
Вывод к первому разделу








В ходе выполнения первого раздела выпускной квалификационной работы был проведен анализ предметной области, изучена актуальная литература, рассмотрены особенности рынка, правовое регулирование интернета, а также проведен анализ рынка интернет-провайдера, которые присутствуют на рынке.
Основной целью работы является проектирование структуры интернет-провайдера, которой будет вести свою деятельность в г. Ухта.
Цель проекта состоит в создании структуры интернет-провайдера, которая будет обеспечивать абонентскую емкость сетевой и сервисной инфраструктуры провайдера, а также автоматизировать процессы локализации аварий и проблем на сети и абонентских узлах.
На основании приведенных данных можно сделать вывод, что при правильной организации работы компании-субпровайдера, арендуя канал связи вышестоящего провайдера, будет несложно получить достаточное количество абонентов и обеспечить хорошую стабильную прибыль. Но перед реализацией проекта крайне необходимо провести детальный анализ конъюнктуры рынка, чтобы определиться, в каком направлении следует действовать для обеспечения максимально эффективного результата.
2. Проектирование информационной системы
В ходе проектирования информационной системы будет выполнен выбор архитектурных и программных решений, а также выполнена разработка функциональных моделей с применением принципов концептуального, логического и физического моделирований, будут разработаны модели данных.
2.1 Выбор архитектурного решения
В зависимости от оператора сеть может быть организована на основе нескольких технологий. Зачастую используются технологии Ethernet и PON, все зависит от предпочтений провайдера, списка востребованных услуг, плотности абонентов и еще многих факторов. В нашей статье мы будем рассматривать классическую Ethernet сеть, развернутую в рамках города с высокой плотностью абонентов.
Для наглядности рассмотрим схему сети интернет-провайдера, основанную на модели OSI, но заметим, что «в жизни» схема сети модифицируется и перерабатывается провайдером в рамках собственных задач и возможностей.
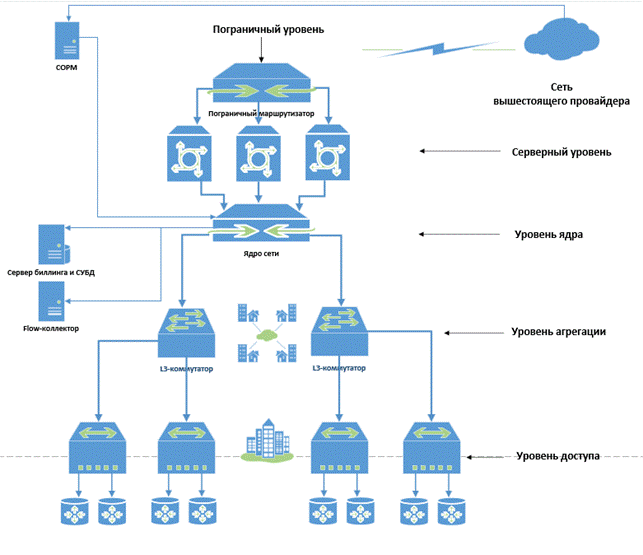
Рисунок 1 – Модель структуры локальной фирмы-провайдера
1. Пограничный уровень – граница сети провайдера, стык с другими операторами. На этом уровне обычно ведется работа с магистральными операторами, которые предоставляют интернет-трафик. Реализуется при помощи пограничного маршрутизатора или L3-коммутатора. Данный уровень представляет собой границу между локальной сетью провайдера и Интернетом
2. Серверный уровень – представляет собой кластер серверов, необходимых для работы провайдера. Может быть реализован, как на серверных платформах, так и при помощи специализированного оборудования. В данный уровень входят: DHCP-сервер, DNS-сервер, сервер AAA (radius или diameter), биллинг-сервер, СОРМ, сервисы развлечений для пользователей, серверы контента. Часто данный уровень сети объединяют с уровнем ядра сети. Серверный уровень, по факту являясь неотъемлемой частью ядра сети. Его подключение также требует резервирования для обеспечения бесперебойности работы сервисов. В связи с небольшими расстояниями между оборудованием, в пределах машинного зала или здания, на этом уровне сети распространены трансиверы для «коротких» соединений. В основном все соединения имеют скорость передачи 10 Гбит/с и 40 Гбит/с.
