
□ Компонент (сборка в .NET) можно публиковать.








□ Компоненты уникальны и идентифицируются по имени, версии, региональным стандартам и открытому ключу.
□ Компонент сохраняет свою уникальность (код одной сборки никогда статически не связывается с другой сборкой — в .NET применяется только динамическое связывание).
□ В компоненте всегда четко указана зависимость от других компонентов (ссылочные таблицы метаданных).
□ В компоненте документированы его классы и члены. В C# даже разрешается включать в код компонента XML-документацию — для этого служит параметр /doс командной строки компилятора.
□ В компоненте определяются требуемые разрешения на доступ. Для этого в CLR существует механизм защиты доступа к коду (Code Access Security, CAS).
□ Опубликованный компонентом интерфейс (объектная модель) не изменяется во всех его служебных версиях. Служебной версией (servicing) называют новую версию компонента, обратно совместимую с оригинальной. Обычно служебная версия содержит исправления ошибок, исправления системы безопасности и небольшие корректировки функциональности. Однако в нее нельзя добавлять новые зависимости или разрешения безопасности.
Как видно из последнего пункта, в компонентном программировании большое внимание уделяют управлению версиями. В компоненты вносятся изменения, к тому же они поставляются в разное время. Необходимость управления версиями существенно усложняет компонентное программирование по сравнению с ООП, где все приложение пишет, тестирует и поставляет одна компания.
В .NET номер версии состоит из четырех частей: основного (major) и дополнительного (minor) номеров версии, номера построения (build) и номера редакции (revision). Например, у сборки с номером 1.2.3.4 основной номер версии — 1, дополнительный номер версии — 2, номер построения — 3 и номер редакции — 4. Основной и дополнительный номера обычно определяют уникальность сборки, а номера построения и редакции указывают на служебную версию.
Допустим, компания поставила сборку версии 2.7.0.0. Если впоследствии потребуется выпустить сборку с исправленными ошибками, выпускают новую сборку, в которой изменяют только номера построения и редакции, например 2.7.1.34. То есть сборка является служебной версией и обратно совместима с оригинальной (2.7.0.0).
В то же время, если компания выпустит новую версию сборки, в которую внесены значительные изменения, а обратная совместимость не гарантируется, нужно изменить основной и/или дополнительный номер версии (например, 3.0.0.0).
ПРИМЕЧАНИЕ
Я описал то, как вам следует относиться к номерам версий. К сожалению, CLR не работаете номерами версий по этим правилам. Если сборка зависит от версии 1.2.3.4 другой сборки, CLR будет пытаться загрузить только версию 1.2.3.4 (если только не задействовать механизм перенаправления связывания).
После ознакомления с порядком присвоения номера версии новому компоненту самое время узнать о возможностях CLR и языков программирования (таких как С#), позволяющих разработчикам писать код, устойчивый к изменениям компонентов.
Проблемы управления версиями возникают, когда тип, определенный в одном компоненте (сборке), используется в качестве базового класса для типа другого компонента (сборки). Ясно, что изменения в базовом классе могут повлиять на поведение производного класса. Эти проблемы особенно характерны для полиморфизма, когда в производном типе переопределяются виртуальные методы базового типа.
В C# для типов и/или их членов есть пять ключевых слов, влияющих на управление версиями, причем они напрямую связаны с соответствующими возможностями CLR. В табл. 6.2 перечислены ключевые слова С#, относящиеся к управлению версиями, и описано их влияние на определение типа или члена типа.
| Таблица 6.2. Ключевые слова C# и их влияние на управление версиями компонентов
| ||||||||||||||||||||||||
|
|
О назначении и использовании этих ключевых слов рассказывается в разделе «Работа с виртуальными методами при управлении версиями типов», но прежде необходимо рассмотреть механизм вызова виртуальных методов в CLR.
Вызов виртуальных методов, свойств и событий в CLR
В этом разделе речь идет только о методах, но все сказанное относится и к виртуальным свойствам и событиям, поскольку они, как показано далее, на самом деле реализуются методами.
Методы содержат код, выполняющий некоторые действия над типом (статические методы) или экземпляром типа (нестатические). У каждого метода есть имя, сигнатура и возвращаемый тип, который может быть пустым (void). У типа может быть несколько методов с одним именем, но с разным числом параметров или разными возвращаемыми значениями. Можно также определить два метода с одним и тем же именем и параметрами, но с разными типами возвращаемого значения. Однако эта «возможность» большинством языков не используется (за исключением IL) — все они требуют, чтобы методы с одинаковым именем различались параметрами, а возвращаемое значение при определении уникальности метода игнорируется. Впрочем, благодаря операторам преобразования типов в языке C# это ограничение смягчается (см. главу 8).
Определим класс Employee с тремя различными вариантами методов.
internal class Employee {
// Невиртуальный экземплярный метод public Int32 GetYearsEmployed { ... }
// Виртуальный метод (виртуальный - значит, экземплярный) public virtual String GetProgressReport { ... }
// Статический метод
public static Employee Lookup(String name) { }
}
При компиляции этого кода компилятор помещает три записи в таблицу определений методов сборки. Каждая запись содержит флаги, указывающие, является ли метод экземплярный, виртуальным или статическим.
При компиляции кода, ссылающегося на эти методы, компилятор проверяет флаги в определении методов, чтобы выяснить, какой IL-код нужно вставить для корректного вызова методов. В CLR есть две инструкции для вызова метода:
□ Инструкция call используется для вызова статических, экземплярных и виртуальных методов. Если с помощью этой инструкции вызывается статический метод, необходимо указать тип, в котором определяется метод. При вызове экземплярного или виртуального метода необходимо указать переменную, ссылающуюся на объект, причем в call подразумевается, что эта переменная не равна null. Иначе говоря, сам тип переменной указывает, в каком типе определен необходимый метод. Если в типе переменной метод не определен, проверяются базовые типы. Инструкция call часто служит для невиртуального вызова виртуального метода.
□ Инструкция callvirt используется только для вызова экземплярных и виртуальных (но не статических) методов. При вызове необходимо указать переменную, ссылающуюся на объект. Если с помощью этой инструкции вызывается невиртуальный экземплярный метод, тип переменной показывает, где определен необходимый метод. При использовании callvirt для вызова виртуального экземплярного метода CLR определяет настоящий тип объекта, на который ссылается переменная, и вызывает метод полиморфно. При компиляции такого вызова JIT-компилятор генерирует код для проверки значения переменной — если оно равно null, CLR сгенерирует исключение NullReferenceException. Из-за этой дополнительной проверки инструкция callvirt выполняется немного медленнее, чем call. Проверка на null выполняется даже при вызове невиртуального экземплярного метода.
Давайте посмотрим, как эти инструкции используются в С#.
using System;
public sealed class Program { public static void Main() {
Console.WriteLine(); // Вызов статического метода
Object о = new ObjectQ;
o.GetHashCode(); // Вызов виртуального экземплярного метода
o.GetTypeQ; // Вызов невиртуального экземплярного метода
}
}
После компиляции результирующий IL-код выглядит следующим образом.
.method public hidebysig static void MainQ cil managed {
.entrypoint
// Code size 26 (0xla)
.maxstack 1
.locals init (object o)
IL_0000: call void System.Console::WriteLine()
IL_0005: newobj instance void System.Object::,ctor()
IL_000a: stloc.0 IL_000b: ldloc.0
IL_000c: callvirt instance int32 System.Object::GetHashCode()
IL_0011: pop IL_0012: ldloc.0
IL_0013: callvirt instance class System.Type System.Object::GetType()
IL_0018: pop
IL0019: ret
} // end of method Program::Main
Поскольку метод WriteLine является статическим, компилятор C# использует для его вызова инструкцию call. Для вызова виртуального метода GetHashCode применяется инструкция callvirt. Наконец, метод GetType также вызывается с помощью инструкции callvirt. Это выглядит странно, поскольку метод GetType невиртуальный. Тем не менее код работает, потому что во время JIT-компиляции CLR знает, что GetType — это невиртуальный метод, и вызывает его невиртуально.
Разумеется, возникает вопрос: почему компилятор C# не использует инструкцию call? Разработчики C# решили, что JIT-компилятор должен генерировать код, который проверяет, не равен ли null вызывающий объект. Поэтому вызовы невиртуальных экземплярных методов выполняются чуть медленнее, чем могли бы - а также то, что следующий код в C# вызовет исключение NullReferenceException, хотя в некоторых языках все работает отлично, using System;
public sealed class Program {
public Int32 GetFiveQ { return 5; } public static void Main() {
Program p = null;
Int32 x = p.GetFiveQ; // В C# выдается NullReferenceException
Теоретически с этим кодом все в порядке. Хотя переменная р равна null, для вызова невиртуального метода Get Five среде CLR необходимо узнать только тип р, а это Program. При вызове GetFive аргумент this равен null, но в методе GetFive он не используется, поэтому исключения нет. Однако компилятор C# вместо инструкции call вставляет callvirt, поэтому выполнение кода приведет к выдаче исключения NullReferenceException.
ВНИМАНИЕ
Если методопределен как невиртуальный, не рекомендуется вдальнейшемделатьего виртуальным. Причина в том, что некоторые компиляторы для вызова невиртуального метода используют инструкцию call вместо callvirt. Если метод сделать виртуальным и не перекомпилировать ссылающийся на него код, виртуальный метод будет вызван невиртуально, в результате приложение может повести себя непредсказуемо. Если код, содержащий вызов, написан на С#, все пройдет нормально, поскольку в C# все экземплярные методы вызываются с помощью инструкции callvirt. Flo если код написан на другом языке, возможны проблемы.
Иногда компилятор вместо callvirt использует для вызова виртуального метода команду call. Такое поведение выглядит странно, но следующий пример показывает, почему это действительно бывает необходимо, internal class SomeClass {
// ToString - виртуальный метод базового класса Object public override String ToStringO {
// Компилятор использует команду call для невиртуального вызова // метода ToString класса Object
// Если бы компилятор вместо call использовал callvirt, этот
// метод продолжал бы рекурсивно вызывать сам себя до переполнения стека
return base.ToString();
}
}
При вызове виртуального метода base. ToString компилятор C# вставляет команду call, чтобы метод ToString базового типа вызывался невиртуально. Это необходимо, ведь если ToString вызвать виртуально, вызов будет выполняться рекурсивно до переполнения стека потока что, разумеется, нежелательно.
Компиляторы стремятся использовать команду call при вызове методов, определенных значимыми типами, поскольку они запечатаны. В этом случае полиморфизм невозможен даже для виртуальных методов, и вызов выполняется быстрее. Кроме того, сама природа экземпляра значимого типа гарантирует, что он никогда не будет равен null, поэтому исключение NullReferenceException не возникнет. Наконец, для виртуального вызова виртуального метода значимого типа CLR необходимо получить ссылку на объект значимого типа, чтобы воспользоваться его таблицей методов, а это требует упаковки значимого типа. Упаковка повышает нагрузку на кучу, увеличивая частоту сборки мусора и снижая производительность.
Независимо от используемой для вызова экземплярного или виртуального метода инструкции — call или callvirt — эти методы всегда в первом параметре получают скрытый аргумент this, ссылающийся на объект, с которым производятся действия.
При проектировании типа следует стремиться свести к минимуму количество виртуальных методов. Во-первых, виртуальный метод вызывается медленнее невиртуального. Во-вторых, JIT-компилятор не может подставлять (inline) виртуальные методы, что также ухудшает производительность. В-третьих, как показано далее, виртуальные методы затрудняют управление версиями компонентов. В-четвертых, при определении базового типа часто создается набор перегруженных методов. Чтобы сделать их полиморфными, лучше всего сделать наиболее сложный метод виртуальным, оставив другие методы невиртуальными. Кстати, соблюдение этого правила поможет управлять версиями компонентов, не нарушая работу производных типов. Приведем пример:
public class Set {
private Int32 m_length = 0;
// Этот перегруженный метод - невиртуальный public Int32 Find(ObJect value) { return Find(value, 0, mlength);
}
// Этот перегруженный метод - невиртуальный public Int32 Find(ObJect value, Int32 startlndex) { return Find(value, startlndex, m_length startlndex);
}
// Наиболее функциональный метод сделан виртуальным // и может быть переопределен
public virtual Int32 Find(Object value, Int32 startlndex, Int32 endlndex) {
// Здесь находится настоящая реализация, которую можно переопределить...
