
Достоинства и недостатки файловой организации








1. Недостатки файловых систем по сравнению с системами баз данных.
Файловые системы – набор программ, предназначенных для решения той или иной задачи (расчет зарплаты и совокупность файлов, содержащих необходимые данные). Со временем стали очевидны следующие недостатки файловых систем:
1) зависимость программ от данных т.к. программы на алгоритмическом языке содержат описание данных, то при изменении их структуры приходилось изменять исходные тексты программ.
2) файлы разных систем могли пересекаться, т.е. содержать одни и те же данные, например, система расчета зарплаты. Это приводило к неэкономному использованию дисковой памяти или к нарушению целостности данных.
3) невозможность совместной обработки, т.к. разные системы были написаны на разных языках программирования, то и файлы этих систем хранились в разных форматах ⇒пользователь одной системы не имел доступа к файлам другой системы.
4) быстрый рост приложений, поскольку в то время отсутствовали средства генерации отчетов произвольной формы, то для формирования каждого отчета приходилось создавать соответствующее приложение.
Перечисленные недостатки являются следствием 2х причин:
1)отсутствие др. средств доступа к данным кроме приложений;
2)необходимости описания данных в приложении.
Попытки исправить эти недостатки и устранить эти причины привели к появлению концепции баз данных (БД).
Достоинства и недостатки файловой организации
Достоинства:
Файловые системы обычно обеспечивают хранение слабо структурированной информации, оставляя дальнейшую структуризацию обрабатывающим программам. В некоторых случаях использования файлов это даже хорошо, потому что при разработке любой новой прикладной системы, опираясь на простые, стандартные и сравнительно дешевые средства файловой системы, можно реализовать те структуры хранения, которые наиболее естественно соответствуют специфике соответствующей прикладной области.
· Файловая организация позволяет достигнуть высокой скорости обработки.
Недостатки:
· Узкая специализация как обрабатывающих программ, так и файловых данных, что служит причиной большой избыточности, так как одни и те же элементы данных хранятся в разных программных системах.
· Возможность наличия противоречивости данных, когда для выполнения одних
и тех же операций над однотипными данными, хранящихся в разных файлах, требуются разные программы.
· Частое нарушение целостности данных, когда логически идентичные элементы данных в разных частных файлах имеют разные типы значений (например, Real и Integer), что может привести к расхождению в отчетах, полученных с помощью ЭВМ.
Программа
=
логическая структура данных
+
методы доступа
+
Физические данные
Рис.1. Структура программы при файловой организации данных
Бд
| Достоинства | Недостатки |
| · Эта модель данных отображает информацию в наиболее простой для пользователя форме · Основана на развитом математи-ческом аппарате, который позволяет достаточно лаконично описать основные операции над данными. · Позволяет создавать языки манипулирования данными не процедурного типа. · Манипулирование данными на уровне выходной БД и возможность изменения. | · Самый медленный доступ к данным. · Трудоемкость разработки |
2. Понятие системы и информационной системы. Классификация информационных систем.
Информационные системы главным образом ориентированы на хранение, выбор и модификацию постоянно хранимой информации, как правило, очень сложной структуры.
На начальном этапе использования вычислительной техники проблемы структуризации данных решались индивидуально в каждой информационной системе путем создания необходимых надстроек (библиотек программ) над файловыми системами, учитывающими специфику структур файлов для конкретной предметной области, причем эти индивидуальные средства управления данными составляли существенную часть информационных систем
Однако, несмотря на то, что структуры данных различны в разных информационных системах, между ними часто бывает много общего. Разумным представлялось выделить общую часть информационных систем, ответственную за управление сложно структурированными данными, в виде некоторой библиотеки программ, доступной каждой информационной системе.
Но очень скоро стало понятно, что обойтись такой общей библиотекой программ, реализующей над стандартной базовой файловой системой более сложные методы хранения данными, невозможно.
Информационная система - взаимосвязанная совокупность средств, методов и персонала, используемых для хранения, обработки и выдачи информации в интересах достижения поставленной цели.
