
Вопрос 12. Локальная и интегральная теоремы Лапласа.








Когда n велико, а р мало, то вычисления по формуле Бернулли крайне затруднительны. Поэтому для вычисления вер-тей применяются приближенные формулы, кот. называются ассимптотическим. одной из таких формул явл. формулы Лапласа.
Пусть в каждом из n независимых испытаний событие A может произойти с вероятностью p,q=1-p (условия схемы Бернулли). Обозначим через Pn(k) вероятность ровно k появлений события А в испытаниях. кроме того, пусть 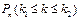 – вероятность того, что число появлений события А находится между k1 и k2 .
– вероятность того, что число появлений события А находится между k1 и k2 .
Локальная теорема Лапласа.
Если n – велико, а р – отлично от 0 и 1, то вер-ть Pn(k) того, что событие А появится в n испытаниях ровно k раз, приближенно равна значению ф-ии:
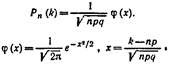
Значения ф-ии фи(х) для положительных х приведены в специальных таблицах. Для отрицательных значений аргумента исп. те же таблицы, т.к. ф-ия фи(х) четная. (фи от –х= фи от х)
Интегральная теорема:
Для того, чтобы посчитать вер-ть наступления не более чем m успехов, когда n велико, прим интегральную теорему Лапласа: 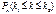 =
= 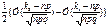
Замечание:ф-ия для Ф=2/2корня из пи...(в таблице). При Ф=1/2корня из пи.. 1 /2 перед формулой убирается.
Осн. св-ва ф-ии Лапласа:
1.Ф(0)=0
2.Ф( 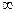 )=0,5
)=0,5
3.Ф(-t)=-Ф(t)
Для ф-ии Лапласа также есть таблицы ее значений. В таблице даются значения для 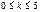 . Для отр. знач. t исп св-во нечетности ф-ии, т.е. Ф(-t)=-Ф(t)
. Для отр. знач. t исп св-во нечетности ф-ии, т.е. Ф(-t)=-Ф(t)
Если t 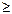 5, то Ф(t)=0,5 , для любого t 5.
5, то Ф(t)=0,5 , для любого t 5.
Теоремы Лапласа дают удовлетворительное приближение при np>=10. Чем ближе значения p к 0,5, тем точнее данные формулы. При маленьких или больших значениях вероятности (близких к 0 или 1) формула дает большую погрешность (по сравнению с исходной формулой Бернулли).
13.Формула Пуассона для редких событий.
Когда n велико, а р мало, то вычисления по формуле Бернулли крайне затруднительны. Поэтому для вычисления вер-тей применяются приближенные формулы, кот. называются ассимптотическим. одной из таких формул явл. ф. Пуассона для редких событий: 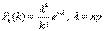
Эта формула дает удовлетворительное приближение для p<=0,1и np<=10 . При больших np рекомендуется применять формулы Лапласа.
14. Дискретная случайная величина, ее закон распределения. Многоугольник распределения.
Часто р-том случ. эксперимента явл. число.Естественно рассм. случайную величину как ф-ию, заданную на множестве исходов случ. эксперимента.
СВ условно разделяют на дискретные и непрерывные.
СВ называется дискретной, если множество ее возможных значений конечно или счетно. Например, число бросаний монеты до появления герба или число выпавших очков при бросании игрального кубика.
ДСВ полностью характеризуется заданием закона распределения, кот. опис. с помощью матрицы, сост. из двух строк:
строка возм. знач. СВ и строка вер-тей, с кот. эти значения могут появляться. [Пример с кубиком] Т.к. в верхней строке перечислены все возм. знач. СВ, то эти значения образ. полную г-пу событий. Следовательно сумма вер-тей равна 1.
Ряд распределения дискретной случайной величины можно изобразить
графически в виде полигона или многоугольника распределения вероятностей.
Для этого по горизонтальной оси в выбранном масштабе нужно отложить зна-
чения случайной величины, а по вертикальной — вероятности этих значений,
тогда точки с координатами (xi , pi) будут изображать полигон распределения
вероятностей; соединив же эти точки отрезками прямой, получим многоуголь -
ник распределения вероятностей .
15. Функция распределения вероятностей случайной величины и ее свойства.
Ф-ия распр. – это вер-ть того, что СВ принимает значения, меньше, чем х. Функцией распределения (ФР) (или интегральная ф-ия распределения) СВ X называется числовая функция F(x) = P{X < x}, определенная для любых x Î R.
Св-ва ФР:
1. 0 £ F(x) £ 1, т.к. по опр. это вер-ть;
2. F(x1) £ F(x2), если x1 < x2, т.е. F(x) - неубывающая функция;
3. 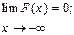
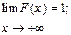
4. P{a £ X < b} = F(a) - F(b).
16. Математическое ожидание дискретной случайной величины и его свойства.
Одной из важнейших хар-к СВ явл. мат.ожидание, кот по своему смыслу характ. ср. знач. СВ.
Для ДСВ МХ находится по формуле:
mX = M[X] = M(X) = x1 p1+ x2 p2+...+ xn pn= 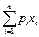
Свойства математического ожидания:
1. M[C] = C, где С - константа;
2. M[C×X] = C×M[X];
3. M[X+-Y] = M[X]+-M[Y], для любых СВ X и Y;
4. M[X×Y] = M[X]×M[Y]
5. М[X-M(X)]=0 – мат. ожидание отклонения СВ от ее мат. ожидания равно 0.