>
// Другие методы
>
Разумное использование видимости типов и модификаторов доступа к членам
В .NET Framework приложения состоят из типов, определенных в многочисленных сборках, созданных различными компаниями. Это означает практически полное отсутствие контроля над используемыми компонентами и типами. Разработчику обычно недоступен исходный код компонентов (он может даже не знать, на каком языке они написаны), к тому же версии компонентов обновляются в разное время. Более того, из-за полиморфизма и наличия защищенных членов разработчик базового класса должен доверять коду разработчика производного класса. В свою очередь, разработчик производного класса должен доверять коду, наследуемому от
базового класса. Это лишь часть ограничений, с которыми приходится сталкиваться при разработке компонентов и типов.
В этом разделе я расскажу о том, как проектировать типы с учетом этих факторов. А если говорить конкретно, речь пойдет о том, как правильно задавать видимость типов и модификаторы доступа к членам.
В первую очередь при определении нового типа компиляторам следовало бы по умолчанию делать его запечатанным. Вместо этого большинство компиляторов (в том числе С#) поступают как раз наоборот, считая, что программист при необходимости сам может запечатать класс с помощью ключевого слова sealed. Было бы неплохо, если бы неправильное, на мой взгляд, поведение, предлагаемое по умолчанию, в следующих версиях компиляторов изменилось. Есть три веские причины в пользу использования запечатанных классов.
□ Управление версиями. Если класс изначально запечатан, его впоследствии можно сделать незапечатанным, не нарушая совместимости. Однако обратное невозможно, поскольку это нарушило бы работу всех производных классов. Кроме того, если в незапечатанном классе определены незапечатанные виртуальные методы, необходимо сохранять порядок вызова виртуальных методов в новых версиях, иначе в будущем возникнут проблемы с производными типами.
□ Производительность. Как уже отмечалось, невиртуальные методы вызываются быстрее виртуальных, поскольку для последних CLR во время выполнения проверяет тип объекта, чтобы выяснить, где находится метод. Однако, встретив вызов виртуального метода в запечатанном типе, JIT-компилятор может сгенерировать более эффективный код, задействовав невиртуальный вызов. Это возможно потому, что у запечатанного класса не может быть производных классов. Например, в следующем коде JIT-компилятор может вызвать виртуальный метод ToStning невиртуально:
using System;
public sealed class Point { private Int32 m_x, my;
public Point(Int32 x, Int32 y) { m_x = x; m_y = y; }
public override String ToStringO {
return String.Format("({0}, {1})", m_x, m_y);
}
public static void Main() {
Point p = new Point(3, 4);
// Компилятор C# вставит здесь инструкцию callvirt,
// но 31Т-компилятор оптимизирует этот вызов и сгенерирует код // для невиртуального вызова ToString,
// поскольку р имеет тип Point, являющийся запечатанным Console.WriteLine(р.ToStгing());
}
□ Безопасность и предсказуемость. Состояние класса должно быть надежно защищено. Если класс не запечатан, производный класс может изменить его состояние, воспользовавшись незащищенными полями или методами базового класса, изменяющими его доступные незакрытые поля. Кроме того, в производном классе можно переопределить виртуальные методы и не вызывать реализацию соответствующих методов базового класса. Назначая метод, свойство и событие виртуальным, базовый класс уступает некоторую степень контроля над его поведением и состоянием производному классу, что при неумелом обращении может вызвать непредсказуемое поведение и проблемы с безопасностью.
Беда в том, что запечатанные классы могут создать изрядные неудобства для пользователей типа. Разработчику приложения может понадобиться производный тип, в котором будут добавлены дополнительные поля или другая информация о состоянии. Они даже могут попытаться добавить в производном типе дополнительные методы для работы с этими полями. Хотя CLR не предоставляет механизма расширения уже построенных типов вспомогательными методами или полями, вспомогательные методы можно имитировать при помощи методов расширения C# (см. главу 8), а для расширения состояния объекта может использоваться класс ConditionalWeakTable (см. главу 21).
Вот несколько правил, которым я следую при проектировании классов:
□ Если класс не предназначен для наследования, я всегда явно объявляю его запечатанным. Как уже отмечалось, C# и многие современные компиляторы поступают иначе. Если нет необходимости в предоставлении другим сборкам доступа к классу, он объявляется внутренним. К счастью, именно так ведет себя по умолчанию компилятор С#. Если я хочу определить класс, предназначенный для создания производных классов, одновременно запретив его специализацию, я должен переопределить и запечатать все виртуальные методы, которые наследует мой класс.
□ Все поля данных класса всегда объявляются закрытыми, и в этом я никогда не уступлю. К счастью, по умолчанию C# поступает именно так. Вообще говоря, я бы предпочел, чтобы в C# остались только закрытые поля, а объявлять их со спецификаторами protected, internal, public и т. д. было бы запрещено. Доступ к состоянию объекта — верный путь к непредсказуемому поведению и проблемам с безопасностью. При объявлении полей внутренними (internal) также могут возникнуть проблемы, поскольку даже внутри одной сборки очень трудно отследить все обращения к полям, особенно когда над ней работает несколько разработчиков.
□ Методы, свойства и события класса я всегда объявляю закрытыми и невиртуальными. К счастью, C# по умолчанию делает именно так. Разумеется, чтобы типом можно было воспользоваться, некоторые методы, свойства и события должны быть открытыми, но лучше не делать их защищенными или внутренними, поскольку это может сделать тип уязвимым. Впрочем, защищенный или внутренний член все-таки лучше виртуального, поскольку последний предоставляет производному классу большие возможности и всецело зависит от корректности его поведения.
□ В ООП есть проверенный временем принцип: «лучший метод борьбы со сложностью — добавление новых типов». Если реализация алгоритма чрезмерно усложняется, следует определить вспомогательные типы, инкапсулирующие часть функциональности. Если вспомогательные типы используются в единственном супертипе, следует сделать их вложенными. Это позволит ссылаться на них через супертип и позволит им обращаться к защищенным членам супертипа. Однако существует правило проектирования, примененное в утилите FxCopCmd. exe Visual Studio и рекомендующее определять общедоступные вложенные типы в области видимости файла или сборки (за пределами супертипа), поскольку некоторые разработчики считают синтаксис обращения к вложенным типам громоздким. Я соблюдаю это правило, и никогда не определяю открытые вложенные типы.
Работа с виртуальными методами при управлении версиями типов
Как уже отмечалось, управление версиями — важный аспект компонентного программирования. Некоторых проблем я коснулся в главе 3 (там речь шла о сборках со строгими именами и обсуждались меры, позволяющие администраторам гарантировать привязку приложения именно к тем сборкам, с которыми оно было построено и протестировано). Однако при управлении версиями возникают и другие сложности с совместимостью на уровне исходного кода. В частности, следует быть очень осторожными при добавлении и изменении членов базового типа. Рассмотрим несколько примеров.
Пусть разработчиками компании CompanyA спроектирован тип Phone:
namespace CompanyA { public class Phone { public void Dial() {
Console.Write Line("Phone.Dial");
// Выполнить действия по набору телефонного номера
}
}
}
А теперь представьте, что в компании CompanyB спроектировали другой тип, BettenPhone, использующий тип Phone в качестве базового:
namespace CompanyB {
public class BetterPhone : CompanyA.Phone { public void Dial() {
Console.Write Line("BetterPhone.Dial");
EstablishConnectionQ;
продолжение &
base.Dial();
}
protected virtual void EstablishConnection() {
Console.WriteLine("BetterPhone.EstablishConnection"); // Выполнить действия по набору телефонного номера
}
}
}
При попытке скомпилировать свой код разработчики компании CompanyB получают от компилятора C# предупреждение:
warning CS0108: 'CompanyB.BetterPhone.Dial()' hides inherited member
'CompanyA.Phone.Dial()'. Use the new keyword if hiding was intended.
Смысл в том, что метод Dial, определяемый в типе BetterPhone, скроет одноименный метод в Phone. В новой версии метода Dial его семантика может стать совсем иной, нежели та, что определена программистами компании CompanyA в исходной версии метода.
Предупреждение о таких потенциальных семантических несоответствиях — очень полезная функция компилятора. Компилятор также подсказывает, как избавиться от этого предупреждения: нужно поставить ключевое слово new перед определением метода Dial в классе BetterPhone. Вот как выглядит исправленный класс BetterPhone:
namespace CompanyB {
public class BetterPhone : CompanyA.Phone {
// Этот метод Dial никак не связан с одноименным методом класса Phone public new void Dial() {
Console.WriteLine("BetterPhone.Dial");
EstablishConnection(); base.Dial();
}
protected virtual void EstablishConnection() {
Console.WriteLine("BetterPhone.EstablishConnection");
// Выполнить действия по установлению соединения
}
}
}
Теперь компания CompanyB может использовать в своем приложении тип BetterPhone следующим образом:
public sealed class Program { public static void Main() {
CompanyB.BetterPhone phone = new CompanyB.BetterPhone(); phone.Dial();
>
При выполнении этого кода выводится следующая информация:
BetterPhone.Dial BetterPhone.EstablishConnection Phone.Dial
Результат свидетельствует о том, что код выполняет именно те действия, которые нужны компании CompanyB. При вызове Dial вызывается новая версия этого метода, определенная в типе BetterPhone. Она сначала вызывает виртуальный метод EstablishConnection, а затем — исходную версию метода Dial из базового типа Phone.
А теперь представим, что несколько компаний решили использовать тип Phone, созданный в компании CompanyA. Допустим также, что все они сочли полезным установление соединения в самом методе Dial. Эти отзывы заставили разработчиков компании CompanyA усовершенствовать класс Phone:
namespace CompanyA { public class Phone { public void Dial() {
Console.WriteLine("Phone.Dial");
EstablishConnectionQ;
// Выполнить действия по набору телефонного номера
}
protected virtual void EstablishConnection() {
Console.Write Line("Phone.EstablishConnection");
// Выполнить действия по установлению соединения
}
}
}
В результате теперь разработчики компании CompanyB при компиляции своего типа BetterPhone (производного от новой версии Phone) получают следующее предупреждение:
warning CS0114: 'BetterPhone.EstablishConnectionQ' hides inherited member
'Phone.EstablishConnectionQ'. To make the current member override that implementation, add the override keyword. Otherwise, add the new keyword
В нем говорится о том, что ' BetterPhone. EstablishConnection ()' скрывает унаследованный член ' Phone. EstablishConnection()', и чтобы текущий член переопределил реализацию, нужно вставить ключевое слово override; в противном случае нужно вставить ключевое слово new.
То есть компилятор предупреждает, что как Phone, так и BetterPhone предлагают метод EstablishConnection, семантика которого может отличаться в разных классах. В этом случае простая перекомпиляция BetterPhone больше не может гарантировать, что новая версия метода будет работать так же, как прежняя, определенная в типе Phone.
