
На рис. 3.29, а показано символическое изображение так называемого буферного элемента без инверсии.








Он содержит входную линию для данных, выходную линию для данных и входную линию для управления.
Когда управляющий вход равен 1, буферный элемент работает как замкнутый выключатель - проводник (рис, 3.29, б).
Когда управляющий вход равен 0, буферный элемент работает как разомкнутый выключатель.
Соединение может быть восстановлено за несколько наносекунд, если сделать сигнал управления равным 1.
На рис. 3,29, г показан буферный элемент с инверсией, который действует как обычный инвертор, когда сигнал управления равен 1, и отделяет выход от остальной части схемы, когда сигнал управления равен 0.
Оба буферных элемента представляют собой устройства с тремя состояниями, поскольку могут выдавать нулевой сигнал, единичный сигнал или вообще не выдавать никакого сигнала (случай разомкнутой цепи). Буферные элементы, кроме того, усиливают сигналы, поэтому они могут справляться с большим количеством сигналов одновременно. Иногда они используются в схемах именно в качестве усилителей.
Три буферных элемента без инверсии на линиях вывода данных в рассматриваемой логической схеме памяти 4-х 3-хразрядных слов, используются именно для этих целей.
Когда сигналы CS, RD и ОЕ равны 1, сигнал разрешения выдачи выходных данных также равен 1, в результате запускаются буферные элементы и слово помещается на выходные линии. Когда один из сигналов CS, RD и ОЕ равен 0, выходы отсоединяются от остальной части схемы.
Адреса памяти
Память состоит из ячеек, каждая из которых может хранить некоторую порцию информации. Каждая ячейка имеет номер, который называется адресом.
По адресу программы могут ссылаться на определенную ячейку. Если память содержит п ячеек, они будут иметь адреса от 0 до п - 1.
Все ячейки памяти содержат одинаковое число бит. Если ячейка состоит из k бит, она может содержать любую из 2 k комбинаций.
На рис. 2,8 показаны 3 различных варианта организации 96-битной памяти. Отметим, что соседние ячейки по определению имеют последовательные адреса.
В компьютерах, в которых используется двоичная система счисления, адреса памяти также выражаются в двоичных числах.
Если адрес состоит из т бит, максимальное число адресованных ячеек составит 2т. Например, адрес для обращения к памяти, изображенной на рис. 2,8, а, должен состоять по крайней мере из 4 бит, чтобы выражать все числа от 0 до 11.
При устройстве памяти, показанном на рис. 2.8, 6 и 2.8, в, достаточно 3-разрядного адреса.
Число бит в адресе определяет максимальное количество адресуемых ячеек памяти и не зависит от числа бит в ячейке.
 |
Например.
8-разрядные адреса нужны и памяти из 212 ячеек по 8 бит каждая, и памяти из 212 ячеек по 64 бит каждая.
Ячейка — минимальная единица памяти, к которой можно обращаться. В последние годы практически все производители выпускают компьютеры с 8-разрядными ячейками, которые называются байтами. Байты группируются в сло ва.
В компьютере с 32-разрядными словами на каждое слово приходится 4 байт, а в компьютере с 64-разрядными словами — 8 байт.
Такая единица как слово, необходима, поскольку большинство команд производят операции над целыми словами (например, складывают два слова).
Таким образом:
· 32-разрядная машина содержит 32-разрядные регистры и команды для операций с 32-разрядными словами,
· 64-разрядная машина имеет 64-разрядные регистры и команды для перемещения, сложения, вычитания и других операций над 64-разрядными словами.
Упорядочение байтов
 |
Байты в слове могут нумероваться слева направо или справа налево. На что это влияет?
 |
На рисунке а) изображена область 32-разрядной памяти, в которой байты пронумерованы слева направо. Компьютер, с такой памятью относится к категории компьютеров с прямым порядком следования байтов (big endian)
На рисунке, б) показана аналогичная область памяти 32-разрядного компьютера с нумерацией байтов справа налево (как у компьютеров Intel). Компьютер, с такой памятью относится к категории компьютеров с обратным порядком следования байтов (little endian)
Рисунок а). Адреса байт и полуслов в слове при прямом порядке (Little-endian).
Рисунок б). Адреса байт и полуслов в слове при обратном порядке (Big-endian).
Таким образом, в формате прямого порядка, байт с наименьшим адресом в слове рассматривается как младший значащий байт слова, а байт с наибольшим адресом - старший значащий байт.
В формате обратного порядка, старший значащий байт слова хранится в позиции байта с наименьшим порядковым номером, а младший байт - в позиции байта с наибольшим порядковым номером.
Оба этих представления хороши и внутренне последовательны. Проблемы начинаются тогда, когда один из компьютеров пытается переслать запись на другой компьютер по сети.