3. Уровень ядра сети – коммутаторы ядра сети, которые распределяют трафик по всей сети. Реализуется на маршрутизаторах или L3-коммутаторах. Уровень ядра сети самый ответственный, на нем важна и высокая производительность, и максимальная отказоустойчивость. Резервирование оборудования ядра сети производится с использованием топологии «каждый-с-каждым» и физическим резервированием каналов связи и сервисов. Расстояние между активным сетевым оборудованием на данном уровне может составлять как десятки метров и находиться в рамках одного здания, так и десятков километров с разнесением ядра сети на несколько площадок.
4. Уровень агрегации – это уровень распределения трафика между ядром сети и абонентами. Как правило, для организации данного уровня сети используются L3-коммутаторы. Коммутаторы уровня агрегации подключаются к ядру сети по топологии «Звезда», реже применяется топология «Шина». Объем и скорость передаваемой информации на этом уровне сети заметно выше, чем на уровне доступа. Для организации каналов связи «агрегация – ядро сети» зачастую используются трансиверы со скоростью передачи 10 Гбит/с. В зависимости от схемы прокладки оптических кабелей и их волоконной емкости на уровне агрегации, могут применяться технологии спектрального уплотнения WDM и CWDM, в основном это вызвано дефицитом волокон и необходимостью их экономить. В случае, если уровень агрегации подключается к ядру сети по топологии «Звезда» с организацией одного канала 10 Гбит/с, с каждой точки агрегации логично использовать WDM трансиверы форм-фактора SFP+ или XFP (форм-фактор зависит от используемых коммутаторов агрегации).
5. Уровень доступа – это точка клиентского доступа. Чаще всего в качестве активного сетевого оборудования используются простые L2-коммутаторы. В качестве коммутатора доступа, расположенного на чердаке или в подвале многоквартирного дома, зачастую используются бюджетное и неприхотливое оборудование такое как L2-коммутатор Dlink 3200 или SNR 2960.
2.2 Выбор программных решений
2.2.1 Структура данных
Успешная компания сегодня должна принимать множество различных решений. И чем более обоснованные решения будут приняты, тем большего успеха и прибыли достигнет предприятие. Для многих лиц, играющих ключевую роль в принятии решений, способность быстрее и эффективнее конкурента анализировать бизнес-процессы означает принятие более правильных решений, достижение большей прибыльности и большего успеха. Оптимизация реляционной базы данных предоставила компаниям возможность продуктивно собирать данные о транзакциях, поставляя информации лицам, принимающим решения. Тем не менее, имеется верхний предел объема данных, который может содержаться в реляционной базе данных, при котором еще сохраняется возможность достаточно эффективно осуществлять анализ.
MOLAP (Multidimensional OLAP) – для реализации многомерной модели используют многомерные БД;
MOLAP‑серверы используют для хранения и управления данными многомерные БД. При этом данные хранятся в виде упорядоченных многомерных массивов. Индексами таких массивов являются измерения. Многомерные массивы подразделяются на гиперкубы и поликубы. В гиперкубе все хранимые в БД ячейки имеют полный набор измерений. В поликубе каждая ячейка хранится с собственным набором измерений, и все связанные с этим сложности обработки перекладываются на внутренние механизмы системы.
Физически данные, представленные в многомерном виде, хранятся в "плоских" файлах. При этом куб представляется в виде одной плоской таблицы, в которую построчно вписываются все комбинации членов всех измерений с соответствующими им значениями мер.
"+" многомерных БД: высокая скорость поиска и выборки данных, т. к. многомерная база данных денормализована, содержит заранее агрегированные показатели и обеспечивает доступ к запрашиваемым ячейкам без дополнительных преобразований при переходе от множества связанных таблиц к многомерной модели.