Если в компании CompanyB решат, что семантика метода EstablishConnection в этих двух типах отличается, компилятору будет указано, что «правильными» являются методы Dial и EstablishConnection, определенные в BetterPhone, и они не связаны с одноименными методами из базового типа Phone. Для этого разработчики компании CompanyB добавляют ключевое слово new в определение EstablishConnection:
namespace CompanyB {
public class BetterPhone : CompanyA.Phone {
// Ключевое слово 'new' оставлено, чтобы указать,
// что этот метод не связан с методом Dial базового типа public new void Dial() {
Console.Write Line("BetterPhone. Dial");
EstablishConnectionQ; base.Dial();
}
// Ключевое слово 'new' указывает, что этот метод
// не связан с методом EstablishConnection базового типа
protected new virtual void EstablishConnectionQ {
Console.Write Line("BetterPhone.EstablishConnection");
// Выполнить действия для установления соединения
}
}
}
Здесь ключевое слово new заставляет компилятор сгенерировать метаданные, информирующие CLR, что определенные в BetterPhone методы Dial и EstablishConnection следует рассматривать как новые функции, введенные в этом типе. При этом CLR будет известно, что одноименные методы типов Phone и BetterPhone никак не связаны.
При выполнении того же приложения (метода Main) выводится информация:
BetterPhone.Dial BetterPhone.EstablishConnection Phone.Dial
Phone.EstablishConnection
Отсюда видно, что, когда Main обращается к методу Dial, вызывается версия, определенная в BetterPhone. Далее Dial вызывает виртуальный метод EstablishConnection, также определенный в BetterPhone. Когда метод EstablishConnection типа BetterPhone возвращает управление, вызывается метод Dial типа Phone, вызывающий метод EstablishConnection этого типа. Но поскольку метод EstablishConnection в типе BetterPhone помечен ключевым словом new, вызов этого метода не считается переопределением виртуального метода EstablishConnection, исходно определенного в типе Phone. В результате метод Dial типа Phone вызывает метод EstablishConnection, определенный в типе Phone, что и требовалось от программы.
ПРИМЕЧАНИЕ
Если бы компилятор по умолчанию считал методы переопределениями (как C++), разработчики типа BetterPhone не смогли бы использовать в нем имена методов Dial и EstablishConnection. Вероятно, при изменении имен этих методов негативный эффект затронет всю кодовую базу, нарушая совместимость на уровне исходного текста и двоичного кода. Обычно такого рода изменения с далеко идущими последствиями нежелательны, особенно в средних и крупных проектах. Однако если изменение имени метода коснется лишь необходимости обновления исходного текста, следует пойти на это, чтобы одинаковые имена методов Dial и EstablishConnection, обладающие разной семантикой в разных типах, не вводили в заблуждение других разработчиков.
Альтернативное решение: CompanyB, получив от CompanyA новую версию типа Phone, решает, что текущая семантика методов Dial и EstablishConnection типа Phone — это именно то, что нужно. В этом случае в CompanyB полностью удаляют метод Dial из типа BetterPhone. Поскольку теперь разработчикам CompanyB нужно указать компилятору, что метод EstablishConnection типа BetterPhone связан с одноименным методом типа Phone, нужно удалить из его определения ключевое слово new. Удаления ключевого слова недостаточно, так как компилятор не поймет предназначения метода EstablishConnection типа BetterPhone. Чтобы выразить намерения явно, разработчик из CompanyB должен изменить модификатор определенного в типе BetterPhone метода EstablishConnection с virtual на override. Код новой версии BetterPhone выглядит так:
namespace CompanyB {
public class BetterPhone : CompanyA.Phone {
// Метод Dial удален (так как он наследуется от базового типа)
// Здесь ключевое слово new удалено, а модификатор virtual заменен // на override, чтобы указать, что этот метод связан с методом // EstablishConnection из базового типа protected override void EstablishConnectionQ {
Console.Write Line("BetterPhone.EstablishConnection");
П Выполнить действия по установлению соединения
}
}
Теперь то же приложение (метод Main) выводит следующий результат:
Phone.Dial
BetterPhone.EstablishConnection
Видно, что когда Main вызывает метод Dial, вызывается версия этого метода, определенная в типе Phone и унаследованная от него типом BetterPhone. Далее, когда метод Dial, определенный в типе Phone, вызывает виртуальный метод EstablishConnection, вызывается одноименный метод типа BetterPhone, так как он переопределяет виртуальный метод EstablishConnection, определяемый типом Phone.
Глава 7. Константы и поля
В этой главе показано, как добавить к типу члены, содержащие данные. В частности, мы рассмотрим константы и поля.
Константы
Константа (constant) — это идентификатор, значение которого никогда не меняется. Значение, связанное с именем константы, должно определяться во время компиляции. Затем компилятор сохраняет значение константы в метаданных модуля. Это значит, что константы можно определять только для таких типов, которые компилятор считает примитивными. В C# следующие типы считаются примитивными и могут использоваться для определения констант: Boolean, Char, Byte, SByte, Intl6, UIntl6, Int32, UInt32, Int64, UInt64, Single, Double, Decimal и String. Тем не менее C# позволяет определить константную переменную, не относящуюся к элементарному типу, если присвоить ей значение null:
using System;
public sealed class SomeType {
// Некоторые типы не являются элементарными, но C# допускает существование // константных переменных этих типов после присваивания значения null public const SomeType Empty = null;
}
Так как значение констант никогда не меняется, константы всегда считаются частью типа. Иначе говоря, константы считаются статическими, а не экземпляр- ными членами. Определение константы приводит в конечном итоге к созданию метаданных.
Встретив в исходном тексте имя константы, компилятор просматривает метаданные модуля, в котором она определена, извлекает значение константы и внедряет его в генерируемый им IL-код. Поскольку значение константы внедряется прямо в код, в период выполнения память для констант не выделяется. Кроме того, нельзя получать адрес константы и передавать ее по ссылке. Эти ограничения также означают, что изменять значения константы в разных версиях модуля нельзя, поэтому константу надо использовать, только когда точно известно, что ее значение никогда не изменится (хороший пример — определение константы Maxlntl6 со значением 32767). Поясню на примере, что я имею в виду. Возьмем код и скомпилируем его в DLL-сборку:
using System;
public sealed class SomeLibraryType {
// ПРИМЕЧАНИЕ: C# не позволяет использовать для констант модификатор // static, поскольку всегда подразумевается, что константы являются // статическими
public const Int32 MaxEntriesInList = 50;
}
Затем построим сборку приложения из следующего кода:
using System;
public sealed class Program { public static void Main() {
Console.WriteLine("Max entries supported in list: "
+ SomeLibraryType.MaxEntriesInList);
}
}
Нетрудно заметить, что код приложения содержит ссылку на константу MaxEntriesInList. При компоновке этого кода компилятор, обнаружив, что MaxEntriesInList — это литерал константы со значением 50, внедрит значение 50 типа Int32 прямо в IL-код приложения. Фактически после построения кода приложения DLL-сборка даже не будет загружаться в период выполнения, поэтому ее можно просто удалить с диска.
.method public hidebysig static void Main() cil managed
{
. entrypoint
// Code size 25 (0x19)
.maxstack 8 IL0000: nop
IL0001: ldstr "Max entries supported in list: "
IL_0006: ldc.i4.s 50
IL_0008: box [mscorlib]System.Int32
IL_000d: call string [mscorlib]System.String::Concat(object, object)
IL_0012: call void [mscorlib]System.Console::WriteLine(string)
IL_0017: nop IL_0018: ret
} // Закрываем метод Program::Main
Теперь проблема управления версиями при использовании констант должна стать очевидной. Если разработчик изменит значение константы MaxEntriesInList на 1000 и перестроит только DLL-сборку, это не повлияет на код самого приложения. Для того чтобы в приложении использовалось новое значение константы, его тоже необходимо перекомпилировать. Нельзя применять константы во время выполнения (а не во время компиляции), если модуль должен задействовать значение, определенное в другом модуле. В этом случае вместо констант следует использовать предназначенные только для чтения поля, о которых речь идет в следующем разделе.
Поля
Поле (field) — это член данных, который хранит экземпляр значимого типа или ссылку на ссылочный тип. В табл. 7.1 приведены модификаторы, применяемые по отношению к полям.
| Таблица 7.1. Модификаторы полей
|
|
|
Как видно из таблицы, общеязыковая среда (CLR) поддерживает поля как типов (статические), так и экземпляров (нестатические). Динамическая память для хранения поля типа выделяется в пределах объекта типа, который создается при загрузке типа в домен приложений (см. главу 22), что обычно происходит при JIT-компиляции любого метода, ссылающегося на этот тип. Динамическая память для хранения экземплярных полей выделяется при создании экземпляра данного типа.
Поскольку поля хранятся в динамической памяти, их значения можно получить лишь в период выполнения. Поля также решают проблему управления версиями, возникающую при использовании констант. Кроме того, полю можно назначить любой тип данных, поэтому при определении полей можно не ограничиваться встроенными элементарными типами компилятора (что приходится делать при определении констант).
CLR поддерживает поля, предназначенные для чтения и записи (изменяемые), а также поля, предназначенные только для чтения (неизменяемые). Большинство полей изменяемые. Это значит, что во время исполнения кода значение таких полей может многократно меняться. Данные же в неизменяемые поля можно записывать только при исполнении конструктора (который вызывается лишь раз — при создании объекта). Компилятор и механизм верификации гарантируют, что ни один
метод, кроме конструктора, не сможет записать данные в поле, предназначенное только для чтения. Замечу, что для изменения такого поля можно задействовать отражение.
Попробуем решить проблему управления версиями в примере из раздела «Константы», используя статические неизменяемые поля. Вот новая версия кода DLL-сборки:
using System;
public sealed class SomeLibraryType {
// Модификатор static необходим, чтобы поле // ассоциировалось с типом, а не экземпляром public static readonly Int32 MaxEntriesInList = 50;
}
Это единственное изменение, которое придется внести в исходный текст, при этом код приложения можно вовсе не менять, но чтобы увидеть его новые свойства, его придется перекомпилировать. Теперь при исполнении метода Main этого приложения CLR загружает DLL-сборку (так как она требуется во время выполнения) и извлекает значение поля MaxEntriesInList из динамической памяти, выделенной для его хранения. Естественно, это значение равно 50.
Допустим, разработчик сборки изменил значение поля с 50 на 1000 и скомпоновал сборку заново. При повторном исполнении код приложения автоматически задействует новое значение — 1000. В этом случае не обязательно компоновать код приложения заново, оно просто работает в том виде, в котором было (хотя и чуть медленнее). Однако этот сценарий предполагает, что у новой сборки нет строгого имени, а политика управления версиями приложения заставляет CLR загружать именно эту новую версию сборки.
В следующем примере показано, как определять изменяемые статические поля, а также изменяемые и неизменяемые экземплярные поля:
public sealed class SomeType {
// Статическое неизменяемое поле. Его значение рассчитывается
// и сохраняется в памяти при инициализации класса во время выполнения
public static readonly Random srandom = new Random();
// Статическое изменяемое поле
private static Int32 snumberOfWrites = 0;
// Неизменяемое экземплярное поле
public readonly String Pathname = "Untitled";
// Изменяемое экземплярное поле private System.10.FileStream m_fs;
public SomeType(String pathname) {
// Эта строка изменяет значение неизменяемого поля
//В данном случае это возможно, так как показанный далее код
// расположен в конструкторе
продолжение &
this.Pathname = pathname;
}
public String DoSomething() {
11 Эта строка читает и записывает значение статического изменяемого поля s_numberOfWrites = s_numberOfWrites + 1;
// Эта строка читает значение неизменяемого экземплярного поля return Pathname;
}
}
Многие поля в нашем примере инициализируются на месте (inline). C# позволяет использовать этот удобный синтаксис для инициализации констант, а также изменяемых и неизменяемых полей. Как продемонстрировано в главе 8, C# рассматривает инициализацию поля на месте как синтаксис сокращенной записи, позволяющий инициализировать поле во время исполнения конструктора. Вместе с тем, в C# возможны проблемы производительности, которые нужно учитывать при использовании синтаксиса инициализации поля на месте, а не присвоения в конструкторе. Они также обсуждаются в главе 8.
