
3. Инициализация указателя на объект-тип и индекса блока синхронизации.








4. Вызов конструктора экземпляра типа с параметрами, указанными при вызове new (в предыдущем примере это строка ConstructorParaml). Большинство компиляторов автоматически включает в конструктор код вызова конструктора базового класса. Каждый конструктор выполняет инициализацию определенных в соответствующем типе полей. В частности, вызывается конструктор System. Object, но он ничего не делает и просто возвращает управление.
Выполнив все эти операции, new возвращает ссылку (или указатель) на вновь созданный объект. В предыдущем примере кода эта ссылка сохраняется в переменной е типа Employee.
Кстати, у оператора new нет пары — оператора delete, то есть нет явного способа освобождения памяти, занятой объектом. Уборкой мусора занимается среда CLR (см. главу 21), которая автоматически находит объекты, ставшие ненужными или недоступными, и освобождает занимаемую ими память.
Приведение типов
Одна из важнейших особенностей CLR — безопасность типов (type safety). Во время выполнения программы среде CLR всегда известен тип объекта. Программист всегда может точно определить тип объекта при помощи метода GetType. Поскольку это невиртуальный метод, никакой тип не сможет сообщить о себе ложные сведения. Например, тип Employee не может переопределить метод GetType, чтобы тот вернул тип SupenHeno.
При разработке программ часто прибегают к приведению объекта к другим типам. CLR разрешает привести тип объекта к его собственному типу или любому из его базовых типов. В каждом языке программирования приведение типов реализовано по-своему. Например, в C# нет специального синтаксиса для приведения типа объекта к его базовому типу, поскольку такое приведение считается безопасным
неявным преобразованием. Однако для приведения типа к производному от него типу разработчик на C# должен ввести операцию явного приведения типов — неявное преобразование приведет к ошибке. Следующий пример демонстрирует приведение к базовому и производному типам:
// Этот тип неявно наследует от типа System.Object internal class Employee {
}
public sealed class Program { public static void Main() {
// Приведение типа не требуется, т. к. new возвращает объект Employee,
// a Object - это базовый тип для Employee.
Object о = new EmployeeQ;
// Приведение типа обязательно, т. к. Employee - производный от Object // В других языках (таких как Visual Basic) компилятор не потребует // явного приведения Employee е = (Employee) о;
}
}
Этот пример показывает, что необходимо компилятору для компиляции кода. Теперь посмотрим, что произойдет во время выполнения программы. CLR проверит операции приведения, чтобы приведение типов осуществлялось либо к фактическому типу объекта, либо к одному из его базовых типов. Например, следующий код успешно компилируется, но в период выполнения выдает исключение InvalidCastException:
internal class Employee {
}
internal class Manager : Employee {
}
public sealed class Program { public static void Main() {
// Создаем объект Manager и передаем его в PromoteEmployee // Manager ЯВЛЯЕТСЯ производным от Employee,
// поэтому PromoteEmployee работает Manager m = new Manager()j PromoteEmployee(m);
// Создаем объект DateTime и передаем его в PromoteEmployee // DateTime НЕ ЯВЛЯЕТСЯ производным от Employee,
// поэтому PromoteEmployee выбрасывает // исключение System.InvalidCastException DateTime newYears = new DateTime(2013, 1, 1);
PromoteEmployee(newYears);
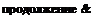 }
}
public static void PromoteEmployee(ObJect о) {
// В этом месте компилятор не знает точно, на какой тип объекта
// ссылается о, поэтому скомпилирует этот код
// Однако в период выполнения CLR знает, на какой тип
// ссылается объект о (приведение типа выполняется каждый раз),
// и проверяет, соответствует ли тип объекта типу Employee
// или другому типу, производному от Employee
Employee е = (Employee) о;
}
}
Метод Main создает объект Manager и передает его в PromoteEmployee. Этот код компилируется и выполняется, так как тип Manager является производным от Object, на который рассчитан PromoteEmployee. Внутри PromoteEmployee CLR проверяет, на что ссылается о — на объект Employee или на объект типа, производного от Employee. Поскольку Manager — производный от Employee тип, CLR выполняет преобразование, и PromoteEmployee продолжает работу.
После того как PromoteEmployee возвращает управление, Main создает объект DateTime, который передает в PromoteEmployee. Объект DateTime тоже является производным от Object, поэтому код, вызывающий PromoteEmployee, компилируется без проблем. Но при выполнении PromoteEmployee CLR выясняет, что о ссылается на объект DateTime, не являющийся ни типом Employee, ни другим типом, производным от Employee. В этот момент CLR не в состоянии выполнить приведение типов и генерирует исключение System.InvalidCastException.
Если разрешить подобное преобразование, работа с типами станет небезопасной. Последствия могут быть непредсказуемы: возможное аварийное завершение приложения, возникновение уязвимостей в системе защиты, обусловленных возможностью типов выдавать себя за другие типы. Фальсификация типов подвергает серьезному риску устойчивость работы приложений, поэтому столь пристальное внимание в CLR уделяется безопасности типов.
В данном примере было бы правильнее выбрать для метода PromoteEmployee в качестве типа параметра не Object, a Employee, чтобы ошибка проявилась на стадии компиляции, а разработчику не пришлось бы ждать исключения, чтобы узнать о существовании проблемы. А объект Object я использовал только для того, чтобы показать, как обрабатывают операции приведения типов компилятор C# и среда CLR.
Приведение типов в C# с помощью операторов is и as
В C# существуют другие механизмы приведения типов. Например, оператор is проверяет совместимость объекта с данным типом, а в качестве результата выдает значение типа Boolean (true или false). Оператор is никогда не генерирует исключение. Взгляните на следующий код:
Object о = new ObJectQ;
Boolean Ы = (о is Object); // Ы равно true Boolean Ь2 = (о is Employee); // Ь2 равно false
Для null-ссылок оператор is всегда возвращает false, так как объекта, тип которого нужно проверить, не существует.
Обычно оператор is используется следующим образом:
if (о is Employee) {
Employee е = (Employee) о;
// Используем е внутри инструкции if
}
В этом коде CLR по сути проверяет тип объекта дважды: сначала в операторе is определяется совместимость о с типом Employee, а затем в теле оператора if анализируется, является ли о ссылкой на Employee. Контроль типов в CLR укрепляет безопасность, но при этом приходится жертвовать производительностью, так как среда CLR должна выяснять фактический тип объекта, на который ссылается переменная (о), а затем проверять всю иерархию наследования на предмет наличия среди базовых типов заданного типа (Employee). Поскольку такая схема встречается в программировании часто, в C# предложен механизм, повышающий эффективность кода с помощью оператора as:
Employee е = о as Employee; if (е != null) {
// Используем е внутри инструкции if
}
В этом коде CLR проверяет совместимость о с типом Employee. Если о и Employee совместимы, as возвращает ненулевой указатель на этот объект, а если нет — оператор as возвращает null. Заметьте: оператор as заставляет CLR верифицировать тип объекта только один раз, a if лишь сравнивает е с null — такая проверка намного эффективнее, чем определение типа объекта.
По сути, оператор as отличается от оператора приведения типа только тем, что никогда не генерирует исключение. Если приведение типа невозможно, результатом является null. Если не сравнить полученный оператором результат с null и попытаться работать с пустой ссылкой, возникнет исключение System. NullReferenceException. Например:
System.Object о = new Object(); // Создание объекта Object Employee e = о as Employee; // Приведение о к типу Employee // Преобразование невыполнимо: исключение не возникло, но е равно null e.ToString(); // Обращение к е вызывает исключение NullReferenceException
Давайте проверим, как вы усвоили материал. Допустим, существуют описания следующих классов:
internal class В { // Базовый класс
}
internal class D : В { // Производный класс
>
В первом столбце табл. 4.3 приведен код на С#. Попробуйте определить результат обработки этих строк компилятором и CLR. Если код компилируется и выполняется без ошибок, сделайте пометку в графе ОК, если произойдет ошибка компиляции — в графе СТЕ (compile-time error), а если ошибка времени выполнения — в графе RTE (run-time error).
| Таблица 4.3. Тест на знание контроля типов
|
|
|
ПРИМЕЧАНИЕ
В C# разрешено определять методы операторов преобразования при помощи типов, об этом речь идет в разделе «Методы операторов преобразования» главы 8. Эти методы вызываются только в случаях, когда имеет место приведение типов, и никогда не вызываются при использовании операторов is и as в С#.
