
Модель (5) відома як модель адаптивних очікувань. Коефіцієнт називається коефіцієнтом очікування.








Рівняння (5) можна переписати у виді:
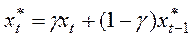 (6)
(6)
З (6) видно, що очікуване значення 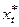 є зваженим середнім між поточним значенням
є зваженим середнім між поточним значенням 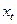 і його очікуваним значенням у попередній період з вагами
і його очікуваним значенням у попередній період з вагами 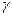 і
і 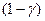 відповідно. Якщо
відповідно. Якщо 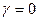 , то очікування є незмінними (статичними):
, то очікування є незмінними (статичними): 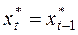 . Якщо
. Якщо 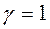 , те
, те 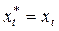 , що означає миттєво реалізовані очікування.Підставивши співвідношення (6) у (4), одержимо:
, що означає миттєво реалізовані очікування.Підставивши співвідношення (6) у (4), одержимо:
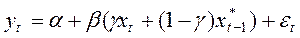 (7)
(7)
Віднімаючи з (7) аналогічне рівняння для 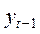 , помножене на , одержимо:
, помножене на , одержимо:
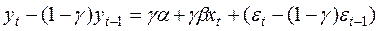 (8)
(8)
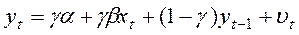

де 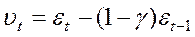 .
.
Модель адаптивних очікувань може використовуватися при аналізі залежності споживання від доходу, попиту на гроші або інвестиції від процентної ставки й в інших ситуаціях, де економічні показники чуттєві до очікувань відносно майбутнього.
4. Авторегресійні моделі. Модель часткових пристосувань.
Авторегресійна модель – це кореляційно-регресійна модель, яка, крім факторних ознак, містить одне або більше попередніх значень результуючої змінної.
У моделі часткового пристосування (моделі акселератора) у рівняння регресії в якості залежної змінної входить не фактичне значення 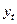 , а бажане (довгострокове) значення
, а бажане (довгострокове) значення 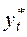 :
:
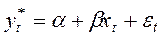 (9)
(9)
Щодо значення 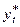 висувається припущення часткового коригування:
висувається припущення часткового коригування:
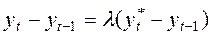 (10)
(10)
по який фактичне збільшення залежної змінної пропорційне різниці між її бажаним значенням і значенням у попередній період. 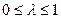 – коефіцієнт коригування. Рівняння (10) можна перетворити до наступного виду:
– коефіцієнт коригування. Рівняння (10) можна перетворити до наступного виду:
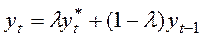 (11)
(11)
З (10) видно, що поточне значення є зваженим середнім бажаного рівня 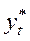 і фактичного значення даної змінної в попередній період. Чим більше
і фактичного значення даної змінної в попередній період. Чим більше 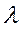 , тим швидше йде коректування. При
, тим швидше йде коректування. При 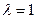 повне коректування відбувається за один період. При
повне коректування відбувається за один період. При 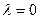 коригування не відбувається зовсім.
коригування не відбувається зовсім.
Підставивши (11) у (9), одержимо модель часткового пристосування:
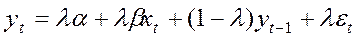 (12)
(12)
5. Визначення коефіцієнта детермінації для багатофакторної лінійної регресії, оцінка його статистичної значущості.
Для перевірки загальної якості рівняння багатофакторної регресії застосовують:
1. Коефіцієнт детермінації:
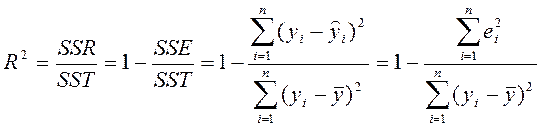 (12)
(12)
2. Скоригований коефіцієнт детермінації:
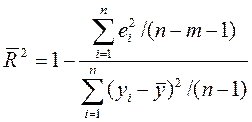 (13)
(13)
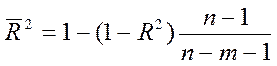 (14)
(14)
З (14) випливає, що 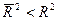 для
для 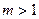 .
. 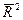 може бути і від’ємним.
може бути і від’ємним.
3. Індекс кореляції (множинний коефіцієнт кореляції) :
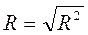 ,
, 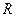 Î [0, 1]. (15)
Î [0, 1]. (15)
Для перевірки статистичної значущості коефіцієнта детермінації застосовують F-критерій Фішера. Аналіз статистичної значущості коефіцієнта детермінації проводять за наступними етапами:
1) розраховують F-статистику:
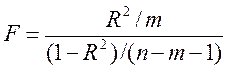 , (16)
, (16)
де 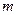 – кількість незалежних змінних;
– кількість незалежних змінних;
2) з таблиць критичних точок розподілу Фішера знаходять 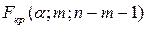 ;
;
3) якщо 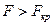 , то
, то 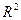 є статистично значущим, рівняння якісно описує зв’язок між залежною і незалежними змінними.