ВНИМАНИЕ
Неизменность поля ссылочного типа означает неизменность ссылки, которую этот тип содержит, а вовсе не объекта, на которую указывает ссылка, например:
public sealed class АТуре {
// InvalidChars всегда ссылается на один объект массива
public static readonly Char[] InvalidChars = new Char[] { 'A', 'B', 'C'};
}
public sealed class AnotherType { public static void M() {
// Следующие строки кода вполне корректны, компилируются // и успешно изменяют символы в массиве InvalidChars АТуре.InvalidChars[0] = 'X';
АТуре.InvalidChars[l] = 'Y';
АТуре.InvalidChars[2] = ' Z';
// Следующая строка некорректна и не скомпилируется,
// так как ссылка InvalidChars изменяться не может АТуре.InvalidChars = new Char[] { 'X', 'Y', 'Z' };
}
}
Глава 8. Методы
В этой главе обсуждаются разновидности методов, которые могут определяться в типе, и разбирается ряд вопросов, касающихся методов. В частности, показано, как определяются методы-конструкторы (создающие экземпляры типов и сами типы), методы перегрузки операторов и методы преобразования (выполняющие явное и неявное приведение типов). Также речь пойдет о методах расширения, позволяющих добавлять собственные методы к уже существующим типам, и частичных методах, позволяющих разделить реализацию типа на несколько частей.
Конструкторы экземпляров и классы (ссылочные типы)
Конструкторы — это специальные методы, позволяющие корректно инициализировать новый экземпляр типа. В таблице определений, входящих в метаданные, методы-конструкторы всегда отмечают сочетанием . ctor (от constructor). При создании экземпляра объекта ссылочного типа выделяется память для полей данных экземпляра и инициализируются служебные поля (указатель на объект-тип и индекс блока синхронизации), после чего вызывается конструктор экземпляра, устанавливающий исходное состояние нового объекта.
При конструировании объекта ссылочного типа выделяемая для него память всегда обнуляется до вызова конструктора экземпляра типа. Любые поля, не задаваемые конструктором явно, гарантированно содержат 0 или null.
В отличие от других методов конструкторы экземпляров не наследуются. Иначе говоря, у класса есть только те конструкторы экземпляров, которые определены в этом классе. Невозможность наследования означает, что к конструктору экземпляров нельзя применять модификаторы virtual, new, override, sealed и abstract. Если определить класс без явно заданных конструкторов, многие компиляторы (в том числе компилятор С#) создадут конструктор по умолчанию (без параметров), реализация которого просто вызывает конструктор без параметров базового класса. Например, рассмотрим следующее определение класса:
public class SomeType { }
Это определение идентично определению:
public class SomeType {
public SomeTypeQ : base() { }
Для абстрактных классов компилятор создает конструктор по умолчанию с модификатором protected, в противном случае область действия будет открытой (public). Если в базовом классе нет конструктора без параметров, производный класс должен явно вызвать конструктор базового класса, иначе компилятор вернет ошибку. Для статических классов (запечатанных и абстрактных) компилятор не создает конструктор по умолчанию.
В типе может определяться несколько конструкторов, при этом сигнатуры и уровни доступа к конструкторам обязательно должны отличаться. В случае верифицируемого кода конструктор экземпляров должен вызывать конструктор базового класса до обращения к какому-либо из унаследованных от него полей. Многие компиляторы, включая С#, генерируют вызов конструктора базового класса автоматически, поэтому вам, как правило, об этом можно не беспокоиться. В конечном счете всегда вызывается открытый конструктор объекта System. Object без параметров. Этот конструктор ничего не делает — просто возвращает управление по той простой причине, что в System. Object не определено никаких экзем плярных полей данных, поэтому конструктору просто нечего делать.
В редких ситуациях экземпляр типа может создаваться без вызова конструктора экземпляров. В частности, метод MemberwiseClone объекта Object выделяет память, инициализирует служебные поля объекта, а затем копирует байты исходного объекта в область памяти, выделенную для нового объекта. Кроме того, конструктор обычно не вызывается при десериализации объекта. Код десериализации выделяет память для объекта без вызова конструктора, используя метод GetUninitializedObject KnnGetSafellninitializedObject типа System. Runtime. Serialization.FormatterServices (см. главу 24).
ВНИМАНИЕ
Нельзя вызывать какие-либо виртуальные методы конструктора, которые могут повлиять на создаваемый объект. Причина проста: если вызываемый виртуальный метод переопределен в типе, экземпляр которого создается, происходит реализация производного типа, но к этому моменту еще не завершилась инициализация всех полей в иерархии. В таких обстоятельствах последствия вызова виртуального метода непредсказуемы.
C# предлагает простой синтаксис, позволяющий инициализировать поля во время создания объекта ссылочного типа:
internal sealed class SomeType { private Int32 m_x = 5;
}
При создании объекта SomeType его поле m_x инициализируется значением 5. Вы можете спросить: как это происходит? Изучив IL-код метода-конструктора этого объекта (этот метод также фигурирует под именем . ctor), вы увидите следующий код:
.method public hidebysig specialname rtspecialname
instance void .ctor() cil managed
{
// Code size 14 (0xe)
.maxstack 8 IL0000: ldarg.0 IL0001: ldc.i4.5
IL0002: stfld int32 SomeType::m_x IL_0007: ldarg.0
IL_0008: call instance void [mscorlib]System.Object::.ctor()
IL_000d: ret
} // end of method SomeTypector
Как видите, конструктор объекта SomeType содержит код, записывающий в поле т_х значение 5 и вызывающий конструктор базового класса. Иначе говоря, компилятор C# предлагает удобный синтаксис, позволяющий инициализировать поля экземпляра при их объявлении. Компилятор транслирует этот синтаксис в метод- конструктор, выполняющий инициализацию. Это значит, что нужно быть готовым к разрастанию кода, как это показано на следующем примере:
internal sealed class SomeType { private Int32 m_x = 5; private String m_s = "Hi there"; private Double m_d = 3.14159; private Byte mb;
// Это конструкторы
public SomeTypeQ { ... }
public SomeType(Int32 x) { ... }
public SomeType(String s) { ...; m_d = 10; }
1
Генерируя I L-код для трех методов-конструкторов из этого примера, компилятор помещает в начало каждого из методов код, инициализирующий поля m_x, m_s и m_d. После кода инициализации вставляется вызов конструктора базового класса, а затем добавляется код, расположенный внутри методов-конструкторов. Например, IL-код, сгенерированный для конструктора с параметром типа String, состоит из кода, инициализирующего поля m_x, m_s и m_d, и кода, перезаписывающего поле m_d значением 10. Заметьте: полет_Ь гарантированно инициализируется значением 0, даже если нет кода, инициализирующего это поле явно.
ПРИМЕЧАНИЕ
Компилятор инициализирует все поля при помощи соответствующего синтаксиса перед вызовом конструктора базового класса для поддержания представления о том, что все поля имеют корректные значения, обозначенные в исходном коде. Потенциальная проблема может возникнуть в тех случаях, когда конструктор базового класса вызывает виртуальный метод, осуществляющий обратный вызов в метод, определенный в производном классе. В этом случае поля инициализируются при помощи соответствующего синтаксиса перед вызовом виртуального метода.
Поскольку в показанном ранее классе определены три конструктора, компилятор трижды генерирует код, инициализирующий поля m_x, m_s и m_d: по одному разу для каждого из конструкторов. Если имеется несколько инициализируемых экземплярных полей и множество перегруженных методов-конструкторов, стоит подумать о том, чтобы определить поля без инициализации; создать единственный конструктор, выполняющий общую инициализацию, и заставить каждый метод- конструктор явно вызывать конструктор, выполняющий общую инициализацию. Этот подход позволит уменьшить размер генерируемого кода. Следующий пример иллюстрирует использование способности C# явно заставлять один конструктор вызывать другой конструктор посредством зарезервированного слова this:
internal sealed class SomeType {
// Здесь нет кода, явно инициализирующего поля
private Int32 m_x;
private String ms;
private Double m_d;
private Byte mb;
// Код этого конструктора инициализирует поля значениями по умолчанию // Этот конструктор должен вызываться всеми остальными конструкторами public SomeType() { m_x = 5;
m_s = "Hi there"; m_d = 3.14159; mb = 0xff;
}
// Этот конструктор инициализирует поля значениями по умолчанию,
// а затем изменяет значение т_х public SomeType(Int32 х) : this() { т_х = х;
}
// Этот конструктор инициализирует поля значениями по умолчанию,
// а затем изменяет значение m_s public SomeType(String s) : this() { m_s = s;
}
// Этот конструктор инициализирует поля значениями по умолчанию,
//а затем изменяет значения т_х и m_s public SomeType(Int32 х, String s) : this() { m_x = x; m_s = s;
}
Конструкторы экземпляров и структуры (значимые типы)
Конструкторы значимых типов (struct) работают иначе, чем ссылочных (class). CLR всегда разрешает создание экземпляров значимых типов и этому ничто не может помешать. Поэтому, по большому счету, конструкторы у значимого типа можно не определять. Фактически многие компиляторы (включая С#) не определяют для значимых типов конструкторы по умолчанию, не имеющие параметров. Разберем следующий код:
internal struct Point { public Int32 m_x, m_y;
>
internal sealed class Rectangle {
public Point m_topLeft, mbottomRight;
>
Для того чтобы создать объект Rectangle, надо использовать оператор new с указанием конструктора. В этом случае вызывается конструктор, автоматически сгенерированный компилятором С#. Память, выделенная для объекта Rectangle, включает место для двух экземпляров значимого типа Point. Из соображений повышения производительности CLR не пытается вызвать конструктор для каждого экземпляра значимого типа, содержащегося в объекте ссылочного типа. Однако, как отмечалось ранее, поля значимого типа инициализируются нулями/null.
Вообще говоря, CLR позволяет программистам определять конструкторы для значимых типов, но эти конструкторы выполняются лишь при наличии кода, явно вызывающего один из них, например, как в конструкторе объекта Rectangle:
internal struct Point { public Int32 m_x, my;
public Point(Int32 x, Int32 y) { m_x = x; m_y = y;
}
internal sealed class Rectangle {
public Point m_topl_eft, mbottomRight;
public Rectangle() {
// B C# оператор new, использованный для создания экземпляра значимого // типа, вызывает конструктор для инициализации полей значимого типа m_topLeft = new Point(l, 2); m_bottomRight = new Point(100, 200);
Конструктор экземпляра значимого типа выполняется только при явном вызове. Так что если конструктор объекта Rectangle не инициализировал его поля m_topLef t и m_bottomRight вызовом с помощью оператора new конструктора Point, поля ш_х и ш_у у обеих структур Point будут содержать 0.
Если значимый тип Point уже определен, то определяется конструктор, по умолчанию не имеющий параметров. Однако давайте перепишем наш код:
internal struct Point { public Int32 ni x, m_yj
public PointQ { m_x = m_y = 5;
}
}
internal sealed class Rectangle {
public Point mtopLeft, m_bottomRight;
public RectangleQ {
}
}
А теперь ответьте, какими значениями — 0 или 5 — будут инициализированы поля ш_х и ш_у, принадлежащие структурам Point (m_topLeft и m_bottomRight)? Предупреждаю, вопрос с подвохом.
Многие разработчики (особенно с опытом программирования на C++) решат, что компилятор C# поместит в конструктор Rectangle код, автоматически вызывающий конструктор структуры Point по умолчанию, не имеющий параметров, для двух полей Rectangle. Однако, чтобы повысить быстродействие приложения во время выполнения, компилятор C# не сгенерирует такой код автоматически. Фактически большинство компиляторов никогда не генерирует автоматически код для вызова конструктора по умолчанию для значимого типа даже при наличии конструктора без параметров. Чтобы принудительно исполнить конструктор значимого типа без параметров, разработчик должен добавить код его явного вызова.
С учетом сказанного можно ожидать, что поля т_х и т_у обеих структур Point из объекта Rectangle в показанном коде будут инициализированы нулевыми значениями, так как в этой программе нет явного вызова конструктора Point.