Пространства имен и сборки
Пространства имен используются для логической группировки родственных типов, чтобы разработчику было проще найти нужный тип. Например, в пространстве имен System.Text описаны типы для обработки строк, а в пространстве имен System.
10 — типы для выполнения операций ввода-вывода. В следующем коде создаются объекты System.10.FileStreamи System.Text.StringBuilder:
public sealed class Program { public static void Main() {
System.10.FileStream fs = new System.10.FileStream(...);
System.Text.StringBuilder sb = new System.Text.StringBuilderQ;
}
}
Этому коду не хватает лаконичности — обращения к типам FileStream и StringBuilder выглядят слишком громоздко. К счастью, многие компиляторы предоставляют программистам механизмы, позволяющие сократить объем набираемого текста. Например, в компиляторе C# предусмотрена директива using. Следующий код аналогичен предыдущему:
using System.10; // Подставлять префикс "System.10"
using System.Text; // Подставлять префикс "System.Text"
public sealed class Program { public static void Main() {
FileStream fs = new FileStream(...);
StringBuilder sb = new StringBuilderQ;
}
}
Для компилятора пространство имен — простое средство, позволяющее удлинить имя типа и сделать его уникальным за счет добавления к началу имени групп символов, разделенных точками. Например, в данном примере компилятор интерпретирует FileStream как System. 10. FileStream, a StringBuilder — KaKSystem. Text.StringBuilder.
Применять директиву using в C# не обязательно, при необходимости достаточно ввести полное имя типа. Директива using заставляет компилятор C# добавлять к имени указанный префикс, пока не будет найдено совпадение.
ВНИМАНИЕ
CLR ничего не знает о пространствах имен. При обращении к какому-либо типу среде CLR надо предоставить полное имя типа (а это может быть действительно длинная строка с точками) и сборку, содержащую описание типа, чтобы во время выполнения загрузить эту сборку, найти в ней нужный тип и оперировать им.
В предыдущем примере компилятор должен гарантировать, что каждый упомянутый в коде тип существует и корректно обрабатывается: вызываемые методы существуют, число и типы передаваемых аргументов указаны правильно, значения, возвращаемые методами, обрабатываются надлежащим образом и т. д. Не найдя тип с заданным именем в исходных файлах и перечисленных сборках, компилятор попытается добавить к имени типа префикс System. 10 и проверит, совпадает ли полученное имя с существующим типом. Если имя типа опять не обнаружится,
поиск повторяется с префиксом System.Text. Благодаря двум директивам using, показанным ранее, я смог ограничиться именами FileStream и StringBuilder — компилятор автоматически расширяет ссылки до System.10. FileStream и System. Collections. StringBuilder. Конечно, такой код намного проще вводится, чем исходный, да и читается проще.
Компилятору надо сообщить при помощи параметра /reference (см. главы 2 и 3), в каких сборках искать описание типа. В поисках нужного типа компилятор просмотрит все известные ему сборки. Если подходящая сборка обнаруживается, сведения о ней и типе помещаются в метаданные результирующего управляемого модуля. Для того чтобы информация из сборки была доступна компилятору, надо указать ему сборку, в которой описаны упоминаемые типы. По умолчанию компилятор C# автоматически просматривает сборку MSCorl_ib.dll, даже если она явно не указана. В ней содержатся описания всех фундаментальных FCL-типов, таких как Object, Int32, String и др.
Легко догадаться, что такой способ обработки пространства имен чреват проблемами, если два (и более) типа с одинаковыми именами находятся в разных сборках. Microsoft настоятельно рекомендует при описании типов применять уникальные имена. Но порой это невозможно. В CLR поощряется повторное использование компонентов. Допустим, в приложении имеются компоненты, созданные в Microsoft и Wintellect, в которых есть типы с одним названием, например Widget. Версия Widget от Microsoft делает одно, а версия от Wintellect - совершенно другое. В этом случае процесс формирования имен типов становится неуправляемым, и чтобы различать эти типы, придется указывать в коде их полные имена. При обращении к Widget от Microsoft надо использовать запись Microsoft.Widget, а при ссылке на Widget от Wintellect — запись Wintellect .Widget. В следующем коде ссылка на Widget неоднозначна, и компилятор C# выдаст сообщение error CS0104: 1 Widget1 is an ambiguous reference (ошибка CS0104: 'Widget' — неоднозначная ссылка):
using Microsoft; // Определяем префикс "Microsoft." using Wintellect; // Определяем префикс "Wintellect."
public sealed class Program { public static void Main() {
Widget w = new Widget(); // Неоднозначная ссылка
}
}
Для того чтобы избавиться от неоднозначности, надо явно указать компилятору, какой экземпляр Widget требуется создать:
using Microsoft; // Определяем приставку "Microsoft." using Wintellect; // Определяем приставку "Wintellect."
public sealed class Program { public static void Main() {
Wintellect.Widget w = new Wintellect.WidgetQ; // Неоднозначности нет
}
В C# есть еще одна форма директивы using, позволяющая создать псевдоним для отдельного типа или пространства имен. Она удобна, если вы намерены использовать несколько типов из пространства имен, но не хочется «захламлять» глобальное пространство имен всеми используемыми типами. Альтернативный способ преодоления неоднозначности следующий:
using Microsoft; // Определяем приставку "Microsoft." using Wintellect; // Определяем приставку "Wintellect."
// Имя WintellectWidget определяется как псевдоним для Wintellect.Widget using WintellectWidget = Wintellect.Widget;
public sealed class Program { public static void Main() {
WintellectWidget w = new WintellectWidget(); // Ошибки нет
>
>
Эти методы устранения неоднозначности хороши, но иногда их недостаточно. Представьте, что компании Australian Boomerang Company (АВС) и Alaskan Boat Corporation (ABC) создали каждая свой тип с именем BuyProduct и собираются поместить его в соответствующие сборки. Не исключено, что обе компании создадут пространства имен АВС, в которые и включат тип BuyProduct. Для разработки приложения, оперирующего обоими типами, необходим механизм, позволяющий различать программными средствами не только пространства имен, но и сборки. К счастью, в компиляторе C# поддерживаются внешние псевдонимы (extern aliases), позволяющие справиться с проблемой. Внешние псевдонимы дают также возможность обращаться к одному типу двух (или более) версий одной сборки. Подробнее о внешних псевдонимах см. спецификацию языка С#.
При проектировании типов, применяемых в библиотеках, которые могут использоваться третьими лицами, старайтесь описывать эти типы в пространстве имен так, чтобы компиляторы могли без труда преодолеть неоднозначность типов. Вероятность конфликта заметно снизится, если в пространстве имен верхнего уровня указывается полное, а не сокращенное название компании. В документации .NET Framework SDK Microsoft использует для своих типов пространство имен Microsoft (например: Microsoft.CSharp, Microsoft.VisualBasic и Microsoft.Win32). Создавая пространство имен, включите в код его объявление (на С#):
namespace CompanyName {
public sealed class A { // TypeDef: CompanyName.A
}
namespace X {
public sealed class В { ... } // TypeDef: CompanyName.X.В }
}
В комментарии справа от объявления класса указано реальное имя типа, которое компилятор поместит в таблицу метаданных определения типов — с точки зрения CLR это «настоящее» имя типа.
()дни компиляторы вовсе не поддерживают пространства имен, другие понимают под этим термином нечто иное. И C# директива namespace заставляет компилятор добавлять к каждому имени типа определенную приставку - это избавляет программиста от необходимости писать массу лишнего кода.