В подавляющем большинстве случаев информационный гиперкуб является сильно разреженным. Серьезным недостатком многомерных баз данных является низкий коэффициент использования памяти при хранении разреженных данных. Это объясняется тем, что требуется заранее резервировать место для всех значений, даже если многие из значений будут отсутствовать. Кроме того, структуру многомерной базы очень сложно модифицировать. Например, добавление нового измерения требует полной перестройки гиперкуба.
Использование MOLAP является эффективным, если объем исходных данных для анализа не слишком велик, набор информационных измерений стабилен и время ответа системы на нерегламентированные запросы является наиболее критичным параметром.
ROLAP (Relational OLAP) – для реализации многомерной модели используют специальную организацию реляционных БД;
HOLAP (Hybrid OLAP) – для реализации многомерной модели используют сочетание многомерных и реляционных БД.
В технологии ROLAP гиперкуб эмулируется на логическом уровне средствами реляционной базы данных. При эмуляции чаще всего используется так называемая радиальная схема, или схема "звезда". В этой схеме используются два вида таблиц: таблица фактов и таблицы измерений.
Запись таблицы факта соответствует ячейке гиперкуба. В таблицах измерений приводятся значения каждого измерения.
Таблица факта является центральной таблицей в схеме "звезда". Размер таблицы может быть очень большим. Таблица факта соединяет данные, которые хранились бы во многих таблицах нормализованной реляционной базы данных.
Таблицы измерений содержат неизменяемые или редко изменяемые данные. Если измерение содержит иерархию, то таблица измерений может содержать поля, указывающие на "родителя" в этой иерархии. Таблицы измерений и таблица факта связаны идентифицирующими связями "один ко многим" (в нотации IDEF1X). Родительскими таблицами являются таблицы измерений. При этом первичные ключи таблиц измерений мигрируют в первичный ключ таблицы факта. Первичный ключ таблицы факта целиком состоит из первичных ключей всех таблиц измерений.
В сложных задачах с многоуровневой иерархией измерений используется схема "снежинка". В этих случаях производится нормализация таблиц измерений, что отражает иерархию измерений. Это схема позволяет добиться лучшей производительности, но часто приводит к избыточности данных и к значительным усложнениям в структуре базы данных, в которой оказывается огромное количество таблиц измерений.
Достоинства ROLAP:
1. Корпоративные хранилища данных реализуются средствами реляционных СУБД. При этом размер хранилища не является таким критичным параметром, как в случае MOLAP.
2. В случае переменной размерности задачи, когда изменения в структуру измерений приходится вносить достаточно часто, ROLAP системы являются оптимальным решением, так как в них такие модификации не требуют физической реорганизации БД.
3. Реляционные СУБД обеспечивают высокий уровень защиты данных и хорошие возможности разграничения прав доступа.
Главный недостаток ROLAP по сравнению с многомерными СУБД – меньшая производительность. Для обеспечения производительности, сравнимой с MOLAP, реляционные системы требуют тщательной проработки схемы базы данных и настройки индексов, то есть больших усилий со стороны администраторов БД.
Гибридная архитектура HOLAP объединяет технологии ROLAP и MOLAP. В отличие от MOLAP, которая работает лучше, когда данные плотные, серверы ROLAP лучше в тех случаях, когда данные довольно разрежены. Серверы HOLAP применяют подход ROLAP для хранения разреженных детализированных данных и подход MOLAP для хранения плотных агрегированных данных. Например, в крупном супермаркете детальные данные по покупкам по каждому чеку можно хранить в реляционной структуре, а обобщенные данные, например, по группам товаров, отделам, интервалам дат целесообразно хранить в многомерной структуре. Логически HOLAP является самым гибким подходом. Реализация HOLAP объединяет достоинства и недостатки MOLAP и ROLAP, но сложна в администрировании.
Существует ряд причин для выбора именно реляционной, а не многомерной базы данных. РБД — это хорошо отработанная технология, имеющая множество возможностей для оптимизации. Использование в реальных условиях дало в результате более проработанный продукт. К тому же, РБД поддерживают более крупные объемы данных. Они как раз и спроектированы для таких объемов.