Формат представления целого числа одинаков в обеих системах. При этом, 32-разрядное целое число (например, 6) представлено кодом 110 в трех крайних правых битах слова, а остальные 29 бит представлены нулями.
После пересылки целого числа (6) из компьютера с прямым порядком следования байт в компьютер с обратным порядком следования байт, младший байт передаваемого целого числа с кодом 110 окажется старшим байтом целого числа.
В результате такой пересылки значение целого числа искажается.
Простого решения этой проблемы не существует. Есть один не эффективный способ, Нужно перед каждой единицей данных помещать заголовок, определяющий, какой тип данных следует за ним — строка, целое и т. д.
Это позволит компьютеру-получателю производить только необходимые преобразования. Отсутствие стандарта упорядочивания байтов является главным недостатком такого способа.
Код исправления ошибок
Память компьютера из-за всплесков напряжения и по другим причинам время от времени может ошибаться.
Чтобы бороться с ошибками, используются специальные коды, умеющие обнаруживать и исправлять ошибки.
В этом случае к каждому слову в памяти особым образом добавляются дополнительные биты. Когда слово считывается из памяти, эти дополнительные биты проверяются, что и позволяет обнаруживать ошибки.
Предположим, что слово состоит из m бит данных, к которым мы дополнительно прибавляем r бит (контрольных разрядов).
Пусть общая длина слова составит n бит (то есть n = m + r). Совокупность из n бит, содержащую m бит данных и r контрольных разрядов, часто называют кодовым словом.
Для любых двух кодовых слов, например 100 010 01 и 101 100 01, можно определить, сколько соответствующих битов в них различаются. В данном примере таких бита три.
Чтобы определить количество различающихся битов, нужно над двумя кодовыми словами произвести логическую операцию ИСКЛЮЧАЮЩЕЕ ИЛИ и сосчитать количество битов со значением 1 в полученном результате.
Число битовых позиций, по которым различаются два слова, называется интервалом Хэмминга.
Если интервал Хэмминга для двух слов равен d, это значит, что достаточно d битовых ошибок, чтобы превратить одно слово в другое.
Например, интервал Хэмминга для кодовых слов 1111 0001 и 0011 0000 равен 3, поскольку для превращения первого слова во второе достаточно 3 битовые ошибки.
Память состоит из m-разрядных слов, следовательно, существуют 2т вариантов сочетания битов.
Кодовые слова состоят из п бит, но из-за способа подсчета контрольных разрядов допустимы только 2т из 2 n кодовых слов.
Если в памяти обнаруживается недопустимое кодовое слово, компьютер знает, что произошла ошибка.
В качестве простого примера кода с обнаружением ошибок рассмотрим код, в котором к данным присоединяется один бит четности.
Бит четности выбирается таким образом, чтобы число битов со значением 1 в кодовом слове было четным (или нечетным).
Интервал Хэмминга для этого кода равен 2, поскольку любая одиночная битовая ошибка приводит к кодовому слову с неправильной четностью. То есть, достаточно двух одиночных битовых ошибок для перехода от одного допустимого кодового слова к другому допустимому слову.
Такой код может использоваться для обнаружения одиночных ошибок. Если из памяти считывается слово с неверной четностью, это является признаком наличия ошибки. В этом случае вырабатывается сигнал об ошибке и программа не сможет выполняться, но зато не выдаст неверных результатов.
Кроме обнаружения ошибок, коды Хеминга позволяют исправлять обнаруженные ошибки.
Рассмотрим в качестве примера графическую схему, которая иллюстрирует идею кода исправления ошибок для 4-разрядных слов.
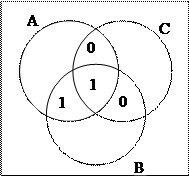 |
Диаграмма Венна на рис, 2.11 содержит 3 круга, А, В и С, которые вместе образуют семь секторов.
Закодируем в качестве примера слово из 4 бит – 1100, записав по одному биту этого слова в сектора АВ, АВС, АС и ВС в алфавитном порядке.
Далее, добавим бит четности к каждому из трех пустых секторов А, В и С, чтобы сумма битов в каждом из этих кругов получилась четной. Таким образом, кодовое слово, будет состоять из 4 бит данных и 3 бит четности.
 |
В круге А находится 4 числа: 0, 0, 1 и 1, которые в сумме дают четное число 2,
В круге В находятся числа 1. 1, 0 и 0, которые также в сумме дают четное число 2.
Аналогичная ситуация и для круга С.
В данном примере получилось так, что все суммы одинаковы, но вообще случае возможны также суммы 0 (все 0) и 4 (все 1).