Связь между сборками и пространством имен
Пространство имен и сборка (файл, в котором реализован тип) не обязательно связаны друг с другом. В частности, различные типы, принадлежащие одному пространству имен, могут быть реализованы в разных сборках. Например, тип System. 10. FileStream реализован в сборке MSCorLib.dll, а тип System. 10. FileSystemWatcher - в сборке System.dll. На самом деле, сборка System.IO.dll в .NET Framework даже не поставляется.
()дна сборка может содержать типы из разных пространств имен. Например, типы System.Int32 и System.Text.StringBuilder находятся в сборке MSCorLib.dll.
Заглянув в документацию .NET Framework SDK. вы обнаружите, что там четко обозначено пространство имен, к которому принадлежит тип. и сборка, в которой этот тип реализован. Из рис. 4.1 видно, что тип ResXFileRef является частью пространства имен System. Resources и реализован в сборке System .Windows. Forms. dll. Для того чтобы скомпилировать код, ссылающийся на тип ResXFileRef. необходимо добавить директиву using System.Resources и использовать параметр компилятора /г:System. Windows. forms .dll.
|
Рис. 4.1. Документация SDK с пространством имен и информацией сборки для типа |
Как разные компоненты взаимодействуют во время выполнения
В этом разделе рассказано, как во время выполнения взаимодействуют типы, объекты, стек потока и управляемая куча. Кроме того, объяснено, в чем различие между вызовом статических, экземплярных и виртуальных методов. А начнем мы с некоторых базовых сведений о работе компьютера. То, о чем я собираюсь рассказать, вообще говоря, не относится к специфике CLR, но я начну с общих понятий, а затем перейду к обсуждению информации, относящейся исключительно к CLR.
На рис. 4.2 представлен один процесс Microsoft Windows с загруженной в него исполняющей средой CLR. У процесса может быть много потоков. После создания потоку выделяется стек размером в 1 Мбайт. Выделенная память используется для передачи параметров в методы и хранения определенных в пределах методов локальных переменных. На рис, 4.2 справа показана память стека одного потока. Стеки заполняются от области верхней памяти к области нижней памяти (то есть от старших к младшим адресам). На рисунке поток уже выполняет какой-то код, и в его стеке уже есть какие-то данные (отмечены областью более темного оттенка вверху стека). А теперь представим, что поток выполняет код, вызывающий метод Ml.
Стек потока
/ \ •
void М1() { •
String name = "Joe"; •___________
M2(name);
• • • return;
V________ )
Рис. 4.2. Стек потока перед вызовом метода М1
Все методы, кроме самых простых, содержат некоторый входной код (prologue code), инициализирующий метод до начала его работы. Кроме того, эти методы содержат выходной код (epilogue code), выполняющий очистку после того, как метод завершит свою основную работу, чтобы возвратить управление вызывающей программе. В начале выполнения метода Ml его входной код выделяет в стеке потока память для локальной переменной name (рис. 4.3).
Далее Ml вызывает метод М2, передавая в качестве аргумента локальную переменную name. При этом адрес локальной переменной name заталкивается в стек (рис. 4.4). Внутри метода М2 местоположение стека хранится в переменной-параметре s. (Кстати, в некоторых процессорных архитектурах для повышения производительности аргументы передаются через регистры, но это различие для нашего обсуждения
несущественно.) При вызове метода адрес возврата в вызывающий метод также заталкивается в стек (показано на рис. 4.4).
 void И1() <
void И1() <
String name = "Joe";
M2(name);
return;
 |
Рис. 4.3. Размещение локальной переменной метода М1 в стеке потока
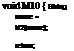 |  |  | |||
Стек потока
void H2(Strlng e) {
Int32 length - 8.Length; Int32 tally;
return;
Рис. 4.4. При вызове М2 метод М1 заталкивает аргументы
и адрес возврата в стек потока
В начале выполнения метода М2 его входной код выделяет в стеке потока память для локальных переменных length и tally (рис. 4.5). Затем выполняется код метода М2. В конце концов, выполнение М2 доходит до команды возврата, которая записывает в указатель команд процессора адрес возврата из стека, и стековый кадр М2 возвращается в состояние, показанное на рис. 4.3. С этого момента продолжается выполнение кода Ml, который следует сразу за вызовом М2, а стековый кадр метода находится в состоянии, необходимом для работы Ml.
В конечном счете, метод Ml возвращает управление вызывающей программе, устанавливая указатель команд процессора на адрес возврата (на рисунках не показан, но в стеке он находится прямо над аргументом name), и стековый кадр Ml возвращается в состояние, показанное на рис. 4.2. С этого момента продолжается выполнение кода вызвавшего метода, причем начинает выполняться код, непосредственно следующий за вызовом Ml, а стековый кадр вызвавшего метода находится в состоянии, необходимом для его работы.


 |
Стек потока
return;
V_____________ )
Рис. 4.5. Выделение в стеке потока памяти для локальных переменных метода М2
А сейчас давайте переключимся на исполняющую среду CLR. Допустим, есть следующие два определения классов:
internal class Employee {
public Int32 GetYearsEmployed () { ... }
public virtual String GetProgressReport () { ... }
public static Employee Lookup(String name) { ... }
}
internal sealed class Manager : Employee {
public override String GenProgressReport() { ... }
}
Процесс Windows запустился, в него загружена среда CLR, инициализирована управляемая куча, и создан поток (с его 1 Мбайт памяти в стеке). Поток уже выполняет какой-то код, из которого вызывается метод М3 (рис. 4.6). Метод М3 содержит код, продемонстрирующий, как работает CLR; вряд ли вы будете включать такой код в свои приложения, потому что он, в сущности, не делает ничего полезного.
В процессе преобразования IL-кода метода М3 в машинные команды JIT-компилятор выявляет все типы, на которые есть ссылки в М3, .что типы Employee, Int32, Manager и String (из-за наличия строки "Зое"). На данном этапе CLR обеспечивает загрузку в домен приложений всех сборок, в которых определены все эти типы. Затем, используя метаданные сборки, CLR получает информацию о типах и создает структуры данных, собственно и представляющие эти типы. Структуры данных для объектов-типов Employee и Manager показаны на рис. 4.7. Поскольку до вызова М3 поток уже выполнил какой-то код, для простоты допустим, что объекты-типы Int32 и String уже созданы (что вполне возможно, так как это часто используемые типы), поэтому они не показаны на рисунке.
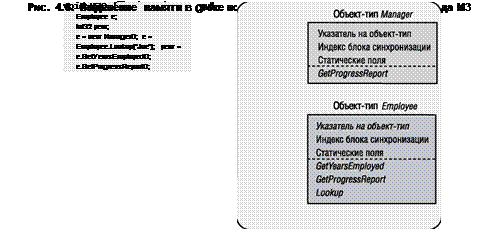
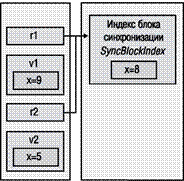
На минуту отвлечемся на обсуждение объектов-типов. Как говорилось ранее в этой главе, все объекты в куче содержат два дополнительных члена: указатель на объект-тип и индекс блока синхронизации. В объектах типа Employee и Manager оба эти члена присутствуют. При определении типа можно включить
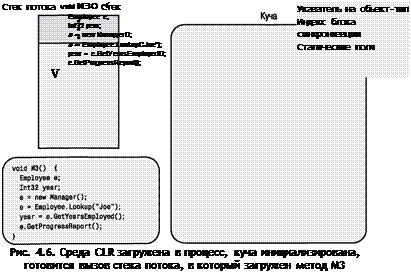 |
в него статические поля данных. Байты для этих статических полей выделяются в составе самих объектов-типов. Наконец, у каждого объекта-типа есть таблица методов с входными точками всех методов, определенных в типе. Эта таблица методов уже обсуждалась в главе 1. Так как в типе Employee определены три метода (GetYearsEmployed, GenProgressReport и Lookup), в соответствующей таблице методов есть три записи. В типе Manager определен один метод (переопределенный метод GenProgressReport), который и представлен в таблице методов этого типа.