Классификация информационных систем управления способствует выявлению наиболее характерных черт, присущих информационным системам. Классификация проводится по определенным признакам.
1. Классификация ИС по признаку структурированности задач:
· структурированные (формализуемые) задачи, где известны все ее элементы и взаимосвязи между ними, удается выразить ее содержание в форме математической модели, имеющей точный алгоритм решения.
· неструктурированные (неформализуемые) задачи– задачи, в которых невозможно выделить элементы и установить между ними связи. Решение таких задач из-за невозможности создания математического описания и разработки алгоритма связано с большими трудностями.
· частично структурированные задачи - известна часть элементов и связей между ними.
Информационные системы, используемые для решения частично структурированных задач, подразделяются на два вида:
· информационные системы, создающие управленческие отчеты и ориентированные главным образом на обработку данных (поиск, сортировку, агрегирование, фильтрацию), обеспечивают информационную поддержку пользователя, т. е. предоставляют доступ к информации в базе данных и ее частичную обработку.
· информационные системы, разрабатывающие альтернативы решений (модельные или экспертные) - предоставляют пользователю математические, статистические, финансовые и другие модели, использование которых облегчает выработку и оценку альтернатив решения.
2. По характеру представления и логической организации хранимой информации:
· фактографические информационные системы - накапливают и хранят данные в виде множества экземпляров одного или нескольких типов структурных элементов (информационных объектов), которые отражают сведения по какому-либо факту, событию и пр., отделенному от других сведений.
· документальные информационные системы - единичным элементом информации является документ и информация на вводе (входной документ). При создании информационной базы процесс структуризации не производится или производится в ограниченном виде
· геоинформационные информационные системы- данные организованы в виде отдельных информационных объектов, привязанных к общей электронной топографической основе (электронной карте).
3. По выполняемым функциям и решаемым задачам:
· справочные информационные системы, которые предоставляют пользователям получать определенные классы объектов (телефоны, адреса, литературу и пр.) – электронные справочники, картотеки, программные или аппаратные электронные записные книжки и т. д.;
· информационно-поисковые информационные системы, которые дают пользователям возможность поиска и получения сведений по различным поисковым образам на неком информационном пространстве;
· расчетные информационные системы, которые производят обработку информации по определенным расчетным алгоритмам, например вычисление определенных статистических характеристик;
· технологические информационные системы, функции таких систем заключаются в автоматизации всего технологического цикла или отдельных его компонент производственной или организационной структуры, например, автоматизированные системы управления, системы автоматизации документооборота и пр.
4. По масштабу и интеграции компонент:
· локальный АРМ (автоматизированное рабочее место) – программно-технический комплекс, предназначен для реализации управленческих функций на отдельном рабочем месте; информационно и функционально не связан с другими информационными системами;
· комплекс информационно и функционально связанных АРМ, реализующих в полном объеме функции управления;
· компьютерная сеть АРМ на единой информационной базе, обеспечивающая интеграцию функций управления в масштабе предприятия или группы бизнес-единиц;
· корпоративная информационная система (КИС), обеспечивающая полнофункциональное распределенное управление крупномасштабным предприятием.
5. По характеру обработки информации на различных уровнях управления предприятием:
· системы обработки данных (EDP – Electronic data processing) - предназначены для учета и оперативного регулирования хозяйственных операций, подготовки стандартных документов для внешней среды (отчетов, накладных, платежных поручений).
· информационные системы управления (MIS – Management Information System) - ориентированы на тактический уровень управления: среднесрочное планирование, анализ и организацию работ в течение нескольких месяцев (недель), например, анализ и планирование поставок, сбыта, составление производственных программ.
· системы поддержки принятия решений (DSS – Decision Support System) -используются на верхнем уровне управления и предназначены для решения задач по формированию стратегических целей, задач планирования, задач привлечения ресурсов и источников финансирования и пр. Задачи ориентированы на реализацию сложных бизнес-процессов, требующих аналитической обработки информации и имеют, как правило, нерегулярный характер.