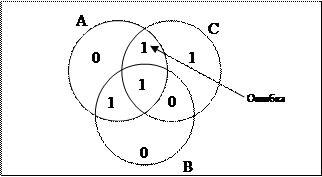 |
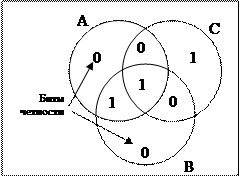
Предположим, что бит в секторе АС изменился с 0 на 1, как показано на рисунке.
Компьютер, после считывания кодового слова и подсчета контрольных сумм, обнаруживает, что контрольные суммы для кругов А и С являются нечетными. То есть сумма всех битов принадлежащих А равна 3 и принадлежащих С также равна 3.
Единственный способ исправить ошибку, изменить только один бит — возвратить значения 0 биту в секторе АС.
Таким способом компьютер может обнаруживать и исправлять одиночные ошибки автоматически.
Использование алгоритма Хэмминга при создании кодов обнаружения и исправления одиночных ошибок для слов любою размера.
В коде Хэмминга к слову, состоящему из т бит, добавляются r бит четности, при этом образуется слово длиной n=т+ r бит.
Биты нумеруются с единицы (а не с нуля), причем первым считается крайний левый.
Все биты, номера которых равны степени двойки, являются битами четности, остальные используются для данных.
Например, к 16-разрядному слову нужно добавить 5 бит четности.
Биты с номерами 1, 2, 4, 8 и 16 — биты четности, все остальные — биты данных. Таким образом кодовое слово содержит 21 бит (16 бит данных и 5 бит четности).
В рассматриваемом примере, для определенности, мы будем использовать проверку на четность (выбор произвольный).
 |
Каждый бит четности позволяет проверять определенные битовые позиции. Общее количество битов со значением 1 в проверяемых позициях должно быть четным.
- бит 1 проверяет биты 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21;
- бит 2 проверяет биты 2, 3, 6, 7, 10, 11, 14, 15, 18, 19;
- бит 4 проверяет биты 4, 5, 6, 7, 12, 13, 14, 15, 20, 21;
- бит 8 проверяет биты 8, 9, 10. 11, 12, 13, 14. 15;
- бит 16 проверяет биты 16, 17, 18, 19, 20, 21,
В общем случае бит b проверяется битами b1, b2 , ... , bj такими, что b1 + b2 + … + bj = b, b - это номер бита.
Например, бит 5 проверяется битами 1 и 4, поскольку 1 + 4 = 5,
Бит 6 проверяется битами 2 и 4, поскольку 2 + 4 = 6 и т. д.
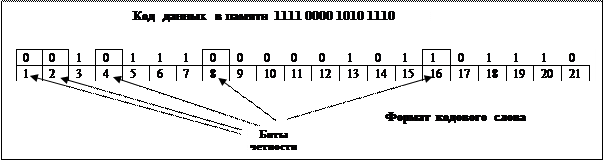
Рассмотрим, что произойдет, если бит 5 изменит значение (например, из-за резкого скачка напряжения). В результате вместо кодового слова 001 011 100 000 101 101 110 получится 001 001 100 000 101 101 110.
При считывании кодового слова из памяти будут проверены все 5 бит четности со следующими результатами:
· неправильный бит четности 1 (биты 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21 содержат пять единиц);
· правильный бит четности 2 (биты 2, 3, 6, 7, 10, 11, 14, 15, 18. 19 содержат шесть единиц);
· неправильный бит четности 4 (биты 4, 5, 6, 7, 12, 13, 14, 15, 20, 21 содержат пять единиц);
· правильный бит четности 8 (биты 8. 9, 10, 11, 12, 13, 14, 15 содержат две единицы);
· правильный бит четности 16 (биты 16, 17, 18, 19, 20, 21 содержат четыре единицы).
Общее количество единиц в битах контролируемых соответствующим правильным битом четности, должно быть четным. (Поскольку в данном примере используется проверка на четность).
Ошибочным должен быть один из битов, проверяемых неправильными битами четности, а именно:
· бит четности 1 - (ошибка в одном из следующих битов 1, 3, 5, 7, 9, 11, 13, 15, 17, 19 и 21).
· бит четности 4 - (ошибка в одном из следующих битов 4, 5, 6, 7, 12, 13, 14, 15, 20, 21)
Ошибка должна быть в бите, который содержится в обоих списках.
В данном примере общими являются биты 5, 7, 13, 15 и 21.
Поскольку бит четности 2 - правильный, биты 7 и 15 исключаются.
Правильность бита четности 8 исключает наличие ошибки в бите 13.
Наконец, бит 21 также исключается, поскольку бит четности 16 правильный.
В итоге остается бит 5, в котором и кроется ошибка. Поскольку этот бит имеет значение 1, он должен принять значение 0. Так выполняется исправление ошибки.