Рис. 4.7. При вызове М3 создаются объекты типа Employee и Manager
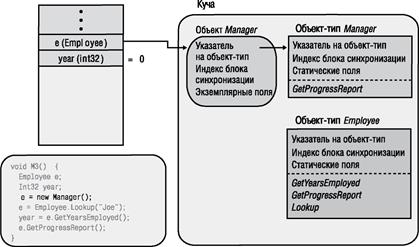
После того как среда CLR создаст все необходимые для метода объекты-типы и откомпилирует код метода М3, она приступает к выполнению машинного кода М3. При выполнении входного кода М3 в стеке потока выделяется память для локальных переменных (рис. 4.8). В частности, CLR автоматически инициализирует все локальные переменные значением null или 0 (нулем) — это делается в рамках выполнения входного кода метода. Однако при попытке обращения к локальной переменной, неявно инициализированной в вашем коде, компилятор C# выдаст сообщение об ошибке Use of unassigned local variable (использование неинициализированной локальной переменной).
Стек потока
Далее М3 выполняет код создания объекта Manager. При этом в управляемой куче создается экземпляр типа Manager, то есть объект Manager (рис. 4.9). У объекта Managei— так же как и у всех остальных объектов — есть указатель на объект-тип и индекс блока синхронизации. У этого объекта тоже есть байты, необходимые для размещения всех экземплярных полей данных, определенные в типе Manager, а также всех экземплярных полей, определенных во всех базовых классах типа Manager (в данном случае — Employee и Object). Всякий раз при создании нового объекта в куче CLR автоматически инициализирует внутренний указатель на объект-тип так, чтобы он указывал на соответствующий объект-тип (в данном случае — на объект-тип Manager). Кроме того, CLR инициализирует индекс блока синхронизации и присваивает всем экземплярным полям объекта значение null или 0 (нуль) перед вызовом конструктора типа метода, который, скорее всего, изменит значения некоторых экземплярных полей. Оператор new возвращает адрес в памяти объекта Manager, который хранится в переменной е (в стеке потока).
| Стек потока
Рис. 4.9. Создание и инициализация объекта Manager |
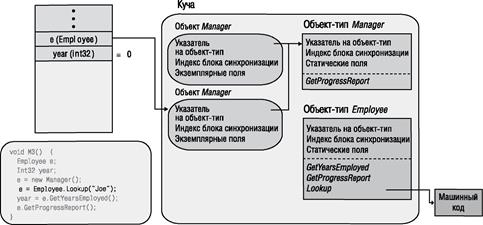
Следующая строка метода М3 вызывает статический метод Lookup объекта Employee. При вызове этого метода CLR определяет местонахождение объекта-типа, соответствующего типу, в котором определен статический метод. Затем на основании таблицы методов объекта-типа среда CLR находит точку входа в вызываемый метод, обрабатывает код JIT-компилятором (при необходимости) и передает управление полученному машинному коду. Для нашего обсуждения достаточно предположить, что метод Lookup объекта Employee выполняет запрос к базе данных, чтобы найти сведения о Зое. Допустим также, что в базе данных указано, что Зое занимает должность менеджера, поэтому код метода Lookup создает в куче новый объект Manager, инициализирует его данными Зое и возвращает адрес готового объекта. Адрес размещается в локальной переменной е. Результат этой операции показан на рис, 4.10.
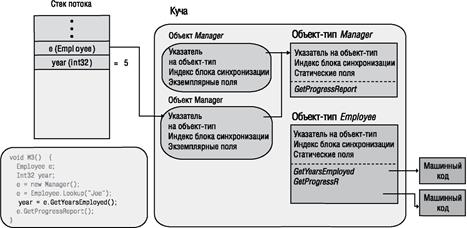
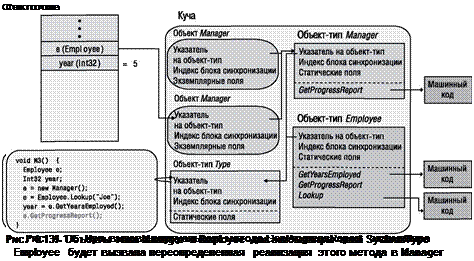
Следующая строка метода М3 вызывает виртуальный экземплярный метод GenProgressReport в Employee. При вызове виртуального экземплярного метода CLR приходится выполнять некоторую дополнительную работу. Во-первых, CLR обращается к переменной, используемой для вызова, и затем следует по адресу вызывающего объекта. В данном случае переменная е указывает на объект Зое типа Manager. Во-вторых, CLR проверяет у объекта внутренний указатель на объект-тип. Затем CLR находит в таблице методов объекта-типа запись вызываемого метода, обрабатывает код JIT-компилятором (при необходимости) и вызывает полученный машинный код. В нашем случае вызывается реализация метода GenProgressReport в Manager, потому что е ссылается на объект Manager. Результат этой операции показан на рис, 4.12.
Заметьте, если метод Lookup в Employee обнаружит, что Зое — это всего лишь Employee, а не Manager, то Lookup создаст объект Employee, в котором указатель на объект-тип ссылается на объект-тип Employee; это приведет к тому, что выполнится реализация GenPnognessRepont из Employee, а не из Manager.
| Cm потока
Рис. 4.10. Статический метод Lookup в Employee выделяет память и инициализирует объект Manager для Joe |
|
Рис. 4.11. Невиртуальный экземплярный метод GetYarsEmployeed в Employee возвращает значение 5 |
Итак, мы обсудили взаимоотношения между исходным текстом, IL и машинным JIT-кодом, поговорили о стеке потока, аргументах и локальных переменных, а также о том, как эти аргументы и переменные ссылаются на объекты в управляемой куче. Мы также узнали, что объекты хранят указатель на свой объект-тип (содержащий
 |
статические поля и таблицу методов). Мы обсудили, как CLR вызывает статические методы, невиртуальные и виртуальные экземплярные методы. Все сказанное призвано дать вам более полную картину работы CLR и помочь при создании архитектуры, проектировании и реализации типов, компонентов и приложений. Заканчивая главу, я хотел бы сказать еще несколько слов о происходящем внутри CLR.
Наверняка вы обратите внимание, что объекты типа Employee и Manager содержат указатели на объекты-типы. По сути объекты-типы тоже являются объектами.
Создавая объект-тип, среда CLR должна его как-то инициализировать. Резонно спросить: «Какие значения будут присвоены при инициализации?» В общем, при своем запуске в процессе CLR сразу же создает специальный объект-тип для типа System.Туре (он определен в MSCorLib.dll). Объекты типа Employee и Manager являются «экземплярами» этого типа, и по этой причине их указатели на объекты-типы инициализируются ссылкой на объект-тип System.Туре (рис. 4.13).
Конечно, объект-тип System.Туре сам является объектом и поэтому также содержит указатель на объект-тип; значит, закономерно поинтересоваться, на что ссылается этот указатель. А ссылается он на самого себя, так как объект-тип System. Туре сам по себе является «экземпляром» объекта-типа. Теперь становится понятно, как устроена и работает вся система типов в CLR. Кстати, метод GetType типа System.Object просто возвращает адрес, хранящийся в указателе на объект-тип заданного объекта. Иначе говоря, метод GetType возвращает указатель на объект- тип указанного объекта и именно поэтому можно определить истинный тип любого объекта в системе (включая объекты-типы).
Глава 5. Примитивные, ссылочные и значимые типы
В этой главе речь идет о разновидностях типов, с которыми вы будете иметь дело при программировании для платформы Microsoft .NET Framework. Важно, чтобы все разработчики четко осознавали разницу в поведении типов. Приступая к изучению .NET Framework, я толком не понимал, в чем разница между примитивными, ссылочными и значимыми типами, в результате мой код получатся не слишком эффективным и содержал много коварных ошибок. Е1адеюсь, мой опыт и мои объяснения различий между этими типами помогут вам избавиться от лишних проблем и повысить производительность своей работы.