2.2.2 Обоснованный выбор инструментария для реализации БД
Для выбора инструментария проектирования ИАС рассмотрим MySQL и phpMyAdmin.
MySQL — свободная реляционная система управления базами данных (СУБД). Под словом «свободная» подразумевается ее бесплатность, под «реляционная» – работа с базами данных, основанных на двумерных таблицах. Система выпущена в 1995 году, её разработка активно продолжается.
MySQL работает по принципу клиент-сервер. Компьютер пользователя (клиент) отправляет запрос. Сервер баз данных его обрабатывает и предоставляет ответ. Именно поэтому часто можно услышать понятие MySQL-сервер. Это сервер, на котором хранится база данных.
Система MySQL написана на языках программирования C и C++. Для работы MySQL используется язык структурированных запросов SQL.
SQL (Structured Query Language) — это язык программирования, при помощи которого можно управлять информацией: добавлять, модифицировать, удалять и получать данные. Запросы к базе данных формируются на языке SQL.
SQL используется не только в MySQL. Многие РСУБД (реляционные системы управления базами данных) используют этот язык для работы с данными. Например:
Microsoft SQL Server,
PostgreSQL,
Oracle Database,
MariaDB,
SQLite.
SQL используется в запросах при обращении к базе данных. Знание SQL позволит вам работать с любой реляционной базой данных, которая использует этот язык.
Этот рейтинг основан на следующих критериях:
упоминания в поисковых системах,
общий интерес,
вакансии с упоминанием MySQL,
профили в LinkedIn с упоминанием системы,
актуальность в социальных сетях.
MySQL поддерживается практически любой CMS. Эта СУБД работает как на Linux, MacOS и Windows, так и на других менее известных операционных системах. Поэтому MySQL очень популярна среди разработчиков сайтов и веб-приложений. Её используют в своей работе такие крупные компании, как Tesla, Netflix, Cisco, PayPal и другие.
Ни у специалистов с опытом ни у новичков не возникает проблем с поиском ответов на вопросы при работе с MySQL. В сети много обучающей информации и обсуждений на форумах, в том числе на русском языке.
К основным достоинствам MySQL также можно отнести следующие:
полностью бесплатная СУБД,
неограниченный многопользовательский режим,
множество плагинов, облегчающих работу с данной СУБД,
поддерживает различные типы таблиц (MyISAM, InnoDB, HEAP, MERGE),
позволяет добавлять до 50 миллионов строк в таблицы.
Однако есть и недостатки:
ограниченный функционал (не реализованы все возможности SQL);
возможны проблемы с надёжностью хранения и передачи данных из-за открытого исходного кода.
Таким образом, MySQL — это бесплатная простая СУБД с открытым исходным кодом. Конечно, она не лишена минусов, но в большинстве случаев именно MySQL будет оптимальным решением при работе с данными.
2.2.3 Модель структуры базы данных
Разновидность схемы типа звезды, предусматривающая нормализацию таблиц измерений. Первичные ключи в них состоят из единственного атрибута (соответствуют единственному элементу измерения). Это позволяет минимизировать избыточность данных и более эффективно выполнять запросы, связанные со структурой значений измерений.
Модель структуры базы данных представлена в приложении Е и Ж.
2.3 Применение CASE-средства Visio в проектировании выбранной предметной области
CASE-технологии (Computer-Aided Software/System Engineering) — инструментальные средства, используемые при проектировании систем. CASE-технологии охватывают весь спектр работ по созданию и сопровождению программного обеспечения (главным образом, анализ и разработку, составление проектной документации, кодирование и тестирование системы).
Как известно из практики, ошибки проектирования ПО, замеченные только на этапах кодирования или эксплуатации очень дорого стоят как Исполнителю, так и Заказчику информационной системы. Именно поэтому во всех современных стандартах на производство программного обеспечения столь значимая роль отводится именно этапу планирования.
CASE-технологии предназначены для детального планирования, структурирования и представления описания проектируемой системы в строгом и наглядном виде.
