
2. Время на выполнения заданий – 90 минут (надеюсь на Вашу честность)








Сегодня, вам предлагается пройти Python Challenge.
Начать задания можно по ссылке: http://www.pythonchallenge.com
Первые пару заданий мы разберем, а дальше все будет зависеть от Вас!
Давайте введем ряд ограничений:
1. Первые три задания не учитываются (мы их сейчас разберем)
2. Время на выполнения заданий – 90 минут (надеюсь на Вашу честность)
3. Не подглядыввать!
Итак, начнем.
Дизайн сайта оставляет желать лучшего, но мы пришли делать задания, переходим по адресу:
И нажимаем по ссылке.
Задание 1:

Под заданием есть подсказка: «Попробуй изменить URL-адрес», поскольку мы работаем из браузера, смотрим в адресную строку:
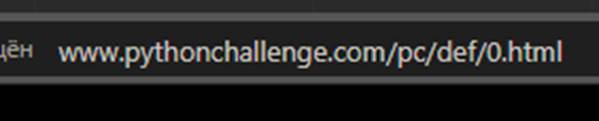
На картинке нам предлагается некоторое числовое значение, попробуем изменить адрес, дописав в конце 238. html:
| Адрес | Ответ |

| 
|
По данному адресу лежит еще одна подсказка: «Нет… значение 38 немного выше чем двойка…». Включаем немножко математики и находим значение выражения 238, ну и поскольку это Python Challenge, то используем Python, для этого нам хватит и консоли:
| Консоль | Ответ |
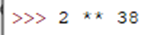
| 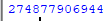
|
|
| |
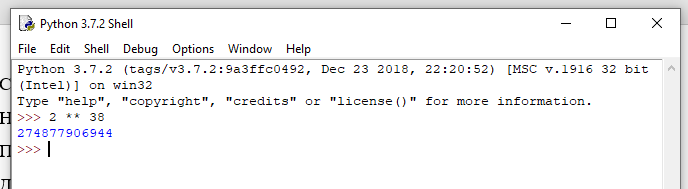
Вставляем полученное значение в адресную строку:
| Адрес | Ответ |

| 
|
И попадаем на новое задание!
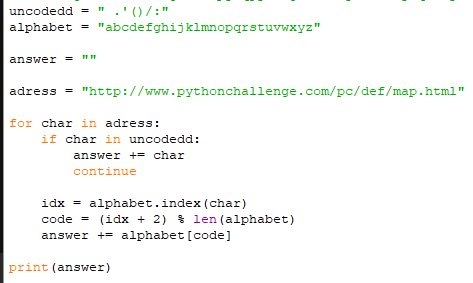
Здесь нам предлагают текст, и картинку-подсказку. Если представить алфавитный ряд на английском языке и примерить смещение на картинке, то получаем следующее:
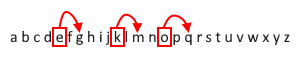
Получаем смещение, подобное шифру Цезаря, когда буква кодируется смещением её индекса в алфавите.
Всегда есть два варианта: примерить смещение вручную, и написать небольшой скрипт, который сделает это за нас.
Поскольку программисты наделены способностью автоматизировать рутинные процессы, напишем небольшой скрипт, который решает эту задачу. Для начала определим переменные, которые необходимы:

Хех, а теперь ближе:
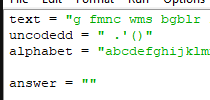
1. text – переменная, содержащая исходный текст
2. uncoded – символы, которые не поддаются кодированию (по тексту это точка, пробел, апостроф и круглые скобки); такие символы просто пропускаются
3. alphabet – исходный алфавит кодирования (в нашем случае – латинский)
4. answer – переменная, в которую мы будем записывать ответ
Теперь непосредственно к алгоритму:
1. Перебираем символы из переменной text
2. Если символ в переменной uncoded, то дописываем его в answer и переходим к следующему шагу
3. Получаем индекс символа в алфавите
4. Получаем смещение символа (на две позиции)
5. Дописываем смещенный символ в answer

Ну и в конце выводим answer:

Разработчики надеются, что вы не переводили текст руками и использовали для этого скрипты. Для этого текст и сделан таким длинным. Также нам подсказывают, что в python есть встроенные функции для работы со смещениями: string.maketrans() (но, мы же крутые разработчики и написали все сами). А теперь, предлагается применить полученный алгоритм к адресной строке. Копируем адрес страницу с заданием и прогоняем его через наш алгоритм:
| Код | Результат |
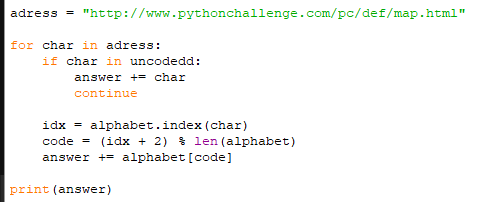
| Ошибка, в строке присутствуют символы, отсутствующие в алфавите. |
| Дополним переменную uncoded двоеточием и символом «/» | |
| jvvr://yyy.ravjqpejcnngpig.eqo/re/fgh/ocr.jvon |
| такого адреса не существует в принципе, по этому просто сократим адрес до названия целевой страницы (map. html) | |

| ocr.jvon |
| Попробуем дописать ocr. jvon в адресную строку | |

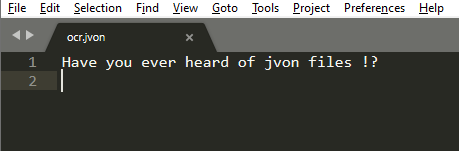
| В ответ получаем файл ocr.jvon, открываем его и смотрим, что внутри! |
|
А внутри файла небольшая насмешка от разработчиков: «Вы когда-нибудь видели расширение у файла JVON!?». | |
Ну и последнее, что осталось, перейти по адресу:
http://www.pythonchallenge.com/pc/def/ocr.html
(заменяем jvon на html)
И попадаем на третье задание:

Нам предлагают расшифровать текст, и подсказывают, что может быть текст в книге, но МОЖЕТ БЫТЬ в ресурсах страницы.
Немного включив разработчика и после пары неудачных попыток, получаем HTML-ресурсы страницы, для этого переходим в панель разработчика (F12 в браузере):
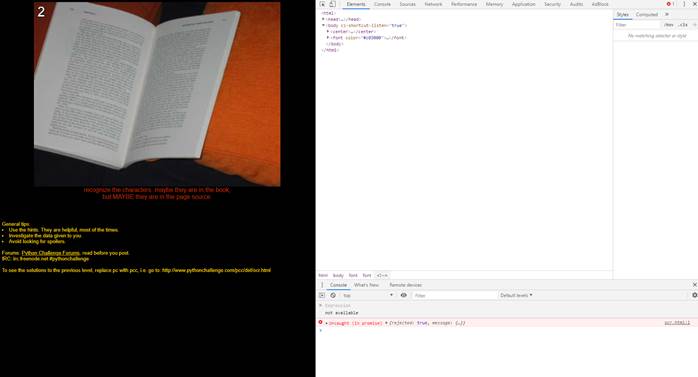
На первый взгляд стандартная HTML-страница. Придется поискать странности, поочередно смотрим элементы:
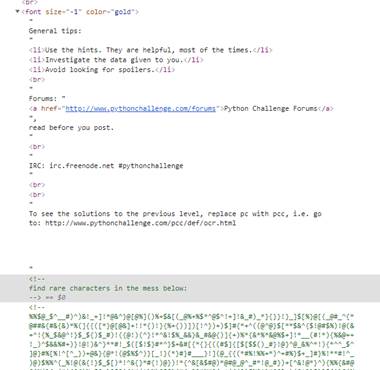
В конце концов находим скрытый текст на странице и задание к нему: «Среди хаоса символов, найдите уникальные»
Ну что, напишем небольшой скрипт (на 1246 строк), который за это отвечает:
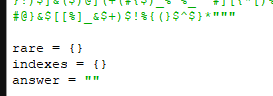
Нам понадобятся переменные:
1. text – исходный текст для поиска
2. rare – список в котором будем считать количество каждого символа
3. indexes – список, в котором будем хранить последний индекс символа
4. answer – для записи ответа
Переменная text (скопируйте текст из файла 3.txt):

Остальные переменные:
По алгоритму все предельно просто:
1. Перебираем символы исходного текста
2. Если такой символ уже существует в нашем списке, то прибавляем к счетчику 1 и запоминаем его индекс
3. Если символ нам еще не встречался, то записываем его в оба списка

Далее, избавляемся от элементов, у которых счетчик больше нуля:

Сортируем оставшиеся значения относительно их индексов:

И формируем ответ:

Если все сделано правильно, в ответе получится слово, которое необходимо вставить в адресную строку и перейти к четвертому заданию:

В слове 8 букв.
Удачных дальнейших заданий!