассмотрим на примерах:
// Если делегат не содержит аргументов, используйте круглые скобки Func<String> f = () => "Heff";
// Для делегатов с одним и более аргументами
// можно в явном виде указать типы
Func<Int32, String) f2 = (Int32 n) => n.ToString();
Func<Int32, Int32, String) f3 =
(Int32 nl, Int32 n2) => (nl + n2).ToString();
// Компилятор может самостоятельно определить типы для делегатов
// с одним и более аргументами
Func<Int32, String) f4 = (n) => n.ToString();
Func<Int32, Int32, String) f5 = (nl, n2) => (nl + n2).ToString();
// Если аргумент у делегата всего один, круглые скобки можно опустить Func<Int32, String) f6 = n => n.ToString();
II Для аргументов ref/out нужно в явном виде указывать ref/out и тип Bar b = (out Int32 n) => n = 5;
Предположим, что в последнем случае делегат Ваг определен следующим образом:
delegate void Bar(out Int32 z);
Тело анонимной функции записывается справа от оператора =>. Оно обычно представляет собой простое или сложное выражение, возвращающее некое значение. В рассмотренном примере это было лямбда-выражение, возвращающее строки всем переменным делегата Func. Чаще всего тело анонимной функции состоит из одной инструкции. К примеру, вызванному методу ThreadPool .QueueUserWorkltem было передано лямбда-выражение, что привело к вызову метода Console.WriteLine (возвращающего значение типа void).
Чтобы вставить в тело функции несколько инструкций, заключите их в фигурные скобки. Если делегат ожидает получить возвращаемое значение, не забудьте инструкцию return, как показано в следующем примере:
Func<Int32, Int32, String) f7 = (nl, n2) => {
Int32 sum = nl + n2j return sum.ToString(); };
ВНИМАНИЕ
Хотя это и не кажется очевидным, основная выгода от использования лямбда- выражений состоит в том, что они снижают уровень неопределенности вашего кода. Обычно приходится писать отдельный метод, присваивать ему имя и передавать это имя методу, в котором требуется делегат. Именно имя позволяет ссылаться на фрагмент кода. И если ссылка на один и тот же фрагмент требуется в различных местах программы, создание метода — это самое правильное решение. Если же обращение к фрагменту кода предполагается всего одно, на помощь приходят лямбда-выражения. Именно они позволяют встраивать фрагменты кода в нужное место, избавляя от необходимости их именования и повышая тем самым продуктивность работы программиста.
ПРИМЕЧАНИЕ
Механизм анонимных методов впервые появился в C# 2.0. Подобно лямбда- выражениям (появившимся в C# 3.0), анонимные методы описывают синтаксис создания анонимных функций. Рекомендуется использовать лямбда-выражения вместо анонимных методов, так как их синтаксис более компактен, что упрощает чтение кода. Разумеется, компилятор до сих пор поддерживаетанонимные функции, так что необходимости вносить исправления в код, написанный на C# 2.0, нет. Тем не менее в этой книге рассматривается только синтаксис лямбда-выражений.
Упрощение 3: не создаем обертку для локальных переменных для передачи их методу обратного вызова
Вы уже видели, что код обратного вызова может ссылаться на другие члены класса. Но иногда бывает нужно обратиться из этого кода к локальному параметру или переменной внутри определяемого метода. Вот интересный пример:
internal sealed class AClass {
public static void UsingLocalVariablesInTheCallbackCode(Int32 numToDo) {
// Локальные переменные
Int32[] squares = new Int32[numToDo];
AutoResetEvent done = new AutoResetEvent(false);
11 Выполнение задач в других потоках
for (Int32 n = 0; n < squares.Length; n++) {
ThreadPool.QueueUserWorkItem( obj => {
Int32 num = (Int32) obj;
// Обычно решение этой задачи требует больше времени squares[num] = num * num;
// Если это последняя задача, продолжаем выполнять главный поток if (Interlocked.Decrement(ref numToDo) == 0) done.SetQ;
b
n);
}
// Ожидаем завершения остальных потоков done.WaitOneQ;
// Вывод результатов
for (Int32 n = 0; n < squares.Length; n++)
Console.WriteLine("Index {0}, Square={l}", n, squares[n]);
}
}
Этот пример демонстрирует, насколько легко в C# реализуются задачи, считавшиеся достаточно сложными. В представленном здесь методе определен един-
ственный параметр numToDo и две локальные переменные squares и done. Ссылки на эти переменные присутствуют в теле лямбда-выражения.