Таким образом общий алгоритм поиска и исправления ошибочного бита включает следующие шаги:
1. Подсчитать все биты четности.
2. Если они правильные, ошибки нет (или есть, но ошибка не однократная).
3. Если обнаружились неправильные биты четности, нужно сложить их номера.
4. Сумма, полученная в результате, даст номер позиции ошибочного бита.
5. Значение ошибочного бита инвертируется (0 заменяется 1, а 1 заменяется 0)
Например, если биты четности 1 и 4 неправильные, а 2, 8 и 16 правильные, то ошибка произошла в бите 5(1+ 4).
Кэш-память
Время выполнения команд процессором, как правило, всегда существенно меньше времени выборки данных из оперативной памяти.
Такое несоответствие в скорости работы приводит к тому, что, когда процессор обращается к памяти, проходит несколько машинных циклов, прежде чем он получит запрошенное слово. Чем медленнее работает память, тем дольше процессору приходится ждать, (простой процессора).
В большей степени эта проблема не технологическая, а экономическая.
Технологически можно создать память, которая работает так же быстро, как процессор. Однако ее приходится помещать прямо на микросхему процессора (поскольку информация через шину поступает существенно медленнее).
Размещение памяти большого объема на микросхеме процессора делает его больше и, следовательно, дороже, и даже если бы стоимость не имела значения, все равно существуют технологические ограничения на размеры создаваемых процессоров.
Таким образом, приходится выбирать между быстрой памятью небольшого объема и медленной памятью большого объема. (Мы, естественно, предпочли бы иметь быструю память большого объема и к тому же дешевую.)
Однако существует способ, объединяющий небольшую и быструю память с большой и медленной памятью.
Это позволяет по разумной цене получить память и с высокой скоростью работы, и с большой емкостью.
Память небольшого объема с высокой скоростью работы называется кэш-памятью.
В английском языке слово « cash получило значение «наличные (карманные) деньги, то есть то, чтo под рукой. А уже из него и образовался термин "кэш", который относят к сверхоперативной памяти.
Основная идея кэш-памяти проста: в ней находятся слова с данными, которые чаще всего используются.
Если процессору нужно какое-нибудь слово, сначала он обращается к кэш-памяти. Только в том случае, если слова там нет (кэш-промах), он обращается к основной памяти. Если значительная часть слов находится в кэш-памяти, среднее время доступа значительно сокращается.
Таким образом, эффективность кэш-памяти определяется тем, какая часть слов находится в кэш-памяти.
Известно, что программы не обращаются к памяти наугад. Если программе нужен доступ к адресу А то скорее всего после этого ей понадобится доступ к адресу, расположенному поблизости от А.
Практически все команды обычной программы (за исключением команд перехода и вызова процедур) вызываются из последовательных областей памяти. Кроме того, большую часть времени программа тратит на циклы, когда ограниченный набор команд выполняется снова и снова.
Высокая вероятность последовательных обращений к ограниченному (локальному) объему памяти в течение некоторого промежутка времени, называется принципом локальности.
Этот принцип лежит в основе всех систем кэш-памяти.
Идея состоит в том, что когда определенное слово вызывается из памяти, оно вместе с соседними словами переносится в кэш-память, что позволяет при очередном запросе быстро обращаться к следующим словам.
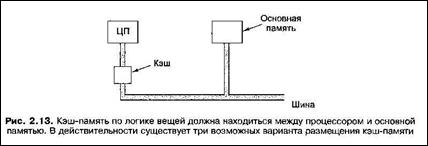 |
Схема подключения процессора, кэш-памяти и основной памяти показана на рисунке.
Если слово считывается или записывается k раз, компьютеру требуется сделать 1 обращение к медленной основной памяти и k - 1 обращений к быстрой кэш-памяти. Чем больше k, тем выше общая производительность.
В некоторых системах обращение к основной памяти может начинаться параллельно с проверкой кэш-памяти, чтобы в случае кэш-промаха цикл обращения к основной памяти уже начался. Однако эта стратегия требует способности останавливать процесс обращения к основной памяти в случае кэш-попадания, что усложняет разработку подобного компьютера.
Основная память и кэш-память делятся на блоки фиксированного размера с учетом принципа локальности.
Блоки внутри кэш-памяти обычно называют строками кэша (cache lines). При кэш-промахе из основной памяти в кэш-память загружается вся строка, а не только необходимое слово.
Например, если строка состоит из 64 байт, обращение к адресу 260 влечет за собой загрузку в кэш-память всей строки (байты с 256 по 319) на случай, если через некоторое время понадобятся другие слова из этой строки.
Такой путь обращения к памяти более эффективен, чем вызов каждого слова по отдельности, потому что однократный вызов k слов происходит гораздо быстрее, чем вызов одного слова k раз.