CASE-технологии имеют ряд характерных особенностей:
- обладают графическими средствами для проектирования и документирования модели информационной системы
- имеют организованное специальным образом хранилище данных, содержащее информацию о версиях проекта и его отдельных компонентах
- расширяют возможности для разработки систем за счет интеграции нескольких компонент CASE-технологий
Современные CASE-средства поддерживают также множество технологий моделирования информационных систем, начиная от простых методов анализа и регламентации и заканчивая инструментами полной автоматизации процессов всего жизненного цикла программного обеспечения.
CASE-технологии можно классифицировать по функциональной направленности на
· средства моделирования предметной области
· средства анализа и проектирования
· технологии проектирования схем баз данных
· средства разработки приложений
· технологии реинжиниринга программного кода и схем баз данных
В настоящий момент на рынке программного обеспечения насчитывается более 300 различных CASE-средств.
Microsoft Visio — программа для создания всевозможных видов схем. К их числу относятся блок-схемы, органиграммы, планы зданий и этажей, диаграммы DFD, схемы технологических процессов, модели бизнес-процессов, диаграммы плавательных дорожек, трехмерные карты и так далее., рассмотрим следующие для проекта нотации моделирования:
· С точки зрения функциональности системы. В рамках методологии IDEF0 (Integration Definition for Function Modeling) бизнес-процесс представляется в виде набора элементов-работ, которые взаимодействуют между собой, а также показывается информационные, людские и производственные ресурсы, потребляемые каждой работой.
· С точки зрения потоков информации (документооборота) в системе. Диаграммы DFD (Data Flow Diagramming) могут дополнить то, что уже отражено в модели IDEF3, поскольку они описывают потоки данных, позволяя проследить, каким образом происходит обмен информацией между бизнес-функциями внутри системы.
· С точки зрения последовательности выполняемых работ. И еще более точную картину можно получить, дополнив модель диаграммами IDEF3. Этот метод привлекает внимание к очередности выполнения событий. В IDEF3 включены элементы логики, что позволяет моделировать и анализировать альтернативные сценарии развития бизнес-процесса.
Как видно, CASE-средства позволяют упорядочить процесс производства ПО, помогают при проектировании и формализации требований к проектируемому программному продукту, помогают следить за развитием проекта, помогают в повторном использовании более удачных практик разработки и внедрении ПО, при применении CASE-средств процесс создания программного обеспечения становится более стабильным и управляемым.
2.3.1 Диаграмма IDEF0
Двумя наиболее важными компонентами, из которых строятся диаграммы IDEF0, являются бизнес-функции или работы (представленные на диаграммах в виде прямоугольников) и данные и объекты (изображаемые в виде стрелок), связывающие между собой работы. При этом стрелки, в зависимости от того в какую грань прямоугольника работы они входят или из какой грани выходят, делятся на пять видов:
· Стрелки входа (входят в левую грань работы) – изображают данные или объекты, изменяемые в ходе выполнения работы.
· Стрелки управления (входят в верхнюю грань работы) – изображают правила и ограничения, согласно которым выполняется работа.
· Стрелки выхода (выходят из правой грани работы) – изображают данные или объекты, появляющиеся в результате выполнения работы.
· Стрелки механизма (входят в нижнюю грань работы) – изображают ресурсы, необходимые для выполнения работы, но не изменяющиеся в процессе работы (например, оборудование, людские ресурсы)
· Стрелки вызова (выходят из нижней грани работы) – изображают связи между разными диаграммами или моделями, указывая на некоторую диаграмму, где данная работа рассмотрена более подробно.
Первая диаграмма в иерархии диаграмм IDEF0 всегда изображает функционирование системы в целом. Такие диаграммы называются контекстными. В контекст входит описание цели моделирования, области (описания того, что будет рассматриваться как компонент системы, а что как внешнее воздействие) и точки зрения (позиции, с которой будет строиться модель). Обычно в качестве точки зрения выбирается точка зрения лица или объекта, ответственного за работу моделируемой системы в целом.