А теперь представим, что код из лямбда-выражения помещен в отдельный метод (как того требует CLR). Каким образом передать туда значения переменных? Для этого потребуется вспомогательный класс, определяющий поле для каждого значения, которое требуется передать в код обратного вызова. Кроме того, этот код следует определить во вспомогательном классе как экземплярный метод. Тогда метод UsingLocalVariablesInTheCallbackCode создаст экземпляр вспомогательного класса, присвоит полям значения локальных переменных и, наконец, создаст объект делегата, связанный с вспомогательным классом и экземплярным методом.
ПРИМЕЧАНИЕ
Когда лямбда-выражение заставляет компилятор генерировать класс с превращенными в поля параметрами/локальными переменными, увеличивается время жизни объекта, на который ссылаются эти переменные. Обычно параметры/локальные переменные уничтожаются после завершения метода, в котором они используются. В данном же случае они остаются, пока не будет уничтожен объект, содержащий поле. В большинстве приложений это не имеет особого значения, тем не менее этот факт следует знать.
Это нудная и чреватая ошибками работа, и разумеется, компилятор лучше выполнит ее за вас. Приведенный код он перепишет примерно так (комментарии мои):
internal sealed class AClass {
public static void UsingLocalVariablesInTheCallbackCode(Int32 numToDo) {
// Локальные переменные WaitCallback callbackl = null;
// Создание экземпляра вспомогательного класса Ос DisplayClass2 classl = new ос DisplayClass2();
// Инициализация полей вспомогательного класса classl.numToDo = numToDo;
classl.squares = new Int32[classl.numToDo]; classl.done = new AutoResetEvent(false);
// Выполнение задач в других потоках for (Int32 n = в; n < classl.squares.Length; n++) { if (callbackl == null) {
// Новый делегат привязывается к объекту вспомогательного класса // и его анонимному экземплярному методу callbackl = new WaitCallback(
classl.<UsingLocalVariablesInTheCallbackCode>b_________ 0);
}
ThreadPool.QueueUserl/\lorkItem( callbackl, n);
// Ожидание завершения остальных потоков classl. done. WaitOneQ;
// Вывод результатов
for (Int32 n = 0; n < classl.squares.Length; n++)
Console.WriteLine("Index {0}, Square={l}“, n, classl.squares[n]);
}
// Вспомогательному классу присваивается необычное имя, чтобы // избежать конфликтов и предотвратить доступ из класса AClass [CompilerGenerated]
private sealed class <>c_____ DisplayClass2 : Object {
// В коде обратного вызова для каждой локальной переменной
// используется одно открытое поле
public Int32[] squares;
public Int32 numToDo;
public AutoResetEvent done;
// Открытый конструктор без параметров public ос DisplayClass2 { }
// Открытый экземплярный метод с кодом обратного вызова
public void <UsingLocalVariablesInTheCallbackCode>b__________ ©(Object obj) {
Int32 num = (Int32) obj; squares[num] = num * num;
if (Interlocked.Decrement(ref numToDo) == 0) done.Set();
}
}
ВНИМАНИЕ
Без сомнения, у любого программиста возникает соблазн использовать лямбда- выражения там, где это уместно и не уместно. Лично я привык к ним не сразу. Ведь код, который вы пишете внутри метода, на самом деле этому методу не принадлежит, что затрудняет отладку и пошаговое выполнение. Хотя я был откровенно поражен тем, что отладчик Visual Studio позволял выполнять лямбда-выражения в моем исходном коде в пошаговом режиме.