Кэш-память очень важна для повышения производительности процессоров. Однако при этом возникают следующие вопросы:
- Какой объем кэш-памяти должен быть? Чем больше объем, тем лучше работает память, но тем дороже она стоит.
- Какой размер должен быть у строки кэш-памяти? Кэш-память объемом 16 Кбайт можно разделить на 1024 строки по 16 байт, или 2048 строк по 8 байт и т. д.
- Какое использовать правило для определения, какие именно слова должны находятся в данный момент в Кеш-памяти?
- Должны ли команды и данные находиться вместе в общей кэш-памяти?
Более простая (и дешевая) объединенная кэш-память (unified cache), в которой охраняться и данные и команды.
В настоящее время существует тенденция к использованию разделенной кэш-памяти (split cache), когда команды хранятся в одной кэш-памяти, а данные — в другой.
Такая архитектура также называется гарвардской (Harvard architecture), поскольку эта идея родилась в Гарвардском университете.
Разделенная кэш-память позволяет осуществлять параллельный доступ к командам и к данным, а объединенная — нет.
К тому же, поскольку команды обычно не меняются во время выполнения программы, содержание кэша-команд не приходится записывать обратно в основную память, в отличие от содержимого кэша-данных.
Какой использовать способ размещения блоков кэш-памяти? В настоящее время блок кэш-память может располагаться:
- прямо на микросхеме процессора - кэш-память первого уровня,
- не на самой микросхеме, но в корпусе процессора - кэш-память второго уровня
- вне корпуса микросхемы процессора — кэш-память третьего уровня.
Типы оперативной памяти
Память, позволяющая процессору считывать и записывать хранимые в ней данные называется ОЗУ (оперативное запоминающее устройство), или RAM (Random Access Memory — память с произвольным доступом).
Существует два типа ОЗУ: статическое и динамическое.
Статическое ОЗУ (Static RAM, SRAM) конструируется с использованием D-триггеров. Информация в ОЗУ сохраняется неизменной (статической) на протяжении всего времени, пока к нему подается питание: секунды, минуты, часы и даже дни.
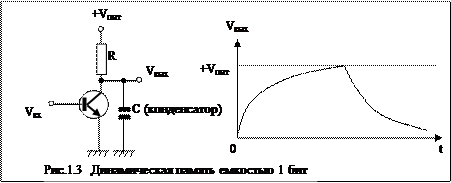 |
Статическое ОЗУ работает очень быстро. Обычно время доступа составляет несколько наносекунд. По этой причине статическое ОЗУ часто используется в качестве кэш-памяти второго уровня.
В динамическом ОЗУ (Dynamic RAM, DRAM), , триггеры не используются.
Динамическое ОЗУ представляет собой массив ячеек, каждая из которых содержит транзистор и конденсатор.
Конденсатор может находится в разряженном заряженном или состоянии, что позволяет использовать его для хранения одного бита информации , принимающему соответственно значение ноль или единица.
Поскольку электрический заряд в течение времени уменьшается за счет собственного тока утечки, а также тока закрытого транзистора, каждый бит в динамическом ОЗУ должен обновляться (перезаряжаться, регенерироваться, динамически изменяться) каждые несколько миллисекунд, чтобы предотвратить потерю данных.
Поскольку об обновлении должна заботиться внешняя логика, динамическое ОЗУ требует более сложного управления, чем статическое.
Однако этот недостаток компенсируется возможностью размещения в одной микросхеме большого объема памяти, при существенно меньшей стоимости.
Поскольку динамическому ОЗУ нужен только 1 транзистор и 1 конденсатор на бит данных (статическому ОЗУ требуется в лучшем случае 6 транзисторов на бит), динамическое ОЗУ имеет очень высокую плотность памяти (много бит на одну микросхему).
По этой причине основная память почти всегда строится на основе динамических ОЗУ.
Однако динамические ОЗУ работают очень медленно (время доступа занимает десятки наносекунд).
Таким образом, сочетание кэш-памяти на основе статического ОЗУ и основной памяти на основе динамического ОЗУ соединяет в себе преимущества обоих устройств.
Энергонезависимая память
Во многих случаях после отключения питания компьютера ни программы, ни данные не должны изменяться, тоесть быть постоянными. (например, если речь идет об игрушках, различных приборах и машинах).
- Это требование привели к появлению ПЗУ (постоянных запоминающих устройств), или ROM (Read-Only Memory —память только для чтения).
ПЗУ не позволяют изменять и стирать хранящуюся в них информацию (ни умышленно, ни случайно). Данные записываются в ПЗУ в процессе производства.