6. По уровням управления:
· информационные системы оперативного (операционного) уровня - (бухгалтерские, банковские, обработки заказов и пр.) поддерживают специалистов, обрабатывая данные о сделках и событиях (счета, накладные, зарплата, кредиты, поток сырья и материалов).
· информационные системы специалистов -специалистов помогают пользователям повысить продуктивность и производительность. Их задача – интеграция новых сведений и помощь в обработке бумажных документов.
· информационные системы для менеджеров среднего звена - используются для мониторинга, контроля, принятия решений и администрирования.
· стратегические информационные системы - обеспечивают поддержку принятия решений по реализации стратегических перспективных целей развития организации и помогают высшему звену управленцев осуществлять долгосрочное планирование.
7. Классификация ИС по функциональному признаку:
· производственные системы, связанные с выпуском продукции и направленные на создание и внедрение в производство научно-технических новшеств;
· системы маркетинга, направленные на анализ рынка производителей и потребителей выпускаемой продукции, анализ продаж, организацию рекламной кампании по продвижению продукции и рациональную организацию материально-технического снабжения;
· финансовые и учетные системы, направленные на организацию контроля и анализа финансовых ресурсов на основе бухгалтерской, статистической и оперативной информации;
· системы кадров по подбору и расстановке специалистов и ведению служебной документации по различным аспектам предназначены для реализации функций оперативного планирования и учета личного состава;
· системы управления вспомогательным производством предназначены для автоматизации оперативного управления инструментальным производством, ремонтным и транспортным хозяйством и энергетическим обеспечением.
12. Классификация по сфере применения
· Информационные системы организационного управления
· ИС управления технологическими процессами (ТП)
· ИС автоматизированного проектирования (САПР)
· Обучающие информационные системы
· Корпоративные ИС
· Интегрированные (корпоративные) ИС
13. По степени распределённости ИС отличают:
· настольные (desktop), или локальные ИС, в которых все компоненты (БД, СУБД, клиентские приложения) работают на одном компьютере;
· распределённые (distributed) ИС, в которых компоненты распределены по нескольким компьютерам:
-файл-серверные ИС (ИС с архитектурой «файл-сервер»),
-клиент-серверные ИС (ИС с архитектурой «клиент-сервер»).
3. Понятие системы баз данных и ее упрощенная схема.
Понятие система баз данных используется как в широком, так и в узком смысле.
В широком смысле система баз данных понимается фактически как синоним понятия информационная система и включает в себя данные, аппаратное обеспечение, программное обеспечение пользователей.
В узком смысле система баз данных понимается как СУБД с управляемой ею базой данных, возможно, уже наполненной.
Информационная система (сокр. ИС) — система обработки информации и соответствующие организационные ресурсы (человеческие, технические, финансовые и т. д.), которые обеспечивают и распространяют информацию (ISO/IEC 2382-1:1993).
Информационная система предназначена для своевременного обеспечения надлежащих людей надлежащей информацией, то есть для удовлетворения конкретных информационных потребностей в рамках определенной предметной области, при этом результатом функционирования информационных систем является информационная продукция — документы, информационные массивы, базы данных и информационные услуги.
База данных — совокупность данных, хранимых в соответствии со схемой данных, манипулирование которыми выполняют в соответствии с правилами средств моделирования данных.
База данных — совокупность данных, организованных в соответствии с концептуальной структурой, описывающей характеристики этих данных и взаимоотношения между ними, причём такое собрание данных, которое поддерживает одну или более областей применения.
Определения из авторитетных монографий:
База данных — организованная в соответствии с определёнными правилами и поддерживаемая в памяти компьютера совокупность данных, характеризующая актуальное состояние некоторойпредметной области и используемая для удовлетворения информационных потребностей пользователей.
База данных — некоторый набор перманентных (постоянно хранимых) данных, используемых прикладными программными системами какого-либо предприятия.
База данных — совместно используемый набор логически связанных данных (и описание этих данных), предназначенный для удовлетворения информационных потребностей организации.