Примитивные типы в языках программирования
Некоторые типы данных применяются так часто, что для работы с ними во многих компиляторах предусмотрен упрощенный синтаксис. Например, целую переменную
можно создать следующим образом:
System.Int32 а = new System.Int32();
Конечно, подобный синтаксис для объявления и инициализации целой переменной кажется громоздким. К счастью, многие компиляторы (включая С#) позволяют использовать вместо этого более простые выражения, например:
int а = в;
Подобный код читается намного лучше, да и компилятор в обоих случаях генерирует идентичный IL-код для System. Int32. Типы данных, которые поддерживаются компилятором напрямую, называются примитивными (primitive types); у них существуют прямые аналоги в библиотеке классов .NET Framework Class Library (FCL). 1Тапример, типу int языка C# соответствует System Л nt32, поэтому весь следующий код компилируется без ошибок и преобразуется в одинаковые IL-команды:
int а = 0; // Самый удобный синтаксис
System.Int32 а = 0; // Удобный синтаксис int а = new int(); // Неудобный синтаксис
System.Int32 а = new System.Int32(); // Самый неудобный синтаксис
В табл. 5.1 представлены типы FCL и соответствующие им примитивные типы С#. В других языках типам, удовлетворяющим общеязыковой спецификации (Common Language Specification, CLS), соответствуют аналогичные примитивные типы. Однако поддержка языком типов, не удовлетворяющих требованиям CLS, не обязательна.
| Таблица 5.1. Примитивные типы C# и соответствующие типы FCL
продолжение &
|
| Таблица 5.1 (продолжение)
|
|
|
Иначе говоря, можно считать, что компилятор C# автоматически предполагает, что во всех файлах исходного кода есть следующие директивы using (как говорилось в главе 4):
using sbyte = System.SByte; using byte = System.Byte; using short = System.Intl6; using ushort = System.UIntl6; using int = System.Int32; using uint = System.UInt32;
Я не могу согласиться со следующим утверждением из спецификации языка С#: «С точки зрения стиля программирования предпочтительней использовать ключевое слово, а не полное системное имя типа», поэтому стараюсь задействовать имена FCT.-типов и избегать имен примитивных типов. На самом деле, мне бы хотелось, чтобы имен примитивных типов не было совсем, а разработчики употребляли только имена FCL-типов. И вот по каким причинам.
□ Мне попадались разработчики, не знавшие, какое ключевое слово использовать им в коде: string или String. В C# это не важно, так как ключевое слово string в точности преобразуется в FCL-тип System.String. Я также слышал, что некоторые разработчики говорили о том, что в 32-разрядных операционных системах тип int представлялся 32-разрядным типом, а в 64-разрядных — 64- разрядным типом. Это утверждение совершенно неверно: в C# тип int всегда преобразуется в System .Int32, поэтому он всегда представляется 32-разрядным типом безотносительно запущенной операционной системы. Использование ключевого слова Int32 в своем коде позволит избежать путаницы.
□ В C# long соответствует тип System. Int64, но в другом языке это может быть Intl6 или Int32. Как известно, в C++/CLI тип long трактуется как Int32. Если кто-то возьмется читать код, написанный на новом для себя языке, то назначение кода может быть неверно им истолковано. Многим языкам незнакомо ключевое слово long, и их компиляторы не пропустят код, где оно встречается.
□ У многих FCL-типов есть методы, в имена которых включены имена типов. Например, у типа BinaryReader есть методы ReadBoolean, Readlnt32, ReadSingle и т. д., а у типа System.Convert — методы ToBoolean, ToInt32, ToSingle и т. д.
Вот вполне приемлемый код, в котором строка, содержащая float, выглядит неестественно; даже возникает впечатление, что код ошибочен:
BinaryReader br = new BinaryReader(...);
float val = br.ReadSingle(); // Код правильный, но выглядит странно
Single val = br.ReadSingle(); // Код правильный и выглядит нормально
□ Многие программисты, пишущие исключительно на С#, часто забывают, что в CLR могут применяться и другие языки программирования. Например, среда FCL практически полностью написана на С#, а разработчики из команды FCL ввели в библиотеку такие методы, как метод GetLongLength класса Array, возвращающий значение Int64, которое имеет тип long в С#, но не в других языках программирования (например, C++/CLI). Другой пример — метод LongCount класса System.Linq.Enumerable.
По этим причинам я буду использовать в этой книге только имена FCL-типов. Во многих языках программирования следующий код благополучно скомпи- лируется и выполнится:
Int32 1=5;// 32-разрядное число
Int64 1=1;// Неявное приведение типа к 64-разрядному значению
Однако если вспомнить, что говорилось о приведении типов в главе 4, можно решить, что он компилироваться не будет. Все-таки System. Int32 и System. Int64, не являются производными друг от друга. Могу вас обнадежить: код успешно компилируется и делает все, что ему положено. Дело в том, что компилятор C# неплохо разбирается в примитивных типах и применяет свои правила при компиляции кода. Иначе говоря, он распознает наиболее распространенные шаблоны программирования и генерирует такие IL-команды, благодаря которым исходный код работает так, как требуется. В первую очередь, это относится к приведению типов, литералам и операторам, примеры которых мы рассмотрим позже.
Начнем с того, что компилятор выполняет явное и неявное приведение между примитивными типами, например:
| Int32 i = 5; | // | Неявное | приведение | Int32 | К | Int32 |
| Int64 1 = i; | // | Неявное | приведение | Int32 | к | Int64 |
| Single s = i; | // | Неявное | приведение | Int32 | к | Single |
| Byte b = (Byte) i; | // | Явное приведение Int32 к | Byte | |||
| Intl6 v = (Intl6) s; // Явное приведение Single к Intl6
|
C# разрешает неявное приведение типа, если это преобразование «безопасно», то есть не сопряжено с потерей данных; пример — преобразование из Int32 в Int64.
Однако для преобразования с риском потери данных C# требует явного приведения типа. Для числовых типов «небезопасное» преобразование означает «связанное с потерей точности или величины числа». Например, преобразование из Int32 в Byte требует явного приведения к типу, так как при больших величинах Int32 теряется точность; требует приведения и преобразование из Single в Int 16, поскольку число Single может оказаться больше, чем допустимо для Intl6.
Для реализации приведения разные компиляторы могут порождать разный код. Например, в случае приведения числа 6,8 типа Single к типу Int32 одни компиляторы сгенерируют код, который поместит в Int32 число 6, а другие округлят результат до 7. Между прочим, в C# дробная часть всегда отбрасывается. Точные правила приведения для примитивных типов вы найдете в разделе спецификаций языка С#, посвященном преобразованиям («Conversions»).
Помимо приведения, компилятор «знает» и о другой особенности примитивных типов: к ним применима литеральная форма записи. Литералы сами по себе считаются экземплярами типа, поэтому можно вызывать экземплярные методы, например, следующим образом:
Console .WriteLine(123. ToString() + 456.ToString()); // "123456"
Кроме того, благодаря тому, что выражения, состоящие из литералов, вычисляются на этапе компиляции, возрастает скорость выполнения приложения.
Boolean found = false; //В готовом коде found присваивается 0 Int32 х = 100 + 20 + 3; // В готовом коде х присваивается 123 String s = "а " + "Ьс"; // В готовом коде s присваивается "а Ьс"
И наконец, компилятор «знает», как и в каком порядке интерпретировать встретившиеся в коде операторы (в том числе +, *, /, %, &, л, |, ==, ! =, >, <, >=, <=,
<<, >>, ~, и т. п.):
Int32 х = 100; // Оператор присваивания
Int32 у = х + 23; // Операторы суммирования и присваивания
Boolean lessThanFifty = (у < 50); // Операторы "меньше чем" и присваивания
Проверяемые и непроверяемые операции для примитивных типов
Программистам должно быть хорошо известно, что многие арифметические операции над примитивными типами могут привести к переполнению:
Byte b = 100;
b = (Byte) (Ь + 200);// После этого Ь равно 44 (2С в шестнадцатеричной записи)
Такое «незаметное» переполнение обычно в программировании не приветствуется, и если его не выявить, приложение поведет себя непредсказуемо. Изредка, правда (например, при вычислении хеш-кодов или контрольных сумм), такое переполнение не только приемлемо, но и желательно.
