
□ Частичные методы могут объявляться только внутри частичного класса или структуры.








□ Частичные методы должны всегда иметь возвращаемый тип void и не могут иметь параметров, помеченных ключевым словом out. Эти ограничения связаны с тем, что во время выполнения программы метода не существует, и вы не можете инициализировать переменную, возвращаемую методом, потому что этого метода не существует. По той же причине нельзя использовать параметр, помеченный словом out, потому что иначе метод должен будет инициализировать этот параметр, но этого метода не существует. Частичный метод может иметь параметры, помеченные ключевым словом ref, а также универсальные параметры, экзем- плярные или статические, или даже параметры, помеченные как unsafe.
□ Естественно, определяющее объявление частичного метода и его реализующее объявление должны иметь идентичные сигнатуры. И оба должны иметь настраивающиеся атрибуты, применяющиеся к ним, когда компилятор объединяет атрибуты обоих методов вместе. Все атрибуты, применяемые к параметрам, тоже объединяются.
□ Если не существует реализующего объявления частичного метода, в вашем коде не может быть попыток создания делегата, ссылающегося на частичный метод. Это причина, по которой метод не существует во время выполнения программы. Компилятор выдаст следующее сообщение (ошибка CS0762: не могу создать делегата из метода ' Base .OnNameChanging( string)', потому что это частичный метод без реализующего объявления):
"error CS0762: Cannot create delegate from method
'Base.OnNameChanging(string)' because it is a partial method without an implementing declaration
□ Хотя частичные методы всегда считаются закрытыми, компилятор C# запрещает писать ключевое слово private перед объявлением частичного метода.
Глава 9. Параметры
В этой главе рассмотрены различные способы передачи параметров в метод. В числе прочего вы узнаете, как определить необязательный параметр, задать параметр по имени и передать его по ссылке. Также рассмотрена процедура определения методов, принимающих различное количество аргументов.
Необязательные и именованные параметры[9]
При выборе параметров метода некоторым из них (и даже всем) можно присваивать значения по умолчанию. В результате в вызывающем такой метод коде можно не указывать эти аргументы, а принимать уже имеющиеся значения. Кроме того, при вызове метода существует возможность указать аргументы, воспользовавшись именами их параметров. Следующий код демонстрирует применение как необязательных, так и именованных параметров:
public static class Program { private static Int32 s_n = 0;
private static void M(Int32 x = 9, String s = "A",
DateTime dt = default(DateTime), Guidguid = new Guid()) {
Console.Writel_ine("x={0}, s={l}, dt={2}, guid={3}“, x, s, dt, guid);
}
public static void Main() {
// 1. Аналогично: M(9, "A", default(DateTime), new Guid());
M();
// 2. Аналогично: M(8, "X", default(DateTime), new Guid());
M(8, "X");
// 3. Аналогично: M(5, "A", DateTime.Now, Guid.NewGuidQ);
M(5, guid: Guid.NewGuid(), dt: DateTime.Now);
11 4. Аналогично: M(0, "1", default(DateTime), new Guid());
M(s_n++, s_n++.ToString());
// 5. Аналогично: String tl = "2"; Int32 t2 = 3;
// M(t2, tl, default(DateTime), new Guid());
M(s: (s_n++).ToString(), x: s_n++);
}
При выполнении этого кода выводится следующий результат:
х=9, s=A, dt=l/l/0001 12:00:00 AM, guid=00000000-0000-0000-0000-000000000000 x=8, s=X, dt=l/l/0001 12:00:00 AM, guid=00000000-0000-0000-0000-000000000000
продолжение &
х=5, s=Aj dt=8/16/2012 10:14:25 PM, guld=d24a59da-6009-4aae-9295-839155811309 х=0, s=l, dt=l/l/0001 12:00:00 AM, guld=00000000-0000-0000-0000-000000000000 x=3, s=2, dt=l/l/0001 12:00:00 AFT guid=00000000-0000-0000-0000-000000000000
Как видите, в случае если при вызове метода аргументы отсутствуют, компилятор берет их значения, предлагаемые по умолчанию. В третьем и пятом вызовах метода М заданы именованные параметры (named parameter). Я в явном виде передал значение переменной х и указал, что хочу передать аргумент для параметров guid и dt.
Передаваемые в метод аргументы компилятор рассматривает слева направо. В четвертом вызове метода М значение аргумента s_n (0) передается в переменную х, затем s_n увеличивается на единицу и аргумент s_n (1) передается как строка в параметр s. После чего s_n увеличивается до 2. Передача аргументов с помощью именованных параметров опять же осуществляется компилятором слева направо. В пятом вызове метода М значение параметра s_n (2) преобразуется в строку и сохраняется в созданной компилятором временной переменной (tl). Затем s_n увеличивается до 3, и это значение сохраняется в еще одной созданной компилятором временной переменной (t2). После этого s_n увеличивается до 4. В конце концов, вызывается метод М, в который передаются переменные t2, tl, переменная DateTime со значением по умолчанию и новое значение Guid.
Правила использования параметров
Определяя метод, задающий для части своих параметров значения по умолчанию, следует руководствоваться следующими правилами:
□ Значения по умолчанию указываются для параметров методов, конструкторов методов и параметрических свойств (индексаторов С#). Также их можно указывать для параметров, являющихся частью определения делегатов. В результате при вызове этого типа делегата аргументы можно опускать, используя их значения по умолчанию.
□ Параметры со значениями по умолчанию должны следовать за всеми остальными параметрами. Другими словами, если указан параметр со значением по умолчанию, значения по умолчанию должны иметь и все параметры, расположенные справа от него. Например, если при определении методам удалить значение по умолчанию ("А") для параметра s, компилятор выдаст сообщение об ошибке. Существует только одно исключение из правил — параметр массива, помеченный ключевым словом params (о котором мы подробно поговорим чуть позже). Он должен располагаться после всех прочих параметров, в том числе имеющих значение по умолчанию. При этом сам массив значения по умолчанию иметь не может.
□ Во время компиляции значения по умолчанию должны оставаться неизменными. То есть задавать значения по умолчанию можно для параметров примитивных типов, перечисленных в табл. 5.1 главы 5. Сюда относятся также перечислимые типы и ссылочные типы, допускающие присвоение значения null. Для параметров произвольного значимого типа значение по умолчанию задается как экземпляр этого типа с полями, содержащими нули. Можно использовать как ключевое слово default, так и ключевое слово new, в обоих случаях генерируется одинаковый IL-код. С примерами обоих вариантов синтаксиса мы уже встречались в методе М при задании значений по умолчанию для параметров dt и guid соответственно.
□ Запрещается переименовывать параметрические переменные, так как это влечет за собой необходимость редактирования вызывающего кода, который передает аргументы по имени параметра. Скажем, если в объявлении метода М переименовать переменную dt в dateTime, то третий вызов метода станет причиной появления следующего сообщения компилятора (ошибка CS1739: в подходящей перегруженной версии ' М' отсутствует параметр с именем ' dt'):
"error CS1739: The best overload for 'M' does not have a parameter named 'dt'
□ При вызове метода извне модуля изменение значения параметров по умолчанию является потенциально опасным. Вызывающая сторона использует значение по умолчанию в процессе работы. Если изменить его и не перекомпилировать код, содержащий вызов, в вызываемый метод будет передано прежнее значение. В качестве индикатора поведения можно использовать значение по умолчанию О или null. В результате исчезает необходимость повторной компиляции кода вызывающей стороны. Вот пример:
// Не делайте так:
private static String MakePath(String filename = "Untitled") { return String.Format(@"C:\{0}.txt", filename);
}
// Используйте следующее решение:
private static String MakePath(String filename = null) {
// Здесь применяется оператор, поддерживающий // значение null (??); см. главу 19
return String. Format((йпС: \{0}.txt", filename ?? "Untitled");
}
□ Для параметров, помеченных ключевыми словами ref или out, значения по умолчанию не задаются.
Существуют также дополнительные правила вызова методов с использованием
необязательных или именованных параметров:
□ Аргументы можно передавать в произвольном порядке; но именованные аргументы должны находиться в конце списка.
□ Передача аргумента по имени возможна для параметров, не имеющих значения по умолчанию, но при этом компилятору должны быть переданы все аргументы, необходимые для компиляции (с указанием их позиции или имени).
□ В C# между запятыми не могут отсутствовать аргументы. Иначе говоря, запись M(l, ,DateTime .Now) недопустима, так как ведет к нечитабельному коду. Чтобы опустить аргумент для параметра со значением по умолчанию, передавайте аргументы по именам параметров.
□ Вот как передать аргумент по имени параметра, требующего ключевого слова ref/out:
// Объявление метода:
private static void M(ref Int32 x) { ... } // Вызов метода:
Int32 a = 5;
M(x: ref a);
ПРИМЕЧАНИЕ
Синтаксис необязательных и именованных параметров в C# весьма удобен при написании кода, поддерживающего объектную модель СОМ из Microsoft Office. При вызове COM-компонентов C# позволяет опускать ключевые слова ref/out в процессе передачи аргументов по ссылке. Это еще больше упрощает код. Если же COM-компонент не вызывается, наличие рядом с аргументом ключевого слова ref/out обязательно.