Но я же предупредил, что мой первый вопрос был с подвохом. Подвох в том, что C# не позволяет определять для значимого типа конструкторы без параметров. Поэтому показанный код на самом деле даже не компилируется. При попытке скомпилировать его компилятор C# генерирует сообщение об ошибке (ошибка CS0568: структура не может содержать явные конструкторы без параметров):
error CS0568: Structs cannot contain explicit parameterless constructors
C# преднамеренно запрещает определять конструкторы без параметров у значимых типов, чтобы не вводить разработчиков в заблуждение относительно того, какой конструктор вызывается. Если конструктор определить нельзя, компилятор никогда не будет автоматически генерировать код, вызывающий такой конструктор. В отсутствие конструктора без параметров поля значимого типа всегда инициализируются нулями/null.
ПРИМЕЧАНИЕ
В поля значимого типа обязательно заносятся значения 0 или null, если значимый тип вложен в объект ссылочного типа. Однако гарантии, что поля значимых типов, работающие со стеком, будут инициализированы значениями 0 или null, нет. Чтобы код был верифицируемым, перед чтением любого поля значимого типа, работающего со стеком, нужно записать в него значение. Если код сможет прочитать значение поля значимого типа до того, как туда будет записано какое-то значение, может нарушиться безопасность. C# и другие компиляторы, генерирующие верифицируемый код, гарантируют, что поля любых значимых типов, работающие со стеком, перед чтением обнуляются или хотя бы в них записываются некоторые значения. Поэтому при верификации во время выполнения исключение выдано не будет. Однако обычно можно предполагать, что поля значимых типов инициализируются нулевыми значениями, а все сказанное в этом примечании можно полностью игнорировать.
Хотя C# не допускает использования значимых типов с конструкторами без параметров, это допускает CLR. Так что если вас не беспокоят упомянутые скрытые особенности работы системы, можно на другом языке (например, на IL) определить собственный значимый тип с конструктором без параметров.
Поскольку C# не допускает использования значимых типов с конструкторами без параметров, при компиляции следующего типа компилятор сообщает об ошибке: (ошибка CS0573: 'SomeValType.m_x': нельзя создавать инициализаторы экземплярных полей в структурах):
error CS0573: 'SomeValType.m_x‘: cannot have instance field initializers in structs А вот как выглядит код, вызвавший эту ошибку:
internal struct SomeValType {
// В значимый тип нельзя подставлять инициализацию экземплярных полей private Int32 m_x = 5;
}
Кроме того, поскольку верифицируемый код перед чтением любого поля значимого типа требует записывать в него какое-либо значение, любой конструктор, определенный для значимого типа, должен инициализировать все поля этого типа. Следующий тип определяет конструктор для значимого типа, но не может инициализировать все его поля:
internal struct SomeValType { private Int32 m_x, m_y;
// C# допускает наличие у значимых типов конструкторов с параметрами public SomeValType(Int32 х) { m_x = х;
// Обратите внимание: поле т_у здесь не инициализируется
>
>
При компиляции этого типа компилятор C# генерирует сообщение об ошибке: (ошибка CS0171: поле 'SomeValType.m_y' должно быть полностью определено до возвращения управления конструктором):
error CS0171: Field ,SomeValType.m_y' must be fully assigned before control leaves the constructor
Чтобы разрешить проблему, конструктор должен ввести в поле у какое-нибудь значение (обычно 0).
В качестве альтернативного варианта можно инициализировать все поля значимого типа, как это сделано здесь:
// C# позволяет значимым типам иметь конструкторы с параметрами public SomeValType(Int32 х) {
// Выглядит необычно, но компилируется прекрасно,
// и все поля инициализируются значениями 0 или null
this = new SomeValType();
m_x = x; // Присваивает m_x значение x
// Обратите внимание, что поле m_y было инициализировано нулем
}
В конструкторе значимого типа this представляет экземпляр значимого типа и ему можно приписать значение нового экземпляра значимого типа, у которого все поля инициализированы нулями. В конструкторах ссылочного типа указатель this считается доступным только для чтения и присваивать ему значение нельзя.
Конструкторы типов
Помимо конструкторов экземпляров, CLR поддерживает конструкторы типов (также известные как статические конструкторы, конструкторы классов и инициализаторы типов). Конструкторы типов можно применять и к интерфейсам (хотя C# этого не допускает), ссылочным и значимым типам. Подобно тому, как конструкторы экземпляров используются для установки первоначального состояния экземпляра типа, конструкторы типов служат для установки первоначального состояния типа. По умолчанию у типа не определено конструктора. У типа не может быть более одного конструктора; кроме того, у конструкторов типов никогда не бывает параметров. Вот как определяются ссылочные и значимые типы с конструкторами в программах на С#:
internal sealed class SomeRefType { static SomeRefTypeQ {
// Исполняется при первом обращении к ссылочному типу SomeRefType
>
}
internal struct SomeValType {
// C# на самом деле допускает определять для значимых типов // конструкторы без параметров static SomeValType() {
// Исполняется при первом обращении к значимому типу SomeValType
}
I
Обратите внимание, что конструкторы типов определяют так же, как конструкторы экземпляров без параметров за исключением того, что их помечают как статические. Кроме того, конструкторы типов всегда должны быть закрытыми (C# делает их закрытыми автоматически). Однако если явно пометить в исходном тексте программы конструктор типа как закрытый (или как-то иначе), компилятор C# выведет сообщение об ошибке: (ошибка CS0515: 'SomeValType.Some-ValType() в статических конструкторах нельзя использовать модификаторы доступа):
error CS0515: "SomeValType.SomeValType()': access modifiers are not allowed on static constructors
Конструкторы типов всегда должны быть закрытыми, чтобы код разработчика не смог их вызвать, напротив, в то же время среда CLR всегда способна вызвать
конструктор типа.
ВНИМАНИЕ
Хотя конструктор типа можно определить в значимом типе, этого никогда не следует делать, так как иногда CLR не вызывает статический конструктор значимого типа.
Например:
internal struct SomeValType { static SomeValTypeQ {
Console.WriteLine("This never gets displayed");
}
public Int32 m_x;
}
public sealed class Program { public static void Main() {
SomeValType[] a = new SomeValType[10]; a[0].m_x = 123;
Console.WriteLine(a[0].m_x); // Выводится 123
}
} [8]
компилятор создает в IL-коде вызов конструктора типа. Если же код уже исполнялся, JIT-компилятор вызова конструктора типа не создает, так как «знает», что тип уже инициализирован.
Затем, после JIT-компиляции метода, начинается выполнение потока, и в конечном итоге очередь доходит до кода вызова конструктора типа. В реальности может оказаться, что несколько потоков одновременно начнут выполнять метод. CLR старается гарантировать, чтобы конструктор типа выполнялся только раз в каждом домене приложений. Для этого при вызове конструктора типа вызывающий поток в рамках синхронизации потоков получает исключающую блокировку. Это означает, что если несколько потоков одновременно попытаются вызывать конструктор типа, только один получит такую возможность, а остальные блокируются. Первый поток выполнит код статического конструктора. После выхода из конструктора первого потока «проснутся» простаивающие потоки и проверят, был ли выполнен конструктор. Они не станут снова выполнять код, а просто вернут управление из метода конструктора. Кроме того, при последующем вызове какого-либо из этих методов CLR будет «в курсе», что конструктор типа уже выполнялся, и не будет вызывать его снова.
ПРИМЕЧАНИЕ
Поскольку CLR гарантирует, что конструктор типа выполняется только однажды в каждом домене приложений, а также обеспечивает его безопасность по отношению к потокам, конструктор типа лучше всего подходит для инициализации всех объектов-одиночек (singleton), необходимых для существования типа.
В рамках одного потока возможна неприятная ситуация, когда существует два конструктора типа, содержащих перекрестно ссылающийся код. Например, конструктор типа ClassA содержит код, ссылающийся на ClassB, а последний содержит конструктор типа, ссылающийся на ClassA. Даже в таких условиях CLR заботится, чтобы код конструкторов типов выполнился лишь однажды, но исполняющая среда не в состоянии обеспечить завершение исполнения конструктора типа ClassA до начала исполнения конструктора типа ClassB. При написании кода следует избегать подобных ситуаций. В действительности, поскольку за вызов конструкторов типов отвечает CLR, не нужно писать код, который требует вызова конструкторов типов в определенном порядке.
Наконец, если конструктор типа генерирует необрабатываемое исключение, CLR считает такой тип непригодным. При попытке обращения к любому полю или методу такого типа возникает исключение System.TypelnitializationException.
Код конструктора типа может обращаться только к статическим полям типа; обычно это делается, чтобы их инициализировать. Как и в случае экземплярных полей, C# предлагает простой синтаксис:
internal sealed class SomeType {
private static Int32 s_x = 5;
ПРИМЕЧАНИЕ
C# не позволяет в значимых типах использовать синтаксис инициализации полей на месте, но разрешает это в статических полях. Иначе говоря, если в приведенном ранее коде заменить class на struct, код откомпилируется и будет работать, как задумано.
При компоновке этого кода компилятор автоматически генерирует конструктор типа SomeType. Иначе говоря, получается тот же эффект, как если бы этот код был написан следующим образом:
internal sealed class SomeType { private static Int32 s_x; static SomeTypeQ { s_x = 5; }
}
При помощи утилиты ILDasm.exe нетрудно проверить, какой код на самом деле сгенерировал компилятор. Для этого нужно изучить IL-код конструктора типа. В таблице определений методов, составляющей метаданные модуля, метод-конструктор типа всегда называется . ccton (от class constructor).
Из представленного далее IL-кода видно, что метод . cctor является закрытым и статическим. Заметьте также, что код этого метода действительно записывает в статическое поле s_x значение 5.
.method private hidebysig specialname rtspecialname static void .cctor() cil managed {
// Code size 7 (0x7)
.maxstack 8 IL0000: ldc.i4.5
IL0001: stsfld int32 SomeType::s_x IL0006: ret
} // end of method SomeType::.cctor
Конструктор типа не должен вызывать конструктор базового класса. Этот вызов не обязателен, так как ни одно статическое поле типа не используется совместно с базовым типом и не наследуется от него.
ПРИМЕЧАНИЕ
В ряде языков, таких как Java, предполагается, что при обращении ктипу будет вызван его конструктор, а также конструкторы всех его базовых типов. Кроме того, интерфейсы, реализованные этими типами, тоже должны вызывать свои конструкторы. CLR не поддерживает такую семантику, но позволяет компиляторам и разработчикам предоставлять поддержку подобной семантики через метод RunClassConstructor, предоставляемый типом System.Runtime.CompilerServices.RuntimeHelpers. Компилятор любого языка, требующего подобную семантику, генерирует в конструкторе типа код, вызывающий этот метод для всех базовых типов. При использовании метода RunClassConstructor для вызова конструктора типа CLR определяет, был ли он исполнен ранее, и если да, то не вызывает его снова.
В завершение этого раздела рассмотрим следующий код:
internal sealed class SomeType {
private static Int32 s_x = 5;
static SomeTypeQ { s_x = 10;
}
Здесь компилятор C# генерирует единственный метод-конструктор типа, который сначала инициализирует поле s_x значением 5, затем — значением 10. Иначе говоря, при генерации IL-кода конструктора типа компилятор C# сначала генерирует код, инициализирующий статические поля, затем обрабатывает явный код, содержащийся внутри метода-конструктора типа.
ВНИМАНИЕ
Иногда разработчики спрашивают меня: можно ли исполнить код во время выгрузки типа? Во-первых, следует знать, что типы выгружаются только при закрытии домена приложений. Когда домен приложений закрывается, объект, идентифицирующий тип, становится недоступным, и уборщик мусора освобождает занятую им память. Многим разработчикам такой сценарий дает основание полагать, что можно добавить к типу статический метод Finalize, автоматически вызываемый при выгрузке типа. Увы, CLR не поддерживает статические методы Finalize. Однако не все потеряно: если при закрытии домена приложений нужно исполнить некоторый код, можно зарегистрировать метод обратного вызова для события DomainUnload типа System.AppDomain.