є статистично значущим, рівняння якісно описує зв’язок між залежною і незалежними змінними.
6. Визначення коефіцієнта детермінації для парної лінійної регресії.
Функціональна залежність умовного математичного сподівання 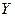 від
від 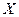 називається функцієюрегресії на :
називається функцієюрегресії на : 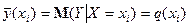 (1)
(1)
де 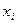 – значення ВВ в
– значення ВВ в 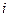 -му спостереженні,
-му спостереженні, 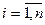 .
.
Парна лінійна регресія являє собою лінійну функцію між умовним математичним сподіванням 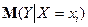 залежної змінної і однією незалежною змінною :
залежної змінної і однією незалежною змінною : 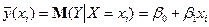 .(2)Співвідношення (2) називається теоретичним лінійним рівнянням регресії. Для відображення того факту, що кожне фактичне значення залежної змінної (
.(2)Співвідношення (2) називається теоретичним лінійним рівнянням регресії. Для відображення того факту, що кожне фактичне значення залежної змінної ( 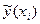 ) відхиляється від відповідного умовного математичного сподівання (
) відхиляється від відповідного умовного математичного сподівання ( 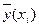 ), необхідно ввести в співвідношення випадковий доданок
), необхідно ввести в співвідношення випадковий доданок 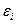 :
: 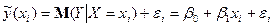 , (3)
, (3)
де 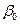 ,
, 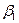 – теоретичні параметри (теоретичні коефіцієнти) регресії; – випадкові відхилення.Співвідношення (3) називається теоретичною лінійною регресійною моделлю. За вибіркою можна побудувати емпіричне рівняння регресії:
– теоретичні параметри (теоретичні коефіцієнти) регресії; – випадкові відхилення.Співвідношення (3) називається теоретичною лінійною регресійною моделлю. За вибіркою можна побудувати емпіричне рівняння регресії: 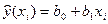 , (4)
, (4)
де 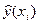 – оцінка умовного математичного сподівання ;
– оцінка умовного математичного сподівання ;
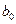 ,
, 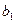 – оцінки невідомих параметрів
– оцінки невідомих параметрів 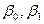 (емпіричні коефіцієнти регресії).
(емпіричні коефіцієнти регресії).
Фактичні значення залежної змінної ( 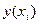 ) розраховуються за формулою:
) розраховуються за формулою:
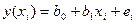 , (5)
, (5)
де 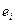 – оцінка теоретичного випадкового відхилення .
– оцінка теоретичного випадкового відхилення .
7. Використання Dummy-змінних у сезонному аналізі.
Однією із сфер застосування бінарних змінних є аналіз сезонних коливань. За допомогою цих змінних можна усунути сезонні коливання з метою визначення головних тенденцій розвитку певного економічного процесу.
Приклад 9.2. Нехай y — обсяг споживання певного продукту, який залежить від пори року. Для виявлення сезонності можна ввести
бінарні змінні d1, d2, d3:
d1 — 1, якщо місяць року зимовий, d1 — 0 — в інших випадках;
d2 — 1, якщо місяць року весняний, d2 — 0 — в інших випадках;
d3 — 1, якщо місяць року літній, d3 — 0 — в інших випадках.
На базі відповідних статистичних даних методом найменших квадратів можна оцінити параметри a3 лінійного регресійного рівняння
y — a0 + a d1 + a2 d2 + a3d3 + u.
Отримані результати мають такий зміст: коефіцієнт a0 визначає середньомісячний обсяг споживання досліджуваного продукту; суми коефіцієнтів a0 + a0 + a0 + a3 — обсяг споживання відповідно взимку, навесні та влітку. Отже, параметри a3 вказують на сезонні відхилення в обсягах споживання продукту відносно осінніх місяців. Перевірка статистичної значущості кожного з коефіцієнтів регресії виконується за допомогою традиційного t-тесту. Прийняття гіпотези про рівність нулю кожного з параметрів означає несуттєву різницю між споживанням в осінній період і споживанням в інший сезон. Комплексна гіпотеза a — a2 — a3 — 0 перевіряється за допомогою Р-тесту. Зокрема, якщо приймається припущення a — то це означає, що споживання взимку та весною не відрізняються між собою і т. ін.
8. Виявлення автокореляції за допомогою графічного методу, методу рядів.
Графічний метод
Існує кілька варіантів графічного визначення автокореляції. Відповідно до одному з них, на графіку відбиваються відхилення 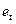 , що відповідають моментам
, що відповідають моментам 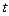 . Це так називані послідовно-часові графіки. На рис.1 наведені приклади послідовно-часових графіків.
. Це так називані послідовно-часові графіки. На рис.1 наведені приклади послідовно-часових графіків.