Для этого изготавливается трафарет с определенным набором битов, который накладывается на фоточувствительный материал, а затем открытые (или закрытые) части поверхности вытравливаются.
Единственный способ изменить данные в ПЗУ — поменять всю микросхему. ПЗУ стоят гораздо дешевле ОЗУ, если заказывать их большими партиями, чтобы оплатить расходы на изготовление трафарета.
Однако они не допускают изменений после выпуска с производства, а между подачей заказа на ПЗУ и его выполнением может пройти несколько недель.
- Чтобы компаниям было проще разрабатывать новые устройства, основанные на ПЗУ, были выпущены програм мируемые ПЗУ (Programmable ROM, "память с возможностью программирования" PROM).
В отличие от обычных ПЗУ, их можно программировать в условиях эксплуатации, что позволяет сократить время выполнения заказа.
Многие программируемые ПЗУ содержат массив крошечных плавких перемычек. Чтобы пережечь определенную перемычку, нужно выбрать требуемые строку и столбец, а затем приложить высокое напряжение к определенному выводу микросхемы.
- Следующая тип памяти — стираемое программируемое ПЗУ (Erasable PROM, EPROM "память допускающая стирание и программирование), которое можно программировать в условиях эксплуатации, а также стирать с него информацию.
Если кварцевое окно в данном ПЗУ подвергать воздействию сильного ультрафиолетового света в течение 15 минут, все биты установятся в 1.
Если нужно сделать много изменений во время одного этапа проектирования, стираемые ПЗУ гораздо экономичнее, чем обычные программируемые ПЗУ, поскольку их можно использовать многократно. Стираемые программируемые ПЗУ обычно устроены так же, как статические ОЗУ.
Следующий тип памяти — электронно-перепрограммируемое ПЗУ (Electronically EPROM, EEPROM), с которого можно стирать информацию, прилагая к нему импульсы, и которое не нужно для этого помещать в специальную камеру, чтобы подвергнуть воздействию ультрафиолетовых лучей.
Кроме того, чтобы перепрограммировать данное устройство, не нужно использовать специальный программатор, в отличие от стираемого программируемого ПЗУ.
В то же время самые большие электронно-перепрограммируемые ПЗУ в 64 раза меньше обычных стираемых ПЗУ, и работают они в два раза медленнее.
Электронно-перепрограммируемые ПЗУ работают в 10 раз медленнее динамических и статических ОЗУ, их емкость в 100 раз меньше, а они стоят гораздо дороже.
- Более современный тип электронно-перепрограммируемого ПЗУ — флэш-память, которая стирается и записывается блоками.
Флеш-память хранит информацию в массиве транзисторов с плавающим затвором, называемых ячейками (англ. cell).
В традиционных устройствах с одноуровневыми ячейками (англ. single-level cell, SLC), каждая из них может хранить только один бит. Некоторые новые устройства с многоуровневыми ячейками (англ. multi-level cell, MLC; triple-level cell, TLC [2]) могут хранить больше одного бита, используя разный уровень электрического заряда на плавающем затворе транзистора.
В настоящее время флэш-память, обладая временем доступа в 50 нс., и начинает вытеснять магнитные диски. Область применения флэш-памяти очень широкая.
Основной технической проблемой на современном уровне развития этой технологии является то, что флэш-память изнашивается после 100 000 операций стирания, а диски могут служить годами независимо от количества перезаписей данных.
Микросхемы процессоров
Все современные процессоры размещаются на одной микросхеме. Это определяет способ взаимодействия процессора с остальными частями ЭВМ.
Каждая микросхема процессора содержит набор выводов, через которые происходит обмен информацией с другими устройствами.
Выводы микросхемы центрального процессора можно подразделить на три типа:
· адресные,
· информационные и
· управляющие.
Эти выводы связаны с соответствующими выводами на микросхемах памяти и микросхемах устройств ввода-вывода через набор параллельных проводов (так называемую шину).
Чтобы вызвать команду, центральный процессор сначала посылает в память адрес этой команды по адресным выводам.
Затем он задействует одну или несколько линий управления, чтобы сообщить памяти, что ему нужно, например, прочитать слово.
Память выдает ответ, помещая требуемое слово на информационные выводы процессора и посылая сигнал о том, что это сделано.
Когда центральный процессор получает этот сигнал, он считывает слово и выполняет вызванную команду.
Команда может требовать чтения или записи слов, содержащих данные. В этом случае весь процесс повторяется для каждого дополнительного слова.
Таким образом, центральный процессор обменивается информацией с памятью и устройствами ввода-вывода, подавая сигналы на выводы и принимая сигналы на входы. Другого способа обмена информацией не существует.
Число адресных выводов и число информационных выводов — два ключевых параметра, которые определяют производительность процессора.