Атрибут DefaultParameterValue и необязательные атрибуты
Хотелось бы, чтобы концепция заданных по умолчанию и необязательных аргументов выходила за пределы С#. Особенно здорово было бы, если бы программисты могли определять методы, указывающие, какие параметры являются необязательными и каковы должны быть заданные по умолчанию значения параметров в разных языках программирования, дав попутно возможность вызывать их из разных языковых сред. Но такое возможно только при условии, что выбранный компилятор позволяет при вызове опускать некоторые аргументы, а также умеет определять заданные по умолчанию значения этих аргументов.
В C# параметрам со значением по умолчанию назначается настраиваемый атрибут System.Runtime.InteropServices.OptionalAttribute, сохраняющийся в метаданных итогового файла. Кроме того, компилятор применяет к параметру атрибут System.Runtime.InteropServices.DefaultParameterValueAttribute, опять же сохраняя его в метаданных итогового файла. После чего конструктору DefaultParameterValueAttribute передаются постоянные значения, указанные в первоначальном коде.
В итоге встречая код, вызывающий метод, в котором не хватает аргументов, компилятор проверяет, являются ли эти аргументы необязательными, берет их значения из метаданных и автоматически вставляет в вызов метода.
Неявно типизированные локальные переменные
В C# поддерживается возможность определения типа используемых в методе локальных переменных по типу используемого при их инициализации выражения:
private static void ImplicitlyTypedLocalVariables() { var name = "3eff";
ShowVariableType(name); // Вывод: System.String
// var n = null; // Ошибка
var x = (String)null; // Допустимо, хотя и бесполезно
ShowVariableType(x); // Вывод: System.String
var numbers = new Int32[] { 1, 2, 3, 4 };
ShowVariableType(numbers); // Вывод: System.Int32[]
// Меньше символов при вводе сложных типов
var collection = new DictionarycString, Single>() { { "Grant", 4.0f } };
// Вывод: System.Collections.Generic.Dictionary'2[System.String,System.Single] ShowVariableType(collection); foreach (var item in collection) {
// Вывод: System.Collections.Generic.KeyValuePair'2 [System.String,System.Single]
ShowVariableType(item);
}
}
private static void ShowVariableType<T>(T t) {
Console.WriteLine(typeof(T));
}
Первая строка кода метода ImplicitlyTypedLocalVariables вводит новую локальную переменную при помощи ключевого слова var. Чтобы определить ее тип, компилятор смотрит на тип выражения с правой стороны от оператора присваивания (=). Так как "leff" — это строка, компилятор присваивает переменной name тип St ring. Чтобы доказать, что компилятор правильно определяет тип, я написал универсальный метод ShowVariableType. Он определяет тип своего аргумента и выводит его на консоль. Для простоты чтения выводимые методом ShowVariableType значения я добавил в виде комментариев внутрь метода ImplicitlyTypedLocalVariables.
Вторая операция присваивания (закомментированная) в методе ImplicitlyTypedLocalVariables во время компиляции привела бы к ошибке (ошибка CS0815: невозможно присвоить значение null локальной переменной с неявно заданным типом):
error CS0815: Cannot assign <null> to an implicitly-typed local variable
Дело в том, что значение null неявно приводится к любому ссылочному типу или значимому типу, допускающему значение null. Соответственно, компилятор не в состоянии однозначно определить его тип. Однако в третьей операции присваивания я показал, что инициализировать локальную переменную с неявно заданным типом значением null все-таки можно, если в явном виде указать тип (в моем примере это тип String). Впрочем, это не самая полезная возможность, так как, написав String х = null;, вы получите тот же самый результат.
В четвертом примере в полной мере демонстрируется полезность локальных переменных неявно заданного типа. Ведь без этой возможности вам бы потребовалось с обеих сторон от оператора присваивания писать Dictionary<String, Singlex Это не просто увеличивает объем набираемого текста, но и заставляет редактировать код с обеих сторон от оператора присваивания в случае;, если вы решите поменять тип коллекции или любой из типов обобщенных параметров.
В цикле foreach я также воспользовался ключевым словом var, заставив компилятор автоматически определить тип элементов коллекции. Этот пример демонстрирует пользу ключевого слова var внутри инструкций foreach, using и for. Кроме того, оно полезно в процессе экспериментов с кодом. К примеру, вы инициализируете локальную переменную с неявно заданным типом, взяв за основу тип возвращаемого методом значения. Но в будущем может появиться необходимость поменять тип возвращаемого значения. В этом случае компилятор автоматически определит, что тип возвращаемого методом значения изменился, и изменит тип локальной переменной! К сожалению, остальной код внутри метода, работающий с этой переменной, может перестать компилироваться — если этот код обращается к членам в предположении, что переменная принадлежит к старому типу.
В Microsoft Visual Studio при наведении указателя мыши на ключевое слово var появляется всплывающая подсказка с названием типа, определяемого компилятором. Функцию неявного задания типа локальных переменных в C# следует задействовать при работе с методами, использующими анонимные типы. Они подробно рассматривают в главе 10.
Тип параметра метода при помощи ключевого слова var объявлять нельзя. Ведь компилятор будет определять его, исходя из типа аргументов, передаваемых при вызове метода. Вызова же может вообще не быть или же, наоборот, их может быть несколько. Аналогично, нельзя объявлять при помощи этого ключевого слова тип поля. Для такого ограничения в C# существует множество причин. Одна из них — возможность обращения к полю из нескольких методов. Группа проектирования C# считает, что контракт (тип переменной) должен быть указан явно. Второй причиной является тот факт, что в данном случае анонимные типы (обсуждаемые в главе 10) начнут выходить за границы одного метода.
ВНИМАНИЕ
Не путайте ключевые слова dynamic и var. Объявление локальной переменной с ключевым слово var является не более чем синтаксическим сокращением, заставляющим компилятор определить тип данных по выражению. Данное ключевое слово служит только для объявления локальных переменных внутри метода, в то время как ключевое слово dynamic используется для локальных переменных, полей и аргументов. Невозможно привести выражение к типу var, но такая операция вполне допустима для типа dynamic. Переменные, объявленные с ключевым словом var, должны инициализироваться явно, что не обязательно для переменных типа dynamic. Более подробную информацию о динамическом типе вы найдете в главе 5.
Передача параметров в метод по ссылке
По умолчанию CLR предполагает, что все параметры методов передаются по значению. При передаче объекта ссылочного типа методу передается ссылка (или указатель) на этот объект. То есть метод может изменить переданный объект, влияя на состояние вызывающего кода. Если параметром является экземпляр значимого типа, методу передается его копия. В этом случае метод получает собственную копию объекта, а исходный экземпляр сохраняется неизменным.
ВНИМАНИЕ
Следует знать тип каждого объекта, передаваемого методу в качестве параметра, поскольку манипулирующий параметрами код может существенно различаться в зависимости от типа параметров.
CLR также позволяет передавать параметры по ссылке, а не по значению. В C# это делается с помощью ключевых слов out и ref. Оба заставляют компилятор генерировать метаданные, описывающие параметр как переданный по ссылке. Компилятор использует эти метаданные для генерирования кода, передающего вместо самого параметра его адрес,
С точки зрения CLR, ключевые слова out и ref не различаются, то есть для них генерируются одинаковый IL-код, а метаданные отличаются всего одним битом, указывающим, какое ключевое слово было использовано при объявлении метода. Однако компилятор C# различает эти ключевые слова при выборе метода, используемого для инициализации объекта, на который указывает переданная ссылка. Если параметр метода помечен ключевым словом out, вызывающий код может не инициализировать его, пока не вызван сам метод. В этом случае вызванный метод не может прочитать значение параметра и должен записать его, прежде чем вернуть управление. Если же параметр помечен ключевым словом ref, вызывающий код должен инициализировать его перед вызовом метода, а вызванный метод может как читать, так и записывать значение параметра.
Поведение ссылочных и значимых типов при использовании ключевых слов out и ref различается значительно. Вот как это выглядит в случае значимого типа:
public sealed class Program { public static void Main() {
Int32 x; П Инициализация x
GetVal(out x); 11 Инициализация x не обязательна
Console.WriteLine(x); // Выводится 10
}
private static void GetVal(out Int32 v) {
v = 10; // Этот метод должен инициализировать переменную V
}
}
Здесь переменная х объявлена в стеке Main, а ее адрес передается методу GetVal. Параметр этого метода v представляет собой указатель на значимый тип Int32. Внутри метода GetVal значение типа Int32, на которое указывает V, изменяется на 10. Именно это значение выводится на консоль, когда метод GetVal возвращает управление. Использование ключевого слова out со значимыми типами повышает эффективность кода, так как предотвращает копирование экземплярных полей значимого типа при вызовах методов.