Систе́ма управле́ния ба́зами да́нных (СУБД) — совокупность программных и лингвистических средств общего или специального назначения, обеспечивающих управление созданием и использованием баз данных.
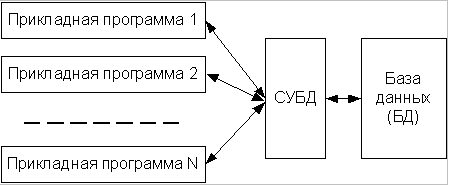
Упрощённая схема системы базы данных:
Система баз данных содержит 5 главных компонентов: данные, аппаратное обеспечение, программное обеспечение, юзеры, сама база данных.
4. Понятия интегрированности и разделяемости данных, независимости от данных и целостности данных применительно к системам баз данных.
В общем случае данные в базе данных (по крайней мере, в больших системах) являются интегрированными и разделяемыми. Как будет показано в разделе 1.4, эти два аспекта, интеграция и разделение данных, представляют собой наиболее важные преимущества использования систем баз данных на большом оборудовании и по меньшей мере один из них - интеграция - является преимуществом их использования на малом оборудовании. Конечно, есть множество других преимуществ (даже на малом оборудовании), но о них речь пойдет позже. Сначала следует объяснить, что понимается под терминами интегрированный и разделяемый.
Под понятием интегрированности данных подразумевается возможность представить базу данных как объединение нескольких отдельных файлов данных, полностью или частично исключающее избыточность хранения информации. Например, база данных может содержать файл EMPLOYEE, включающий имена сотрудников, адреса, отделы, зарплату и т.д., и файл ENROLLMENT, содержащий сведения о регистрации сотрудников на курсах обучения (рис. 1.4). Допустим, что для контроля процесса обучения необходимо знать отдел каждого зачисленного на курсы студента. Совершенно очевидно, что нет необходимости включать такую информацию в файл ENROLLMENT, поскольку ее всегда можно получить из файла EMPLOYEE.
EMPLOYEE NAME ADDRESS DEPARMENT SALARY ...
ENROLLMENT NAME COURSE
Рис. 1.4. Фаты EMPLOYEE и ENROLLMENT
Под понятием разделяемости данных подразумевается возможность использования отдельных элементов, хранимых в базе данных несколькими различными пользователями. Имеется в виду, что каждый из пользователей сможет получить доступ к одному и тому же элементу данных, возможно, для достижения различных целей. Как уже упоминалось, разные пользователи могут даже получать доступ к одному и тому же элементу данных в одно и то же время (параллельный доступ). В приведенном выше примере информация об отделе в файле EMPLOYEE может разделяться пользователями отдела кадров и отдела обучения. Причем, как подчеркивалось выше, эти две группы пользователей смогут применять такую информацию для разных целей, что обычно и происходит.
Замечание. Если база данных не является разделяемой, то ее иногда называют личной или базой данных специального назначения.
Одним из следствий упомянутых выше характеристик базы данных (интегрированности и разделяемости) является то, что каждый конкретный пользователь обычно имеет дело лишь с небольшой частью всей базы данных, причем обрабатываемые различными пользователями части могут произвольным образом перекрываться. Иначе говоря, каждая база данных воспринимается ее различными пользователями по-разному. Фактически даже те два пользователя базы данных, которые работают с одними и теми же элементами данных, могут иметь значительно отличающиеся представления о них.
5. Жизненный цикл базы данных. Этапы концептуального, логического и физического проектирования базы данных.
Жизненный цикл базы данных — это совокупность этапов, которые проходит база данных на своём пути от создания до окончания использования.



6. Понятия модели и модели данных. Логические модели данных.
Моде́ль (фр. modèle, от лат. modulus — «мера, аналог, образец») — это система, исследование которой служит средством для получения информации о другой системе, это упрощённое представление реального устройства и/или протекающих в нём процессов, явлений.
Первоначально понятие модели данных употреблялось как синоним структуры данных в конкретной базе данных.