После того как контекст описан, проводится построение следующих диаграмм в иерархии. Каждая последующая диаграмма является более подробным описанием (декомпозицией) одной из работ на вышестоящей диаграмме. Пример декомпозиции контекстной работы показан далее.
Для фирмы-провайдера входящей информацией будет являться заявка клиента на подключение.
Управляющая информация содержит в себе, прежде всего, федеральное законодательство (Постановление Правительства РФ «Об утверждении правил оказания услуг связи по передачи данных»), как основной элемент управления, без которого невозможна никакая деятельность. Деятельность юридического лица невозможна без лицензии, а значит, этот элемент обязательно надо учесть. К второстепенным членам управления относится устав фирмы, регулирующий внутренний распорядок.
К механизму управления относятся: персонал; технические средства.
Чек и договор являются исходящим потоком данных.
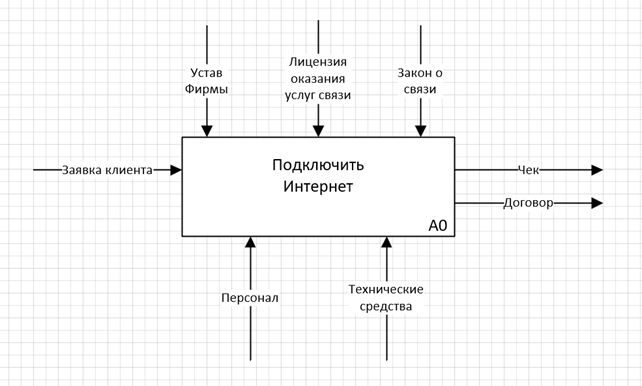
Рисунок 2 – Контекстная диаграмма «Подключить интернет» в IDEF0
Разберем подробнее процессы, происходящие в фирме. На данном уровне декомпозиции (Рисунок 3) содержится 4 бизнес процесса, необходимых для достижения конечного результата, т.е. предоставления услуг как выходной информации.
Бизнес-процессы:
· Обработать заявку клиента
- Входная информация: заявка клиента.
- Выходная информация: информационные данные, заказ.
- Управление: закон о связи, устав фирмы.
- Механизм управления: персонал.
· Провести монтажные работы
- Входная информация: заказ.
- Выходная информация: сроки проведения технических работ, информация об оплате.
- Управление: лицензия, устав фирмы.
- Механизм управления: персонал, технические средства.
· Выполнить техническое обслуживание
- Входная информация: информация об оплате.
- Выходная информация: время ликвидации неисправностей, предоставление услуг.
- Управление: закон о связи, устав фирмы.
- Механизм управления: персонал, технические средства.
· Внести в базу данных
- Входная информация: сроки проведения технических работ, информационные данные.
- Выходная информация: Договор, чек.
- Управление: устав фирмы.
- Механизм управления: персонал.
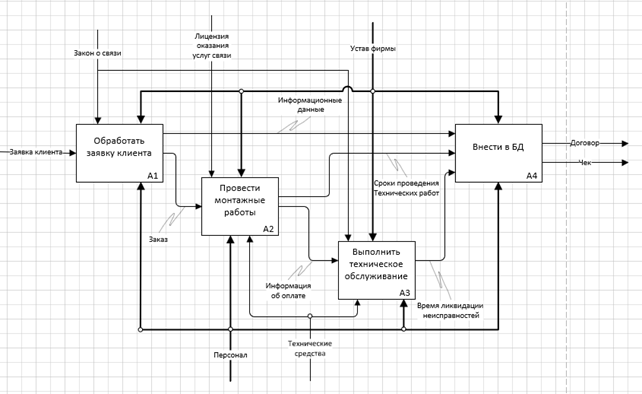
Рисунок 3 – Декомпозиция контекстной диаграммы «Подключить интернет» в IDEF
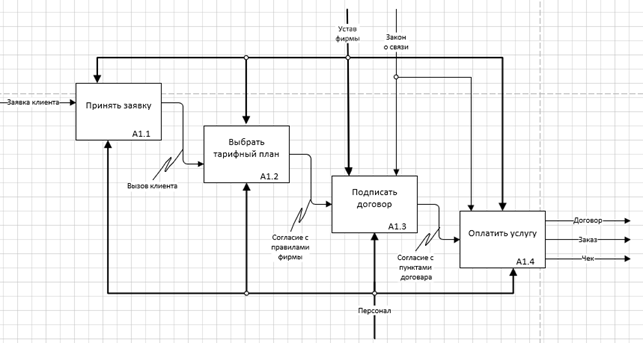
Рисунок 4 – Декомпозиция процесса «Обработать заявку клиента» в IDEF0
Декомпозиция процесса «Обработать заявку клиента» ( Рисунок 4 ).
