
КОИ-8 (код обмена информацией, 8 битов) — восьмибитовая ASCII-совместимая кодовая страница, разработанная для кодирования букв кириллических алфавитов.








Существует также семибитовая версия кодировки, не полностью совместимая с ASCII — КОИ-7.
Разработчики КОИ-8 поместили символы русского алфавита в верхней части кодовой таблицы таким образом, что позиции кириллических символов соответствуют их фонетическим аналогам в английском алфавите в нижней части таблицы.
Это означает, что если в тексте, написанном в КОИ-8, убирать восьмой бит каждого символа, то получается «читаемый» текст, хотя он и написан латинскими символами.
Например, слова «Русский Текст» превратились бы в «rUSSKIJ tEKST». Как побочное следствие, символы кириллицы оказались расположены не в алфавитном порядке.
Как в основной таблице, так и в ее расширении коды букв и цифр соответствуют их лексикографическому порядку (т.е. порядку следования в алфавите) – это обеспечивает возможность ускорения автоматизации обработки текстов.
В настоящее время появился и находит все более широкое применение еще один международный стандарт кодировки – Unicode.
Его особенность в том, что в нем использовано 16-битное кодирование, т.е. для представления каждого символа отводится 2 байта.
Такая длина кода обеспечивает включения в первичный алфавит 65536 знаков. Это, в свою очередь, позволяет создать и использовать единую для всех распространенных алфавитов кодовую таблицу.
7. Кодирование с неравной длительностью элементарных сигналов.
7.1. Код Морзе
Примером использования данного варианта кодирования является телеграфный код Морзе ("азбука Морзе").
В нем каждой букве или цифре сопоставляется некоторая последовательность кратковременных импульсов – точек и тире, разделяемых паузами.
Длительности импульсов и пауз различны:
Если продолжительность импульса, соответствующего точке, обозначить  , то
, то
· длительность импульса тире составляет 3 ,
· длительность паузы между точкой и тире ,
· пауза между буквами слова 3 ,
· пауза между словами (пробел) – 6 .
Таким образом, под знаками кода Морзе следует понимать:
"  " – "короткий импульс + короткая пауза",
" – "короткий импульс + короткая пауза",
"  " – "длинный импульс + короткая пауза",
" – "длинный импульс + короткая пауза",
"0" – "длинная пауза", т.е. код оказывается троичным.
Свой код Морзе разработал в 1838 г., т.е. задолго до исследований относительной частоты появления различных букв в текстах.
Однако им был правильно выбран принцип кодирования – буквы, которые встречаются чаще, должны иметь более короткие коды, чтобы сократить общее время передачи.
Относительные частоты букв английского алфавита он оценил простым подсчетом литер в ячейках типографской наборной машины.
Поэтому самая распространенная английская буква "E" получила код "точка".
При составлении кодов Морзе для букв русского алфавита учет относительной частоты букв не производился, что, естественно, повысило его избыточность. (для русского языка -около 18% ;для английского языка  15%).
15%).
Код Морзе имел в недалеком прошлом широкое распространение в ситуациях, когда источником и приемником сигналов являлся человек (не техническое устройство) и на первый план выдвигалась не экономичность кода, а удобство его восприятия человеком.
7.2. Блочное двоичное кодирование
При алфавитном кодировании передаваемое сообщение представляет собой последовательность кодов отдельных знаков первичного алфавита.
Однако возможны варианты кодирования, при которых кодовый знак относится сразу к нескольким буквам первичного алфавита (будем называть такую комбинацию блоком) или даже к целому слову первичного языка.
Кодирование блоков понижает избыточность. В этом легко убедиться на простом примере.
Пусть имеется словарь некоторого языка, содержащий n = 16000 слов (это, безусловно, более чем солидный словарный запас!).
Поставим в соответствие каждому слову равномерный двоичный код. Очевидно, длина кода может быть найдена из соотношения K(2) 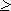 log2n 13,97 = 14.
log2n 13,97 = 14.
Следовательно, каждому слову будет поставлена в соответствие комбинация из 14 нулей и единиц – получатся своего рода двоичные иероглифы.
Например, пусть слову "ИНФОРМАТИКА" соответствует код 10101011100110, слову "НАУКА" – 00000000000001, а слову "ИНТЕРЕСНАЯ" – 00100000000010; тогда последовательность:
000000000000110101011100110000000000000001,
очевидно, будет означать "ИНФОРМАТИКА ИНТЕРЕСНАЯ НАУКА".
Легко оценить, что при средней длине русского слова K(r) = 6,3 буквы (5,3 буквы + пробел между словами) средняя информация на знак первичного алфавита оказывается равной I (2) = K (2) / K (r) = 14/6,3 = 2,222 бит, что почти в 2 раза меньше, чем 4,395 бит при алфавитном кодировании.
Для английского языка такой метод кодирования дает 2,545 бит на знак. Таким образом, кодирование слов оказывается более выгодным, чем алфавитное.
Еще более эффективным окажется кодирование в том случае, если сначала установить относительную частоту появления различных слов в текстах и затем использовать код Хаффмана.
Подобные исследования провел в свое время Шеннон: по относительным частотам 8727 наиболее употребительных в английском языке слов он установил, что средняя информация на знак первичного алфавита оказывается равной 2,15 бит.
Вместо слов можно кодировать сочетания букв – блоки.
В принципе блоки можно считать словами равной длины, не имеющими, однако, смыслового содержания.
Удлиняя блоки и применяя код Хаффмана теоретически можно добиться того, что средняя информация на знак кода будет сколь угодно приближаться к 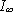 .
.
Однако, несмотря на кажущиеся преимущества, применение блочного и словесного метода кодирования имеет свои недостатки.
Во-первых, необходимо хранить огромную кодовую таблицу и постоянно к ней обращаться при кодировании и декодировании, что замедлит работу и потребует значительных ресурсов памяти.
Во-вторых, помимо основных слов разговорный язык содержит много производных от них, например, падежи существительных в русском языке или глагольные формы в английском; в данном способе кодирования им всем нужно присвоить свои коды, что приведет к увеличению кодовой таблицы еще в несколько раз.
В-третьих, возникает проблема согласования (стандартизации) этих громадных таблиц, что непросто.
Наконец, в-четвертых, алфавитное кодирование имеет то преимущество, что буквами можно закодировать любое слово, а при кодировании слов – можно использовать только имеющийся словарный запас.
По указанным причинам блочное и словесное кодирование представляет лишь теоретический интерес, на практике же применяется кодирование алфавитное.