А теперь рассмотрим аналогичный пример с ключевым словом ref:
public sealed class Program { public static void Main() {
Int32 x = 5; // Инициализация x
AddVal(ref x)j // x требуется инициализировать
Console.WriteLine(x); // Выводится 15
>
private static void AddVal(ref Int32 v) {
v += 10; // Этот метод может использовать инициализированный параметр v
>
Здесь объявленной в стеке Main переменной х присваивается начальное значение 5. Затем ее адрес передается методу AddVal, параметр v которого представляет собой указатель на значимый тип Int32 в стеке Main. Внутри метода AddVal должно быть уже инициализированное значение типа Int32, на которое указывает параметр V. Таким образом, метод AddVal может использовать первоначальное значение v в любом выражении. Он может менять это значение, возвращая вызывающему коду новый вариант. В рассматриваемом примере метод AddVal прибавляет к исходному значению 10. Соответственно, когда он возвращает управление, переменная х метода Main содержит значение 15, которое и выводится на консоль.
В завершение отметим, что с точки зрения IL или CLR ключевые слова out и ref ничем не различаются: оба заставляют передать указатель на экземпляр объекта. Разница в том, что они помогают компилятору гарантировать корректность кода. В следующем коде попытка передать методу, ожидающему параметр ref, неинициализированное значение приводит к ошибке компиляции (ошибка CS0165: использование локальной переменной х, у которой не задано значение):
error CS0165: Use of unassigned local variable 'x'
А вот сам фрагмент кода, вызывающий это сообщение:
public sealed class Program { public static void Main() {
Int32 x; // x не инициализируется
// Следующая строка не компилируется, а выводится сообщение:
// error CS0165: Use of unassigned local variable 'x'
AddVal(ref x);
Console.WriteLine(x);
}
private static void AddVal(ref Int32 v) {
v += 10; // Этот метод может использовать инициализированный параметр v
}
ВНИМАНИЕ
Меня часто спрашивают, почему при вызовах методов в программах на C# надо в явном виде указывать ключевые слова out или ref. В конце концов, компилятор в состоянии самостоятельно определить, какое из ключевых слов ему требуется, азначит, должен корректно компилировать код. Однако разработчики C# сочли, что вызывающий код должен явно указывать свои намерения, чтобы при вызове метода сразу было ясно, что этот метод должен менять значение передаваемой переменной.
Кроме того, CLR позволяет по-разному перегружать методы в зависимости от выбора параметра out или ref. Например, следующий код на C# вполне допустим и прекрасно компилируется:
public sealed class Point {
static void Add(Point p) { ... } static void Add(ref Point p) { ... }
}
He допускается перегружать методы, отличающиеся только типом параметров (out или ref), так как результатом их JIT-компиляции становится идентичный код метаданных, представляющих сигнатуру методов. Поэтому в показанном ранее типе Point я не могу определить вот такой метод:
static void Add(out Point p) { ... }
При попытке включить такой метод в тип Point компилятор C# вернет ошибку (ошибка CS0663: в 'Add' нельзя определять перегруженных методов, отличных от ref и out):
error CS0663: 'Add' cannot define overloaded methods that differ only on ref and out
Со значимыми типами ключевые слова out и ref дают тот же результат, что и передача ссылочного типа по значению. Они позволяют методу управлять единственным экземпляром значимого типа. Вызывающий код должен выделить память для этого экземпляра, а вызванный метод управляет выделенной памятью. В случае ссылочных типов вызывающий код выделяет память для указателя на передаваемый объект, а вызванный код управляет этим указателем. В силу этих особенностей использование ключевых слов out и ref со ссылочными типами полезно, лишь когда метод собирается «вернуть» ссылку на известный ему объект. Рассмотрим это на примере:
using System; using System.10;
public sealed class Program { public static void Main() {
FileStream fs; // Объект fs не инициализирован
// Первый файл открывается для обработки
продолжение #
StartProcessingFiles(out fs);
// Продолжаем, пока остаются файлы для обработки for (; fs != null; ContinueProcessingFiles(ref fs)) {
// Обработка файла fs.Read(.. .);
}
private static void StartProcessingFiles(out FileStream fs) { fs = new FileStream(...); // в этом методе объект fs
// должен инициализироваться
}
private static void ContinueProcessingFiles(ref FileStream fs) { fs.Close(); // Закрытие последнего обрабатываемого файла
// Открыть следующий файл или вернуть null, если файлов больше нет if (noMoreFilesToProcess) fs = null; else fs = new FileStream (...);
}
Как видите, главная особенность этого кода в том, что методы с параметрами ссылочного типа, помеченными ключевыми словами out или ref, создают объект и возвращают вызывающему коду указатель на него. Обратите внимание, что метод ContinueProcessingFiles может управлять передаваемым ему объектом, прежде чем вернет новый объект. Это возможно благодаря тому, что его параметр помечен ключевым словом ref. Показанный здесь код можно немного упростить:
using System; using System.10;
public sealed class Program { public static void Main() {
FileStream fs = null; // Обязательное присвоение // начального значения null
// Открытие первого файла для обработки ProcessFiles(ref fs);
// Продолжаем, пока остаются необработанные файлы for (; fs != null; ProcessFiles(ref fs)) {
// Обработка файла fs.Read(...);
}
}
private static void ProcessFiles(ref FileStream fs) {
// Если предыдущий файл открыт, закрываем его
if (fs != null) fs.CloseQ; // Закрыть последний обрабатываемый файл
// Открыть следующий файл или вернуть null, если файлов больше нет if (noMoreFilesToProcess) fs = null; else fs = new FileStream (...);
}
Еще один пример, демонстрирующий использование ключевого слова ref для реализации метода, меняющего местами два ссылочных типа:
public static void Swap(ref Object a, ref Object b) {
Object t = b; b = a; a = t;
}
Кажется, что код, меняющий местами ссылки на два объекта типа String, должен выглядеть так:
public static void SomeMethod() {
String si = "Jeffrey";
String s2 = "Richter";
Swap(ref si, ref s2);
Console.WriteLine(sl); // Выводит "Richter"
Console.WriteLine(s2); // Выводит "Jeffrey"
}
Однако компилироваться этот код не будет: ведь переменные, передаваемые методу по ссылке, должны быть одного типа, объявленного в сигнатуре метода. Иначе говоря, метод Swap ожидает получить ссылки на тип Object, а не на тип String. Решение же нашей задачи выглядит следующим образом:
public static void SomeMethodQ {
String si = "Jeffrey";
String s2 = "Richter";
// Тип передаваемых по ссылке переменных должен // соответствовать ожидаемому Object ol = si, о2 = s2;
Swap(ref ol, ref o2);
// Приведение объектов к строковому типу si = (String) ol; s2 = (String) o2;
Console.WriteLine(sl); // Выводит "Richter"
Console.Writel_ine(s2); // Выводит "Jeffrey"
}
Такая версия метода SomeMethod будет компилироваться и работать нужным нам образом. Причиной ограничения, которое нам пришлось обходить, является обеспечение безопасности типов. Вот пример кода, нарушающего безопасность типов (к счастью, он не компилируется):
internal sealed class SomeType { public Int32 mval;
>
public sealed class Program { public static void Main() {
SomeType st;
// Следующая строка выдает ошибку CS1503: Argument '1':
// cannot convert from 'ref SomeType' to 'ref object'.
GetAnObject(out st);
Console. Write Line (st. nival);
}
private static void GetAnObject(out Object o) { о = new String('X', 100);
}
}
Совершенно ясно, что здесь метод Main ожидает от метода GetAnObject объект SomeType. Однако поскольку в сигнатуре GetAnObject задана ссылка на Object, метод GetAnObject может инициализировать параметр о объектом произвольного типа. В этом примере параметр st в момент, когда метод GetAnObject возвращает управление методу Main, ссылается на объект типа String, в то время как ожидается тип SomeType. Соответственно, вызов метода Console .WriteLine закончится неудачей. Впрочем, компилятор C# откажется компилировать этот код, так как st представляет собой ссылку на объект типа SomeType, тогда как метод GetAnObject требует ссылку на Object.
Однако, как оказалось, эти методы можно заставить работать при помощи обобщений. Вот так следует исправить показанный ранее метод Swap:
public static void Swap<T>(ref T a, ref T b) {
T t = b; b = a; a = t;
}
После этого следующий код (идентичный ранее показанному) будет без проблем компилироваться и выполняться:
public static void SomeMethod() {
String si = "Jeffrey";
String s2 = "Richter";
Swap(ref si, ref s2);
Console.WriteLine(sl); // Выводит "Richter"
Console.WriteLine(s2); // Выводит "Jeffrey"
}
За другими примерами решения, использующими обобщения, обращайтесь к классу System. Threading .Interlocked сего методами CompareExchange и Exchange.
Передача переменного количества аргументов
Иногда разработчику удобно определить метод, способный принимать переменное число параметров. Например, тип System.String предлагает методы, выполняющие объединение произвольного числа строк, а также методы, при вызове которых можно задать набор единообразно форматируемых строк.
Метод, принимающий переменное число аргументов, объявляют так:
static Int32 Add(params Int32[] values) {
// ПРИМЕЧАНИЕ: при необходимости этот массив // можно передать другим методам
Int32 sum = 0; if (values != null) {
for (Int32 x = 0; x < values.Length; x++) sum += values[x];
}
return sum;
}
Незнакомым в этом методе является только ключевое слово params, примененное к последнему параметру в сигнатуре метода. Если не обращать на него внимания, станет ясно, что метод принимает массив значений типа Int32, складывает все элементы этого массива и возвращает полученную сумму.
Очевидно, этот метод можно вызвать так:
public static void Main() {
// Выводит "15"
Console.WriteLine(Add(new Int32[] { 1, 2, 3, 4, 5 } ));
}
He вызывает сомнений утверждение, что этот массив легко инициализировать произвольным числом элементов и передать для обработки методу Add. Показанный здесь код немного неуклюж, хотя он корректно компилируется и работает. Разработчики, конечно, предпочли бы вызывать метод Add так:
public static void Main() {
// Выводит "15"
Console.WriteLine(Add(l, 2, 3, 4, 5));
}
Такая форма вызова возможна благодаря ключевому слову params. Именно оно заставляет компилятор рассматривать параметр как экземпляр настраиваемого атрибута System.ParamArrayAttribute.
Обнаружив такой вызов, компилятор C# проверяет все методы с заданным именем, у которых ни один из параметров не помечен атрибутом ParamArray. Найдя метод, способный принять вызов, компилятор генерирует вызывающий его код. В противном случае ищутся методы с атрибутом ParamArray и проверяется, могут ли они принять вызов. Если компилятор находит подходящий метод, то прежде чем сгенерировать код его вызова, он генерирует код, создающий и заполняющий массив.
В предыдущем примере не определен метод Add, принимающий пять совместимых с типом Int32 аргументов. Компилятор же видит в тексте исходного кода вызов метода Add, которому передается список значений Int32, и метод Add, у которого массив типа Int32 помечен атрибутом ParamArray. Компилятор считает данный метод подходящим для вызова и генерирует код, собирающий все параметры в массив типа Int32 и вызывающий метод Add. В конечном итоге получается, что можно написать вызов, без труда передающий методу Add набор параметров, и компилятор сгенерирует тот же код, что и для первой версии вызова метода Add, в которой массив создается и инициализируется явно.
Ключевым словом params может быть помечен только последний параметр метода (ParamArrayAttribute). Он должен указывать на одномерный массив произвольного типа. В последнем параметре метода допустимо передавать значение null или ссылку на массив, состоящий из нуля элементов. Следующий вызов метода Add прекрасно компилируется, отлично работает и дает в результате сумму, равную 0 (как и ожидалось):
 // передает новый элемент Int32[0] методу Add // передает методу Add значение null,
// передает новый элемент Int32[0] методу Add // передает методу Add значение null,
// что более эффективно (не выделяется // память под массив)
Все показанные до сих пор примеры демонстрировали методы, принимающие произвольное количество параметров типа Int32. А как написать метод, принимающий произвольное количество параметров любого типа? Ответ прост: достаточно отредактировать прототип метода, заставив его вместо Int32[ ] принимать Object [ ]. Следующий метод выводит значения Туре всех переданных ему объектов:
public sealed class Program { public static void MainQ {
DisplayTypes(new ObjectQ, new RandomQ, "Jeff"", 5);
}
private static void DisplayTypes(params Object[] objects) { if (objects != null) {
foreach (Object о in objects)
Console.WriteLine(o.GetType());
>
>
При выполнении этого кода будет выведен следующий результат:
System.Object System.Random System.String System.Int32
ВНИМАНИЕ
Вызов метода, принимающего переменное число аргументов, снижает производительность, если, конечно, не передавать в явном виде значение null. В любом случае всем объектам массива нужно выделить место в куче и инициализировать элементы массива, а по завершении работы занятая массивом память должна быть очищена сборщиком мусора. Чтобы уменьшить негативное влияние этих операций на производительность, можно определить несколько перегруженных методов, в которых не используется ключевое слово params. За примерами обратитесь к методу Concat класса System.String, который перегружен следующим образом:
public sealed class String : Object, ... { public static string Concat(object arg0)j public static string Concat(object arg0, object argl); public static string Concat(object arg0, object argl, object arg2); public static string Concat(params object[] args);
public static string Concat(string str0, string strl); public static string Concat(string str0, string strl, string str2); public static string Concat(string str0, string strl, string str2, string str3);
public static string Concat(params string[] values);
}
Как видите, для метода Concat определены несколько вариантов перегрузки, в которых ключевое слово params не используется. Здесь представлены наиболее распространенные варианты перегрузки, которые, собственно, и предназначены для повышения эффективности работы в стандартных ситуациях. Варианты перегрузки с ключевым словом params предназначены для более редких ситуаций, поскольку при этом страдает производительность. К счастью, такие ситуации возникают не так уж часто.
Типы параметров и возвращаемых значений
Объявляя тип параметров метода, нужно по возможности указывать «минимальные» типы, предпочитая интерфейсы базовым классам. Например, при написании метода, работающего с набором элементов, лучше всего объявить параметр метода, используя интерфейс IEnumerable<T> вместо сильного типа данных, например List<T>, или еще более сильного интерфейсного типа ICollection<T> или IList<T>:
// Рекомендуется в этом методе использовать параметр слабого типа public void ManipulateItems<T>(IEnumenable<T> collection) { ... }
// He рекомендуется в этом методе использовать параметр сильного типа public void ManipulateItems<T>(List<T> collection) { ... }
Причина, конечно же, в том, что первый метод можно вызывать, передав в него массив, объект List<T>, объект String и т. п., то есть любой объект, тип которого реализует интерфейс IEnumerable<T>. Второй метод принимает только объекты List<T>, с массивами или объектами String он работать уже не может. Ясно, что первый метод предпочтительнее, так как он гибче и может использоваться в более разнообразных ситуациях.
Естественно, при создании метода, получающего список (а не просто любой перечислимый объект), нужно объявлять тип параметра как IList<T>, в то время как типа List<T> лучше избегать. Именно такой подход позволит вызывающему коду передавать массивы и другие объекты, тип которых реализует IList<T>.
Обратите внимание, что в приводимых примерах речь идет о коллекциях, созданных с использованием архитектуры интерфейсов. Этот же подход применим к классам, опирающимся на архитектуру базовых классов. Потому, к примеру, при реализации метода, обрабатывающего байты из потока, пишем следующее:
// Рекомендуется в этом методе использовать параметр мягкого типа public void ProcessBytes(Stream someStream) { ... }
// He рекомендуется в этом методе использовать параметр сильного типа public void ProcessBytes(FileStream fileStream) { ... }
Первый метод может обрабатывать байты из потока любого вида: FileStream, NetworkStream, MemoryStream и т. п. Второй поддерживает только FileStream, то есть область его применения ограничена.
В то же время, объявляя тип возвращаемого методом объекта, желательно выбирать самый сильный из доступных вариантов (пытаясь не ограничиваться конкретным типом). Например, лучше объявлять метод, возвращающий объект FileStream,а не Stream:
// Рекомендуется в этом методе использовать // сильный тип возвращаемого объекта public FileStream OpenFileQ { ... }
// Не рекомендуется в этом методе использовать // слабый тип возвращаемого объекта public Stream OpenFileQ { ... }
Здесь предпочтительнее первый метод, так как он позволяет вызывающему коду обращаться с возвращаемым объектом как с объектом FileStream или Stream. А вот второму методу требуется, чтобы вызывающий код рассчитывал только на объект Stream, то есть область его применения более ограничена.
Иногда требуется сохранить возможность изменять внутреннюю реализацию метода, не влияя на вызывающий код. В приведенном ранее примере изменение реализации метода OpenFile в будущем маловероятно, он вряд ли будет возвращать что-либо отличное от объекта типа FileStneam (или типа, производного от FileStneam). Однако для метода, возвращающего объект List<Stning>, вполне возможно изменение реализации, после которого он начнет возвращать тип St г i ng [ ]. В подобных случаях следует выбирать более слабый тип возвращаемого объекта. Например:
// Гибкий вариант: в этом методе используется
// мягкий тип возвращаемого объекта
public ILlst<Strlng> GetStringCollection() { ... }
// Негибкий вариант: в этом методе используется
// сильный тип возвращаемого объекта
public List<String> GetStrlngCollectlon() { ... }
Хотя в коде метода GetStringCollection используется и возвращается объект List<String>, в прототипе метода лучше указать в качестве возвращаемого объекта IList<Stning>. Даже если в будущем указанная в коде метода коллекция изменит свой тип на String[ ], вызывающий код не потребуется ни редактировать, ни даже перекомпилировать. Обратите внимание, что в этом примере я выбрал самый «сильный» из самых «слабых» типов. К примеру, я не воспользовался типом IEnumerable<String> или ICollection<Stning>.
Константность
В некоторых языках, в том числе в неуправляемом языке C++, методы и параметры можно объявлять как константы. Этим вы запрещаете коду в экземплярном методе изменять поля объекта или объекты, передаваемые в метод. В CLR эта возможность не поддерживается, а многим программистам ее не хватает. Так как сама исполняющая среда не поддерживает такой функции, естественно, что она не поддерживается ни в одном языке (в том числе в С#).
В первую очередь следует заметить, что в неуправляемом коде C++ пометка экземплярного метода или параметра ключевым словом const гарантировала неизменность этого метода или параметра стандартными средствами кода. При этом внутри метода всегда можно было написать код, изменяющий объект или параметр путем игнорирования их «константной» природы или путем получения адреса объекта с последующей записью. В определенном смысле неуправляемый код C++ «врал» программистам, утверждая, что константные объекты или константные параметры вообще нельзя менять.