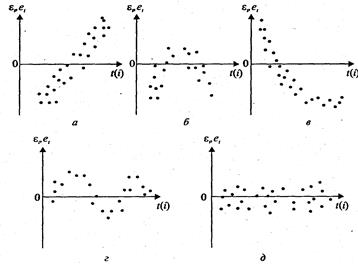
Рис. 1
У випадку, якщо на графіку є визначені зв'язки між відхиленнями (рис. 1, а) – г), то автокореляція має місце. Відсутність залежності свідчить про відсутність автокореляції (рис. 1, д).
Метод рядів
Послідовно визначаються знаки відхилень , 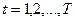 .
.
Наприклад, 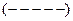
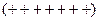
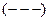
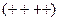
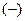 , тобто 5 «-», 7 «+», 3 «-», 4 «+», 1 «-» при 20 спостереженнях.
, тобто 5 «-», 7 «+», 3 «-», 4 «+», 1 «-» при 20 спостереженнях.
Візуальний розподіл знаків свідчить про невипадковий характер зв'язків між відхиленнями.
9. Виявлення гетероскедастичності (графічний аналіз залишків, тест рангової кореляції Спірмена).
Графічний аналіз залишків
При використанні методу графічного аналізу залишків по осі абсцис відкладаються значення ( 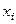 ) пояснюючої змінної (або лінійної комбінації пояснюючих змінних
) пояснюючої змінної (або лінійної комбінації пояснюючих змінних 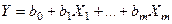 ), а по осі ординат або відхилення
), а по осі ординат або відхилення 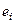 , або їх квадрати
, або їх квадрати 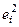 ,
, 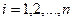 .
.
Приклади цих графіків наведені на рис. 4.– 8.
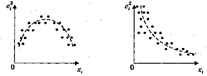
На рис. 4 усі відхилення знаходяться усередині смуги постійної ширини, що паралельна осі абсцис. Це говорить про незалежність дисперсій від значень змінної і їхній сталості, тобто в цьому випадку виконується умова гомоскедастичності. Ситуації, що представлені на рис. 5 – 8 відбивають велику ймовірність наявності гетероскедастичності.Тест рангової кореляції Спірмена.Алгоритм тесту рангової кореляції Спірмена:
1) значення 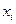 і
і 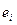 , ранжуються (упорядковуються по величинах).
, ранжуються (упорядковуються по величинах).
2) визначається коефіцієнт рангової кореляції: 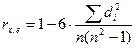 (1)
(1)
де 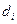 – різниця між рангами і ,
– різниця між рангами і , 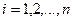 ;
; 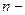 число спостережень.
число спостережень.
3) перевіряється значущість коефіцієнта рангової кореляції за допомогою t - критерію Стьюдента: 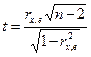 (2)
(2)
У випадку, якщо 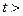
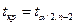 , то спостерігається гетероскедастичність, якщо
, то спостерігається гетероскедастичність, якщо 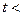
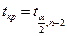 – гомоскедастичність.
– гомоскедастичність.
10. Дайте означення дисперсії ВВ.
Диспе́рсія є мірою відхилення значень випадкової величини від центру розподілу. Більші значення дисперсії свідчать про більші відхилення значень випадкової величини від центру розподілу.
Дисперсією випадкової величини X називається математичне сподівання квадрату відхилення від її математичного сподівання D(X) = M[X—N(X)]
Дисперсію зручніше обчислювати за формулою: D(X ) = M(X2)–[M(X)]2.
Властивості дисперсії.
Вастивість 1. Дисперсія постійної величини дорівнює нулю D(С)=0
Вастивість 2. Постійний множник виноситься за знак дисперсії, якщо піднести його до квадрату, тобто: D(СX)=С2 D(X)
Властивість 3. Дисперсія суми скінченої кількості незалежних випадкових величин дорівнює сумі дисперсій цих величин: D(x1 + x2+...+xn) = D(x1)+ D(x2)+..+ D(xn).
сперсія біноміального розподілу дорівнює добутку числа випробувань на ймовірності появи і не появленні події в одному випробуванні: D(X) = npq.
Середнє квадратичне відхилення. Середнім квадратичним відхиленням випадкової величину називають квадратний корінь з дисперсії: δ(Х)= 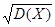 .
.
11. Дайте означення закону розподілу дискретної ВВ. Яким чином можна його задати?
Задають дискретні випадкові величини за допомогою закону розподілу, коли задаються ймовірності їх можливих випадкових значень (див. §1). Залежно від того, за якою формулою будуть обчислюватися ймовірності Рі, ці закони будуть мати свою назву.
Біноміальний розподіл – це закон розподілу випадкових величин, заданий таблицею, у якій ймовірності Рі обчислюються за формулою Бернуллі:
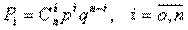 .
.
де p, n, q = 1-p, називаються араметрами розподілу.
Математичне сподівання і дисперсія випадкової величини, що має біноміальний розподіл відповідно рівні:
 .
.