
Ви ведення результату оцінки застосовності .








Розглянути результати оцінки застосовності можна на вкладці Analyze. По суті, вона являє собою інструмент порівняння і виведення середніх значень для різних отриманих в ході експерименту параметрів і може використовуватися і для інших даних, а не тільки для експериментів, тому і може використовувати багато джерел - як щойно проведений експеримент (Experiment), так і вже створені в ході експерименту (і не тільки) файли (File) і бази даних (Database). І тому перед початком роботи з цією вкладкою потрібно вказати, звідки брати дані. Після цього поруч з кнопками буде показано, скільки результатів експерименту буде досліджено.
Фактично, відразу після цього можна натискати кнопку Perform Test, яка і виконує знаходження середнього. Так як всі оцінки проводяться на одних і тих же множинах, їх результати не є незалежними і тому звичайні методи знаходження середніх не підходять. Застосовують особливе середнє (скорегований перероблений результат t-тесту):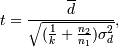
де 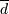 - це середня різниця між результатами оцінок, k - кількість результатів оцінок, n2 - число об'єктів в навчальній множині, n1 - число об'єктів в тестовій множині,
- це середня різниця між результатами оцінок, k - кількість результатів оцінок, n2 - число об'єктів в навчальній множині, n1 - число об'єктів в тестовій множині, 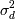 - стандартне відхилення.
- стандартне відхилення.
Саме воно і виводиться в комірках отриманої таблиці.
За замовчуванням, в результаті тесту обчислюється відсоток коректно класифікованих значень. Змінити це можна за допомогою поля Comparison field. Стовпці за замовчуванням є методами класифікації, рядки - наборами даних для класифікації. Змінити це можна за допомогою кнопок Rows Select і Colums Select (вибирати доведеться з набору даних оцінки, і не всі вибори є значущими). Також можна змінити статистичну значущість різниці (Significance) (чим нижче, тим більш імовірно визначається, що один з алгоритмів статистично відрізняється від іншого), показ стандартного відхилення (Show std. Deviation) (краще відразу поставити показувати), формат виводу (Output format) , а також базу порівняння (там можна вибрати базовий для статистичного порівняння алгоритм, або Summary - виводить матрицю, де в комірках - кількість наборів даних, в яких один алгоритм статистично кращий / нейтральний / гірший, ніж інший із заданою статистичною значущістю, або Ranking - виводить кількість перемог / поразок / нічиїх, в яких переміг чи програв певний алгоритм щодо інших алгоритмів).
Завдання: над своїми даними провести порівняння всіх алгоритмів класифікації, використаних у першій лабораторній роботі, методом десятипроходної крос-перевірки з кількістю ітерацій не менше 12. Зробити порівняння алгоритмів (Comparison field) за одним із полів. Спробуйте змінювати статистичну значущість. Що змінюється?
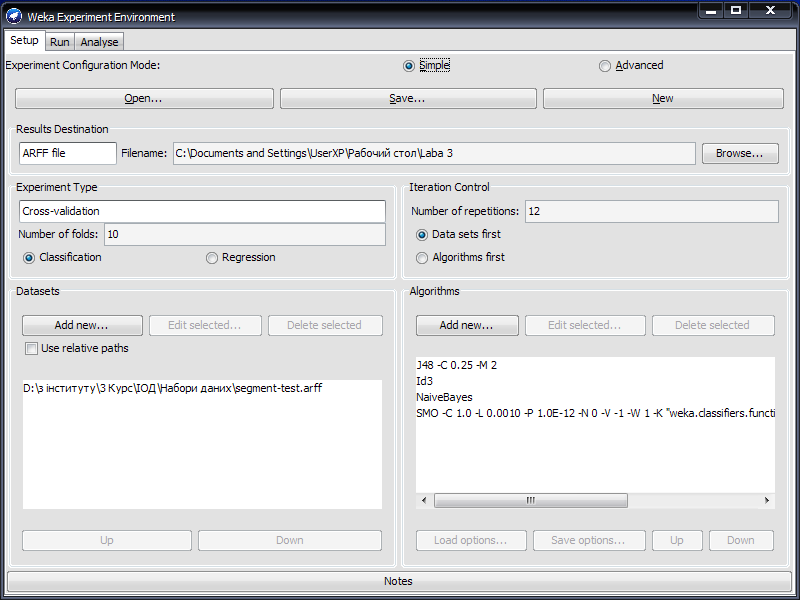 Здійснюємо настройку Weka Experiment таким чином
Здійснюємо настройку Weka Experiment таким чином
Запускаємо аналізатор
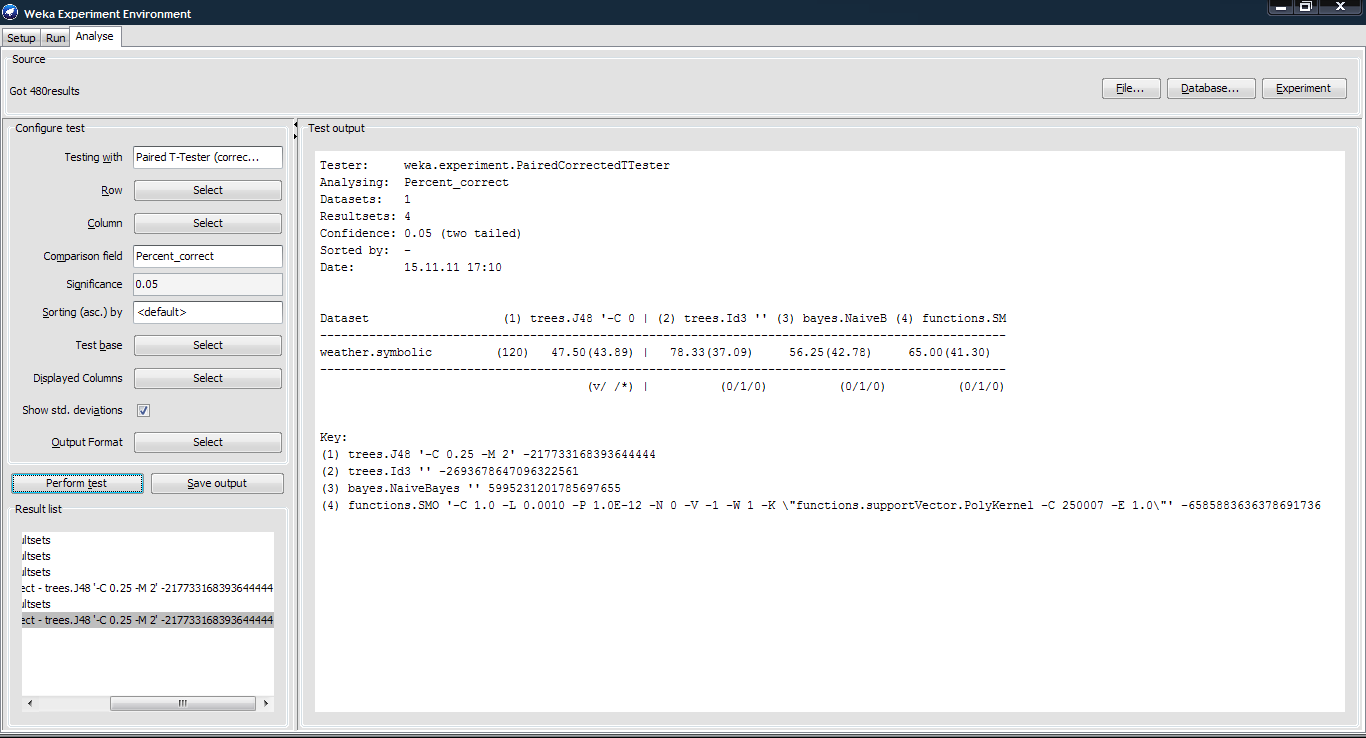
Tester: weka.experiment.PairedCorrectedTTester
Analysing: Percent_correct
Datasets: 1
Resultsets: 4
Confidence: 0.05 (two tailed)
Sorted by: -
Date: 15.11.11 17:10
Dataset (1) trees.J48 '-C 0 | (2) trees.Id3 '' (3) bayes.NaiveB (4) functions.SM
--------------------------------------------------------------------------------------------------
weather.symbolic (120) 47.50(43.89) | 78.33(37.09) 56.25(42.78) 65.00(41.30)
--------------------------------------------------------------------------------------------------
(v/ /*) | (0/1/0) (0/1/0) (0/1/0)
Key:
(1) trees.J48 '-C 0.25 -M 2' -217733168393644444
(2) trees.Id3 '' -2693678647096322561
(3) bayes.NaiveBayes '' 5995231201785697655
(4) functions.SMO '-C 1.0 -L 0.0010 -P 1.0E-12 -N 0 -V -1 -W 1 -K \"functions.supportVector.PolyKernel -C 250007 -E 1.0\"' -6585883636378691736
Як видно з результату найкраще для класифікації цього набору даних використовувати метод trees.Id3.
Висновок: в даній лабораторній роботі я визнач ив застосовності методів аналізу даних до певн ого набору даних за допомогою програми Weka .