ВНИМАНИЕ
При выполнении этой арифметической операции CLR на первом шаге все значения операндов расширяются до 32 разрядов (или 64 разрядов, если для представления операнда 32 разрядов недостаточно). Поэтому b и 200 (для которых 32 разрядов достаточно) сначала преобразуются в 32-разрядные значения, а затем уже суммируются. Полученное 32-разрядное число (300 в десятичной системе, 12С в шестнадцатеричной), прежде чем поместить его обратно в переменную Ь, нужно привести ктипу Byte. Так как в данном случае C# не выполняет неявного приведения типа, во вторую строку введена операция приведения ктипу Byte.
В каждом языке существуют свои свособы обработки переполнения. В С и C++ переполнение отпибкой не считается, а при усечении значений приложение не прервет свою работу. А вот в Visual Basic переполнение всегда рассматривается как ошибка, и при его обнаружении генерируется исключение.
В CLR есть IL-команды, позволяющие компилятору по-разному реагировать на переполнение. Например, суммирование двух чисел выполняет команда add, не реагирующая на переполнение, а также команда add. ovf, которая при переполнении генерирует исключение System.OverflowException. Кроме того, в CLR есть аналогичные IL-команды для вычитания (sub/sub. ovf), умножения (mul/mul. ovf) и преобразования данных (conv/conv.ovf).
Пишущий на C# программист может сам решать, как обрабатывать переполнение; по умолчанию проверка переполнения отключена. Это значит, что компилятор генерирует для операций сложения, вычитания, умножения и преобразования IL- команды без проверки переполнения. В результате код выполняется быстро, но разработчик должен быть либо уверен в отсутствии переполнения, либо предусмотреть возможность его возникновения в своем коде.
Чтобы включить механизм управления процессом обработки переполнения на этапе компиляции, добавьте в командную строку компилятора параметр /checked+. Он сообщает компилятору, что для выполнения сложения, вычитания, умножения и преобразования должны быть сгенерированы IL-команды с проверкой переполнения. Такой код медленнее, так как CLR тратит время на проверку этих операций, ожидая переполнение. Когда оно возникает, CLR генерирует исключение OverflowException. Код приложения должен предусматривать корректную обработку этого исключения.
Однако программистам вряд ли понравится необходимость включения или отключения режима проверки переполнения во всем коде. Им лучше самим решать, как реагировать на переполнение в каждом конкретном случае. И C# предлагает такой механизм гибкого управления проверкой в виде операторов checked и unchecked. Например (предполагается, что компилятор по умолчанию создает код без проверки):
UInt32 invalid = unchecked((UInt32) -1); // OK
А вот пример с использованием оператора checked:
Byte b = 100; П Выдается исключение
b = checked((Byte) (b + 200)); // OverflowException
Здесь b и 200 преобразуются в 32-разрядные числа и суммируются; результат равен 300. Затем при преобразовании 300 в Byte генерируется исключение OvenflowException. Если приведение к типу Byte вывести из оператора checked, исключения не будет:
b = (Byte) checked(b + 200); // b содержит 44; нет OverflowException
Наряду с операторами checked и unchecked в C# есть одноименные инструкции, позволяющие включить проверяемые или непроверяемые выражения внутрь блока:
checked { // Начало проверяемого блока
Byte b = 100;
b = (Byte) (b + 200); // Это выражение проверяется на переполнение } // Конец проверяемого блока
Кстати, внутри такого блока можно задействовать оператор += с Byte, который немного упростит код:
checked { // Начало проверяемого блока
Byte b = 100;
b += 200; // Это выражение проверяется на переполнение
} // Конец проверяемого блока
ВНИМАНИЕ
Установка режима контроля переполнения не влияет на работу метода, вызываемого внутри оператора или инструкции checked, так как действие оператора (и инструкции) checked распространяется только на выбор IL-команд сложения, вычитания, умножения и преобразования данных. Например:
checked {
// Предположим, SomeMethod пытается поместить 400 в Byte SomeMethod(400);
// Возникновение OverflowException в SomeMethod // зависит от наличия в нем операторов проверки
}
Я видел немало вычислений, генерирующих непредсказуемые результаты. Обычно это случается из-за неправильного ввода данных пользователем или же из-за возвращения неожиданных значений переменных. Итак, я рекомендую программистам соблюдать следующие правила при использовании операторов checked и unchecked.
□ Используйте типы со знаком (Int32 и Int64) вместо числовых типов без знака (UInt32 и UInt64) везде, где это возможно. Это позволит компилятору выявлять ошибку переполнения. Кроме того, некоторые компоненты библиотеки классов (например, свойства Length классов Array и String) жестко запрограммированы на возвращение значений со знаком, и передача этих значений в коде потребует меньшего количества преобразований типа (а следовательно, упр<ютит структуру кода и его сопровождение). Кроме того, числе>вые типы без знака несовместимы с CLS.
□ Включайте в блок checked ту часть кода, в которой возможно переполнение из- за неверных входных данных, например при обработке запросов, содержащих данные, предоставленные конечным пользователем или клиентской машиной. Возможно, также стоит перехватывать исключение OverflowException, чтобы ваше приложение могло корректно продолжить работу после таких сбоев.
□ Включайте в блок unchecked те фрагменты кода, в которых переполнение не п >здает 11р<)блем (например, при вычислении контрольной суммы).
□ В коде, где нет операторов и блоков checked и unchecked, предполагается, что при переполнении должно происходить исключение. Например, при вычислении простых чисел входные данные известны, а переполнение является признаком ошибки.
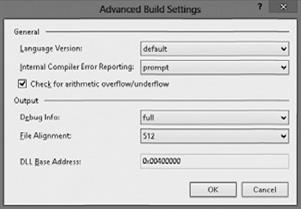
В процессе отладки кода установите параметр компилятора/checked+. Вы пол немце приложения замедлится, так как система будет контролировать переполнение во всем коде, не помеченном ключевыми словами checked или unchecked. Обнаружив исключение, мы сможете легко обнаружить его и исправить ошибку. В окончательной сборке приложения установите параметр /checked-, что ускорит выполнение приложения; исключения при этом генерироваться не будут. Для того чтобы изменить значение параметра checked в Microsoft Visual Studio, откройте окно свойств вашего проекта, перейдите на вкладку Build, щелкните на кнопке Advanced и установите флажок Check for arithmetic overflow/underflow. как это показано на рис. .5.1.
|
Рис. 5.1. Изменение применяемых по умолчанию параметров компилятора Visual Studio в окне Advanced Build Settings |
В случае если для вашего при. к >жения производительность не критична, я реке>- мендую оставлять параметр /checked включенным даже в окончательной версии.
Это позволит защитить приложение от некорректных данных и брешей в системе безопасности. Например, если при вычислении индекса массива используется исключение, лучше получить исключение OverflowException, чем обратиться к неверному элементу массива из-за переполнения.
ВНИМАНИЕ
Тип System. Decimal стоит особняком. В отличие от многих языков программирования (включая C# и Visual Basic), в CLR тип Decimal не относится к примитивным типам. В CLR нет IL-команд для работы со значениями типа Decimal. В документации по .NET Framework сказано, что тип Decimal имеет открытые статические методы-члены Add, Subtract, Multiply, Divide и прочие, а также перегруженные операторы +, / и т. д.
При компиляции кода с типом Decimal компилятор генерирует вызовы членов Decimal, которые и выполняют реальную работу. Поэтому значения типа Decimal обрабатываются медленнее примитивных CLR-типов. Кроме того, раз нет IL-команд для манипуляции числами типа Decimal, то не будут иметь эффекта ни операторы checked и unchecked, ни соответствующие параметры командной строки компилятора, а неосторожность в операциях над типом Decimal может привести к исключению OverflowException.