Методы перегруженных операторов
В некоторых языках тип может определять, как операторы должны манипулировать его экземплярами. В частности, многие типы (например, System.String, System. Decimal и System.DateTime) используют перегрузку операторов равенства (==) и неравенства (! =). CLR ничего не известно о перегрузке операторов — ведь среда даже не знает, что такое оператор. Смысл операторов и код, который должен быть сгенерирован, когда тот или иной оператор встретится в исходном тексте, определяется языком программирования.
Например, если в программе на C# поставить между обычными числами оператор +, компилятор генерирует код, выполняющий сложение двух чисел. Когда оператор + применяют к строкам, компилятор C# генерирует код, выполняющий конкатенацию этих строк. Для обозначения неравенства в C# используется оператор ! =, а в Visual Basic — оператор о. Наконец, оператор Л в C# задает операцию «исключающее или» (XOR), тогда как в Visual Basic это возведение в степень.
Хотя CLR ничего не знает об операторах, среда указывает, как языки программирования должны предоставлять доступ к перегруженным операторам, чтобы последние могли легко использоваться в коде на разных языках программирования. Для каждого конкретного языка проектировщики решают, будет ли этот язык поддерживать перегрузку операторов и, если да, какой синтаксис задействовать для представления и использования перегруженных операторов. С точки зрения CLR перегруженные операторы представляют собой просто методы.
От выбора языка зависит наличие поддержки перегруженных операторов и их синтаксис, а при компиляции исходного текста компилятор генерирует метод, определяющий работу оператора. Спецификация CLR требует, чтобы перегруженные операторные методы были открытыми и статическими. Дополнительно C# (и многие другие языки) требует, чтобы у операторного метода тип, по крайней мере, одного из параметров или возвращаемого значения совпадал с типом, в котором определен операторный метод. Причина этого ограничения в том, что оно позволяет компилятору C# в разумное время находить кандидатуры операторных методов для привязки.
Пример метода перегруженного оператора, заданного в определении класса С#:
public sealed class Complex {
public static Complex operator+(Complex cl, Complex c2) { ... }
}
Компилятор генерирует определение метода op_Addition и устанавливает в записи с определением этого метода флаг specialname, свидетельствующий о том, что это «особый» метод. Когда компилятор языка (в том числе компилятор С#) видит в исходном тексте оператор +, он исследует типы его операндов. При этом компилятор пытается выяснить, не определен ли для одного из них метод op_Addition с флагом specialname, параметры которого совместимы с типами операндов. Если такой метод существует, компилятор генерирует код, вызывающий этот метод, иначе возникает ошибка компиляции.
В табл. 8.1 и 8.2 приведен набор унарных и бинарных операторов, которые C# позволяет перегружать, их обозначения и рекомендованные имена соответствующих методов, которые должен генерировать компилятор. Третий столбец я прокомментирую в следующем разделе.
| Таблица 8.1. Унарные операторы C# и CLS-совместимые имена соответствующих методов
продолжение &
|
| Таблица 8.1 (продолжение)
|
|
|
| Таблица 8.2. Бинарные операторы и их CLS-совместимые имена методов
|
|
|
В спецификации CLR определены многие другие операторы, поддающиеся перегрузке, но C# их не поддерживает. Они не очень распространены, поэтому я их здесь не указал. Полный список есть в спецификации ЕСМА (www.ecma-international.org/ publications/standards/Ecma-335.htm) общеязыковой инфраструктуры CLI, разделы 10.3.1 (унарные операторы) и 10.3.2 (бинарные операторы).
ПРИМЕЧАНИЕ
Если изучить фундаментальные типы библиотеки классов .NET Framework (FCL) — Int32, Int64, Ulnt32 и t. д., — можно заметить, что они не определяют методы перегруженных операторов. Дело в том, что компиляторы целенаправленно ищут операции с этими примитивными типами и генерируют IL-команды, манипулирующие экземплярами этих типов. Если бы эти типы поддерживали соответствующие методы, а компиляторы генерировали вызывающий их код, то каждый такой вызов снижал бы быстродействие во время выполнения. Кроме того, чтобы реализовать ожидаемое действие, такой метод в конечном итоге все равно исполнял бы те же инструкции языка IL. Для вас это означает следующее: если язык, на котором вы пишете, не поддерживает какой-либо из фундаментальныхтипов FCL, вы не сможете выполнять действия над экземплярами этого типа.
Операторы и взаимодействие языков программирования
Перегрузка операторов очень полезна, поскольку позволяет разработчикам лаконично выражать свои мысли в компактном коде. Однако не все языки поддерживают перегрузку операторов; например, при использовании языка, не поддерживающего перегрузку, он не будет знать, как интерпретировать оператор + (если только соответствующий тип не является элементарным в этом языке), и компилятор сгенерирует ошибку. При использовании языков, не поддерживающих перегрузку, язык должен позволять вызывать методы с приставкой ор_ (например, op_Addition) напрямую.
Если вы пишете на языке, не поддерживающем перегрузку оператора + путем определения в типе, ничто не мешает типу предоставить метод op_Addition. Логично ожидать, что в C# можно вызвать этот метод op_Addition, указав оператор +, но это не так. Обнаружив оператор +, компилятор C# ищет метод op_Addition с флагом метаданных specialname, который информирует компилятор, что op_Addition — это перегруженный операторный метод. А поскольку метод op_Addition создан на языке, не поддерживающем перегрузку, в методе флага specialname не будет, и компилятор C# вернет ошибку. Ясно, что код любого языка может явно вызывать метод по имени op_Addition, но компиляторы не преобразуют оператор + в вызов этого метода.
Особое мнение автора о правилах Microsoft, связанных с именами методов операторов
Я уверен, что все эти правила, касающиеся случаев, когда можно или нельзя вызвать метод перегруженного оператора, излишне сложны. Если бы компиляторы, поддерживающие перегрузку операторов, просто не генерировали флаг метаданных specialname, можно было бы заметно упростить эти правила, и программистам стало бы намного легче работать с типами, поддерживающими методы перегруженных операторов. Если бы языки, поддерживающие перегрузку операторов, поддерживали бы и синтаксис операторов, все языки также поддерживали бы явный вызов методов
с приставкой ор_. Я не могу назвать ни одной причины, заставившей Microsoft так усложнить эти правила, и надеюсь, что в следующих версиях своих компиляторов Microsoft упростит их.
Для типа с методами перегруженных операторов Microsoft также рекомендует определять открытые экземплярные методы с дружественными именами, вызывающие методы перегруженных операторов в своей внутренней реализации. Например, тип с перегруженными методами op_Addition или op_AdditionAssignment должен также определять открытый метод с дружественным именем Add. Список рекомендованных дружественных имен для всех методов операторов приводится в третьем столбце табл. 8.1 и 8.2. Таким образом, показанный ранее тип Complex можно было бы определить и так:
public sealed class Complex {
public static Complex operator+(Complex cl, Complex c2) { . .. } public static Complex Add(Complex cl, Complex c2) { return(cl + c2); }
}
Ясно, что код, написанный на любом языке, способен вызывать любой из операторных методов по его дружественному имени, скажем Add. Правила же Microsoft, предписывающие дополнительно определять методы с дружественными именами, лишь осложняют ситуацию. Думаю, это излишняя сложность, к тому же вызов методов с дружественными именами вызовет снижение быстродействия, если только JIT-компилятор не будет способен подставлять код в метод с дружественным именем. Подстановка кода позволит JIT-компилятору оптимизировать весь код путем удаления дополнительного вызова метода и тем самым повысить скорость выполнения.
ПРИМЕЧАНИЕ
Примером типа, в котором перегружаются операторы и используются дружественные
имена методов в соответствии с правилами Microsoft, может служить класс System.
Decimal библиотеки FCL.
Методы операторов преобразования
Время от времени возникает необходимость в преобразовании объекта одного типа в объект другого типа. Уверен, что вам приходилось преобразовывать значение Byte в Int32. Когда исходный и целевой типы являются примитивными, компилятор способен без посторонней помощи генерировать код, необходимый для преобразования объекта.
Если ни один из типов не является примитивным, компилятор генерирует код, заставляющий CLR выполнить преобразование (приведение типов). В этом случае CLR просто проверяет, совпадает ли тип исходного объекта с целевым типом (или является производным от целевого). Однако иногда требуется преобразовать объект одного типа в совершенно другой тип. Например, класс System. Xml. Linq. XElement позволяет преобразовать элемент XML в Boolean, (U)Int32, (U)Int64, Single, Double, Decimal, String, DateTime, DateTimeOffset, TimeSpan, Guid или эквивалент любого из этих типов, допускающий присваивание null (кроме String). Также можно представить, что в FCL есть тип данных Rational, в который удобно преобразовывать объекты типа Int32 или Single. Более того, было бы полезно иметь возможность выполнить обратное преобразование объекта Rational в Int32 или Single.
Для выполнения этих преобразований в типе Rational должны определяться открытые конструкторы, принимающие в качестве единственного параметра экземпляр преобразуемого типа. Кроме того, нужно определить открытый экземплярный метод ТоХхх, не принимающий параметров (как популярный метод ToString). Каждый такой метод преобразует экземпляр типа, в котором определен этот метод, в экземпляр типа Ххх. Вот как правильно определить соответствующие конструкторы и методы для типа Rational:
public sealed class Rational {
// Создает Rational из Int32 public Rational(Int32 num) { ... }
// Создает Rational из Single public Rational(Single num) { ... }
// Преобразует Rational в Int32 public Int32 ToInt32() { ... }
// Преобразует Rational в Single public Single ToSingleQ { ... }
}
Вызывая эти конструкторы и методы, разработчик, используя любой язык, может преобразовать объект типа Int32 или Single в Rational и обратно. Подобные преобразования могут быть весьма удобны, и при проектировании типа стоит подумать, какие конструкторы и методы преобразования имело бы смысл включить в него.
Ранее мы обсуждали способы поддержки перегрузки операторов в разных языках. Некоторые (например, С#) наряду с этим поддерживают перегрузку операторов преобразования — методы, преобразующие объекты одного типа в объекты другого типа. Методы операторов преобразования определяются при помощи специального синтаксиса. Спецификация CLR требует, чтобы перегруженные методы преобразования были открытыми и статическими. Кроме того, C# (и многие другие языки) требуют, чтобы у метода преобразования тип, по крайней мере, одного из параметров или возвращаемого значения совпадал с типом, в котором определен операторный метод. Причина этого ограничения в том, что оно позволяет компилятору C# в разумное время находить кандидатуры операторных методов для привязки. Следующий код добавляет в тип Rational четыре метода операторов преобразования:
public sealed class Rational {
// Создает Rational из Int32 public Rational(Int32 num) { ... }
// Создает Rational из Single public Rational(Single num) { ... }
// Преобразует Rational в Int32 public Int32 ToInt32() { ... }
// Преобразует Rational в Single public Single ToSingle() { ... }
// Неявно создает Rational из Int32 и возвращает полученный объект public static implicit operator Rational(Int32 num) { return new Rational(num); }
// Неявно создает Rational из Single и возвращает полученный объект public static implicit operator Rational(Single num) { return new Rational(num); }
// Явно возвращает объект типа Int32, полученный из Rational public static explicit operator Int32(Rational r) { return r.ToInt32(); }
// Явно возвращает объект типа Single, полученный из Rational public static explicit operator Single(Rational r) { return r.ToSingle();
}
При определении методов для операторов преобразования следует указать, должен ли компилятор генерировать код для их неявного вызова автоматически или лишь при наличии явного указания в исходном тексте. Ключевое слово implicit указывает компилятору С#, что наличие в исходном тексте явного приведения типов не обязательно для генерации кода, вызывающего метод оператора преобразования. Ключевое слово explicit позволяет компилятору вызывать метод только тогда, когда в исходном тексте происходит явное приведение типов.