Создавая реализацию типа, разработчик может просто избегать написания кода, меняющего объекты и параметры. Например, неизменяемыми являются строки, так как класс String не предоставляет нужных для этого методов.
Кроме того, специалисты Microsoft не предусмотрели в CLR возможность проверки неизменности константных объектов или константных параметров. CLR пришлось бы при каждой операции записи проверять, не выполняется ли запись в константный объект, что сильно снизило бы эффективность работы программы. Естественно, обнаружение нарушения должно приводить к выдаче исключения. Кроме того, поддержка констант создает дополнительные сложности для разработчиков. В частности, при наследовании неизменяемого типа производные типы должны соблюдать это ограничение. Кроме того, неизменяемый тип, скорее всего, должен состоять из полей, которые тоже представляют собой неизменяемые типы.
Это лишь несколько причин, по которым CLR не поддерживает константные объекты/аргументы.
Глава 10. Свойства
Эта глава посвящена свойствам. Свойства позволяют обратиться к методу в исходном тексте программы с использованием упрощенного синтаксиса. CLR поддерживает два вида свойств: без параметров, их называют просто — свойства, и с параметрами — у них в разных языках разное название. Например, в C# свойства с параметрами называют индексаторами, а в Visual Basic — свойствами по умолчанию. Кроме того, в этой главе рассказывается об инициализации свойств при помощи инициализаторов объектов и коллекций, а также о механизме объединения свойств посредством анонимных типов и типа System.Tuple.
Свойства без параметров
Во многих типах определяется информация состояния, которую можно прочитать или изменить. Часто эта информация состояния реализуется полями типа. Вот, например, определение типа с двумя полями:
public sealed class Employee {
public String Name; // Имя сотрудника public Int32 Age; // Возраст сотрудника
}
Создавая экземпляр этого типа, можно получить или задать любые сведения о его состоянии при помощи примерно такого кода:
Employee е = new EmployeeQ;
e.Name = "Jeffrey Richter"; // Задаем имя сотрудника e.Age = 48; // Задаем возраст сотрудника
Console.WriteLine(e.Name); // Выводим на экран "Jeffrey Richter"
Этот способ чтения и записи информации состояния объекта очень распространен. Однако я считаю, что реализация такого вида совершенно недопустима. Одним из краеугольных камней объектно-ориентированного программирования и разработки является инкапсуляция данных. Инкапсуляция данных означает, что поля типа ни в коем случае не следует открывать для общего доступа, так как в этом случае слишком просто написать код, способный испортить сведения о состоянии объекта путем ненадлежащего использования полей. Например, следующим кодом разработчик может легко повредить объект Employee:
e.Age = -5; // Можете вообразить человека, которому минус 5 лет?
Есть и другие причины для инкапсуляции доступа к полям данных типа. Допустим, вам нужен доступ к полю, чтобы что-то сделать, разместить в кэше некоторое значение или создать какой-то внутренний объект, создание которого было отложено, причем обращение к полю не должно нарушать безопасность потоков. Или, скажем, поле является логическим и его значение представлено не байтами в памяти, а вычисляется по некоторому алгоритму.
Каждая из этих причин заставляет при разработке типов, во-первых, помечать все поля как закрытые (private), во-вторых, давать пользователю вашего типа возможность получения и задания сведений о состоянии через специальные методы, предназначенные исключительно для этого. Методы, выполняющие функции оболочки для доступа к полю, обычно называют методами доступа (accessor). Методы доступа могут выполнять дополнительные проверки, гарантируя, что сведения о состоянии объекта никогда не будут искажены. Я переписал класс из предыдущего примера следующим образом:
public sealed class Employee {
private String m_Name; // Поле стало закрытым private Int32 m_Age; // Поле стало закрытым
public String GetNameQ { return(m_Name);
}
public void SetName(String value) { m_Name = value;
}
public Int32 GetAge() { return(mAge);
>
public void SetAge(Int32 value) { if (value < 0)
throw new ArgumentOutOfRangeExceptlon(nvaluenj value.ToStringQj "The value must be greater than or equal to 0"); m_Age = value;
>
>
Несмотря на всю простоту, этот пример демонстрирует огромное преимущество инкапсуляции полей данных. Он также показывает, как просто создаются свойства, доступные только для чтения или только для записи — достаточно опустить один из методов доступа. В качестве альтернативы можно позволить изменять значения только в производных типах — для этого метод SetXxx помечается как защищенный (protected).
Как видите, у инкапсуляции данных есть два недостатка: во-первых, из-за реализации дополнительных методов приходится писать более длинный код, во-вторых, вместо простой ссылки на имя поля пользователям типа приходится вызывать
соответствующие методы:
е.SetName("Jeffrey Richter"); // Обновление имени сотрудника
String EmployeeName = e.GetName(); // Получение возраста сотрудника
e.SetAge(41); // Обновление возраста сотрудника
e.SetAge(-5); // Выдача исключения
// ArgumentOutOfRangeException
Int32 EmployeeAge = e.GetAge(); // Получение возраста сотрудника
Лично я считаю эти недостатки незначительными. Тем не менее CLR поддерживает механизм свойств, частично компенсирующий первый недостаток и полностью устраняющий второй.
Следующий класс функционально идентичен предыдущему, но в нем используются свойства:
public sealed class Employee { private String m_Name; private Int32 m_Age;
public String Name { get { return(m_Name); }
set { m_Name = value; } // Ключевое слово value } // идентифицирует новое значение
public Int32 Age {
get { return(m_Age); } set {
if (value < 0) // Ключевое слово value всегда
// идентифицирует новое значение throw new ArgumentOutOfRangeExceptionC'value", value.ToStringQ,
"The value must be greater than or equal to 0"); m_Age = value;
}
}
}
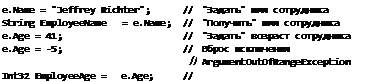 |
Как видите, хотя свойства немного усложняют определение типа, дополнительная работа более чем оправдана, потому что она позволяет писать код следующего вида:
Можно считать свойства «умными» полями, то есть полями с дополнительной логикой. CLR поддерживает статические, экземплярные, абстрактные и виртуальные свойства. Кроме того, свойства могут помечаться модификатором доступа (см. главу 6) и определяться в интерфейсах (см. главу 13).
У каждого свойства есть имя и тип (но не void). Нельзя перегружать свойства (то есть определять несколько свойств с одинаковыми именами, но разным типом).
Определяя свойство, обычно описывают пару методов: get и set. Однако опустив метод set, можно определить свойство, доступное только для чтения, а опуская только метод get, мы получим свойство, доступное только для записи.
Методы get и set свойства довольно часто манипулируют закрытым полем, определенным в типе. Это поле обычно называют резервным (backing field). Однако методам get и set не приходится обращаться к резервному полю. Например, тип System.Threading.Thread поддерживает свойство Priority, взаимодействующее непосредственно с ОС, а объект Thread не поддерживает поле, хранящее приоритет потока. Другой пример свойств, не имеющих резервных полей, — это неизменяемые свойства, вычисляемые при выполнении: длина массива, заканчивающегося нулем, или область прямоугольника, заданного шириной и высотой и т. д.
При определении свойства компилятор генерирует и помещает в результирующий управляемый модуль следующее:
□ метод get свойства генерируется, только если для свойства определен метод доступа get;
□ метод set свойства генерируется, только если для свойства определен метод доступа set;
□ определение свойства в метаданных управляемого модуля генерируется всегда.
Вернемся к показанному ранее типу Employee. При его компиляции компилятор обнаруживает свойства Name и Age. Поскольку у обоих есть методы доступа get и set, компилятор генерирует в типе Employee четыре определения методов. Результат получается такой, как если бы тип был исходно написан следующим образом:
public sealed class Employee { private String mName; private Int32 m_Age;
public String get_Name(){ return mName;
>
public void set_Name(String value) {
m_Name = value; // Аргумент value всегда идентифицирует новое значение
>
public Int32 get_Age() { return m_Age;
>
public void set_Age(Int32 value) {
if (value < 0) { // value всегда идентифицирует новое значение throw new ArgumentOutOfRangeException("value", value.ToStringQ,
"The value must be greater than or equal to 0");
>
m_Age = value;
>
>
Компилятор автоматически генерирует имена этих методов, прибавляя приставку get_ или set_ к имени свойства, заданному разработчиком.
Поддержка свойств встроена в С#. Обнаружив код, пытающийся получить или задать свойство, компилятор генерирует вызов соответствующего метода. Если используемый язык не поддерживает свойства напрямую, к ним все равно можно обратиться посредством вызова нужного метода доступа. Эффект тот же, только исходный текст выглядит менее элегантно.
Помимо методов доступа, для каждого из свойств, определенных в исходном тексте, компиляторы генерируют в метаданных управляемого модуля запись с определением свойства. Такая запись содержит несколько флагов и тип свойства, а также ссылки на методы доступа get и set. Эта информация существует лишь затем, чтобы связать абстрактное понятие «свойства» с его методами доступа. Компиляторы и другие инструменты могут использовать эти метаданные через класс System. Reflection. Pnopentylnfo. И все же CLR не использует эти метаданные, требуя при выполнении только методы доступа.