Аналогично, тип System.Numerics.Biglnteger используется в массивах Ulnt32 для представления большого целочисленного значения, не имеющего верхней или нижней границы. Следовательно, операции с типом Biglnteger никогда не вызовут исключения OverflowException. Однако они могут привести к выдаче исключения OutOfMemoryException, если значение переменной окажется слишком большим.
Ссылочные и значимые типы
CLR поддерживает две разновидности типов: ссылочные (reference types) и значимые (value types). Большинство типов в FCL — ссылочные, но программисты чаще всего используют значимые. Память для ссылочных типов всегда выделяется из управляемой кучи, а оператор C# new возвращает адрес в памяти, где размещается сам объект. При работе со ссылочными типами необходимо учитывать следующие обстоятельства, относящиеся к производительности приложения:
□ память для ссылочных типов всегда выделяется из управляемой кучи;
□ каждый объект, размещаемый в куче, содержит дополнительные члены, подлежащие инициализации;
□ незанятые полезной информацией байты объекта обнуляются (это касается полей);
□ размещение объекта в управляемой куче со временем инициирует сборку мусора.
Если бы все типы были ссылочными, эффективность приложения резко упала бы. Представьте, насколько замедлилось бы выполнение приложения, если бы при
каждом обращении к значению типа Int32 выделялась память! Поэтому, чтобы ускорить обработку простых, часто используемых типов CLR предлагает «облегченные» типы — значимые. Экземпляры этих типов обычно размещаются в стеке потока (хотя они могут быть встроены и в объект ссылочного типа). В представляющей экземпляр переменной нет указателя на экземпляр; поля экземпляра размещаются в самой переменной. Поскольку переменная содержит поля экземпляра, то для работы с экземпляром не нужно выполнять разыменование (dereference) экземпляра. Благодаря тому, что экземпляры значимых типов не обрабатываются уборщиком мусора, уменьшается интенсивность работы с управляемой кучей и сокращается количество сеансов уборки мусора, необходимых приложению на протяжении его существования.
В документации на .NET Framework можно сразу увидеть, какие типы относят к ссылочным, а какие — к значимым. Если тип называют классом (class), речь идет о ссылочном типе. Например, классы System.Object, System.Exception, System.10. FileStream и System.Random — это ссылочные типы. В свою очередь, значимые типы в документации называются структурами (structure) и перечислениями (enumeration). Например, структуры System.Int32, System.Boolean, System.Decimal, System.TimeSpan и перечисления System.DayOfWeek, System. 10. FileAttributes и System.Drawing. FontStyle являются значимыми типами.
Все структуры являются прямыми потомками абстрактного типа System. ValueType, который, в свою очередь, является производным от типа System. Object. По умолчанию все значимые типы должны быть производными от System. ValueType. Все перечисления являются производными от типа System. Enum, производного от System.ValueType. CLR и языки программирования по-разному работают с перечислениями. О перечислимых типах см. главу 15.
При определении собственного значимого типа нельзя выбрать произвольный базовый тип, однако значимый тип может реализовать один или несколько выбранных вами интерфейсов. Кроме того, в CLR значимый тип является изолированным, то есть он не может служить базовым типом для какого-либо другого ссылочного или значимого типа. Поэтому, например, нельзя в описании нового типа указывать в качестве базовых типы Boolean, Char, Int32, Uint64, Single, Double, Decimal и т. д.
ВНИМАНИЕ
Многим разработчикам (в частности, тем, кто пишет неуправляемый код на C/C++) деление на ссылочные и значимые типы поначалу кажется странным. В неуправляемом коде C/C++ вы объявляете тип, и уже код решает, куда поместить экземпляр типа: в стек потока или в кучу приложения. В управляемом коде иначе: разработчик, описывающий тип, указывает, где должны размещаться экземпляры данного типа, а разработчик, использующий тип в своем коде, управлять этим не может.
В следующем коде (и на рис. 5.2) продемонстрировано различие между ссылочными и значимыми типами:
// Ссылочный тип (поскольку ’class') class SomeRef { public Int32 x; }
// Значимый тип (поскольку 'struct') struct SomeVal { public Int32 x; }
static void ValueTypeDemo() {
SomeRef rl = new SomeRef(); // Размещается в куче
SomeVal vl = new SomeValQ; // Размещается в стеке
rl.x = 5; // Разыменовывание указателя vl.x = 5; // Изменение в стеке Console.WriteLine(rl.x); // Отображается "5"
Console.WriteLine(vl.x); // Также отображается "5"
// В левой части рис. 5.2 показан результат // выполнения предыдущих строк
SomeRef r2 = rl; // Копируется только ссылка (указатель)
SomeVal v2 = vl; // Помещаем в стек и копируем члены
rl.x = 8; // Изменяются rl.x и г2.х vl.x = 9; // Изменяется vl.x, но не v2.x Console.WriteLine(rl.x); // Отображается "8"
Console.WriteLine(r2.x); // Отображается "8"
Console.WriteLine(vl.x); // Отображается "9"
Console.WriteLine(v2.x); // Отображается "5"
// В правой части рис. 5.2 показан результат // выполнения ВСЕХ предыдущих строк
 |  | ||
}
Рис. 5.2. Разница между размещением в памяти значимых и ссылочных типов
В этом примере тип SomeVal объявлен с ключевым словом struct, а не более распространенным ключевым словом class. В C# типы, объявленные как struct, являются значимыми, а объявленные как class, — ссылочными. Между поведением
ссылочных и значимых типов существуют существенные различия. Поэтому так важно представлять, к какому семейству относится тот или иной тип — к ссылочному или значимому: ведь это может существенно повлиять на то, как вы выражаете свои намерения в коде.
В предыдущем примере есть следующая строка:
SomeVal vl = new SomeValQ; // Размещается в стеке
Может показаться, что экземпляр SomeVal будет помещен в управляемую кучу. Однако поскольку компилятор C# «знает», что SomeVal является значимым типом, в сгенерированном им коде экземпляр SomeVal будет помещен в стек потока. C# также обеспечивает обнуление всех полей экземпляра значимого типа.
Ту же строку можно записать иначе:
SomeVal vl; // Размещается в стеке
Здесь тоже создается IL-код, который помещает экземпляр SomeVal в стек потока и обнуляет все его поля. Единственное отличие в том, что экземпляр, созданный оператором new, C# «считает» инициализированным. Поясню эту мысль на следующем примере:
// Две следующие строки компилируются, так как C# считает,
// что поля в vl инициализируются нулем SomeVal vl = new SomeValQ;
Int32 a = vl.x;
// Следующие строки вызовут ошибку компиляции, поскольку C# не считает,
// что поля в vl инициализируются нулем SomeVal vl;
Int32 а = vl.x;
// error CS0170: Use of possibly unassigned field 'x'
// (ошибка CS0170: Используется поле 'x', которому не присвоено значение)
Проектируя свой тип, проверьте, не использовать ли вместо ссылочного типа значимый. Иногда это позволяет повысить эффективность кода. Сказанное особенно справедливо для типа, удовлетворяющего всем перечисленным далее условиям.
□ Тип ведет себя подобно примитивному типу. В частности, это означает, что тип достаточно простой и у него нет членов, способных изменить экземплярные поля типа, в этом случае говорят, что тип неизменяемый (immutable). На самом деле, многие значимые типы рекомендуется помечать спецификатором readonly (см. главу 7).
□ Тип не обязан иметь любой другой тип в качестве базового.
□ Тип не имеет производных от него типов.