Я установил для себя правило: если в методе обратного вызова предполагается более трех строк кода, не использовать лямбда-выражения. Вместо этого я пишу метод вручную и присваиваю ему имя. Впрочем, при разумном подходе лямбда-выражения способны серьезно повысить продуктивность работы программиста и упростить поддержку кода. В следующем примере кода лямбда-выражения смотрятся естественно, и без них написание, чтение и редактирование кода было бы намного сложнее:
// Создание и инициализация массива String
String[] names = { "3eff", "Kristin", "Aidan", "Grant" };
// Извлечение имен со строчной буквой 'а'
Char charToFind = 'а';
names = Array.FindAll(names, name => name.IndexOf(charToFind) >= 0);
// Преобразование всех символов строки в верхний регистр names = Array.ConvertAll(names, name => name.ToUpper());
// Вывод результатов
Array.ForEach(names, Console.WriteLine);
Делегаты и отражение
Все показанные в этой главе примеры использования делегатов требовали, чтобы разработчик заранее знал прототип метода обратного вызова. Скажем, если переменная fb ссылается на делегата Feedback (см. листинг первого примера в этой главе), код обращения к делегату мог бы выглядеть примерно так:
fb(item); // параметр item определен как Int32
Как видите, разработчик должен знать количество и тип параметров метода обратного вызова. К счастью, эта информация почти всегда доступна разработчику, так что написать подобный этому код — не проблема.
Впрочем, в отдельных редких ситуациях на момент компиляции эти сведения отсутствуют. В главе 11 при обсуждении типа EventSet приводился соответствующий пример со словарем, хранящим набор разных типов делегатов. Для вызова события во время выполнения производился поиск и вызов делегата из словаря. Однако при этом было невозможно узнать во время компиляции, какой делегат будет вызван и какие параметры следует передать его методу обратного вызова.
К счастью, в классе System. Reflection .Methodlnfo имеется метод Create- Delegate, позволяющий создавать и вызывать делегаты даже при отсутствии сведений о них на момент компиляции. Вот как выглядят перегруженные версии этого метода:
public abstract class Methodlnfo : MethodBase {
// Создание делегата, служащего оберткой статического метода, public virtual Delegate CreateDelegate(Type delegateType);
11 Создание делегата, служащего оберткой экземплярного метода;
// target ссылается на аргумент 'this', public virtual Delegate CreateDelegate(Type delegateType, Object target);
}
После того как делегат будет создан, его можно вызвать методом Dynamiclnvoke класса Delegate, который выглядит примерно так:
public abstract class Delegate {
// Вызов делегата с передачей параметров
public Object DynamicInvoke(params ObJect[] args);
При использовании API отражения (см. главу 23) необходимо сначала получить объект Methodlnfo для метода, для которого требуется создать делегата. Затем вызов метода CreateDelegate создает новый объект типа, производного от Delegate и определяемого первым параметром delegateType. Если делегат представляет экземплярный метод, также следует передать CreateDelegate параметр target, обозначающий объект, который должен передаваться экземплярному методу как параметр this.
Метод Dynamiclnvoke класса System.Delegate позволяет задействовать метод обратного вызова делегата, передавая набор параметров, определяемых во время выполнения. При вызове метода Dynamiclnvoke проверяется совместимость переданных параметров с параметрами, ожидаемыми методом обратного вызова. Если параметры совместимы, выполняется обратный вызов; в противном случае генерируется исключение ArgumentException. Данный метод возвращает объект, который был возвращен методом обратного вызова.
Рассмотрим пример применения методов CreateDelegate и Dynamiclnvoke:
using System;
using System.Reflection;
using System.10;
// Несколько разных определений делегатов
internal delegate Object TwoInt32s(Int32 nl, Int32 n2);
internal delegate Object OneString(String si);
public static class DelegateReflection { public static void Main(String[] args) { if (args.Length < 2) {
String usage =
@"Usage:“ +
"{0} delType methodName [Argl] [Arg2]“ +
"{0} where delType must be TwoInt32s or OneString" +
"{0} if delType is TwoInt32s, methodName must be Add or Subtract" +
"{0} if delType is OneString, methodName must be NumChars or Reverse"
+
"{0}" +
"{0}Examples:" +
"{0} TwoInt32s Add 123 321" +
"{0} TwoInt32s Subtract 123 321" +
"{0} OneString NumChars V'Hello thereV" +
"{0} OneString Reverse V'Hello thereY"';
Console.WriteLine(usage, Environment.NewLine); return;
}
// Преобразование аргумента delType в тип делегата Type delType = Type.GetType(args[0]); if (delType == null) {