Микросхема, содержащая т адресных выводов, может обращаться к 2т ячейкам памяти. Обычно т равно 16, 20, 32 или 64.
Микросхема, содержащая п информационных выводов, может считывать или записывать п -разрядное слово за одну операцию. Обычно п равно 8. 16. 32, 36 или 64.
Центральному процессору с 8 информационными выводами чтобы считать 32-разрядное слово потребуется 4 операции. Процессор, имеющий 32 информационных вывода, может сделать ту же работу в рамках одной операции.
Следовательно, микросхема с 32 информационными выводами работает гораздо быстрее, но и стоит гораздо дороже.
Помимо адресных и информационных выводов, каждый процессор содержит управляющие выводы. Эти выводы позволяют регулировать и синхронизировать поток данных к процессору и от него, а также выполнять другие функции.
Все процессоры содержат выводы для питания (обычно +3,3 В или +5 В), земли и синхронизирующего сигнала (меандра). Остальные выводы разнятся от процессора к процессору. Тем не менее, управляющие выводы можно разделить на несколько основных категорий:
· управление шиной
· прерывания;
· арбитраж шины;
· сигналы сопроцессора;
· состояние;
· прочие
Схема типичного центрального процессора, в котором используются эти типы сигналов, изображена на рис. 3.32.
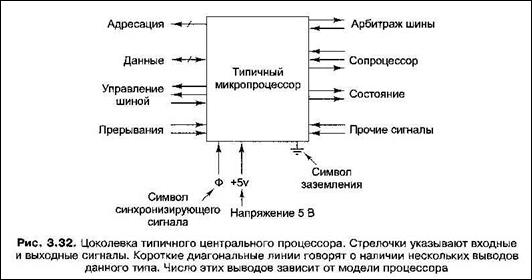 |
Выводы управления шиной обеспечивают передачу сигналов из центрального процессора в шину и, далее на входы микросхем памяти и микросхем устройств вводам вывода.
Эти сигналы позволяют сообщить памяти или УВВ тип выполняемой процессором операции - чтение или запись данных.
Выводы прерывания — это входы обеспечивают прием в процессор сигналов из устройств ввода-вывода.
В большинстве систем процессор может дать сигнал устройству ввода-вывода начать операцию, а затем приступить к какому-нибудь другому действию, пока устройство ввода-вывода выполняет свою работу.
Когда устройство ввода-вывода заканчивает свою работу, контроллер ввода-вывода может посылает сигнал на один из выводов прерывания, чтобы прервать работу процессора и заставить его обслужить устройство ввода-вывода (например, считать данные, проверить ошибки ввода-вывода). Некоторые процессоры содержат выходной вывод, призванный подтверждать получение сигнала прерывания.
Выводы арбитража шины нужны для того, чтобы регулировать поток информации в шине, то есть не допускать таких ситуаций, когда два устройства пытаются воспользоваться шиной одновременно. В плане арбитража центральный процессор считается просто одним из устройств.
Некоторые центральные процессоры могут работать с различными сопроцессорами (например, с графическими процессорами, процессорами для обработки данных в формате с плавающей точкой и т. п.). Чтобы обеспечить обмен информацией между процессором и сопроцессором, используются специальные выводы.
Помимо этих выводов, у некоторых процессоров есть дополнительные выводы. Одни из них выдают или принимают информацию о состоянии процессора, другие используются для перезагрузки компьютера, третьи призваны обеспечивать совместимость со старыми микросхемами устройств ввода-вывода.
Шины
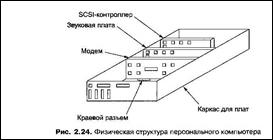 |
Большинство персональных компьютеров и рабочих станций имеют физическую структуру, сходную с показанную на рис, 2-24.
Типичное устройство ПК представляет собой металлический корпус (системный блок) в котором размещена большая электронная плата, которую называют материнской платой (или системной платой).
Материнская плата содержит микросхему процессора, несколько разъемов для модулей оперативной памяти и различные вспомогательные микросхемы.
На материнской плате располагаются шина (она тянется вдоль платы) и несколько разъемов для подсоединения устройств ввода-вывода.
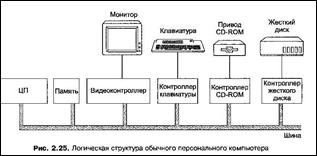 |
Схема логической структуры типичного персонального компьютера имеет вид:
У данного компьютера имеется одна шина для соединения центрального процессора, памяти и устройств ввода-вывода; однако большинство современных ПК имеют две и более шины.
Каждое устройство ввода-вывода состоит из двух частей: одна объединяет большую часть электроники и называется контроллером, а другая представляет собой само устройство ввода-вывода, например дисковод.