17. Дисперсия ДСВ и ее св-ва. Среднее квадр. отклонение.
Вадной хар-кой СВ явл. хар-ка разброса значений СВ около мат.ожидания. Эта хар-ка называется дисперсией DX.
По определению дисперсия – это мат. ожидание квадрата отклонения СВ от ее MX: 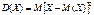
Если Х — ДСВ, то дисперсию вычисляют по следующим формулам:
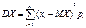
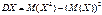
Св-ва дисперсии:
1. 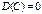
2. 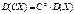
3. 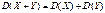
4. 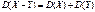
Среднее квадратическое отклонение дискретной случайной величины есть арифметическое значение корня квадратного из ее дисперсии:
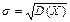 Среднее квадратическое отклонение характеризует степень отклонения случайной величины от ее математического ожидания и имеет размерность
Среднее квадратическое отклонение характеризует степень отклонения случайной величины от ее математического ожидания и имеет размерность
значений случайной величины
18. Биномиальный закон распределения и его числовые характеристики. Пусть проводится n независимых испытаний. В результате каждого из которых возможны 2 исхода: А – успех с вероятностью p, или 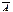 - неуспех с вероятностью q = 1-p. Дискретная СВ X , ,характ. число появления события А принимает значения Х=m c вер-тями
- неуспех с вероятностью q = 1-p. Дискретная СВ X , ,характ. число появления события А принимает значения Х=m c вер-тями
P(X=m)= 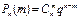 , где p>0, q>0, m
, где p>0, q>0, m 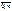 0,n. Для бин. з.р. доказано, что мат.ожидание M(X)= np , дисперсия
0,n. Для бин. з.р. доказано, что мат.ожидание M(X)= np , дисперсия 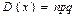 среднее квадратическое отклонение -
среднее квадратическое отклонение - 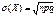
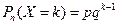 Т.о геометр.распр. есть испытание по схеме Бернулли до первого положительного исхода.Вероятности образуют бесконечно убывающую геометрическую прогрессию со знаменателем q=1-p (с этим связано название). Для геометр. закона распр. доказано, что мат. ожидание равно M(x)=1/p , дисперсия равна D(x)=
Т.о геометр.распр. есть испытание по схеме Бернулли до первого положительного исхода.Вероятности образуют бесконечно убывающую геометрическую прогрессию со знаменателем q=1-p (с этим связано название). Для геометр. закона распр. доказано, что мат. ожидание равно M(x)=1/p , дисперсия равна D(x)= 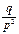 20. Гипергеометрическое распределение. Пусть имеется N элементов, из кот-х М эл-тов облад. некот-м признаком А. Извлек. случ. образом без возвращ-я n эл-тов. X – ДСВ, число эл-тов, облад. признаком А, среди отобр. n эл-тов. Вер-ть того, что Х =k опред. по формуле: P(x=k)=
20. Гипергеометрическое распределение. Пусть имеется N элементов, из кот-х М эл-тов облад. некот-м признаком А. Извлек. случ. образом без возвращ-я n эл-тов. X – ДСВ, число эл-тов, облад. признаком А, среди отобр. n эл-тов. Вер-ть того, что Х =k опред. по формуле: P(x=k)= 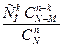 Для гипергеометр. распр. доказано, что M(x)=
Для гипергеометр. распр. доказано, что M(x)= 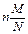 D(x)=
D(x)= 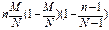

21. Формула Пуассона. Распределение Пуассона. Фактически, закон Пуассона – это биномиальное распр при большом числе испытаний n и малой вер-ти наступления события в каждом из испытаний, поэтому з-н Пуассона часто называют з-н редких явлений. ДСВ Х распр. по закону Пуассона, если она прин. знач. 0,1,2,..m,... с вер-тями 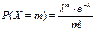 ,где λ=np (среднее число появл-я события в n испытаниях), m – число появления события в n независимых испытаниях; m приним. значения 0,1,2,…,n. Мат. ожидание и дисперсия СВ, распределенной по закону Пуассона, совпадают и равны параметру λ : M(X)=λ, D(X)=λ.
,где λ=np (среднее число появл-я события в n испытаниях), m – число появления события в n независимых испытаниях; m приним. значения 0,1,2,…,n. Мат. ожидание и дисперсия СВ, распределенной по закону Пуассона, совпадают и равны параметру λ : M(X)=λ, D(X)=λ.
22. Непрерывная случайная величина, плотность распределения вероятностей непрерывной случайной величины и ее свойства. Случ. вел-на Х наз. непрерывной, если ее функция распред-я непрерывна в любой точке и дифференцируема всюду, кроме отдельных точек. Пример: рост человека. Теорема: Вероятность любого отдельного знач-я непрер. случ. вел-ны равна нулю: P(X=x1)=0. Для НСВ P(x1< X < x2)=F(x2)-F(x1). НСВ как и ДСВ задается функцией распр. Однако,такой способ задания неперыв.СВ не единств. Для НСВ ввод. понятие плотности вер-ти. Р(Х) 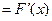 ). Свойства: 1.p(x)≥0 для люб, т.к. F(x) явл. неубывающей ф-ей.
). Свойства: 1.p(x)≥0 для люб, т.к. F(x) явл. неубывающей ф-ей.