Бизнес-процессы:
· Принять заявки
- Входная информация: заявка клиента.
- Выходная информация: вызов клиента.
- Управление: учесть устав фирмы.
- Механизм управления: персонал.
· Выбрать тарифный план
- Входная информация: вызов клиента.
- Выходная информация: согласие с правилами фирмы.
- Управление: учесть устав фирмы.
- Механизм управления: персонал.
· Подписать договор
- Входная информация: согласие с правилами фирмы.
- Выходная информация: согласие с пунктами договора, договор.
- Управление: Закон о связи, устав фирмы.
- Механизм управления: персонал.
· Оплатить услугу
- Входная информация: согласие с пунктами договора.
- Выходная информация: заказ, чек, договор.
- Управление: Закон о связи, устав фирмы.
- Механизм управления: персонал.
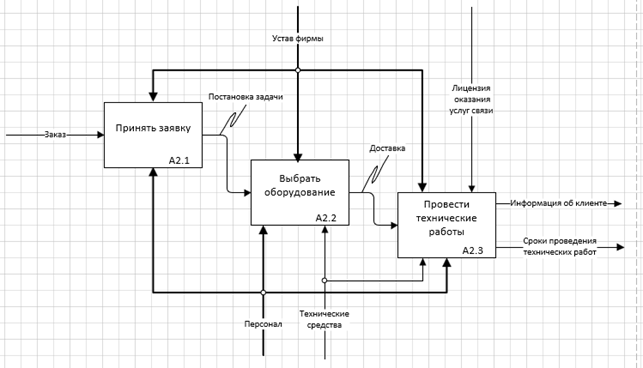
Рисунок 5 – Декомпозиция процесса «Провести монтажные работы» в IDEF0
Декомпозиция процесса «Провести монтажные работы» ( Рисунок 5 ).
Бизнес-процессы:
· Принять заявку
- Входная информация: заказ.
- Выходная информация: постановка задачи, технические средства.
- Управление: устав фирмы.
- Механизм управления: персонал.
· Выбрать оборудование
- Входная информация: постановка задачи.
- Выходная информация: информация о доставке.
- Управление: устав фирмы.
- Механизм управления: персонал, технические средства.
· Произвести технические работы
- Входная информация: информация о доставке.
- Выходная информация: сроки проведения технических работ, информация об оплате.
- Управление: устав фирмы.
- Механизм управления: персонал, технические средства.
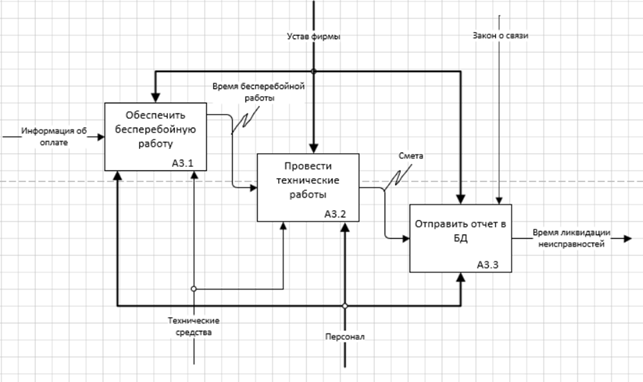
Рисунок 6 – Декомпозиция процесса «Выполнить техническое
обслуживание» в IDEF0