Контроллер обычно располагается на плате, которая вставляется в свободный разъем системной платы.
Исключение представляют собой встроенные контроллеры устройств, являющихся неотъемлемыми составными частями компьютера (например, клавиатуры, дисплея), которые располагаются на материнской плате.
Контроллер управляет своим устройством ввода-вывода и для этого использует доступ к шине.
Например, если программа запрашивает данные с диска, она посылает команду контроллеру диска, который затем отправляет диску команду поиска данных.
После считывания данных диск начинает передавать контроллеру информацию в виде потока битов. Задача контроллера состоит в том, чтобы разбить поток битов на блоки (байты, слова) и записывать каждый такой блок в память.
Если контроллер считывает данные из памяти или записывает их в память без участия центрального процессора, то говорят, что осуществляется прямой доступ к памяти (ПДП) (Direct Memory Access, DMA).
Когда передача данных заканчивается, контроллер вызывает прерывание, вынуждая центральный процессор приостанавливать работу текущей программы и начинать выполнение программы обработки прерываний.
Эта программа проверяет, наличие ошибок, в случае их обнаружения выполняет необходимые действия по их устранению, а также и сообщает операционной системе о завершении, процесса ввода-вывода.
Когда программа обработки прерывания завершается, процессор возобновляет работу программы, которая была приостановлена в момент прерывания.
Шина используется не только контроллерами ввода-вывода, но и процессором для передачи команд и данных.
В этом случае если процессор и контроллер ввода-вывода хотят получить доступ к шине одновременно особая микросхема, которая называется арбитром шины, решает, чья очередь первая.
Обычно предпочтение отдастся устройствам ввода-вывода, поскольку работу дисков и других движущихся устройств нельзя прерывать, так как это может привести к потере данных.
Когда ни одно устройство ввода-вывода не функционирует, центральный процессор может полностью распоряжаться шиной для взаимодействия с памятью.
Однако если работает какое-нибудь устройство ввода-вывода, оно будет запрашивать доступ к шине и получать его каждый раз, когда ему это необходимо. Этот процесс, который притормаживает работу компьютера, называется захватом цикла памяти (cycle stealing).
Описанная структура успешно использовалась в первых персональных компьютерах, поскольку все их компоненты работали с примерно одинаковой скоростью. Одной из таких широко использовавшихся шин была шиной ISA (Industry Standard Architecture — стандартная промышленная архитектура).
Однако как только центральные процессоры, память и устройства ввода-вывода стали работать быстрее, шина перестала справляться с нагрузкой.
В результате начали производить компьютеры с несколькими шинами, одной из которых была либо прежняя шина ISA, либо шина EISA (Extended ISA — расширенная стандартная промышленная архитектура), как и ISA, совместимая со старыми устройствами ввода-вывода.
В настоящее время самой популярной моделью шин является шина PCI (Peripheral Component Interconnect — взаимодействие периферийных компонентов), разработанная компанией Intel.
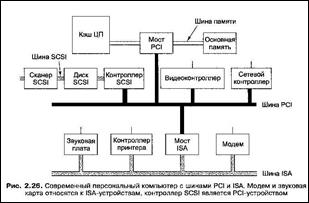 |
Типичная конфигурация шины PCL показана на рис, 2.26.
В такой конфигурации центральный процессор взаимодействует с контроллером памяти по выделенному высокоскоростному соединению – шина памяти.
Таким образом, процессор соединяется с памятью непосредственно, то есть передача данных между центральным процессором и памятью происходит не через шину PCI.
Высокоскоростные периферийные устройства» например видеоадаптер, могут подсоединяться прямо к шине PCI.
Кроме того, шина PCI имеет параллельное соединение с шиной ISA, чтобы можно было использовать контроллеры ISA соответствующих устройств.
Машина такого типа обычно содержит 3 или 4 пустых разъема PCI и еще 3 или 4 пустых разъема ISA, чтобы покупатели имели возможность вставлять как старые платы ввода-вывода ISA (для низко скоростных устройств), так и новые карты PCI (для высокоскоростных устройств1).
В современных ПК шина ISA уже не используется.
PCI Express
Возможностей шины PCI вполне достаточно для большинства современных приложений, однако потребность в ускорении выполнения операций ввода-вывода делает такую архитектуру ПК не эффективной.. внутреннюю архитектуру ПК.
Еще один недостаток шипы PCI состоит в больших габаритах плат. Их трудно уместить в корпуса современных портативных компьютеров, не говоря уже о карманных моделях.
С целью устранения этих недостатков появилась шина PCI Express, (Intel).
Она не имеет почти ничего общего с шиной PCI; более того — это вообще не шина. Тем не менее маркетологи решили не избавляться от названия PCI.
Некоторые ПК уже сейчас поддерживают эту технологию.