Также необходимо учитывать размер экземпляров типа, потому что по умолчанию аргументы передаются по значению; при этом поля экземпляров значимого типа копируются, что отрицательно сказывается на производительности. Повторюсь: для метода, возвращающего значимый тип, поля экземпляра копируются в память, выделенную вызывающим кодом в месте возврата из метода, что снижает эффективность работы программы. Поэтому в дополнение к перечисленным условиям следует объявлять тип как значимый, если верно хотя бы одно из следующих условий:
□ Размер экземпляров типа мал (примерно 16 байт или меньше).
□ Размер экземпляров типа велик (более 16 байт), но экземпляры не передаются в качестве параметров метода или не являются возвращаемыми из метода значениями.
Основное достоинство значимых типов в том, что они не размещаются в управляемой куче. Конечно, в сравнении со ссылочными типами у значимых типов есть недостатки. Важнейшие отличия между значимыми и ссылочными типы:
□ Объекты значимого типа существуют в двух формах (см. следующий раздел): неупакованной (unboxed) и упакованной (boxed). Ссылочные типы бывают только в упакованной форме.
□ Значимые типы являются производными от System. ValueType. Этот тип имеет те же методы, что и System.Object. Однако System. ValueType переопределяет метод Equals, который возвращает true, если значения полей в обоих объектах совпадают. Кроме того, в System.ValueType переопределен методGetHashCode, который создает хеш-код по алгоритму, учитывающему значения полей экземпляра объекта. Из-за проблем с производительностью в реализации по умолчанию, определяя собственные значимые типы значений, надо переопределить и написать свою реализацию методов Equals и GetHashCode. О методах Equals и GetHashCode рассказано в конце этой главы.
□ Поскольку в объявлении нового значимого или ссылочного типа нельзя указывать значимый тип в качестве базового класса, создавать в значимом типе новые виртуальные методы нельзя. Методы не могут быть абстрактными и неявно являются запечатанными (то есть их нельзя переопределить).
□ Переменные ссылочного типа содержат адреса объектов в куче. Когда переменная ссылочного типа создается, ей по умолчанию присваивается null, то есть в этот момент она не указывает на действительный объект. Попытка задействовать переменную с таким значением приведет к генерации исключения NullReferenceException. В то же время в переменной значимого типа всегда содержится некое значение соответствующего типа, а при инициализации всем членам этого типа присваивается 0. Поскольку переменная значимого типа не является указателем, при обращении к значимому типу исключение NullReferenceException возникнуть не может. CLR поддерживает понятие значимого типа особого вида, допускающего присваивание null (nullable types). Этот тип обсуждается в главе 19.
□ Когда переменной значимого типа присваивается другая переменная значимого типа, выполняется копирование всех ее полей. Когда переменной ссылочно
го типа присваивается переменная ссылочного типа, копируется только ее адрес.
□ Вследствие сказанного в предыдущем пункте несколько переменных ссылочного типа могут ссылаться на один объект в куче, благодаря чему, работая с одной переменной, можно изменить объект, на который ссылается другая переменная. В то же время каждая переменная значимого типа имеет собственную копию данных «объекта», поэтому операции с одной переменной значимого типа не влияют на другую переменную.
□ Так как неупакованные значимые типы не размещаются в куче;, отведенная для них память освобождается сразу при возвращении управления методом, в котором описан экземпляр этого типа (в отличие от ожидания уборки мусора).
Как CLR управляет размещением полей для типа
Для повышения производительности CLR дано право устанавливать порядок размещения полей типа. Например, CLR может выстроить поля таким образом, что ссылки на объекты окажутся в одной группе, а поля данных и свойства — выровненные и упакованные — в другой. Однако при описании типа можно указать, сохранить ли порядок полей данного типа, определенный программистом, или разрешить CLR выполнить эту работу.
Для того чтобы сообщить CLR способ управления полями, укажите в описании класса или структуры атрибут System.Runtime.InteropServices.StructLayout- Attnibute. Чтобы порядок полей устанавливался CLR, нужно передать конструктору атрибута параметр LayoutKind .Auto, чтобы сохранить установленный программистом порядок — параметр LayoutKind .Sequential, а параметр LayoutKind. Explicit позволяет разместить поля в памяти, явно задав смещения. Если в описании типа не применен атрибут StructLayoutAttribute, порядок полей выберет компилятор.
Для ссылочных типов (классов) компилятор C# выбирает вариант LayoutKind. Auto, а для значимых типов (структур) — LayoutKind. Sequential. Очевидно, разработчики компилятора считают, что структуры обычно используются для взаимодействия с неуправляемым кодом, а значит, поля нужно расположить так, как определено разработчиком. Однако при создании значимого типа, не работающего совместно с неуправляемым кодом, скорее всего, поведение компилятора, предлагаемое по умолчанию, потребуется изменить, например:
using System;
using System.Runtime.InteropServices;
 |
// Для повышения производительности разрешим CLR // установить порядок полей для этого типа [StructLayout(LayoutKind.Auto)] internal struct SomeValType { private readonly Byte m_b;
private readonly Intl6 m_x;
>
Атрибут StructLayoutAttribute также позволяет явно задать смещение для всех полей, передав в конструктор LayoutKind. Explicit. Затем можно применить атрибут System. Runtime. InteropServices. FieldOf f setAttribute ко всем полям путем передачи конструктору этого атрибута значения типа Int32, определяющего смещение (в байтах) первого байта поля от начала экземпляра. Явное размещение обычно используется для имитации того, что в неуправляемом коде на C/C++ называлось объединением (union), то есть размещения нескольких полей с одного смещения в памяти, например:
using System;
using System.Runtime.InteropServices;
// Разработчик явно задает порядок полей в значимом типе [StructLayout(LayoutKind. Explicit) ] internal struct SomeValType {
[FieldOffset(O)]
private readonly Byte m_b; // Поля mb и m_x перекрываются
[FieldOffset(O)]
private readonly Intl6 m_x; // в экземплярах этого класса
}
Не допускается определение типа, в котором перекрываются ссылочный и значимый типы. Можно определить тип, в котором перекрываются несколько значимых типов, однако все перекрывающиеся байты должны быть доступны через открытые поля, чтобы обеспечить верификацию типа.
Упаковка и распаковка значимых типов
Значимые типы «легче» ссылочных: для них не нужно выделять память в управляемой куче, их не затрагивает сборка мусора, к ним нельзя обратиться через указатель. Однако часто требуется получать ссылку на экземпляр значимого типа, например если вы хотите сохранить структуры Point в объекте типа ArrayList (определен в пространстве имен System.Collections). В коде это выглядит примерно следующим образом:
// Объявляем значимый тип struct Point {
public Int32 x, у;
}
public sealed class Program { public static void Main() {
ArrayList а = new ArrayListQ;
Point р; // Выделяется память для Point (не в куче)
for (Int32 i = 0; i < 10; i++) {
p.x = p.y = i; // Инициализация членов в нашем значимом типе a.Add(p); // Упаковка значимого типа и добавление
// ссылки в ArrayList
>
>
>
В каждой итерации цикла инициализируются поля значимого типа Point, после чего Point помещается в ArrayList. Задумаемся, что же помещается в ArrayList: сама структура Point, адрес структуры Point или что-то иное? За ответом обратимся к методу Add типа ArrayList и посмотрим описание его параметра. В данном случае прототип метода Add выглядит следующим образом:
public virtual Int32 Add(Object value);
Отсюда видно, что в параметре Add должен передаваться тип Ob j ect, то есть ссылка (или указатель) на объект в управляемой куче. Однако в примере я передаю переменную р, имеющую значимый тип Point. Чтобы код работал, нужно преобразовать значимый тип Point в объект из управляемой кучи и полу чип, на него ссылку.
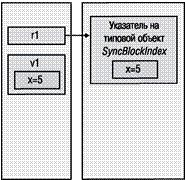
Для преобразования значимого типа в ссылочный служит упаковка (boxing). При упаковке экземпляра значимого типа происходит следующее.
1. В управляемой куче выделяется память. Ее объем определяется длиной значимого типа и двумя дополнительными членами — указателем на типовой объект и индексом блока синхронизации. Эти члены необходимы для всех объектов в управляемой куче.