Модель данных — это абстрактное, самодостаточное, логическое определение объектов, операторов и прочих элементов, в совокупности составляющих абстрактную машину доступа к данным, с которой взаимодействует пользователь. Эти объекты позволяют моделировать структуру данных, а операторы — поведение данных.
Каждая БД и СУБД строится на основе некоторой явной или неявной модели данных. Все СУБД, построенные на одной и той же модели данных, относят к одному типу. Например, основой реляционных СУБД является реляционная модель данных, сетевых СУБД — сетевая модель данных, иерархических СУБД — иерархическая модель данных и т.д.
Реляционная модель данных (РМД) — логическая модель данных, прикладная теория построения баз данных, которая является приложением к задачам обработки данных таких разделов математикикак теории множеств и логика первого порядка.
На реляционной модели данных строятся реляционные базы данных.
Сетевая модель данных — логическая модель данных, являющаяся расширением иерархического подхода, строгая математическая теория, описывающая структурный аспект, аспект целостности и аспект обработки данных в сетевых базах данных.
Логическая модель данных. На следующем, более низком уровне находится логическая модель данных предметной области. Логическая модель описывает понятия предметной области, их взаимосвязь, а также ограничения на данные, налагаемые предметной областью. Примеры понятий - "сотрудник", "отдел", "проект", "зарплата". Примеры взаимосвязей между понятиями - "сотрудник числится ровно в одном отделе", "сотрудник может выполнять несколько проектов", "над одним проектом может работать несколько сотрудников". Примеры ограничений - "возраст сотрудника не менее 16 и не более 60 лет".
Логическая модель данных является начальным прототипом будущей базы данных. Логическая модель строится в терминах информационных единиц, но без привязки к конкретной СУБД. Более того, логическая модель данных необязательно должна быть выражена средствами именно реляционноймодели данных. Основным средством разработки логической модели данных в настоящий момент являются различные варианты ER-диаграмм (Entity-Relationship, диаграммы сущность-связь). Одну и ту же ER-модель можно преобразовать как в реляционную модель данных, так и в модель данных для иерархических и сетевых СУБД, или в постреляционную модель данных. Однако, т.к. мы рассматриваем именно реляционные СУБД, то можно считать, что логическая модель данных для нас формулируется в терминах реляционной модели данных.
Решения, принятые на предыдущем уровне, при разработке модели предметной области, определяют некоторые границы, в пределах которых можно развивать логическую модель данных, в пределах же этих границ можно принимать различные решения. Например, модель предметной области складского учета содержит понятия "склад", "накладная", "товар". При разработке соответствующей реляционной модели эти термины обязательно должны быть использованы, но различных способов реализации тут много - можно создать одно отношение, в котором будут присутствовать в качестве атрибутов "склад", "накладная", "товар", а можно создать три отдельных отношения, по одному на каждое понятие.
7. Иерархическая модель данных, ее достоинства и недостатки.
В иерархической модели связи между данными можно описать с помощью упорядоченного графа (или дерева). Упрощенно представление связей между данными в иерархической модели показано на рис. 2.
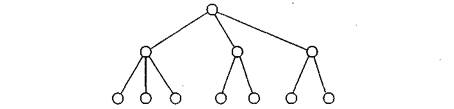
Рис.2. Иерархическая модель
Для описания структуры (схемы) иерархической БД на некотором языке программирования используется тип данных «дерево».
Тип «дерево» является составным. Он включает в себя подтипы («поддеревья»), каждый из которых, в свою очередь, является типом «дерево». Каждый из типов «дерево» состоит из одного «корневого» типа и упорядоченного набора (возможно, пустого) подчиненных типов. Каждый из элементарных типов, включенных в тип «дерево», является простым или составным типом «запись». Простая «запись» состоит из одного типа, например числового, а составная «запись» объединяет некоторую совокупность типов, например целое, строку символов и указатель (ссылку). Пример типа «дерево» как совокупности типов показан на рис. 3.