После ключевого слова implicit или explicit вы сообщаете компилятору, что данный метод представляет собой оператор преобразования (ключевое слово operator). После ключевого слова operator указывается целевой тип, в который преобразуется объект, а в скобках — исходный тип объекта.
Определив в показанном ранее типе Rational операторы преобразования, можно написать (на С#):
public sealed class Program { public static void Main() {
Rational rl = 5; // Неявное приведение Int32 к Rational
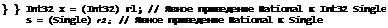 |
Rational r2 = 2.5F; // Неявное приведение Single к Rational
При исполнении этого кода «за кулисами» происходит следующее. Компилятор C# обнаруживает в исходном тексте операции приведения (преобразования типов) и при помощи внутренних механизмов генерирует I L-код, который вызывает методы операторов преобразования, определенные в типе Rational. Но каковы имена этих методов? На этот вопрос можно ответить, скомпилировав тип Rational и изучив его метаданные. Оказывается, компилятор генерирует по одному методу для каждого из определенных операторов преобразования. Метаданные четырех методов операторов преобразования, определенных в типе Rational, выглядят примерно так:
public static Rational op_Implicit(Int32 num) public static Rational oplmplicit(Single num) public static Int32 op_Explicit(Rational r) public static Single op_Explicit(Rational r)
Как видите, методы, выполняющие преобразование объектов одного типа в объекты другого типа, всегда называются op_Implicit или op_Explicit. Определять оператор неявного преобразования следует, только когда точность или величина значения не теряется в результате преобразования, например при преобразовании Int32 в Rational. Если же точность или величина значения в результате преобразования теряется (например, при преобразовании объекта типа Rational в Int32), следует определять оператор явного преобразования. Если попытка явного преобразования завершится неудачей, следует сообщить об этом, выдав в методе исключение OvenflowException или InvalidOpenationException.
ПРИМЕЧАНИЕ
Два метода с именем op_Explicit принимают одинаковый параметр — объект типа Rational. Но эти методы возвращают значения разных типов: Int32 и Single соответственно. Это пример пары методов, отличающихся лишь типом возвращаемого значения. CLR в полном объеме поддерживает возможность определения нескольких методов, отличающихся только типами возвращаемых значений. Однако эта возможность используется лишь очень немногими языками. Как вы, вероятно, знаете, C++, С#, Visual Basic и Java не позволяют определять методы, различающиеся только типом возвращаемого значения. Лишь несколько языков (например, IL) позволяют разработчику явно выбирать, какой метод вызвать. Конечно, IL-программистам не следует использовать эту возможность, так как определенные таким образом методы будут недоступны для вызова из программ, написанных на других языках программирования. И хотя C# не предоставляет эту возможность программисту, внутренние механизмы компилятора все равно используют ее, если в типе определены методы операторов преобразования.
Компилятор C# полностью поддерживает операторы преобразования. Обнаружив код, в котором вместо ожидаемого типа используется объект совсем другого типа, компилятор ищет метод оператора неявного преобразования, способный выполнить нужное преобразование, и генерирует код, вызывающий этот метод. Если подходящий метод оператора неявного преобразования обнаруживается, компилятор вставляет в результирующий IL-код вызов этого метода. Е1айдя в исходном тексте
явное приведение типов, компилятор ищет метод оператора явного или неявного преобразования. Если он существует, компилятор генерирует вызывающий его код. Если компилятор не может найти подходящий метод оператора преобразования, он выдает ошибку, и код не компилируется.
ПРИМЕЧАНИЕ
C# генерирует код вызова операторов неявного преобразования в случае, когда используется выражение приведения типов. Однако операторы неявного преобразования никогда не вызываются, если используется оператор as или is.
Чтобы по-настоящему разобраться в методах перегруженных операторов и операторов преобразования, я настоятельно рекомендую использовать тип System. Decimal как образец. В типе Decimal определено несколько конструкторов, позволяющих преобразовывать в Decimal объекты различных типов. Он также поддерживает несколько методов ТоХхх для преобразования объектов типа Decimal в объекты других типов. Наконец, в этом типе определен ряд методов операторов преобразования и перегруженных операторов.
Методы расширения
Механизм методов расширения лучше всего рассматривать на конкретном примере. В главе 14 я упоминаю о том, что для управления строками класс StringBuilder предлагает меньше методов, чем класс String, и это довольно странно, потому что класс StringBuilder является предпочтительнее для управления строками, так как он изменяем. Допустим, вы хотите определить некоторые отсутствующие в классе StringBuilder методы самостоятельно. Возможно, вы решите определить собственный метод IndexOf:
public static class StringBuilderExtensions {
public static Int32 IndexOf(StringBuilder sb, Char value) { for (Int32 index = 0; index < sb.Length; index++) if (sb[index] == value) return index; return -1;
}
}
После того как метод будет определен, его можно использовать в программах: // Инициализирующая строка
StringBuilder sb = new StringBuilder("Hello. My name is 3eff.“);
// Замена точки восклицательным знаком
// и получение номера символа в первом предложении (5)
Int32 index = StringBuilderExtensions. IndexOf (sb. Replace(, ' !'), ' !')j
Этот программный код работает, но в перспективе он не идеален. Во-первых, программист, желающий получить индекс символа при помощи класса StringBuilder, должен знать о существовании класса StringBuilderExtensions. Во-вторых, программный код не отражает последовательность операторов, представленных в объекте StringBuilder, что усложняет понимание, чтение и сопровождение кода. Программистам удобнее было бы вызывать сначала метод Replace, а затем метод IndexOf, но когда вы прочитаете последнюю строчку кода слева направо, первым в строке окажется IndexOf, а затем — Replace. Вы можете исправить ситуацию и сделать поведение программного кода более понятным, написав следующий код:
// Замена точки восклицательным знаком sb.Replace('.', '!');
// Получение номера символа в первом предложении (5)
Int32 index = StringBuilderExtensions.IndexOf(sb, ' !')j
Однако здесь возникает третья проблема, затрудняющая понимание логики кода. Использование класса StringBuilderExtensions отвлекает программиста от выполняемой операции: IndexOf. Если бы класс StringBuilder определял собственный метод IndexOf, то представленный код можно было бы переписать следующим образом:
// Замена точки восклицательным знаком
// и получение номера символа в первом предложении (5)
Int32 index = sb.Replace('.', '!').IndexOf('!');
В контексте сопровождения программного кода это выглядит великолепно! В объекте StringBuilder мы заменяем точку восклицательным знаком, а затем находим индекс этого знака.
А сейчас я попробую объяснить, что именно делают методы расширения. Они позволяют вам определить статический метод, который вызывается посредством синтаксиса экземплярного метода. Иначе говоря, мы можем определить собственный метод IndexOf — и три проблемы, упомянутые выше, исчезнут. Для того чтобы превратить метод IndexOf в метод расширения, мы просто добавим ключевое слово this перед первым аргументом:
public static class StringBuilderExtensions {
public static Int32 IndexOf(this StringBuilder sb, Char value) { for (Int32 index = 0; index < sb.Length; index++) if (sb[index] == value) return index; return -1;
}
}
Компилятор увидит следующий код:
Int32 index = sb.IndexOf('X');
Сначала он проверит класс StringBuilder или все его базовые классы, предоставляющие экземплярные методы с именем IndexOf и единственным параметром
Char. Если они не существуют, тогда компилятор будет искать любой статический класс с определенным методом IndexOf. у которого первый параметр соответствует типу выражения, используемого при вызове метода. Этот тип должен быть отмечен при помощи ключевого слова this. В данном примере выражением является sb типа StringBuilder. 15 этом случае компилятор ищет метод IndexOf с двумя параметрами: StringBuilder (отмеченное словом this) и Char. Компилятор найдет наш метод IndexOf и сгенерирует IL-код для вызова нашего статического метода.
Теперь понятно, как компилятор решает две последние упомянутые мной проблемы, относящиеся к читабельности кода. Однако до сих пор непонятно, как решается первая проблема, то есть как программисты узнают о том, что метод IndexOf существует и может использоваться в объекте StringBuilder? ()твет на эк)Т вопрос в Microsoft Visual Studio дает механизм IntelliSense. В редактс>ре, к< >гда вы напечатаете точку, появится IntelliSense-окно со списком доступных методов. Кроме того, в IntelliSense-окне будут представлены все методы расширения, существующие для типа выражения, написанного слева от точки. IntelliSense-окно показано на рис. В. I. Как видите, ря/м >м с методами расширения имеется стрелочка, а контекстная подсказка показывает, что метод действительно является методом
расширения. ............... удобно, потому что теперь при помощи этого инструмента
вы можете легко определять собственные методы для управления различными типами ()бъектов, а другие программисты естественным образом узнают о них при использовании объектов этих типов.
^ CLR 41* О - Mi(№»KViswl Sfcuke ftwHuwHtmi Р - О х
.ЕМ 6М Iftw ВМЛТЙА e*Cuffl ель ЫвиЬ ПДЫ ап САГА Idtx* «я ЛАГиТЫТиМ АЦЛ1.уЯ *N(xJw
о - с- а - a u "> - - ► a.rt» bin tiv 1 ,
| // Cheng* period to extlemtion ewr-li end n*t * eh*r*ct*rs in lit i^ntsik* (5), index - ч1|.4 , 1 1 * ) . lndi'xDF( ' 1 ' ); 9 l*VUAlrt R в Mi в GtfHwtyGoJk // sb ii null в ЗДГурс |
 |
в Гн.0
Правила и рекомендации
Приведу несколько правил и фактов, которые необходимо знать о методах расширения.
□ Язык C# поддерживает только методы расширения, он не поддерживает свойств расширения, событий расширения, операторов расширения и т. д.
□ Методы расширения (методы со словом this перед первым аргументом) должны быть объявлены в статическом необобщенном классе. Однако нет ограничения на имя этого класса, вы можете назвать его как вам угодно. Конечно, метод расширения должен иметь, по крайней мере, один параметр, и только первый параметр может быть отмечен ключевым словом this.
□ Компилятор C# ищет методы расширения, заданные только в статических классах, определенных в области видимости файла. Другими словами, если вы определили статический класс, унаследованный от другого класса, компилятор C# выдаст следующее сообщение (ошибка CS1109: метод расширения должен быть определен в статическом классе первого уровня, StringBuilderExtensions является вложенным классом):
error CS1109: Extension method must be defined in a top-level static class; StringBuilderExtensions is a nested class
□ Так как статическим классам можно давать любые имена по вашему желанию, компилятору C# необходимо какое-то время для того, чтобы найти методы расширения; он просматривает все статические классы, определенные в области файла, и сканирует их статические методы. Для повышения производительности и для того, чтобы не рассматривать лишние в данных обстоятельствах методы расширения, компилятор C# требует «импортирования» методов расширения. Например, пусть кто-нибудь определил класс StringBuilderExtensions в пространстве имен Wintellect, тогда другой программист, которому нужно иметь доступ к методу расширения данного класса, в начале файла программного кода должен указать команду using Wintellect.
□ Существует возможность определения в нескольких статических классах одинаковых методов расширения. Если компилятор выяснит, что существуют два и более методов расширения, то тогда он выдает следующее сообщение (ошибка CS0121: неоднозначный вызов следующих методов или свойств 'StringBuilderExtensions.IndexOf(string, char)' и 'AnotherStringBuild erExtensions.IndexOf(string, char)):
error CS0121: The call is ambiguous between the following methods
or properties: 'StringBuilderExtensions.IndexOf(string, char)'
and 'AnotherStringBuilderExtensions.IndexOf(string, char)'.
Для того чтобы исправить эту ошибку, вы должны модифицировать программный код. Нельзя использовать синтаксис экземплярного метода для вызова
статического метода, вместо этого должен применяться синтаксис статического метода с указанием имени статического класса, чтобы точно сообщить компилятору, какой именно метод нужно вызвать.