Автоматически реализуемые свойства
Если необходимо создать свойства для инкапсуляции резервных полей, то в C# есть упрощенный синтаксис, называемый автоматически реализуемыми свойствами (Automatically Implemented Properties, AIP). Приведу пример для свойства Name:
public sealed class Employee {
11 Это свойство является автоматически реализуемым public String Name { get; set; } private Int32 m_Age; public Int32 Age {
get { return(m_Age); } set {
if (value < 0) // value всегда идентифицирует новое значение throw new ArgumentOutOfRangeException("value"J value.ToStringO,
"The value must be greater than or equal to 0“); m_Age = value;
}
}
Если вы объявите свойства и не обеспечите реализацию методов set и get, то компилятор C# автоматически объявит их закрытыми полями. В данном примере поле будет иметь тип String — тип свойства. И компилятор автоматически реализует методы get_Name и set_Name для правильного возвращения значения из поля и назначения значения полю.
Вы спросите, зачем это нужно, особенно в сравнении с обычным объявлением строкового поля Name? Между ними есть большая разница. Использование AIP- синтаксиса означает, что вы создаете свойство. Любой программный код, имеющий доступ к этому свойству, вызывает методы get и set. Если вы позднее решите реализовать эти методы самостоятельно, заменив их реализацию, предложенную компилятором по умолчанию, то код, имеющий доступ к свойству, не нужно будет перекомпилировать. Однако если объявить Name как поле и позднее заменить его свойством, то весь программный код, имеющий доступ к полю, придется перекомпилировать, поскольку он будет обращаться к методам свойства.
Лично мне не нравятся автоматически реализуемые свойства, обычно я стараюсь их избегать по нескольким причинам.
□ Синтаксис объявления поля может включать инициализацию, таким образом, вы объявляете и инициализируете поле в одной строке кода. Однако нет подходящего синтаксиса для установки при помощи AIP начального значения. Следовательно, необходимо неявно инициализировать все автоматически реализуемые свойства во всех конструкторах.
□ Механизм сериализации на этапе выполнения сохраняет имя поля в сериализованном потоке. Имя резервного поля для AIP определяется компилятором, и он может менять это имя каждый раз, когда компилирует код, сводя на нет возможность десериализации экземпляров всех типов, содержащих автоматически реализуемые свойства. Не используйте этот механизм для типов, подлежащих сериализации и десериализации.
□ Во время отладки нельзя установить точку останова в AIP-методах set и get, поэтому вы не сможете легко узнать, когда приложение получает и задает значение автоматически реализуемого свойства. Точки останова можно устанавливать только в тех свойствах, которые программист пишет самостоятельно.
Также следует знать, что при использовании AIP свойства должны иметь уровень доступа для чтения и записи, так как компилятор генерирует методы set и get. Это разумно, поскольку поля для чтения и записи бесполезны без возможности чтения их значения, более того, поля для чтения бесполезны, если в них будет храниться только значение по умолчанию. К тому же из-за того, что вы не знаете имени автоматически генерируемого резервного поля, ваш программный код должен всегда обращаться к свойству по имени. И если вы решите явно реализовать один из методов доступа, то вам придется явно реализовать оба метода доступа и при этом отказаться от использования AIP. Механизм AIP работает слишком бескомпромиссно.
Осторожный подход к определению свойств
Лично мне свойства не нравятся и я был бы рад, если бы в Microsoft решили убрать их поддержку из .NET Framework и сопутствующих языков программирования. Причина в том, что свойства выглядят как поля, являясь по сути методами. Это порождает немыслимую путаницу. Столкнувшись с кодом, который вроде бы обращается к полю, разработчик привычно предполагает наличие множества условий, которые далеко не всегда соблюдаются, если речь идет о свойстве.
□ Свойства могут быть доступны только для чтения или только для записи, в то время как поля всегда доступны и для чтения, и для записи. Определяя свойство, лучше всего создавать для него оба метода доступа (get и set).
□ Свойство, являясь по сути методом, может выдавать исключения, а при обращениям к полям исключений не бывает.
□ Свойства нельзя передавать в метод в качестве параметров с ключевым словом out или ref, в частности, следующий код не компилируется:
using System;
public sealed class SomeType {
private static String Name { get { return null; } set {>
>
static void MethodWithOutParam(out String n) { n = null; }
public static void Main() {
// При попытке скомпилировать следующую строку // компилятор вернет сообщение об ошибке:
// error CS0206: A property or indexer may not // be passed as an out or ref parameter.
MethodWithOutParam(out Name);
}
}
□ Свойство-метод может выполняться довольно долго, в то время как обращения к полям выполняются моментально. Часто свойства применяют для синхронизации потоков, но это может привести к приостановке потока на неопределенное время, поэтому свойства не следует использовать для этих целей — в такой ситуации лучше задействовать метод. Кроме того, если предусмотрен удаленный доступ к классу (например, если он наследует от System. MarshalByRefOb ject), вызов свойства-метода выполняется очень медленно, поэтому предпочтение следует отдать методу. Я считаю, что в классах, производных от MarshalByRefObject, никогда не следует использовать свойства.
□ При нескольких вызовах подряд свойство-метод может возвращать разные значения, а поле возвращает одно и то же значение. В классе System. DateTime есть неизменяемое свойство Now, которое возвращает текущие дату и время. При каждом последующем вызове свойство возвращает новое значение. Это ошибка, и в компании Microsoft охотно исправили бы этот класс, превратив Now в метод. Другой пример подобной ошибки — свойство Environment.TickCount.
□ Свойство-метод может порождать видимые побочные эффекты, невозможные при доступе к полю. Иначе говоря, порядок определения значений различных свойств типа никак не должен влиять на поведение типа, однако в действительности часто бывает не так.
□ Свойству-методу может требоваться дополнительная память или ссылка на объект, не являющийся частью состояния объекта, поэтому изменение возвращаемого объекта никак не сказывается на исходном объекте; при запросе поля всегда возвращается ссылка на объект, который гарантированно относится к состоянию исходного объекта. Свойство, возвращающее копию, — источник путаницы для разработчиков, причем об этом часто забывают упомянуть в документации.
Я считаю, что разработчики используют свойства намного чаще, чем следовало бы. Достаточно внимательно изучить список различий между свойствами и полями, чтобы понять: есть очень немного ситуаций, в которых определение свойства действительно полезно, удобно и не запутывает разработчика. Единственная привлекательная черта свойств — упрощенный синтаксис, все остальное — недостатки, в числе которых потеря в производительности и читабельности кода. Если бы я участвовал в разработке .NET Framework и компиляторов, я бы вообще отказался от свойств, вместо этого я предоставил бы разработчикам полную свободу реализации методов GetXxx и SetXxx. Позже создатели компиляторов могли бы предоставить особый упрощенный синтаксис вызова этих методов, но только при условии его отличия от синтаксиса обращения к полям, чтобы программист четко понимал, что выполняется вызов метода!
Свойства и отладчик Visual Studio
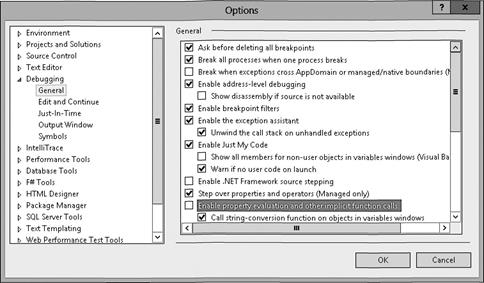
Microsoft Visual Studio позволяет указывать свойства объектов в окне просмотра отладчика. В результате при задании точки останова отладчик будет вызывать метод get и показывать возвращаемое значение. Это может быть полезно при поиске ошибок, но также может сказаться на точности и производительности приложения. Например, пусть вы создали поток FileStream для файла, передаваемого по сети, и затем добавили свойство FileStream. Length в окно просмотра отладчика. Каждый раз при переходе к точке останова отладчик вызовет метод доступа get, который во внутренней реализации выполнит сетевой запрос к серверу для получения текущей длины файла!