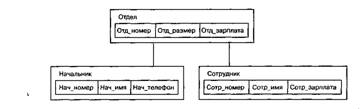
Рис. 3. Пример типа «дерево»
Корневым называется тип, который имеет подчиненные типы и сам не является подтипом. Подчиненный тип (подтип) является потомком по отношению к типу, который выступает для него в роли предка (родителя). Потомки одного и того же типа являются близнецами по отношению друг к другу.
В целом тип «дерево» представляет собой иерархически организованный набор типов «запись».
Иерархическая БД представляет собой упорядоченную совокупность экземпляров данных типа «дерево» (деревьев), содержащих экземпляры типа «запись» (записи). Поля записей хранят собственно числовые или символьные значения, составляющие основное содержание БД. Обход всех элементов иерархической БД обычно производится сверху вниз и слева направо.
Данные в базе с приведенной схемой (рис. 3) могут выглядеть, например, как показано на рис.4.
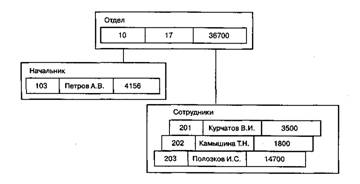
Рис. 4. Данные в иерархической базе
К основным операциям манипулирования иерархически организованными данными относятся следующие:
•поиск указанного экземпляра БД (например, дерева со значением 10 в поле Отд_номер);
• переход от одного дерева к другому;
• переход от одной записи к другой внутри дерева (например, к следую
щей записи типа Сотрудники);
• вставка новой записи в указанную позицию;
• удаление текущей записи и т. д.
К достоинствам иерархической модели данных относятся эффективное использование памяти ЭВМ и неплохие показатели времени выполнения основных операций над данными. Иерархическая модель данных удобна для работы с иерархически упорядоченной информацией.
Недостатком иерархической модели является ее громоздкость для обработки информации с достаточно сложными логическими связями, а также сложность понимания для обычного пользователя.
На иерархической модели данных основано сравнительно ограниченное количество СУБД, в числе которых можно назвать зарубежные системы IMS, PC/Focus, Team-Up и Data Edge, а также отечественные системы Ока, ИНЭС и МИРИС.
8. Сетевая модель данных, ее достоинства и недостатки.
На разработку этого стандарта большое влияние оказал американский ученый Ч.Бахман. Основные принципы сетевой модели данных были разработаны в середине 60-х годов, эталонный вариант сетевой модели данных описан в отчетах рабочей группы по языкам баз данных (COnference on DAta SYstem Languages) CODASYL (1971 г.).
Сетевая модель данных определяется в тех же терминах, что и иерархическая. Она состоит из множества записей, которые могут быть владельцами или членами групповых отношений. Связь между записью-владельцем и записью-членом также имеет вид 1:N.
Основное различие этих моделей состоит в том, что в сетевой модели запись может быть членом более чем одного группового отношения. Согласно этой модели каждое групповое отношение именуется и проводится различие между его типом и экземпляром. Тип группового отношения задается его именем и определяет свойства общие для всех экземпляров данного типа. Экземпляр группового отношения представляется записью-владельцем и множеством (возможно пустым) подчиненных записей. При этом имеется следующее ограничение: экземпляр записи не может быть членом двух экземпляров групповых отношений одного типа (т.е. сотрудник из примера в п..1, например, не может работать в двух отделах).
Иерархическая структура рис. 4.2 преобразовывается в сетевую модель, следующим образом (см. рис. 4.3):
· деревья (a) и (b), показанные на рис. 4.2, заменяются одной сетевой структурой, в которой запись СОТРУДНИК входит в два групповых отношения;
· для отображения типа M:N вводится запись СОТРУДНИК_КОНТРАКТ, которая не имеет полей и служит только для связи записей КОНТРАКТ и СОТРУДНИК, (см. рис. 4.3). Отметим, что в этой записи может храниться и полезная информация, например, доля данного сотрудника в общем вознаграждении по данному контракту.