□ Прибегать к этому механизму следует не слишком часто, так как он известен не всем разработчикам. Например, когда вы расширяете тип с методом расширения, вы действительно расширяете унаследованные типы с этим методом. Следовательно, вы не должны определять метод выражения, чей первый параметр — System .Object, так как этот метод будет вызываться для всех типов выражений, и соответствующие ссылки только будут загромождать окно IntelliSense.
□ Существует потенциальная проблема с версиями. Если в будущем разработчики Microsoft добавят экземплярный метод IndexOf к классу StningBuilden с тем же прототипом, что и в моем примере, то когда я перекомпилирую свой программный код, компилятор свяжет с программой экземплярный метод IndexOf компании Microsoft вместо моего статического метода IndexOf. Из-за этого моя программа начнет себя по-другому. Эта проблема версий — еще одна причина, по которой этот механизм следует использовать осмотрительно.
Расширение разных типов методами расширения
В этой главе я продемонстрировал, как определять методы расширения для класса StningBuilden. Я хотел бы отметить, что так как метод расширения на самом деле является вызовом статического метода, то среда CLR не генерирует код для проверки значения выражения, используемого для вызова метода (равно ли оно null).
// sb равно null StringBuilder sb = null;
// Вызов метода выражения: исключение NullReferenceException НЕ БУДЕТ // выдано при вызове IndexOf
// Исключение NullReferenceException будет вброшено внутри цикла IndexOf sb.IndexOf('X');
// Вызов экземплярного метода: исключение NullReferenceException БУДЕТ // вброшено при вызове Replace sb.Replace('.', '!1);
Я также хотел бы отметить, что вы можете определять методы расширения для интерфейсных типов, как в следующем программном коде:
public static void ShowItems<T>(this IEnumerable<T> collection) { foreach (var item in collection)
Console.WriteLine(item);
}
Представленный здесь метод расширения может быть вызван с использованием любого выражения, результат выполнения которого относится к типу, реализующему интерфейс IEnumenable<T>:
public static void Main() {
// Показывает каждый символ в каждой строке консоли "Grant".Showltems();
// Показывает каждую строку в каждой строке консоли new[] { "3eff", "Kristin" }.ShowItems();
// Показывает каждый Int32 в каждой строчке консоли, new List<Int32>() { 1, 2, 3 }. ShowIternsQ;
}
ВНИМАНИЕ
Методы расширения являются краеугольным камнем предлагаемой Microsoft технологии Language Integrated Query (LINQ). В качестве хорошего примера класса с большим количеством методов расширения обратите внимание на статический класс System.Linq.Enumerable и все его статические методы расширения в документации Microsoft .NET FrameworkSDK. Каждый метод расширения в этом классе расширяет либо интерфейс lEnumerable, либо интерфейс IEnumerable<T>.
Методы расширения также можно определять и для типов-делегатов, например:
public static void InvokeAndCatch<TException>(this Action<Object> d, Object o) where TException : Exception { try { d(o); } catch (TException) { }
}
Пример вызова:
Action<Object> action = о => Console.WriteLine(o.GetTypeQ);
// Выдает NullReferenceException action.InvokeAndCatch<NullReferenceException>(null);
// Поглощает NullReferenceException
Кроме того, можно добавлять методы расширения к перечислимым типам (примеры см. в главе 15).
Наконец, компилятор C# позволяет создавать делегатов, ссылающихся на метод расширения через объект (см. главу 17):
public static void Main () {
// Создание делегата Action, ссылающегося на статический метод расширения // Showltems; первый аргумент инициализируется ссылкой на строку "3eff"
Action а = "3eff".Showltems;
// Вызов делегата, вызывающего Showltems и передающего // ссылку на строку "3eff"
а();
}
В представленном программном коде компилятор C# генерирует IL-код для того, чтобы создать делегата Action. После создания делегата конструктор передается в вызываемый метод, также передается ссылка на объект, который должен быть передан в этот метод в качестве скрытого параметра. Обычно, когда вы создаете делегата, ссылающегося на статический метод, объектная ссылка равна null, потому что статический метод не имеет этого параметра. Однако в данном примере компилятор C# сгенерирует специальный код, создающий делегата, ссылающегося на статический метод Showltems, а целевым объектом статического метода будет ссылка на строку " Jeff". Позднее, при вызове делегата, CLR вызовет статический метод и передаст ему ссылку на строку "Jeff". Все это напоминает какие-то фокусы, но хорошо работает и выглядит естественно, если не думать, что при этом происходит внутри.
Атрибут расширения
Конечно, было бы лучше, чтобы концепция методов расширения относилась бы не только к С#. Хотелось бы, чтобы программисты определяли набор методов расширения на разных языках программирования и, таким образом, способствовали развитию других языков программирования. Для того чтобы этот механизм работал, компилятор должен поддерживать поиск статичных типов и методов для сопоставления с методами расширения. И компиляторы должны это проделывать быстро, чтобы время компиляции оставалось минимальным.
В языке С#, когда вы помечаете первый параметр статичного метода ключевым словом this, компилятор применяет соответствующий атрибут к методу, и данный атрибут сохраняется в метаданных результирующего файла. Этот атрибут определен в сборке System.Core.dll и выглядит следующим образом:
// Определен в пространстве имен System.Runtime.CompilerServices [Att г ibutellsage( AttributeTargets. Met hod | AttributeTargets.Class
| AttributeTargets.
Assembly)]
public sealed class ExtensionAttribute : Attribute {
}
К тому же этот атрибут применяется к метаданным любого статического класса, содержащего, по крайней мере, один метод расширения. Итак, когда скомпилированный код вызывает несуществующий экземплярный метод, компилятор может быстро просканировать все ссылающиеся сборки, чтобы определить, какая из них содержит методы расширения. В дальнейшем он может сканировать только те сборки статических классов, которые содержат методы расширения, выполняя поиск потенциальных соответствий компилируемому коду настолько быстро, насколько это возможно.
ПРИМЕЧАНИЕ
Класс ExtensionAttribute определен в сборке System.Core.dll. Это означает, что результирующая сборка, сгенерированная компилятором, будет иметь ссылку на встроенную в нее библиотеку System.Core.dll, даже если не использовать какой-либо тип из System.Core.dll и даже если не ссылаться на него во время компиляции программного кода. Однако это не такая уже большая проблема, потому что ExtensionAttribute используется только один раз во время компиляции, и во время выполнения System. Core.dll не загрузится, пока приложение занято чем-либо другим в этой сборке.
Частичные методы
Представьте, что вы используете служебную программу, которая генерирует исходный код на C# с определением типа. Этой программе известно, что внутри программного кода есть места, в которых вы хотели бы настроить поведение типа. Обычно такая настройка производится при помощи виртуальных методов, вызываемых сгенерированным кодом. Сгенерированный код также должен содержать определения этих виртуальных методов, где их реализация ничего не делает, а просто возвращает управление. Чтобы настроить поведение класса, нужно определить собственный класс, унаследованный от базового, и затем переопределить все его виртуальные методы, реализующие желаемое поведение. Вот пример:
// Сгенерированный код в некотором файле с исходным кодом: internal class Base { private String mname;
// Вызывается перед изменением поля m_name protected virtual void OnNameChanging(String value) {
}
public String Name { get { return mname; } set {
// Информирует класс о возможных изменениях OnNameChanging(value. Tollpper ()); m_name = value; 11 Изменение поля
}
}
}
// Написанный программистом код из другого файла internal class Derived : Base {
protected override void OnNameChanging(string value) { if (String.IsNullOrEmpty(value))
throw new ArgumentNullException("value");
}
}
К сожалению, у представленного кода имеются два недостатка.
□ Тип не должен быть запечатанным (sealed) классом. Нельзя использовать этот подход для запечатанных классов или для значимых типов (потому что значимые типы неявно запечатаны). К тому же нельзя использовать этот подход для статических методов, потому что они не могут переопределяться.
□ Существует проблема эффективности. Тип, определяемый только для переопределения метода, понапрасну расходует некоторое количество системных ресурсов. И даже если вы не хотите переопределять поведение типа OnNameChanging, код базового класса по-прежнему вызовет виртуальный метод, который помимо возврата управления ничего больше не делает. Метод ToUppen вызывается и тогда, когда OnNameChanging получает доступ к переданным аргументам, и тогда, когда не получает.
Для решения проблемы переопределения поведения можно задействовать частичные методы языка С#. В следующем коде для достижения той же семантики, что и в предыдущем коде, используются частичные методы:
// Сгенерированный при помощи инструмента программный код internal sealed partial class Base { private String m_name;
// Это объявление с определением частичного метода вызывается
// перед изменением поля m_name
partial void OnNameChanging(String value);
public String Name { get { return mname; } set {
// Информирование класса о потенциальном изменении OnNameChanging(value.ToUpper()); mname = value; // Изменение поля
}
}
>
// Написанный программистом код, содержащийся в другом файле internal sealed partial class Base {
// Это объявление с реализацией частичного метода вызывается перед тем,
// как будет изменено поле m_name partial void OnNameChanging(String value) { if (String.IsNullOrEmpty(value)) throw new ArgumentNullException("value");
>
>
В этом коде есть несколько мест, на которые необходимо обратить внимание.
□ Теперь класс запечатан (хотя это и не обязательно). В действительности, класс мог бы быть статическим классом или даже значимым типом.
□ Код, сгенерированный программой, и код, написанный программистом, на самом деле являются двумя частичными определениями, которые в конце концов образуют одно определение типа (подробности см. в главе 6).
□ Код, сгенерированный программой, представляет собой объявление частичного метода. Этот метод помечен ключевым словом partial и не имеет тела.
□ Код, написанный программистом, реализует объявление частичного метода. Этот метод также помечен ключевым словом partial и тоже не имеет тела.
Когда вы скомпилируете этот код, вы увидите то же самое, что и в представленном ранее коде. Большое преимущество такого решения заключается в том, что вы можете перезапустить программу и сгенерировать новый код в новом файле, а ваш программный код по-прежнему останется нетронутым в отдельном файле. Кроме того, этот подход работает для изолированных классов, статических классов и значимых типов.
ПРИМЕЧАНИЕ
В редакторе Visual Studio, если ввести partial и нажать пробел, в окне IntelliSense появятся объявления всех частичных методов вложенного типа, которые пока не имеют соответствия объявлениям выполняемого частичного метода. Вы легко можете выбрать частичный метод в IntelliSense-окне, и Visual Studio сгенерирует прототип метода автоматически. Это очень удобная функция, повышающая производительность программирования.
У частичных методов имеется еще одно серьезное преимущество. Скажем, у вас теперь нет нужны модифицировать поведение типа, сгенерированного инструментом, и менять файл исходного кода. Если просто скомпилировать такой код, компилятор создаст IL-код и метаданные, как если бы сгенерированный программой код выглядел следующим образом:
// Логический эквивалент сгенерированного инструментом кода в случае,
// когда нет объявления выполняемого частичного метода internal sealed class Base { private String m_name;
public String Name { get { return m_name; } set {
m_name = value; // Измените поле
}
}
}
При отсутствии объявления выполняемого частичного метода компилятор не будет генерировать метаданные, представляющие частичный метод. К тому же компилятор не сгенерирует IL-команды вызова частичного метода, он не сгенерирует код, вычисляющий аргументы, которые необходимо передать частичному методу.
В приведенном примере компилятор не сгенерирует код для вызова метода ToUpper. В результате будет меньше метаданных и IL-кода и производительность во время выполнения повысится!
ПРИМЕЧАНИЕ
Подобным образом частичные методы работают с атрибутом System.Diagnostics. ConditionalAttribute. Однако они работают только с одним типом, тогда как атрибут ConditionalAttribute может быть использован для необязательного вызова методов, определенных в другом типе.
Правила и рекомендации
Несколько дополнительных правил и рекомендаций, касающихся частичных методов.