Console.WriteLine("Invalid delType argument: " + args[0]);
return;
}
Delegate d; try {
// Преобразование аргумента Argl в метод Methodlnfo ml =
typeof(DelegateReflection). GetTypelnfoQ.GetDeclaredMethod(args[l])
// Создание делегата, служащего оберткой статического метода d = mi.CreateDelegate(delType);
}
catch (ArgumentException) {
Console.WriteLine("Invalid methodName argument: " + args[l]); return;
}
// Создание массива, содержащего аргументы,
// передаваемые методу через делегат
Object[] callbackArgs = new Object[args.Length 2];
If (d.GetType() == typeof(TwoInt32s)) { try {
// Преобразование аргументов типа String в тип Int32 for (Int32 a = 2; a < args.Length; a++)
callbackArgs[a 2] = Int32.Parse(args[a]);
}
catch (FormatException) {
Console.WrlteLine("Parameters must be integers."); return;
}
}
if (d.GetTypeQ == typeof(OneString)) {
// Простое копирование аргумента типа String
Array.Copy(args, 2, callbackArgs, 0, callbackArgs.Length);
}
try {
// Вызов делегата и вывод результата
Object result = d.DynamicInvoke(callbackArgs);
Console.WriteLine("Result = " + result);
}
catch (TargetParameterCountException) {
Console.WriteLine("Incorrect number of parameters specified.");
}
// Метод обратного вызова, принимающий два аргумента типа Int32 private static Object Add(Int32 nl, Int32 n2) { return nl + n2;
>
// Метод обратного вызова, принимающий два аргумента типа Int32 private static Object Subtract(Int32 nl, Int32 n2) { return nl n2;
}
// Метод обратного вызова, принимающий один аргумент типа String private static Object NumChars(String si) { return si.Length;
}
// Метод обратного вызова, принимающий один аргумент типа String private static Object Reverse(String si) { return new String(sl.ReverseQ.ToArrayO) 1
}
Глава 18. Настраиваемые атрибуты
В этой главе описывается один из самых новаторских механизмов Microsoft .NET Framework — механизм настраиваемых атрибутов (custom attributes). Именно настраиваемые атрибуты позволяют снабжать кодовые конструкции декларативными аннотациями, наделяя код особыми возможностями. Настраиваемые атрибуты дают возможность задать информацию, применимую практически к любой записи таблицы метаданных. Информацию об этих расширяемых метаданных можно запрашивать во время выполнения с целью динамического изменения хода выполнения программы. Настраиваемые атрибуты применяются в различных технологиях .NET Framework (Windows Forms, WPF, WCF и т. п.), что позволяет разработчикам легко выражать свои намерения в коде. Таким образом, умение работать с настраиваемыми атрибутами необходимо всем разработчикам .NET Framework.
Сфера применения настраиваемых атрибутов
Атрибуты public, private, static и им подобные применяются как к типам, так и к членам типов. Никто не станет спорить с тем, что атрибуты полезны — но как насчет возможности задания собственных атрибутов? Предположим, нужно не просто определить тип, но и каким-либо образом указать на возможность его удаленного использования посредством сериализации. Или, к примеру, назначить методу атрибут, который означает, что для выполнения метода должны быть получены некоторые разрешения безопасности.
Разумеется, создавать настраиваемые атрибуты и применять их к типам и методам очень удобно, однако для этого компилятор должен распознавать эти атрибуты и заносить соответствующую информацию в метаданные. Фирмы-разработчики предпочитают не публиковать исходный код своих компиляторов, поэтому специалисты Microsoft предложили альтернативный способ работы с настраиваемыми атрибутами, которые представляют собой мощный механизм, полезный как при разработке, так и при выполнении приложений. Определять и задействовать настраиваемые атрибуты может кто угодно, а все CLR-совместимые компиляторы должны их распознавать и генерировать соответствующие метаданные.
Следует понимать, что настраиваемые атрибуты представляют собой лишь средство передачи некой дополнительной информации. Компилятор помещает эту информацию в метаданные управляемого модуля. Большая часть атрибутов для компилятора просто не имеет значения; он обнаруживает их в исходном коде и создает для них соответствующие метаданные.
Библиотека классов .NET Framework (FCL) включает определения сотен настраиваемых атрибутов, которые вы можете использовать в своем коде. Вот несколько примеров:
□ Атрибут Dlllmport при применении к методу информирует CFR о том, что метод реализован в неуправляемом коде указанной DFF-библиотеки.
□ Атрибут Serializable при применении к типу информирует механизмы сериализации о том, что экземплярные поля доступны для сериализации и десериализации.