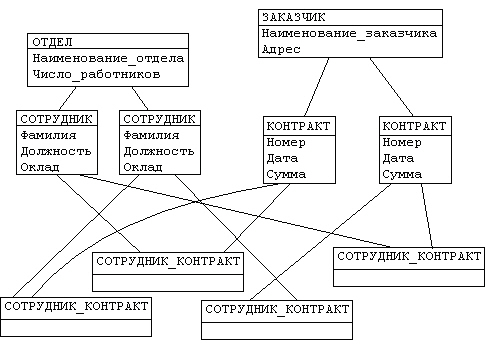
Рис. 4.3. Сетевая модель базы данных
Каждый экземпляр группового отношения характеризуется следующими признаками:
Способ упорядочения подчиненных записей:
· произвольный,
· хронологический /очередь/,
· обратный хронологический /стек/,
· сортированный.
Если запись объявлена подчиненной в нескольких групповых отношениях, то в каждом из них может быть назначен свой способ упорядочивания.
9. Реляционная модель данных. Ее отличие от графовых моделей (иерархической и сетевой).
Реляционная модель данных (РМД) — логическая модель данных, прикладная теория построения баз данных, которая является приложением к задачам обработки данных таких разделов математикикак теории множеств и логика первого порядка.
На реляционной модели данных строятся реляционные базы данных.
Реляционная модель данных включает следующие компоненты:
· Структурный аспект (составляющая) — данные в базе данных представляют собой набор отношений.
· Аспект (составляющая) целостности — отношения (таблицы) отвечают определенным условиям целостности. РМД поддерживает декларативные ограничения целостности уровня домена (типа данных), уровня отношения и уровня базы данных.
· Аспект (составляющая) обработки (манипулирования) — РМД поддерживает операторы манипулирования отношениями (реляционная алгебра, реляционное исчисление).
Информация в базе данных некоторым образом структурирована, т. е. ее можно описать моделью представления данных (моделью данных), которые поддерживаются СУБД. Эти модели подразделяют на иерархические, сетевые и реляционные.
При использовании иерархической модели представления данных связи между данными можно охарактеризовать с помощью упорядоченного графа (или дерева). В программировании при описании структуры иерархической базы данных применяют тип данных «дерево».
Основными достоинствами иерархической модели данных являются:
1) эффективное использование памяти ЭВМ;
2) высокая скорость выполнения основных операций над данными;
3) удобство работы с иерархически упорядоченной информацией.
К недостаткам иерархической модели представления данных относятся:
1) громоздкость такой модели для обработки информации с достаточно сложными логическими связями;
2) трудность в понимании ее функционирования обычным пользователем.
Незначительное число СУБД построено на иерархической модели данных.
Сетевая модель может быть представлена как развитие и обобщение иерархической модели данных, позволяющее отображать разнообразные взаимосвязи данных в виде произвольного графа.
Достоинствами сетевой модели представления данных являются:
1) эффективность в использовании памяти компьютера;
2) высокая скорость выполнения основных операций над данными;
3) огромные возможности (большие, чем у иерархической модели) образования произвольных связей.
К недостаткам сетевой модели представления данных относятся:
1) высокая сложность и жесткость схемы базы данных, которая построена на ее основе;
2) трудность для понимания и выполнения обработки информации в базе данных непрофессиональным пользователем.
Системы управления базами данных, построенные на основе сетевой модели, также не получили широкого распространения на практике.
Реляционная модель представления данных была разработана сотрудником фирмы 1ВМЭ. Коддом. Его модель основывается на понятии «отношения» (relation). Простейшим примером отношения служит двумерная таблица.
Достоинствами реляционной модели представления данных (по сравнению с иерархической и сетевой моделями) являются ее понятность, простота и удобство практической реализации реляционных баз данных на ЭВМ.
К недостаткам реляционной модели представления данных относятся:
1) отсутствие стандартных средств идентификации отдельных записей;
2) сложность описания иерархических и сетевых связей.
Большинство СУБД, применяемых как профессиональными, так и непрофессиональными пользователями, построены на основе реляционной модели данных (Visual FoxPro и Access фирмы Microsoft, Oracle фирмы Oracle и др.).
10. Основные понятия реляционной алгебры.