Аналогичным образом, если метод доступа get производит какой-то побочный эффект, то этот эффект всегда будет выполняться при достижении точки останова. Например, если метод доступа get увеличивает счетчик каждый раз во время вызова, то этот счетчик будет каждый раз увеличиваться на точке останова. Из-за этих потенциальных проблем Visual Studio позволяет отключить режим вычислений для свойств, указанных в окне просмотра отладчика. Для этого выберите команду Tools ► Options, в списке открывшегося окна Options раскройте ветвь Debugging ► General и сбросьте флажок Enable Property Evaluation And Other Implicit Function Calls (рис. 10.1). Обратите внимание, что даже отключив таким образом вычисления для свойства, все равно можно будет добавить свойство в окно просмотра отладчика и вручную запустить вычисления, щелкнув мышью на значке вычислений в колонке Value окна просмотра отладчика Visual Studio.
|
Рис. 10.1. Настройки отладчика Visual Studio |
Инициализаторы объектов и коллекций
Создание объекта с заданием некоторых открытых свойств (или полей) - чрезвычайно распространенная операция. Для ее упрощения в C# предусмотрен специальный синтаксис инициализации объекта, например:
Employee е = new EmployeeQ { Name = "leff", Age = 45 };
В этом выражении я создаю объект Employee, вызывая его конструктор без параметров. и затем назначаю открытому свойству Name значение leff. а открытому свойству Age — значение 45. Этот код идентичен следующему коду (в этом нетрудно убедиться, просмотрев I L-код обоих фрагментов):
Employee е = new EmployeeQ; e.Name = "leff"; e.Age = 45;
Реальная выгода от синтаксиса инициализатора объекта состоит в том, что он позволяет программировать в контексте выражения, строя функции, которые улучшают читабельность кода. J 1апример, можно написать:
String s = new EmployeeQ { Name = "leff". Age = 45 }. ToStning(). Tollppen ();
В одном выражении я сконструировал объект Employee, вызвал его конструктор, инициализировал два открытых свойства, вызвал метод ToString. а затем метод
ТoUpper. C# также позволяет опустить круглые скобки перед открывающей фигурной скобкой, если вы хотите вызвать конструктор без параметров. Для следующего фрагмента генерируется программный код, идентичный предыдущему:
String s = new Employee { Name = "Jeff", Age = 45 }. ToStringQ .ToUpper();
Если тип свойства реализует интерфейс IEnumerable или IEnumerable<T>, то свойство является коллекцией, а инициализация коллекции является дополняющей операцией (а не заменяющей). Например, пусть имеется следующее определение класса:
public sealed class Classroom {
private List<String> m_students = new List<String>(); public List<String> Students { get { return m_students; } }
public ClassroomQ {}
}
Следующий код создает объект Classroom и инициализирует коллекцию Students:
public static void M() {
Classroom classroom = new Classroom {
Students = { "left", "Kristin", "Aidan", "Grant" }
};
// Вывести имена 4 студентов, находящихся в классе foreach (var student in classroom.Students)
Console.WriteLine(student);
}
Во время компиляции этого кода компилятор увидит, что свойство Students имеет тип List<String> и что этот тип реализует интерфейс IEnumerable<String>. Компилятор предполагает, что тип List<String> предоставляет метод с именем Add (потому что большинство классов коллекций предоставляет метод Add для добавления элементов в коллекцию). Затем компилятор сгенерирует код для вызова метода Add коллекции. В результате представленный код будет преобразован компилятором в следующий:
public static void М() {
Classroom classroom = new ClassroomQ; classroom.Students.Add("left"); classroom.Students.Add("Kristin"); classroom.Students.Add("Aidan"); classroom.Students.Add("Grant");
// Вывести имена 4 студентов, находящихся в классе foreach (var student in classroom.Students)
Console.WriteLine(student);
}
Если тип свойства реализует интерфейс IEnumerable или IEnumerable<T>, но не предлагает метод Add, тогда компилятор не разрешит использовать синтаксис инициализации коллекции для добавления элемента в коллекцию, вместо этого компилятор выведет такое сообщение (ошибка CS0117: System.Collections. Generic .IEnumerable<string> не содержит определения для Add):
error CS0117: 'System.Collections.Generic.IEnumerable<string>[10] does not
contain a definition for 'Add'
Некоторые методы Add принимают различные аргументы. Например, вот метод Add класса Dictionary:
public void Add(TKey key, TValue value);
При инициализации коллекции методу Add можно передать несколько аргументов, для чего используется синтаксис с фигурными скобками:
var table = new DictionarycString, Int32> {
{ "Jeffrey", 1 }, { "Kristin", 2 }, { "Aidan", 3 }, { "Grant", 4 }
};
Это равносильно следующему коду:
var table = new DictionarycString, Int32>(); table.Add("Jeffrey", 1); table.Add("Kristin", 2); table.Add("Aidan", 3); table.Add("Grant", 4);
Анонимные типы
Механизм анонимных типов в C# позволяет автоматически объявить кортежный тип при помощи простого синтаксиса. Кортежный тип (tuple type)1 — это тип, который содержит коллекцию свойств, каким-то образом связанных друг с другом. В первой строке следующего программного кода я определяю класс с двумя свойствами (Name типа String и Year типа Int32), создаю экземпляр этого типа и назначаю свойству Name значение leff, а свойству Year — значение 1964.
// Определение типа, создание сущности и инициализация свойств var ol = new { Name = "Jeff", Year = 1964 };
// Вывод свойств на консоль
Console.Writel_ine("Name={0}, Year={l}", ol.Name, ol.Year); // Выводит:
// Name=Jeff, Year=1964
Здесь создается анонимный тип, потому что не был определен тип имени после слова new, таким образом, компилятор автоматически создает имя типа, но не сообщает какое оно (поэтому тип и назван анонимным). Использование синтаксиса инициализации объекта обсуждалось в предыдущем разделе. Итак, я, как разработчик, не имею понятия об имени типа на этапе компиляции и не знаю, с каким типом была объявлена переменная ol. Однако проблемы здесь нет — я могу использовать механизм неявной типизации локальной переменной, о котором говорится в главе 9, чтобы компилятор определил тип по выражению в правой части оператора присваивания (=).
Итак, посмотрим, что же действительно делает компилятор. Обратите внимание на следующий код:
var о = new { propertyl = expression!., . .., propertyN = expressionN };
Когда вы пишете этот код, компилятор определяет тип каждого выражения, создает закрытые поля этих типов, для каждого типа поля создает открытые свойства только для чтения и для всех этих выражений создает конструктор. Код конструктора инициализирует закрытые поля только для чтения путем вычисления результирующих значений. В дополнение к этому, компилятор переопределяет методы Equals, GetHashCode и ToString объекта и генерирует код внутри всех этих методов. Класс, создаваемый компилятором, выглядит следующим образом:
[CompilerGenerated]
internal sealed class of______ AnonymousType0<. . . > : Object {
private readonly tl fl;
public tl pi { get { return fl; } } private readonly tn fn;
public tn pn { get { return fn; } }
public of____ AnonymousType0<... >(tl al, ..., tn an) {
fl = al; ...; fn = an; // Назначает все поля
}
public override Boolean Equals(Object value) {
II Возвращает false, если какие-либо поля не совпадают;
// иначе возвращается true
}
public override Int32 GetHashCode() {
// Возвращает хеш-код, сгенерированный из хеш-кодов полей
}
public override String ToStringO {
// Возвращает пары “name = value", разделенные точками
}
Компилятор генерирует методы Equals и GetHashCode, чтобы экземпляры анонимного типа моги размещаться в хеш-таблицах. Неизменяемые свойства, в отличие
от свойств для чтения и записи, помогают защитить хеш-код объекта от изменений. Изменение хеш-кода объекта, используемого в качестве ключа в хеш-таблице, может помешать нахождению объекта. Компилятор генерирует метод ToStning для упрощения отладки. В отладчике Visual Studio можно навести указатель мыши на переменную, связанную с экземпляром анонимного типа, и Visual Studio вызовет метод ToString и покажет результирующую строку в окне подсказки. Кстати, IntelliSense-окно в Visual Studio будет предлагать имена свойств в процессе написания кода в редакторе — очень полезная функция.
Компилятор поддерживает два дополнительных варианта синтаксиса объявления свойства внутри анонимного типа, где на основании переменных определяются имена и типы свойств:
String Name = "Grant";
DateTime dt = DateTime.Now;
// Анонимный тип с двумя свойствами
// 1. Строковому свойству Name назначено значение Grant // 2. Свойству Year типа Int32 Year назначен год из dt var о2 = new { Name, dt.Year };
В данном примере компилятор определяет, что первое свойство должно называться Name. Так как Name — это имя локальной переменной, то компилятор устанавливает значение типа свойства аналогичного типу локальной переменной, то есть String. Для второго свойства компилятор использует имя поля/свойства: Year. Year — свойство класса DateTime с типом Int32, а следовательно, свойство Year в анонимном типе будет относиться к типу Int32. Когда компилятор создает экземпляр анонимного типа, он назначает экземпляру Name свойство с тем же значением, что и у локальной переменной Name, так что свойство Name будет связано со строкой Grant. Компилятор назначит свойству экземпляра Year то же значение, что и возвращаемое значение из dt свойства Year.
Компилятор очень разумно выясняет анонимный тип. Если компилятор видит, что вы определили множество анонимных типов с идентичными структурами, то он создает одно определение для анонимного типа и множество экземпляров этого типа. Под одинаковой структурой я подразумеваю, что анонимные типы имеют одинаковые тип и имя для каждого свойства и что эти свойства определены в одинаковом порядке. В коде из приведенного примера тип переменной о1 и тип переменной о2 одинаков, так как в двух строках кода определен анонимный тип со свойством Name/String и Year/Int32, и Name стоит перед Year.
Раз две переменные относятся к одному типу, открывается масса полезных возможностей — например, проверить, содержат ли два объекта одинаковые значения, и присвоить ссылку на один объект переменной другого объекта:
// Совпадение типов позволяет осуществлять операции сравнения и присваивания Console.WriteLine("Objects are equal: " + ol.Equals(o2)); ol = o2; // Присваивание
Раз эти типы идентичны, то можно создать массив явных типов из анонимных типов (о массивах см. главу 16):
// Это работает, так как все объекты имею один анонимный тип var people = new[] {
ol, // См. ранее в этом разделе new { Name = "Kristin", Year = 1970 }, new { Name = "Aidan", Year = 2003 }, new { Name = "Grant", Year = 2008 }
};
// Организация перебора массива анонимных типов // (ключевое слово var обязательно), foreach (var person in people)
Console.WriteLine("Person={0}, Year={l}", person.Name, person.Year);
Анонимные типы обычно используются с технологией языка интегрированных запросов (Language Integrated Query, LINQ), когда в результате выполнения запроса создается коллекция объектов, относящихся к одному анонимному типу, после чего производится обработка объектов в полученной коллекции. Все это делается в одном методе. В следующем примере все файлы из папки с моими документами, которые были изменены в последние семь дней:
String myDocuments =
Environment.GetFolderPath(Environment.SpecialFolder.MyDocuments); var query =
from pathname in Directory.GetFiles(myDocuments) let LastWriteTime = File.GetLastWriteTime(pathname) where LastWriteTime > (DateTime.Now - TimeSpan.FromDays(7)) orderby LastWriteTime
select new { Path = pathname, LastWriteTime };
foreach (var file in query)
Console.WriteLine("LastWriteTime={0}, Path={l}“, file.LastWriteTime, file.Path);
Экземпляры анонимного типа не должны выходить за пределы метода. В прототипе метода не может содержаться параметр анонимного типа, так как задать анонимный тип невозможно. По тому же принципу метод не может возвращать ссылку на анонимный тип. Хотя экземпляр анонимного типа может интерпретироваться как Object (все анонимные типы являются производными от Object), преобразовать переменную типа Object обратно к анонимному типу невозможно, потому что имя анонимного типа на этапе компиляции неизвестно. Для передачи кортежного типа следует использовать тип System.Tuple, о котором речь идет в следующем разделе.
Тип System.Tuple
В пространстве имен System определено несколько обобщенных кортежных типов (все они наследуются от класса Object), которые отличаются количеством обобщенных параметров. Приведу наиболее простую и наиболее сложную формы записи.
// Простая форма:
[Serializable] public class Tuple<Tl> { private T1 m_Iteml;
public Tuple(Tl iteml) { m Iteml = iteml; } public T1 Iteml { get { return m_Iteml; } }
// Сложная форма:
[Serializable]
public class TuplecTl, T2, T3, T4, T5, T6, T7, TRest> { private T1 m_Iteml; private T2 m_Item2; private T3 m_Item3; private T4 m_Item4; private T5 m_Item5; private T6 m_Item6; private T7 m_Item7; private TRestm_Rest;
public Tuple(Tl iteml, T2 item2, T3 item3,
T4 item4, T5 item5, T6 item6, T7 item7, TRest t) {
m_Iteml = iteml; m_Item2 = item2; m_Item3 = item3; m_Item4 = item4; m_Item5 = item5; m_Item6 = item6; m_Item7 = item7; mRest = rest;
| public | T1 | Iteml { | get { | return | m | Iteml; | } | } |
| public | T2 | Item2 { | get { | return | m | Item2; | } | } |
| public | T3 | Item3 { | get { | return | m | Item3; | } | } |
| public | T4 | Item4 { | get { | return | m_ | Item4; | } | } |
| public | T5 | Item5 { | get { | return | m_ | Item5; | > | > |
| public | T6 | Item6 { | get { | return | m_ | Item6; | > | > |
| public | T7 | Item7 { | get { | return | m_ | Item7; | > | > |
| public | TRest Rest | { get | { return | m_Rest; | > } | |||
|
|
Как и объекты анонимного типа, объект Tuple создается один раз и остается неименным (все свойства доступны только для чтения). Я не привожу соответствующих примеров, но классы Tuple также позволяют использовать методы CompareTo, Equals, GetHashCode и ToString, как и свойство Size. К тому же все типы Tuple реализуют интерфейсы IStructuralEquatable, IStructuralComparable и IComparable, поэтому вы можете сравнивать два объекта типа Tuple друг с другом и смотреть, как их поля сравниваются. Для детального изучения этих методов и интерфейсов посмотрите документацию SDK.
Приведу пример метода, использующего тип Tuple для возвращения двух частей информации в вызывающий метод.
// Возвращает минимум в Iteml и максимум в Item2 private static Tuple<Int32, Int32>MinMax(Int32 a, Int32 b) { return new Tuple<Int32, Int32>(Math.Min(a, b), Math.Max(a, b));
}
// Пример вызова метода и использования Tuple private static void TupleTypes() { varminmax = MinMax(6, 2);
Console.WriteLine("Min={0}, Max={l}"j
minmax.Iteml, minmax.Item2); 11 Min=2, Max=6
}
Конечно, очень важно, чтобы и производитель, и потребитель типа Tuple имели четкое представление о том, что будет возвращаться в свойствах Item#. С анонимными типами свойства получают действительные имена на основе программного кода, определяющего анонимный тип. С типами Tuple свойства получают их имена автоматически, и вы не можете их изменить. К несчастью, эти имена не имеют настоящего значения и смысла, а зависят от производителя и потребителя. Это также ухудшает читабельность кода и удобство его сопровождения, так что вы должны добавлять комментарии к коду, чтобы объяснить, что именно производитель/по- требитель имеет в виду.
Компилятор может только подразумевать обобщенный тип во время вызова обобщенного метода, а не тогда, когда вы вызываете конструктор. В силу этой причины пространство имен System содержит статический необобщенный класс Tuple с набором статических методов Create, которые могут определять обобщенные типы по аргументам. Этот класс действует как фабрика по производству объектов типа Tuple и существует просто для упрощения вашего кода. Вот переписанная с использованием статического класса Tuple версия метода MinMax:
// Возвращает минимум в Iteml и максимум в Item2
private static Tuple<Int32, Int32>MinMax(Int32 a, Int32 b) {
return Tuple.Create(Math.Min(a, b), Math.Max(a, b)); // Упрощенный
Чтобы создать тип Tuple с более, чем восьмью элементами, передайте другой объект Tuple в параметре Rest:
var t = Tuple.Create(0, 1, 2, 3, 4, 5, 6, Tuple.Create(7, 8))j Console. Write Line ("{0}, {1}, {2}, {3}, {4}, {5}, {6Ь {?b W, t. Iteml, t.Item2, t.Item3, t.Item4, t.Item5, t.Item6, t.Item7, t.Rest.Iteml.Iteml, t.Rest.Iteml.Item2)j
ПРИМЕЧАНИЕ
Кроме анонимных и кортежных типов, стоит присмотреться к классу System. Dynamic. ExpandoObject (определенному в сборке System.Core.dll assembly). При использовании этого класса с динамическим типом C# (о котором говорится в главе 5) появляется другой способ группировки наборов свойств (пар ключ-значение) вместе. Полученный в результате тип не обладает безопасностью типов на стадии компиляции, зато синтаксис выглядит отлично (хотя вы лишаетесь поддержки IntelliSense), а объекты ExpandoObject могут передаваться между C# и такими динамическими языками, как Python. Пример кода с использованием объекта ExpandoObject:
dynamic е = new System.Dynamic. ExpandoObjectQ ; e.x = 6; // Добавление свойства 'x' типа Int32
// со значением 6
е.у = "Jeff"; // Добавление свойства 'у' строкового типа // со значением "Jeff"
e.z = null; // Добавление свойста "z" объекта // со значением null
// Просмотр всех свойств и других значений foreach (var v in (IDictionarycString, Object>)e)
Console.WriteLine("Key={0}, V={1}", v.Key, v.Value);
// Удаление свойства 'x' и его значения var d = (IDictionarycString, ObJect>)e; d.Remove("x");
Свойства с параметрами
У свойств, рассмотренных в предыдущем разделе, методы доступа get не принимали параметры. Поэтому я называю их свойствами без параметров (parameterless properties). Они проще, так как их использование напоминает обращение к полю. Помимо таких «полеобразных» свойств, языки программирования поддерживают то, что я называю свойствами с параметрами (parameterful properties). У таких свойств методы доступа get получают один или несколько параметров. Разные языки поддерживают свойства с параметрами по-разному. Кроме того, в разных языках свойства с параметрами называют по-разному: в C# — индексаторы, в Visual Basic — свойства по умолчанию. Здесь я остановлюсь на поддержке индексаторов в C# на основе свойств с параметрами.
В C# синтаксис свойств с параметрами (индексаторов) напоминает синтаксис массивов. Иначе говоря, индексатор можно представить как средство, позволяющее разработчику на C# перегружать оператор [ ]. В следующем примере класс BitArray позволяет индексировать набор битов, поддерживаемый экземпляром типа, с использованием синтаксиса массива:
using System;
public sealed class BitArray {
// Закрытый байтовый массив, хранящий биты private Byte[] m_byteArray; private Int32 m_numBits;
// Конструктор, выделяющий память для байтового массива //и устанавливающий все биты в 0 public BitArray(Int32 numBits) {
// Начинаем с проверки аргументов if (numBits <= 0)
throw new ArgumentOutOfRangeException("numBits must be > 0");
// Сохранить число битов m_numBits = numBits;
// Выделить байты для массива битов
mbyteArray = new Byte[(numBits + 7) / 8];
}